







beasline
数据分析、预处理


#%% 数据分析、预处理
from collections import defaultdict
import matplotlib.pyplot as plt
# 常用包
import numpy as np
import pandas as pd
import seaborn as sns
# 导入torch
import torch
import torch.nn.functional as F
from pylab import rcParams
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from torch import nn
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
# 导入transformers
from transformers import BertModel, BertTokenizer, AdamW, get_linear_schedule_with_warmup
%matplotlib inline
%config InlineBackend.figure_format='retina' # 主题
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#ADFF02", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 12, 8
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
torch.cuda.is_available()
###########读取数据
with open('train_dataset_v2.tsv', 'r', encoding='utf-8') as handler:
lines = handler.read().split('\n')[1:-1]
data = list()
for line in tqdm(lines):
sp = line.split('\t')
if len(sp) != 4:
print("ERROR:", sp)
continue
data.append(sp)
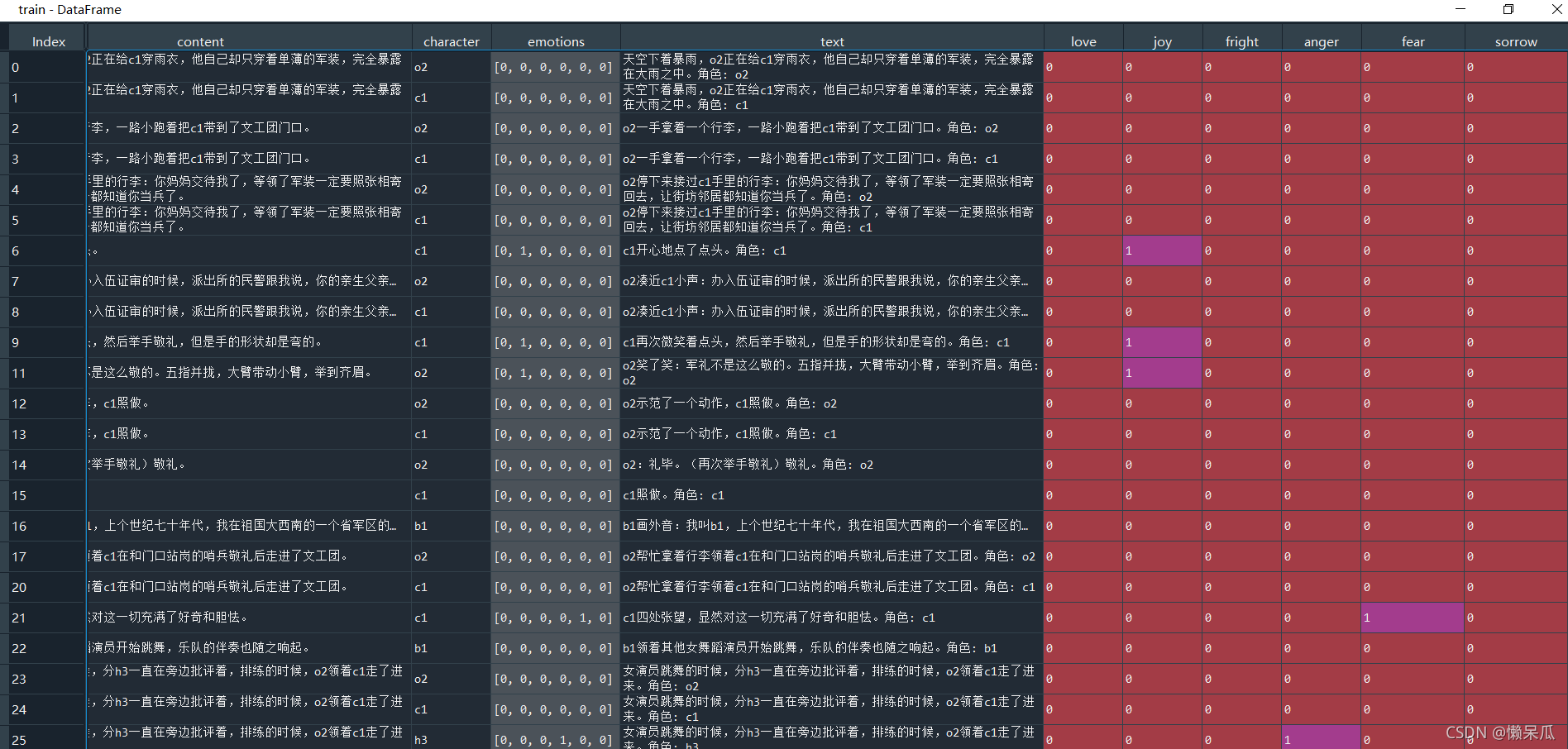
train = pd.DataFrame(data)
train.columns = ['id', 'content', 'character', 'emotions']
test = pd.read_csv('test_dataset.tsv', sep='\t')
submit = pd.read_csv('submit_example.tsv', sep='\t')
train = train[train['emotions'] != '']
###########数据处理
train['text'] = train[ 'content'].astype(str) +'角色: ' + train['character'].astype(str)
test['text'] = test['content'].astype(str) + ' 角色: ' + test['character'].astype(str)
train['emotions'] = train['emotions'].apply(lambda x: [int(_i) for _i in x.split(',')])
train[['love', 'joy', 'fright', 'anger', 'fear', 'sorrow']] = train['emotions'].values.tolist()
test[['love', 'joy', 'fright', 'anger', 'fear', 'sorrow']] =[0,0,0,0,0,0]
train['love'].value_counts()
############tokenizer
PRE_TRAINED_MODEL_NAME = 'bert'
tokenizer = BertTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME)
token_lens = []
for txt in tqdm(train.text):
tokens = tokenizer.encode(txt, max_length=512)
token_lens.append(len(tokens))
############数据分析
sns.distplot(token_lens)
plt.xlim([0, 256]);
plt.xlabel('Token count');
pd.Series(token_lens).describe()
MAX_LEN=128 # 这里我们暂时选定128
target_cols=['love', 'joy', 'fright', 'anger', 'fear', 'sorrow']
构建深度学习数据集
#%% 构建深度学习数据集
class RoleDataset(Dataset):
def __init__(self,texts,labels,tokenizer,max_len):
self.texts=texts
self.labels=labels
self.tokenizer=tokenizer
self.max_len=max_len
def __len__(self):
return len(self.texts)
def __getitem__(self,item):
"""
item 为数据索引,迭代取第item条数据
"""
text=str(self.texts[item])
label=self.labels[item]
encoding=self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=True,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
# print(encoding['input_ids'])
sample = {
'texts': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten()
}
for label_col in target_cols:
sample[label_col] = torch.tensor(label[label_col], dtype=torch.float)
return sample
df_train, df_val = train_test_split(train, test_size=0.1, random_state=RANDOM_SEED)
def create_data_loader(df,tokenizer,max_len,batch_size):
ds=RoleDataset(
texts=df['text'].values,
labels=df[target_cols].to_dict('records'),
tokenizer=tokenizer,
max_len=max_len
)
return DataLoader(
ds,
batch_size=batch_size,
# num_workers=4 # windows多线程
)
BATCH_SIZE = 16
train_data_loader = create_data_loader(df_train, tokenizer, MAX_LEN, BATCH_SIZE)
val_data_loader = create_data_loader(df_val, tokenizer, MAX_LEN, BATCH_SIZE)
# test_data_loader = create_data_loader(df_test, tokenizer, MAX_LEN, BATCH_SIZE)
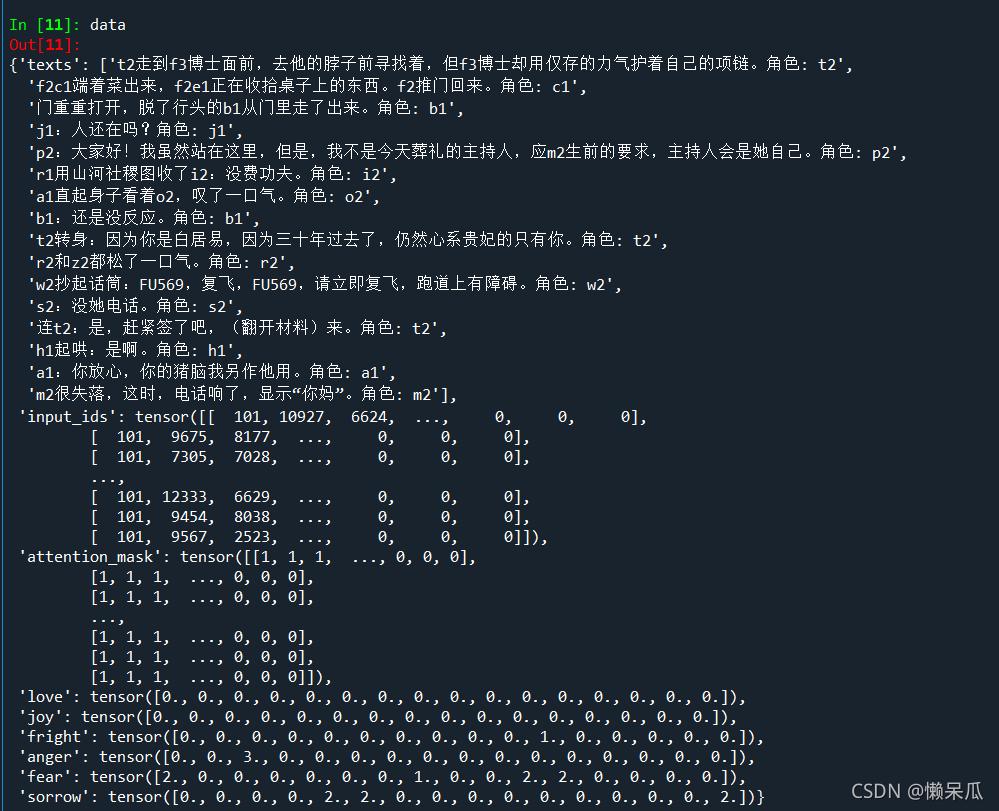
data = next(iter(train_data_loader))
data.keys()
print(data['input_ids'].shape)
print(data['attention_mask'].shape)
print(data['love'].shape)
多目标回归模型构建
#%% 多目标回归模型构建
bert_model = BertModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
class EmotionClassifier(nn.Module):
def __init__(self, n_classes):
super(EmotionClassifier, self).__init__()
self.bert = BertModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
self.out_love = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_joy = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_fright = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_anger = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_fear = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_sorrow = nn.Linear(self.bert.config.hidden_size, n_classes)
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict = False
)
love = self.out_love(pooled_output)
joy = self.out_joy(pooled_output)
fright = self.out_fright(pooled_output)
anger = self.out_anger(pooled_output)
fear = self.out_fear(pooled_output)
sorrow = self.out_sorrow(pooled_output)
return {
'love': love, 'joy': joy, 'fright': fright,
'anger': anger, 'fear': fear, 'sorrow': sorrow,
}
class_names=[1]
model = EmotionClassifier(len(class_names))
model = model.to(device)
模型训练
#%% 模型训练
EPOCHS = 1 # 训练轮数
optimizer = AdamW(model.parameters(), lr=3e-5, correct_bias=False)
total_steps = len(train_data_loader) * EPOCHS
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=total_steps
)
loss_fn = nn.MSELoss().to(device)
def train_epoch(
model,
data_loader,
criterion,
optimizer,
device,
scheduler,
n_examples
):
model = model.train()
losses = []
correct_predictions = 0
for sample in tqdm(data_loader):
input_ids = sample["input_ids"].to(device)
attention_mask = sample["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
loss_love = criterion(outputs['love'], sample['love'].to(device))
loss_joy = criterion(outputs['joy'], sample['joy'].to(device))
loss_fright = criterion(outputs['fright'], sample['fright'].to(device))
loss_anger = criterion(outputs['anger'], sample['anger'].to(device))
loss_fear = criterion(outputs['fear'], sample['fear'].to(device))
loss_sorrow = criterion(outputs['sorrow'], sample['sorrow'].to(device))
loss = loss_love + loss_joy + loss_fright + loss_anger + loss_fear + loss_sorrow
losses.append(loss.item())
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# return correct_predictions.double() / (n_examples*6), np.mean(losses)
return np.mean(losses)
def eval_model(model, data_loader, criterion, device, n_examples):
model = model.eval() # 验证预测模式
losses = []
correct_predictions = 0
with torch.no_grad():
for sample in tqdm(data_loader):
input_ids = sample["input_ids"].to(device)
attention_mask = sample["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
loss_love = criterion(outputs['love'], sample['love'].to(device))
loss_joy = criterion(outputs['joy'], sample['joy'].to(device))
loss_fright = criterion(outputs['fright'], sample['fright'].to(device))
loss_anger = criterion(outputs['anger'], sample['anger'].to(device))
loss_fear = criterion(outputs['fear'], sample['fear'].to(device))
loss_sorrow = criterion(outputs['sorrow'], sample['sorrow'].to(device))
loss = loss_love + loss_joy + loss_fright + loss_anger + loss_fear + loss_sorrow
losses.append(loss.item())
return np.mean(losses)
history = defaultdict(list) # 记录10轮loss和acc
best_loss = float('inf')
for epoch in range(EPOCHS):
print(f'Epoch {epoch + 1}/{EPOCHS}')
print('-' * 10)
# train_loss = train_epoch(
# model,
# train_data_loader,
# loss_fn,
# optimizer,
# device,
# scheduler,
# len(df_train)
# )
print(f'Train loss {train_loss}')
val_loss = eval_model(
model,
val_data_loader,
loss_fn,
device,
len(df_val)
)
print(f'Val loss {val_loss} ')
print()
history['train_loss'].append(train_loss)
history['val_loss'].append(val_loss)
if val_loss < best_loss:
torch.save(model.state_dict(), 'best_model_state.bin')
模型预测
#%% 模型预测
test_data_loader = create_data_loader(test, tokenizer, MAX_LEN, BATCH_SIZE)
def predict(model):
val_loss = 0
test_pred = defaultdict(list)
model.eval()
for step, batch in tqdm(enumerate(test_data_loader)):
b_input_ids = batch['input_ids'].to(device)
b_attention_mask = batch['attention_mask'].to(device)
with torch.no_grad():
logits = model(input_ids=b_input_ids, attention_mask=b_attention_mask)
for col in target_cols:
test_pred[col].append(logits[col].to('cpu').numpy())
preds = {}
for col in target_cols:
print(len(np.concatenate(test_pred[col])))
preds[col] = (np.concatenate(test_pred[col]))
return preds
submit = pd.read_csv('data/submit_example.tsv', sep='\t')
best_model = EmotionClassifier(len(class_names))
path = f'best_model_state.bin'
best_model.load_state_dict(torch.load(path))
best_model.to(device)
test_pred = predict(best_model)
label_preds = []
for col in target_cols:
preds = test_pred[col]
label_preds.append(preds.flatten())
sub = submit.copy()
sub['emotion'] = np.stack(label_preds, axis=1).tolist()
sub['emotion'] = sub['emotion'].apply(lambda x: ','.join([str(i) for i in x]))
sub.head()
sub.to_csv(f'baseline.tsv', sep='\t', index=False)

















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









