






1. 背 景
剧本分析是内容生产链条的第一环,因此,我们结合专家经验知识、大数据与自然语言处理技术来帮助业务部门快速分析和评估剧本。评估体系中涉及到了大量关于角色的分析,其中角色的情感分析是非常重要的一个任务。
不同于通常的评论类短文本,剧本有其独有的业务特点,因此任务的目标和建模与通常的任务区别较大。本文将系统的介绍情感分析领域相关的内容,以及爱奇艺在剧本分析中针对角色进行细粒度情感分析所做的工作。
2. 常见的情感分析任务的分类
2.1
传统的情感分析
传统的情感分析,通常是对一句话,或者一段话做出一个总的情感判定(积极、消极、中性),可以看做是一个文本分类任务。通常的方法分为:词法规则分析、算法模型分析、混合分析。
【词法规则】
使用词法分析将输入文本转换成词序列,然后依次和一个预先准备好的字典进行匹配。如果是积极的匹配,那分数就增加;如果是消极的匹配,分数就减少。文本的分类取决于单词序列的总得分。当然,计算公式上可以有一些变化,不一定是单纯的线性加减。
这个方法的优点是简单、快速;缺点是准确度偏低,且效果和性能很大程度取决于人工构建的字典。
【算法模型分析】
情感分析任务中通常是使用有监督的模型,一般可以分成三个阶段:数据收集、预处理、训练分类。可以使用NB、LR、SVM等传统机器学习算法,以及CNN、RNN系列等深度学习算法。
传统的机器学习方法,特征的构建很重要,这是决定准确率的关键。特征构建方法也很多。比如:N-grams、积极/消极词汇的数量、文本长度等。深度学习时代,关键是网络结构的设计、以及语料的构建。
【混合分析】
工业应用上,很多时候都是将“词法分析”与“算法模型分析”两种方法相结合进行使用。一些研究者在这方面做了大量工作。一般都是先利用字典对原文本进行处理转化、然后再利用算法模型来进行分类。
随着深度学习的发展,特别是Bert这些预训练模型的出现,大家的重心和焦点都发现了变化。从原来研究各种数据处理、特征提取的trick,转为研究如何设计网络、如何转化问题以最大程度利用预处理模型。
2.2
target-dependent 情感分析
与典型情感分析任务不同,target-dependent情感分析是研究基于目标的情感。给定一个句子和句子相关的一个对象,判断句子针对给定的对象的情感倾向。
例如,有句子:“张三在学校里很受大家欢迎,但是邻居李四不太受欢迎 !”
其中,基于目标“张三”,句子的情感是正向的;基于“李四”,句子的情感是负面的。
可见,与传统的情感分析任务相比,任务的难度和复杂性大大增加,一般都是用深度学习模型来解决。
2.2.1 TD-LSTM
传统的LSTM模型并没有考虑被评估的目标词和上下文的相互关系,为了引入这一部分的信息, TD-LSTM 应运而生。TD-LSTM 的主体结构是基于LSTM的。其基本思路是根据target words之前和之后的上下文分别建模。所以实际上,使用的是两个 LSTM 模型: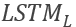 和
和 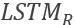 。的输入为目标词之前的上下文加上目标词,即从句子的第一个单词,到最后一个target words
。的输入为目标词之前的上下文加上目标词,即从句子的第一个单词,到最后一个target words 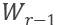 依次输入;的输入则是目标词之后的上下文加上目标词,即从句子的最后一个单词
依次输入;的输入则是目标词之后的上下文加上目标词,即从句子的最后一个单词 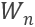 ,到第一个target words
,到第一个target words 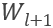 依次输入。模型用 softmax 函数作为最后一层的激活函数来实现分类,用交叉熵作为损失函数来计算损失。模型结构和LSTM对比如下:
依次输入。模型用 softmax 函数作为最后一层的激活函数来实现分类,用交叉熵作为损失函数来计算损失。模型结构和LSTM对比如下:

2.2.2 TC - LSTM
TC-LSTM在TD-LSTM的基础上,在输入端加入了  ,即target words的信息。具体做法就是将原先的字向量与target words向量拼接起来,其中是所有target words字向量的平均值。TC-LSTM整合了target words与context words的相互关联信息。模型同样用 softmax 函数作为最后一层的激活函数来实现分类,用交叉熵作为损失函数来计算损失。模型结构如下所示:
,即target words的信息。具体做法就是将原先的字向量与target words向量拼接起来,其中是所有target words字向量的平均值。TC-LSTM整合了target words与context words的相互关联信息。模型同样用 softmax 函数作为最后一层的激活函数来实现分类,用交叉熵作为损失函数来计算损失。模型结构如下所示:

2.3
Aspect-level 情感分析
TD-LSTM和TC-LSTM两个模型,只能用于target在句子中出现过的情况。对于aspect,它往往是某个target的抽象,aspect本身在句子中可能并没有出现。而TD-LSTM、TC-LSTM两个模型都需要知道target在句子中的具体位置,因此在面向aspect的任务中无法使用。
2.3.1 AT-LSTM
Aspect信息在对象级情感分析任务上具有至关重要的作用,给定同一句话,针对不同Aspect可能会得到完全相反的结果,为了最好地利用Aspect信息,需要为每一个Aspect学习对应的向量,然后将Aspect向量的信息输入模型中。另外,传统的LSTM方法在对象级情感分析任务上不能检测到文本信息的哪一部分是最关键的,为了解决这一问题,AT-LSTM方法增加了Attention机制。模型首先通过一个LSTM模型得到每个词的隐藏状态向量,然后将其与Aspect Embedding连接,Aspect Embedding作为模型参数一起训练,从而得到句子在给定的aspect下的权值向量α,最后再根据权值向量对隐藏向量进行赋值,得到最终的句子表示,然后预测情感。模型结构如下图所示:

2.3.2 ATAE-LSTM
(Attention-based LSTM with Aspect Embedding)
在 AT-LSTM 的基础上,在句子输入时额外再拼接对象词向量,就是 ATAE-LSTM 模型,即同时在模型的输入部分和隐态部分引入aspect信息。与TC-LSTM的思想类似,使用这种方法进一步在句子表示中更好地利用目标词和每个上下文词之间的关系。模型结构如下图:

2.3.3 TNET
TNET模型结构如下图所示:

最底部是一个Bi-LSTM,根据输入的词序列X={x1,x2,...,xn}经过Bi-LSTM得到状态输出h(0)={ h1(0), h2(0),..., hn(0)},中间层包含L个CPT层,模型经过中间层将结果送到最上层的卷积层,使用Max Pooling的方法提取特征,最后使用Softmax得到输出的情感类别。
可以看到,关键在于CPT模块,每一个单独的CPT结构如下图所示:

包含量身定制的TST(Target-Specific Transformation)和LF/AS两个子结构。
TST结构主要是为了强化上下文的词表达与对象词表达之间的关系,其最底层是一个BI-LSTM,输入是对象词的Embedding,输出对应的隐藏层状态。由于传统的方法(多个对象词取平均)会忽略组成target(即对象)的多个词的顺序及重要度,这样的对象词表达会更充分地表示原有对象词的含义。同时,在其上加一个attention, 基于每一个hmt(target的隐层状态输出)和每一个输入的 得到
得到 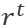 , 最后将r与h拼接后经过一个全连接层送到LF/AS结构中。经过非线性的TST后,原上下文信息容易大量丢失。通过Lossless Forwarding(LF)和Adaptive Scaling(AS)来找回丢失的信息。
, 最后将r与h拼接后经过一个全连接层送到LF/AS结构中。经过非线性的TST后,原上下文信息容易大量丢失。通过Lossless Forwarding(LF)和Adaptive Scaling(AS)来找回丢失的信息。
其中,LF的结构是将第(l)个CPT层的输入hi(l)在CPT的输出时再加回来,这样的话就不会损失掉原有的信息了。AS的结构是类似RNN的门机制,训练一个门结构,AS通过门函数控制哪些信息被传递和传递的比例。
3. 角色细粒度情感分析
剧本中角色情感分析的任务主要是对剧本每句对白和动作描述中涉及到的每个角色从多个维度进行分析。因此,相比于常见的情感分析任务,有其自身的特点。其中碰到的难点包括以下几个大的方面:
(1)角色人名识别。不同于通常的新闻、评论性文本,剧本中角色的名字很多时候都是非常规的,特别是一些玄幻类剧本,角色的命名更加天马行空。
(2)构建一个符合业务场景的情感维度模型。
(3)更深层次的语义理解。角色情感不仅仅取决于当前文本,可能需要对前文语义有深度依赖。一方面,前文依赖的长度可能较长,尽管很多深度模型本身能一部分解决长文本依赖的问题,但是对于窗口超过一定长度的语义理解仍然很吃力。另一方面,需要根据业务特点设计特定的网络结构以更好的捕获信息。
3.1
角色识别
由于需要对角色进行情感分析,因此首先的问题就是要识别剧本中的“角色”;同时,我们还需要识别出“角色”的类型。理论上我们需要针对那些对剧情有推动力的“主、配角”进行分析,而忽略掉“打酱油”的“群众”。
“角色”人名识别属于NER任务。NER属于一个很经典的NLP领域,早期的HMM、CRF在很多业务领域都已经能够比较好的解决问题了。深度学习时代,大家一般都使用 BILSTM+CRF的方案。不同于通常的新闻、评论性文本,识别剧本角色名碰到的问题包括:
(1)剧本中的名字很多时候都是非常规的,特别是一些玄幻类剧本,角色的命名更加天马行空
(2)剧本的行文风格和通常的新闻类语料差别较大
可以看到,通常的开源语料不能做为剧本角色人名识别的训练语料。这对使用深度模型造成了一定的障碍,而传统的HMM、CRF等模型在剧本这种复杂场景中效果很差。
当然,剧本做为长文本,也有其自身在统计方面的优势,这是我们可以充分利用的。
首先,我们使用了“新词发现”这样的概率模型,以充分利用剧本这种长文本在统计层面的优势。
深度模型方面,我们使用了BiLSTM+CRF和LatticeLSTM两个深度模型。BiLSTM+CRF是业界经典的方案,BiLSTM网络上加一个CRF层,能为模型输入一些专家经验。同时,为了避免分词带来的误差,我们使用了不分词的方案,这样就不可避免的丢失了一些成词方面的信息。比如:“爱奇艺创新大厦”这种成词是有意义的,应该把这种信息带入模型。所以,我们补充了LatticeLSTM模型,以弥补“不分词”方案带来的问题。
两个深度模型能够相互进行有益的补充,但是他们对训练语料和标注质量都要求较高,而领域语料的缺乏正是大家的痛点之一。一方面我们会进行一些高质量的人工标注,这个工作的代价比较大,周期较长;另一方面会利用“新词发现”无监督模型的输出来自动化构建标注语料。一个模型的输出又能做为另外模型的输入,这样就形成了内部的良性自循环。
3.2
第一版情感分析模型
做情感分析,构建一个合理的情感分析业务模型是最基础的工作。我们结合了“普鲁契克情感轮盘”、Ekman的情感分类以及医学上的情感分类,最终确定用类似情感轮的 “十情模型”。
我们会针对剧本每句话中涉及到的每个不同角色的情感从“爱、乐、信、期、惊、疑、忧、怒、哀、恐” 十个维度进行细粒度的分析。如下:
【例】
辛小丰躺在地上,回想发生的事。
(闪回 - 阁楼少女出浴,擦拭身体时,可见脖颈挂着玉坠。结束)
辛小丰:我得回去……

这话让喘息中的杨自道,陈比觉心惊。

辛小丰爬起来,往回走。
陈比觉:你要回去……我干你姥,你要回去!我们三个都被你毁了!干你母,我干你母!
陈比觉打辛小丰,辛小丰不还手。

剧本中,“对白”和“动作”在描述风格和语义表达方面存在差异,因此,需要分别针对“对白”和“动作”进行建模。如前面介绍,在进行语义理解时有两个关键问题需要解决:
(1)需要理解较长的前文信息
(2)要定位到每句话中的每一个角色
对于第一个问题,BERT已经能一定程度上解决了,通常要做的就是把输入数据按照BERT的任务要求输入,然后将最高层“CLS”位置的Embedding输入到一个分类器模型。如下:

但是这里有个最关键的问题,我们需要定位到每一个“角色”,直接使用BERT的这种粗犷的方式并不能解决问题。另外,BERT由于有512窗口的限制,在我们的场景中,对于前文信息的理解这块也是不太足的,这个问题后面会说到。
要解决第二个问题,需要做一些更细致的工作。我们在前文中介绍了TD-LSTM,它能基于特定的对象进行分析,但是LSTM网络的结构注定了其在长文本环境下,效果会比较差。
综上所述,我们既需要能理解较长范围内的文本信息,同时又能精确定位到“角色”。所以在分析“动作描述”时,我们使用了BERT+TD-LSTM网络结构。使用BERT来做特征提取,利用TD-LSTM来对特定对象进行分析。模型结构如下:

在分析对白描写时,问题类似,但相比于动作描写,其在情感表达上通常更加直接,同时,对白描写能天然的定位到“角色”,所以我们在模型结构上做了一些改变。使用了BERT+多层CNN的结构。我们知道CNN网络本身存在窗口,难以捕获较长的语义,所以我们使用多层CNN来解决这个问题。另外,对白描写有表达相对较直接、语义较浅层,所以在这里用CNN系列网络比RNN系列更合适。模型结构如下:

3.3
第二版情感分析模型
剧本中角色的情感实际上不仅仅和当前描述所涉及的内容有关,与整体的情感氛围、以及该角色之前的情感都有关系。可以看到,第一版算法模型存在几个问题:
(1)没有考虑内容整体的情感氛围对角色当前情感的影响
(2)没有考虑角色之前的情感带来的累积效应
(3)由于BERT本身窗口的限制,导致前文信息有限
总体来看,我们需要解决两个核心问题:
(1)需要理解更长的前文信息
(2)需要记录角色的情感累计信息
前文中我们也提到了BERT可以一部分解决前文信息的理解。但是,一方面BERT有512个字符窗口大小的限制;另一方面需要有一个明确的下游业务任务模型做指导。所以,我们有针对性的设计了第二版算法模型。
改进点如下:
针对第一个问题,使用一个global GRU记录全局信息,每个时刻的状态和前一时刻的状态以及当前的句子有关,即:
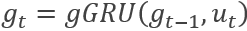
在这种业务模型下,不再盲目的让BERT利用Trm去理解文字之间的语义关联信息,较好的解决了前文信息获取的问题。
针对第二个问题,对于每个角色的状态通过emotion GRU进行编码,记录该角色的状态信息。当前窗口内,每一个角色对应一个针对该角色的eGRU。
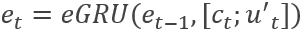
其中,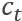 是一个所有前文句子向量的自注意力编码。
是一个所有前文句子向量的自注意力编码。
若当前语句中有多个人物,则分别更新每个人物的 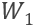 。然后通过FC层进行情感预测。
。然后通过FC层进行情感预测。
3.4
案例分析
案例来自获奖的韩国电影《寄生虫》的剧本。

针对13场的语句“金基泽、忠淑看着儿子的背影走远。”中,关于金基泽的情感,两版模型的分析结果如下:

可以看到,仅根据本场前文中金基宇走路的普通行为和金基泽、忠淑望着儿子背影的描述,V1.0模型推测这是一个离别的场景,并按照常规的思路理解人物情绪,认为金基泽呈现出一定程度的伤感情绪。V2.0模型结合了场次12中金基宇向金基泽宣称志向,金基泽十分骄傲的背景知识,以及相关人物的情绪趋势,给出了不同的情绪分析结果:金基泽、忠淑被认为有显著的高兴、有信心、期待未来等正面情绪。
在这个案例中,针对同样的分析对象,两个模型推理出了完全相反的情感基调,我们认为V2.0模型的理解更为合理。
3.5 总结和规划
目前角色细粒度情感分析模型已经应用于爱奇艺的“剧本评估”项目中。角色情感可以反映出角色的情绪变化和心路历程等,辅助内容部门对角色塑造进行分析;同时也是矛盾冲突、剧情节奏、人物弧光等下游分析任务的重要输入。目前模型仍然存在一些不足之处,我们主要将从算法建模和模型结构两个方面进行优化。
算法建模方面:不同类型的剧本,在角色塑造、写作笔法等方面都有区别,模型中需要进一步利用这些领域知识,以便能更好的表征业务实际。比如:动作片、警匪片中有大量的激烈场面描写,而言情片中很多感情纠葛方面的内容,要避免因为类型不同而带来的模型结果方面的误差。另外,剧本属于艺术创作,使用了大量的插叙、伏笔等创作手法,这些都会带来分析和建模上的复杂性。我们需要进一步提高模型在业务方面的合理性。
模型结构方面:目前的网络结构稍显复杂,可以进一步优化,提高效率;同时基于业务实际情况,转化问题的类型,以进一步充分利用预训练模型。模型中TD-LSTM和几个GRU隐层的作用可以用更高效的网络结构替代。另外,可以考虑把“文本分类”任务转化为“句子匹配”任务,这样可以更好的利用BERT预处理模型带来的福利,不过其中有很多细节的地方需要好好设计一下。
4. 文献引用
[1] Duyu Tang, Bing Qin, Xiaocheng Feng, Ting Liu. 2016. Effective LSTMs for Target-Dependent Sentiment Classification
[2] YequanWang and MinlieHuang and LiZhao and XiaoyanZhu. 2016. Attention-based LSTM for Aspect-level Sentiment Classification
[3] Xin Li, Lidong Bing, Wai Lam, Bei Shi. 2018. Transformation Networks for Target-Oriented Sentiment Classification
[4] Navonil Majumder, Soujanya Poria, Devamanyu Hazarika, Rada Mihalcea, Alexander Gelbukh, Erik Cambria. 2019. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations
[5] Yue Zhang and Jie Yang. 2018. Chinese NER Using Lattice LSTM
[6] Liang-Chih Yu1, Lung-Hao Lee, Shuai Hao, Jin Wang, Yunchao He,Jun Hu, K.Robert Lai and Xuejie Zhang. 2016. Building Chinese Affective Resources in Valence-Arousal Dimensions

也许你还想看

扫一扫下方二维码,更多精彩内容陪伴你!



















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









