






题目:Medical SAM Adapter(医学SAM自适应器): Adapting Segment Anything Model(自适应分割任意模型) for Medical Image Segmentation(医学图像分割)
论文:Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
一、摘要
研究背景:分割任意模型(SAM)由于其在各种分割任务中的出色性能和基于提示的界面,近年来在图像分割领域得到了广泛的应用。
研究问题:然而,最近的研究和个人实验表明,由于缺乏医学特定知识,SAM在医学图像分割方面表现不佳 。这就提出了如何增强SAM对医学图像的分割能力的问题。
主要工作:本文提出了医学SAM自适应器(Medical SAM Adapter, Med-SA),该自适应器以一种 轻而有效的自适应技术 将特定领域的 医学知识融入分割模型 中,而不是对SAM模型进行微调。在Med-SA中,本文提出了 空间深度转置(SD-Trans) 来使 2D SAM适应3D医学图像 ,并提出了 超提示适配器(HyP-Adpt) 来实现 提示条件适应 。
实验效果:在各种图像模态的17个医学图像分割任务上进行了全面的评估实验。Med-SA优于几种最先进的(SOTA)医学图像分割方法,而只更新2%的参数。
二、引言
Adapter(适应器):
- adapter一直是自然语言处理(NLP)中一种流行且广泛使用的技术,用于微调各种下游任务的基本预训练模型。
- 本文选择使用一种称为自适应的参数高效微调 (PEFT) 技术来微调预训练的SAM(Hu等人,2021年)。(也就是 LoRA 模型调参方法,LoRA: Low-Rank Adaptation of Large Language Models )
然而,将自适应技术直接应用于医疗场景并不是那么简单。
- 第一个挑战来自图像形态。目前尚不清楚如何将2D SAM模型应用于3D医学图像分割。
- 其次,虽然自适应在自然语言处理中已经取得了成功,但将其应用于视觉模型,特别是像SAM这样的交互式视觉模型的研究有限。在交互式视觉模型中,用户提供的视觉提示在最终预测中起着至关重要的作用。如何将Adapter(适应器)与这些重要的视觉提示结合起来仍有待探索。
模态转化 和 提示条件适应:
- 引入了空间深度转置(SD-Trans)技术来实现2D到3D的适配。在SD-Trans中,将输入嵌入的空间维度转置到深度维度,允许相同的自我注意块在不同的输入下处理不同的维度信息。
- 提出了超提示适配器(Hyp-Adpt)来实现提示条件适应,它利用视觉提示来生成一系列权重,这些权重可以有效地应用于适应嵌入,促进了广泛而深入的提示-适应交互。
1. 提出了一种适用于一般医学图像分割的自适应方法。所提出的框架Med-SA是SAM架构的简单而强大的扩展,大大增强了其医疗应用的能力,同时仅更新了总参数的2%。
2. 提出 SD-Trans ,以实现高维(3D)医学数据的分割,解决医学图像模态带来的挑战。
3. 提出了 HyP-Adpt 以促进快速条件适应,承认用户提供的提示在医疗领域的重要性。
4. 在 17 个具有不同图像模态的医学图像分割任务上进行了广泛的实验,明确确立了 Med-SA 比 SAM 和以前最先进的方法的优越性。在广泛使用的腹部多器官分割BTCV数据集上,Med-SA 比Swin-UNetr、vanilla SAM 和 MedSAM 分别提高了2.9%、34.8%和9.4%。
三、方法
A. Preliminary: SAM architecture( 预备知识:SAM体系结构 )
SAM由三个主要组件组成:图像编码器、提示编码器 和 掩码解码器。
(1)图像编码器:图像编码器基于 MAE 预训练的标准视觉Transformer (ViT)。
- 过程:具体来说,使用ViT-H/16变体,它采用14×14窗口注意力和四个等间距的全局注意力块。图像编码器的输出是输入图像的16×下采样嵌入。
(2)提示编码器 :提示编码器可以是稀疏的 (点、框) 或 稠密的 (掩码) 。
- 过程:本文只关注稀疏编码器,它将点和框表示为与每种提示类型的学习嵌入相加的位置编码。
(3)掩码解码器:掩码解码器是经过改进的Transformer解码器块,以包括动态掩码预测头。
- 过程:解码器使用双向交叉注意力来学习提示和图像嵌入之间的交互。之后,SAM对图像嵌入进行上采样,MLP将输出标记映射到动态线性分类器,该分类器预测给定图像的目标掩码。
B. Med-SA architecture( Med-SA 架构 )
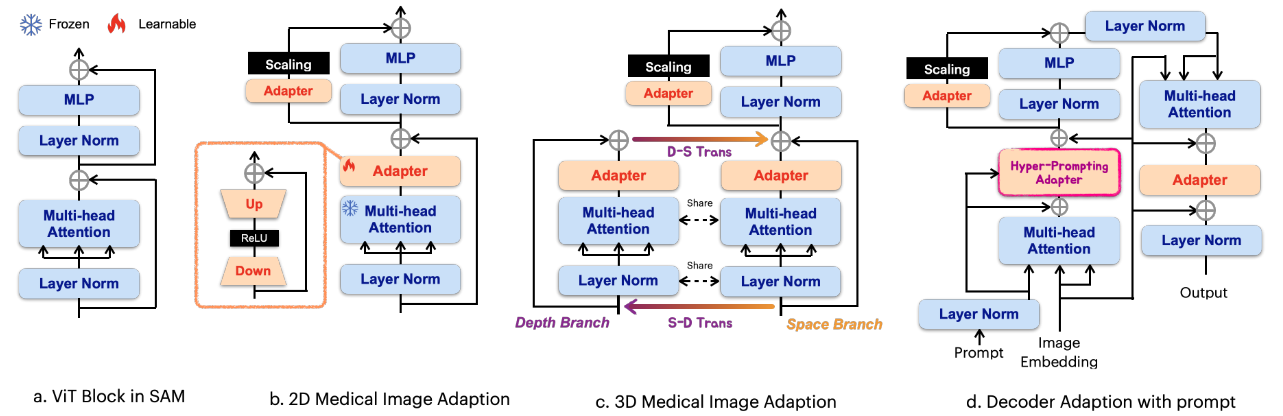
目的:本文的目标是通过 微调 来增强 SAM 架构在医学图像分割任务中的医疗能力。
方法:不是完全调整所有参数,而是将预先训练的 SAM 参数 frozen(冻结),设计一个Adapter(适应器)模块并将其集成到指定位置。
结构(适应器):Adapter(适应器)充当瓶颈模型,由向 下投影、ReLU激活 和 向上投影 依次组成,如图 b 所示。下投影使用简单的MLP层将给定的嵌入压缩到较低的维度,而上投影使用另一个MLP层将压缩的嵌入扩展回其原始维度。
结构(图像编码器):在SAM编码器中,为每个ViT块使用两个适应器。对于标准ViT块,第一个适应器位于多头注意之后和残差连接之前。第二个适应器跟随多头注意力放置在MLP层的残差路径中。紧跟在第二个适配器之后,使用缩放因子 s 对嵌入进行缩放。如图 b 所示。
结构(掩码解码器):在SAM解码器中,为每个VIT块集成了三个适应器。如图 c 所示。
- 第一个适应器:
- 目的:用来集成提示嵌入
- 方法:为了实现这一点,本文引入了一种称为 超提示适配器 (Hyper-Promting Adapter,HyP-Adpt) 的新结构(也是适应器),在中对其进行了进一步的阐述。
- 第二个适应器:
- 目的:为了适应 MLP 增强的嵌入。
- 位置:解码器中的第二个适应器的部署方式与编码器中的完全相同。
- 第三个适应器:
- 位置:在图像嵌入-提示交叉注意力的残差连接之后,部署第三个适配器。在适应器后连接另一个残差连接和层归一化以输出最终结果。
Adapter(适应器)代码实现:
import torch
import torch.nn as nn
class Adapter(nn.Module):
def __init__(self, D_features, mlp_ratio=0.25, act_layer=nn.GELU, skip_connect=True):
super().__init__()
self.skip_connect = skip_connect
D_hidden_features = int(D_features * mlp_ratio)
self.act = act_layer()
self.D_fc1 = nn.Linear(D_features, D_hidden_features)
self.D_fc2 = nn.Linear(D_hidden_features, D_features)
def forward(self, x):
# x is (BT, HW+1, D)
xs = self.D_fc1(x)
xs = self.act(xs)
xs = self.D_fc2(xs)
if self.skip_connect:
x = x + xs
else:
x = xs
return xC. SD-Trans( 空间深度转置 )
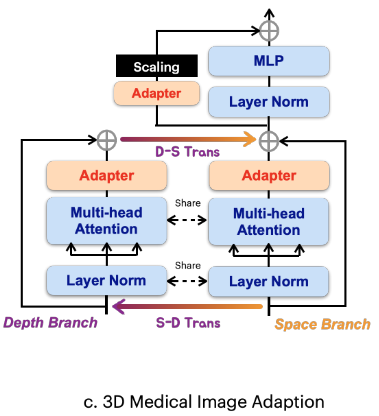
问题:由于二维图像与流行的三维图像(如MRI和CT扫描)之间的维度差异,将SAM应用于医学图像分割提出了挑战。(流行的SAM模型只能分割2D 图像)(3D 图像使用 2D 适应器容易考虑不到3D医学图像分割所固有的密切的体积相关性)
方法:为解决这一限制,本文提出 SD-Trans,受图像到视频适应器(Liu et al. 2019)的启发。具体结构如图 c 所示。(使用双分支,空间和深度,全面提取特征相关性)
结构:如图所示,在每个模块中,将注意力操作分成两个分支:空间分支和深度分支。
过程:
- 1. (空间分支):对于给定的深度为D的3D样本,将D×N×L输入到空间分支的多头注意中,其中 N 表示嵌入的数量,L表示嵌入的长度。这里,D对应于操作的数量,允许在N×L上应用交互,捕获和抽象空间相关性作为嵌入。
- 2. (深度分支):在深度分支中,对输入矩阵进行转置,得到N×D×L,随后将其提供给相同的多头注意力。尽管采用了相同的注意力机制,但现在交互发生在D × L上,使深度相关性的学习和抽象成为可能。
- 最后,将深度分支的结果转置回其原始形状,并将其添加到空间分支的结果中,以融合深度信息。
Q:空间分支和深度分支使用相同的注意力机制?为什么分别捕获和抽象空间和深度相关性作为嵌入?
A:关键在于 “转置操作”,空间和深度分支对应的输入张量形状分别是 D×N×L 和 N×D×L,导致注意力计算发生和作用的维度不一样。
D. HyP-Adpt( 超级提示适应器 )

问题:将 adaptation(自适应技术)应用于交互式视觉模型的工作在很大程度上尚未探索。源任务和下游任务之间的交互行为可以表现出显著的差异。因此,将在交互模型中起关键作用的视觉提示合并到 Adapter(适应器)中变得至关重要。(SAM是一种人为提示的交互式模型)
启发:Hyp-Adpt 背后的想法受到超网络(Ha、Dai和Le 2016)的启发,后者使用一个网络为另一个网络生成权重,以实现知识条件反射。
过程:具体地说,只使用投影和重塑操作来从提示嵌入生成一系列权重图。然后将这些权重映射直接应用于适应器嵌入(矩阵乘积)。
(1):具体来说,对适应器
的减少嵌入进行了超提示。同时,将提示信息进行拼接并缩减为提示嵌入
。然后,使用
来生成一个权重序列,取其中一个来说明,它可以表示为:
![]()
其中,Re表示整形操作,M 表示将 投影到
的MLP层,其中∗为值乘,第一个权重的
为
长度,最后一个权重的
为输出的目标长度。
(2)![]() :然后,将
:然后,将 从一维嵌入重塑为二维权重
,并将其应用于
。将元素沿长度维度归一化,然后应用REU激活。可以表示为:
![]()
其中⊗是矩阵乘积。本文为超级提示设置了3个层,每个权重由单独的MLP层投影。
作用:Hyp-adpt有助于根据提示信息调整参数,更灵活地适应不同的通道和下游任务。
四、实验
4.1 Dataset
1. 评估总体分割性能:选择了腹部多器官分割。使用BTCV数据集,这是一个广泛使用和公开可用的基准,有12种解剖作为基准。
2. 评价对不同模态的泛化性:对于眼底图像分割,在REFUGE2数据集上进行了实验。对于脑肿瘤分割,在BraTs 2021数据集上进行了实验。对于甲状腺结节分割,使用了TNMIX基准,这是一个混合数据集,包含来自TNSCUI的4554张图像和来自DDTI的637张图像。最后,对于黑色素瘤或痣分割,在ISIC 2019数据集上进行了实验。
4.2 Implementation Details
批量大小:对于3D医学图像训练,我们使用了较小的批次大小16。
训练轮次:对于REFUGE2、TNMIX和ISIC数据集,我们训练了40个epoch的模型。对于BTCV和BraTs数据集,我们将训练扩展到60个epoch。与完全微调训练相比,我们选择了更小的迭代次数,因为我们观察到模型在我们的设置中收敛更快。
提示类型:(1) 随机1个正点,记为“1-point”; (2) 3个正点,记为“3-points”; (3) 与目标重叠50%的边界框,记为“BBox 0.5”; (4) 与目标重叠75%的边界框,记为“BBox 0.75”。
实验设备:所有实验均在PyTorch平台上实现,并在4个NVIDIA A100 gpu上进行训练/测试。
4.3 Comparing with SOTA on Abdominal Multi-organ Segmentation(与SOTA在腹部多器官分割上的比较)

在评价指标上:在表中,可以看到,在仅使用1点提示的情况下,Med-SA比SAM有显著的改进。值得注意的是,在BTCV数据集上,单点Med-SA在所有12个器官上都达到了SOTA性能,在整体性能上超过了其他方法。随着我们提供更细粒度的提示,结果继续改进,最终结果为89.8%,BBox为0.75。这一结果比以前的SOTA(Swin-UNetr)高出2.9%的显著优势。
在更新参数上:值得注意的是,Swin-UNetr包含138M个可调参数,而我们只更新了13M个参数。令人惊讶的是,我们甚至在所有即时变化上都超过了完全微调的MedSAM模型。使用建议的SD-Trans和Hyp-Adpt,我们的性能优于MedSAM,只更新了其总可调参数(13M V.S.636M)的2%,这突显了建议技术的有效性。
4.4 Comparing with SOTA on Multi-modality Images(在多模态图像上与SOTA算法进行了比较)
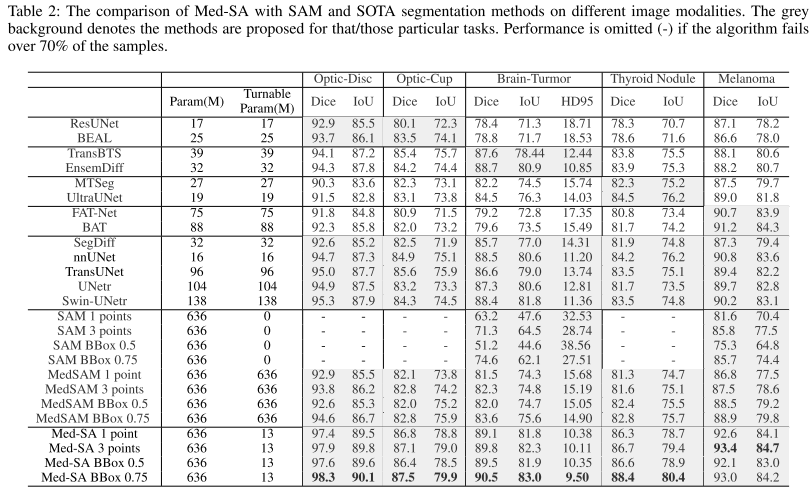
MED-SA在所有分割任务中实现了SOTA性能,展示了其推广到各种医学分割任务和图像模式的能力。在广泛使用的BRATS基准上,由于对3D图像的适应性,MedSA在dice得分和HD95度量方面比以前的Sota Swin-UNetr高出2.1%和1.86,同时利用了不到10%的可调参数。
4.5 Ablation Study

消融方法:SAM和原始自适应方法的简单组合。
3D转换模块消融: 在基线设置中,3D图像被视为2D图像序列并单独处理,不涉及适应过程中的提示。如表所示,在两个3D数据基准(BTCV和BrainTumor)上,本文的2D到3D设计显著提高了性能,而不是普通的SAM加适应设置。这一改进突出了我们建议的2D到3D设计的有效性。
适应器模块消融:在提示-条件适应中,比较了Hyp-adpt和两种更简单的选择:加法和拼接,以结合提示嵌入。虽然加法和级联也显示出一些有效性,但所取得的改进仍然微乎其微。另一方面,使用提出的Hyp-adpt可以显著提高性能,进一步验证了我们提出的Hyp-adpt设计的有效性。
五、结论
主要工作:本文扩展了SAM,一个强大的通用分割模型,以解决医学图像分割问题,提出了Med-SA。利用简单而有效的SD-Trans和HyPAdpt的参数高效适应,实现了对原始SAM模型的实质性改进。
实验效果:本文的方法已经在跨越5种不同图像模式的17个医学图像分割任务中产生了SOTA性能。
展望:预计,这项工作将成为推进基础医学图像分割的垫脚石,并激励新的微调技术的发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











