







论文:https://arxiv.org/abs/1903.06586?context=cs
源码:GitHub - implus/SKNet: Code for our CVPR 2019 paper: Selective Kernel Networks
目录
SKNet是SENet的加强版,是attention机制中的与SE同等地位的一个模块,可以方便地添加到现有的网络模型中,对分类问题,分割问题有一定的提升。
一、论文出发点
在神经科学界,众所周知,视觉皮层神经元的感受野大小受刺激的调节,这在构建CNN时很少被考虑。作者设计一个叫做选择性核(SK)单元的构件,其中具有不同核大小的多个分支在这些分支的信息指导下,使用softmax注意力进行融合。对这些分支的不同关注产生了融合层中神经元的有效感受野的不同大小。
引用博文(SKNet)Selective Kernel Network 解析 - 知乎中的一句话:虽然在此之前,自适应感受野大小的机制还没有人提出,或者说很少被考虑到。但是有一点是存在共识的,那就是结合不同感受野大小能够提升神经元的适应能力。
二、论文主要工作
1.提出了一种非线性方法的聚合方法,从多个内核中聚合信息,实现神经元的自适应RF大小。
2.引入了 “选择性内核”(SK)卷积,它由三组运算符组成。分裂、融合和选择。
三、SK模块的具体实现
SK模块的整体结构图:
在该例中,只有两个分支,但是实际上是可以扩展到多个分支的情况。
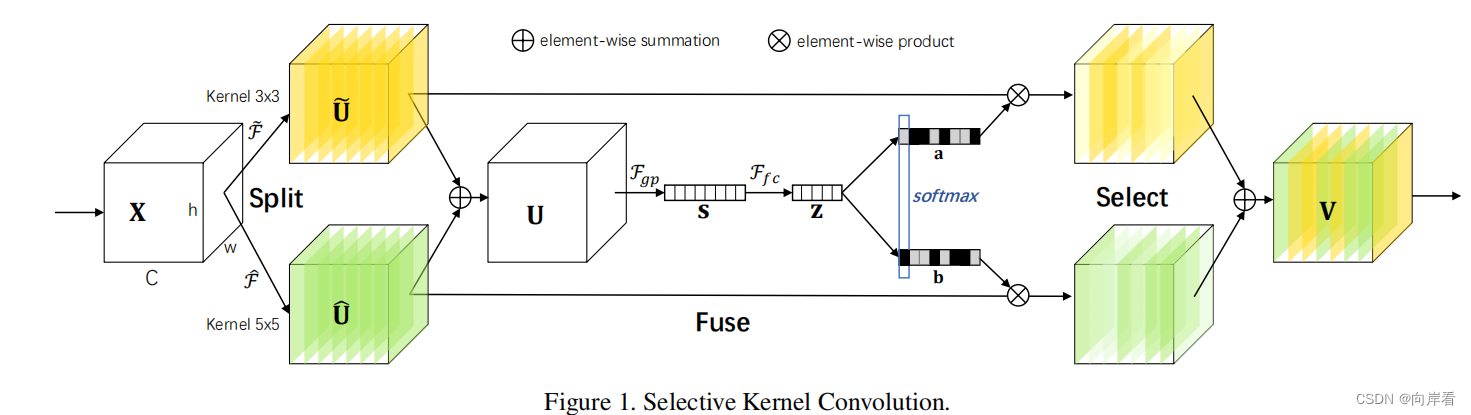
主要通过三个运算符实现 SK 卷积——Split、Fuse 和 Select。
1. Split
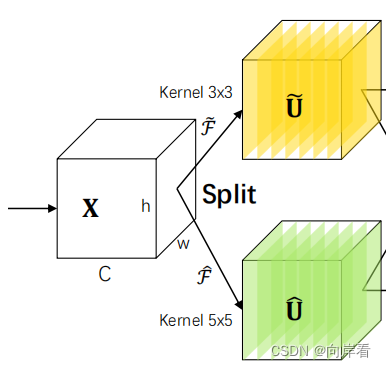
对输入的特征图,分别进行两次卷积变换
、
。
(1):
过程中卷积核大小为3x3,特征图X经过卷积变换为
。
(2):
过程中卷积核大小为5x5,特征图X经过卷积变换为
。
特征图X经过Split操作,输出两个新的特征图、
。
2. Fuse
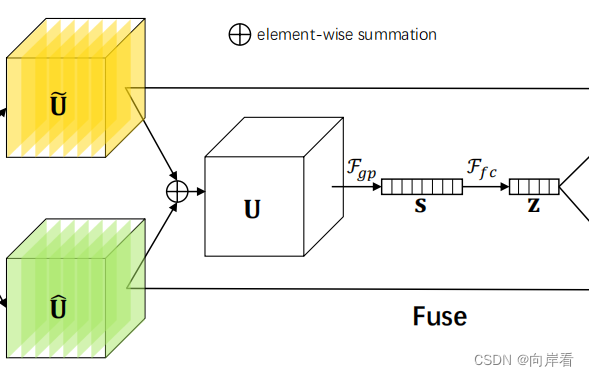
目的:使神经元能够根据刺激内容自适应地调整其RF大小,因此需要使用门来控制来自多个分支的信息流,这些分支携带不同规模的信息进入下一层的神经元。
方法:使用门整合来自所有分支的信息,也就是将来自多个分支的特征进行融合。
步骤:
(1):特征图
、
相加,得到新的特征图U,U中融合了多个感受野的信息。
(2):U通过全局平均池化生成
来嵌入全局信息,
是一个有C个元素的列向量。对应的算子公式如下:
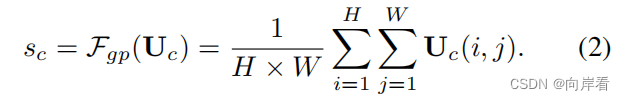
通过将U的第C个feature map缩小空间尺寸H×W来计算得到s的第C个元素。
(3):通过一个简单的全连接 (fc) 层,将向量s压缩为特征向量
。对应的算子公式如下:
![]()
δ是ReLU函数,表示批量归一化,
为权重矩阵。
很明显这里,向量s先是通过了一个全连接层将c个通道变成d个,减少参数量,再经过批量归一化函数,最后通过ReLU函数得到特征向量z。
(4)论文中还研究了 d 对模型效率的影响,其算子公式如下
![]()
这里C/r,可以看出SENet论文的痕迹,目的与SENet论文中的一致,因为一个全连接层无法同时应用relu和sigmoid两个非线性函数,但是两者又缺一不可。为了减少参数,所以设置了r比率。
3. Select
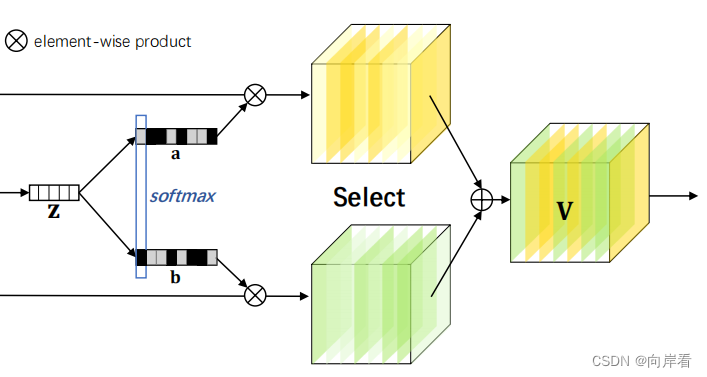
目的:在紧凑的特征描述符z的引导下,利用跨通道的软注意来自适应地选择不同的信息空间尺度。
方法:softmax 运算符应用于通道数,得到各分支上特征图的软注意力向量。这里的特征图示例为、
,因此得到软注意力向量为
、
的软注意力。
步骤:
(1)分别两次对特征向量z使用softmax函数得到软注意力向量 ,这时向量中的每一个数值对应一个channel的分数,代表其channel的重要程度,同时将
再次变回了c个维度,这里又可以看出SENet论文的痕迹。算子公式如下:
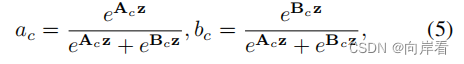
其中,
分别表示
和
的软注意力向量。请注意,
是
的第 c行,
是
的第c个元素,
和
也是如此。
(2)各特征图与对应的注意力权重相乘,再相加,最终得到特征图。
![]()
其中,
。
这个特征图V是通过各种内核上的注意力权重获得的,融合了多个感受野的信息,具有了多尺度的信息。
关于特征图V最终达到的效果,这里博文【CV中的Attention机制】SKNet-SENet的提升版 - 知乎总结比较好,需要进一步理解,可参考。
四、实验
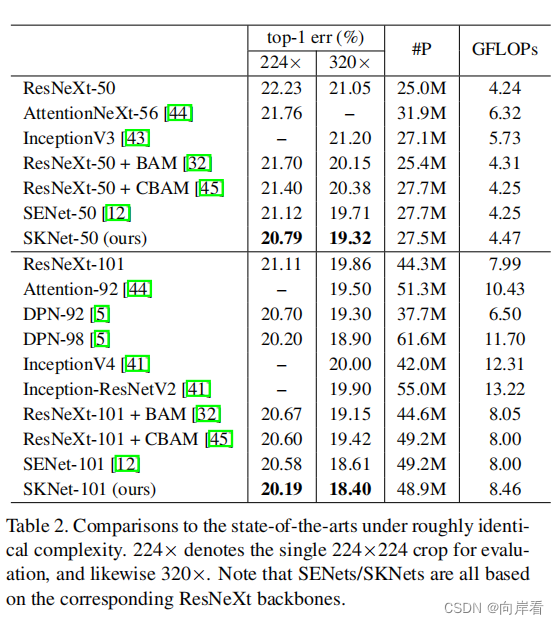
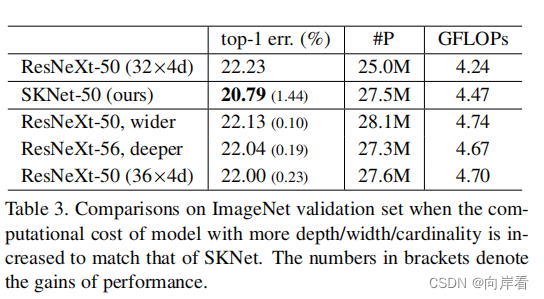
五、总结
在SKNet中可以看到许多SE模块的痕迹,总的来说SK模块先是通过不同的卷积核将输入特征图进行划分为几个不同的子特征图,再将子特征图相加融合,再经过压缩和softmax处理,得到各种内核上的注意力权重,再与对应子特征图相乘,再相加得到最终的输出特征图V,这个特征图既融合了多个感受野的信息,具有了多尺度的信息。
六、代码实现
1.SK卷积
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1, L=32):
""" Constructor
Args:
features: 输入通道维度
WH: 输入特征图的空间维度
M: 分支的数量
G: 卷积组的数量
r: 计算d,向量s的压缩倍数,C/r
stride: 步长,默认为1
L: 矢量z的最小维度,默认为32
"""
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
# 使用不同kernel size的卷积,增加不同的感受野
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3 + i * 2, stride=stride, padding=1 + i, groups=G),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
# 全局平均池化
self.gap = nn.AvgPool2d(int(WH / stride))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
# 全连接层
for i in range(M):
self.fcs.append(
nn.Linear(d, features)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
''' Split操作'''
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
''' Fuse操作'''
fea_U = torch.sum(feas, dim=1)
fea_s = self.gap(fea_U).squeeze_()
fea_z = self.fc(fea_s)
''' Select操作'''
for i, fc in enumerate(self.fcs):
# fc-->d*c维
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector], dim=1)
# 计算attention权重
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
# 最后一步,各特征图与对应的注意力权重相乘,得到输出特征图V
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v2.SKNet完整源码
SKConv替代了ResNext中3*3卷积部分,用两个或多个不同卷积核大小的卷积操作加学习通道权重全连接层替代。
import torch
from torch import nn
# conv = SKConv(64, 32, 3, 8, 2)
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1, L=32):
""" Constructor
Args:
features: 输入通道维度
WH: 输入特征图的空间维度
M: 分支的数量
G: 卷积组的数量
r: 计算d,向量s的压缩倍数,C/r
stride: 步长,默认为1
L: 矢量z的最小维度,默认为32
"""
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
# 使用不同kernel size的卷积,增加不同的感受野
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3 + i * 2, stride=stride, padding=1 + i, groups=G),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
# 全局平均池化
self.gap = nn.AvgPool2d(int(WH / stride))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
# 全连接层
for i in range(M):
self.fcs.append(
nn.Linear(d, features)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
''' Split操作'''
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
''' Fuse操作'''
fea_U = torch.sum(feas, dim=1)
fea_s = self.gap(fea_U).squeeze_()
fea_z = self.fc(fea_s)
''' Select操作'''
for i, fc in enumerate(self.fcs):
# fc-->d*c维
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector], dim=1)
# 计算attention权重
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
# 最后一步,各特征图与对应的注意力权重相乘,得到输出特征图V
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
class SKUnit(nn.Module):
def __init__(self, in_features, out_features, WH, M, G, r, mid_features=None, stride=1, L=32):
""" Constructor
Args:
in_features: 输入通道维度
out_features: 输出通道维度
WH: 输入特征图的空间维度
M: 分支的数量
G: 卷积组的数量
r: 计算d,论文中向量s的压缩倍数,C/r
mid_features: 步长不为1的中间卷积的通道维度,默认为out_features/2
stride: 步长,默认为1
L: 论文中矢量z的最小维度,默认为32
"""
super(SKUnit, self).__init__()
if mid_features is None:
mid_features = int(out_features / 2)
self.feas = nn.Sequential(
nn.Conv2d(in_features, mid_features, 1, stride=1),
nn.BatchNorm2d(mid_features),
# SKConv替代了ResNext中3*3卷积部分
SKConv(mid_features, WH, M, G, r, stride=stride, L=L),
nn.BatchNorm2d(mid_features),
nn.Conv2d(mid_features, out_features, 1, stride=1),
nn.BatchNorm2d(out_features)
)
if in_features == out_features: # when dim not change, in could be added diectly to out
self.shortcut = nn.Sequential()
else: # when dim not change, in should also change dim to be added to out
self.shortcut = nn.Sequential(
nn.Conv2d(in_features, out_features, 1, stride=stride),
nn.BatchNorm2d(out_features)
)
def forward(self, x):
fea = self.feas(x)
return fea + self.shortcut(x)
class SKNet(nn.Module):
def __init__(self, class_num):
super(SKNet, self).__init__()
self.basic_conv = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.BatchNorm2d(64)
) # 32x32
self.stage_1 = nn.Sequential(
SKUnit(64, 256, 32, 2, 8, 2, stride=2),
nn.ReLU(),
SKUnit(256, 256, 32, 2, 8, 2),
nn.ReLU(),
SKUnit(256, 256, 32, 2, 8, 2),
nn.ReLU()
) # 32x32
self.stage_2 = nn.Sequential(
SKUnit(256, 512, 32, 2, 8, 2, stride=2),
nn.ReLU(),
SKUnit(512, 512, 32, 2, 8, 2),
nn.ReLU(),
SKUnit(512, 512, 32, 2, 8, 2),
nn.ReLU()
) # 16x16
self.stage_3 = nn.Sequential(
SKUnit(512, 1024, 32, 2, 8, 2, stride=2),
nn.ReLU(),
SKUnit(1024, 1024, 32, 2, 8, 2),
nn.ReLU(),
SKUnit(1024, 1024, 32, 2, 8, 2),
nn.ReLU()
) # 8x8
self.pool = nn.AvgPool2d(8)
self.classifier = nn.Sequential(
nn.Linear(1024, class_num),
# nn.Softmax(dim=1)
)
def forward(self, x):
fea = self.basic_conv(x)
fea = self.stage_1(fea)
fea = self.stage_2(fea)
fea = self.stage_3(fea)
fea = self.pool(fea)
fea = torch.squeeze(fea)
fea = self.classifier(fea)
return fea
if __name__ == '__main__':
# 随机生成8个(64,32,32)的特征图
x = torch.rand(8, 64, 32, 32)
conv = SKConv(64, 32, 3, 8, 2)
out = conv(x)
criterion = nn.L1Loss()
loss = criterion(out, x)
loss.backward()
# 最终输出特征图V的size和损失值
print('out shape : {}'.format(out.shape))
print('loss value : {}'.format(loss))


















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











