






题目:SegRefiner:Towards Model-Agnostic Segmentation Refinement(面向模型无关的分割细化) with(使用) Discrete Diffusion Process(离散扩散过程)
论文(NeurIPS会议):SegRefiner: Towards Model-Agnostic Segmentation Refinement with Discrete Diffusion Process
一、摘要
主要工作:本文探索了一种增强不同分割模型产生的物体掩模分割质量的主要方法。
- 出发点/动机:本文提出一种与模型无关的解决方案,称为SegRefiner,通过将分割细化解释为数据生成过程,为这个问题提供了一个新的视角。因此,细化过程可以通过一系列的去噪扩散步骤顺利地实现。
- 实现过程:具体来说,SegRefiner将粗糙的掩模作为输入,并使用离散扩散过程对其进行细化。通过预测每个像素的标签和相应的状态转移概率,SegRefiner以条件去噪的方式逐步细化噪声掩模。
实验效果:为评估separfiner的有效性,在各种分割任务上进行了全面的实验,包括语义分割、实例分割和二分图像分割。实验结果从多个方面证明了 SegRefiner 的优越性。首先,它不断提高不同类型粗糙掩模的分割指标和边界指标。其次,它明显优于之前的模型无关的细化方法。最后,在细化高分辨率图像时,它表现出强大的捕捉极精细细节的能力。
分割细化任务:这是在图像分割领域中的一个子任务,分割细化任务的目标是对这些初始分割结果进行精确的修正,以获得更准确的分割结果。
二、引言
研究背景(获得准确和详细的分割掩码有哪些挑战;造成分割精度下降有哪些原因)—> 研究方向(1. 特定于模型的,不可适用于其他模型 2. 模型不可知的方法,适用于细化不同的分割模型)
—> 设计启发(扩散模型通过每一步去噪,逐步逼近图像分布。而这种策略应用到分割细化任务中,细化模型可以专注于纠正每一步中的一些最明显的错误,并迭代地收敛到准确的结果)—>
改进工作(将粗分割掩码视为噪声版本的 ground truth ,通过一系列去噪扩散步骤来实现细化。设计了一种新的离散扩散过程。)—> 主要工作:
- 1. 第一个为分割掩码引入基于扩散的细化的。所提出方法称为 SegRefiner,与模型无关,因此适用于不同的分割模型和任务。
- 2. 广泛分析了SegRefiner在各种分割任务中的性能,证明了所提出的SegRefiner不仅优于所有之前的模型无关的细化方法(在语义分割中+3.42 IoU, +2.21 mBA,在实例分割中+0.9掩码AP, +2.2边界AP),而且还可以毫不费力地转移到其他分割任务(例如,最近提出的二值图像分割任务),而不需要任何修改。此外,当应用于高分辨率图像时,SegRefiner 展示了捕捉极精细细节的强大能力。
三、方法
3.1 Preliminaries: Diffusion Models(预备知识:扩散模型)
- Continuous Diffusion Models(连续扩散模型)
现有的大多数连续扩散模型都遵循高斯假设,定义了 。正向过程的均值和方差由超参数βt定义,而反向过程利用模型预测的均值和方差,从而表示为:
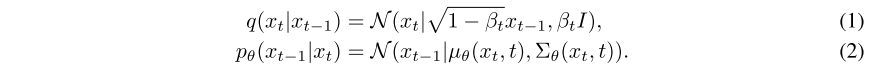
- Discrete Diffusion Models (离散扩散模型)
与连续扩散模型相比,对离散扩散模型的研究较少。首先引入二进制扩散重建一维含噪二进制序列。 定义为服从伯努利分布
。正向过程和反向过程表示为:
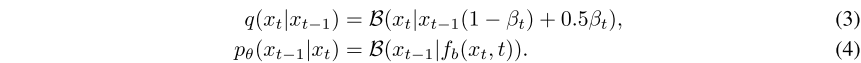
其中, 是超参数,
是预测伯努利概率的模型。
- Austin et al. 的推广(将离散扩散模型的体系结构推广到更一般的形式)
更通用的模式,将正向过程定义为多个状态之间的离散随机变量转移,并使用状态转移矩阵 来表征该过程:
![]()
3.2 SegRefiner
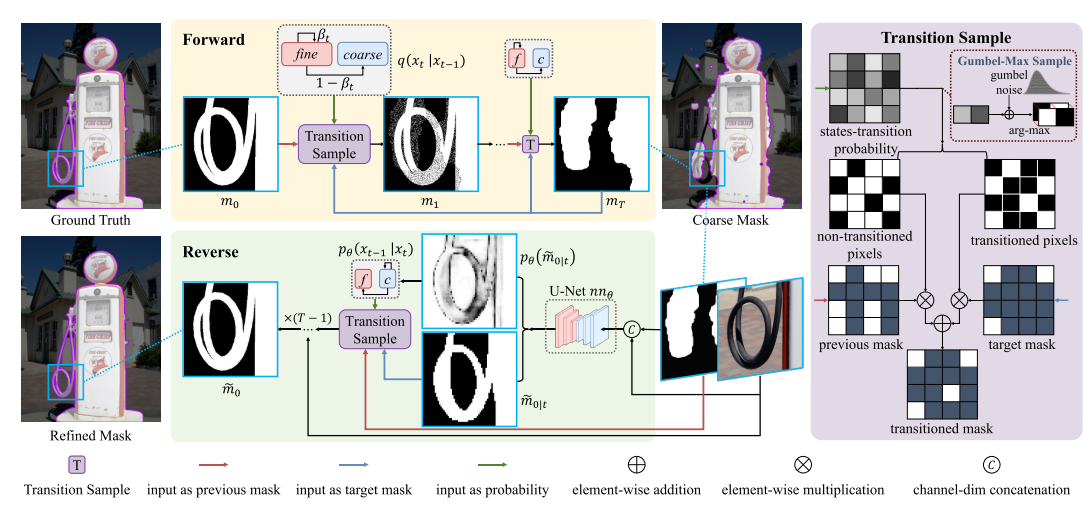
主要工作:在这项工作中,本文提出了具有独特离散扩散过程的SegRefiner,可用于从各种分割模型和任务中提炼粗掩码。SegRefiner 通过由粗到细的扩散过程进行细化。
主要过程:在正向扩散过程中,该算法采用单向随机状态转换的离散扩散过程,使真值掩码逐渐退化为粗糙掩码 。在相反的过程中,SegRefiner 从一个提供的粗掩码开始,并逐渐将粗掩码中的像素转换为细化状态,纠正粗掩码中错误预测的区域。
3.2.1 Forward diffusion process(前向扩散过程)
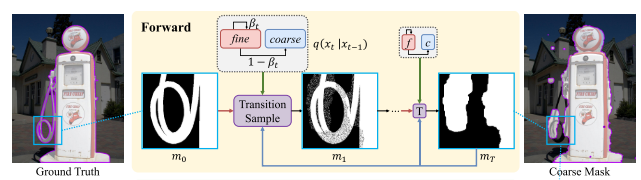
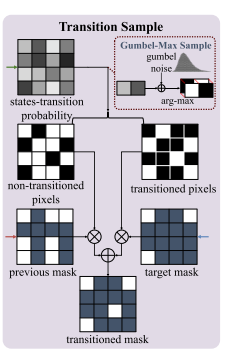
在正向处理过程中,逐渐将 真值掩码 / 精细掩码 退化为粗糙掩码
。换句话说,有
和
。在任意中间时间步 t ∈ {1,2,…, T−1} ,中间掩模
都处于
和
之间的过渡阶段。
方法:本文定义 中的每个像素都有两种状态:fine(精细)和 coarse(粗糙),因此正向过程被表述为这两个状态之间的状态转换。处于精细状态的像素将保留它们在
中的值,反之亦然。本文提出一种新的 Transition Sample (过渡样本) 模块 来制定这一过程。
过程:在正向过程中,Transition Sample (过渡样本) 模块 将前一个 掩码 、粗掩码
和 状态转移概率 作为输入,输出一个转移掩码
。状态转移概率 描述了
中每个像素过渡到粗状态的概率。
- 1. 该模块首先根据状态转移概率对进行Gumbel-max采样,获得 transitioned pixels(状态转移像素);
- 2. 然后,transitioned pixels(经过转换的像素)将从
中获取值,而 non-transitioned pixels(未转换的像素)将保持不变。
Q:Gumbel-max 采样
A:在处理离散变量时,一个经典的问题是如何从给定的概率分布中进行采样。Gumbel-Max技巧提供了一种解决办法,它通过引入Gumbel噪声来模拟离散分布的最大值采样。具体来说,我们先从Gumbel分布中为每个可能的状态生成一个随机数,然后选择对应最大随机数的那个状态。这样我们就得到了一个符合原始离散分布的样本。
前向扩散过程公式表达:
通过重新参数化技巧,本文引入一个二元随机变量 x 来表述上述过程。将 表示为一个one-hot向量,以表示
中像素 (i, j) 的状态,集合
和
分别表示精细状态和粗糙状态。因此,正向过程可以表述为:
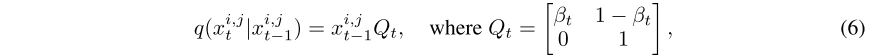
其中 和
对应于转移样本模块中使用的 状态转移概率 。
是一个状态转移矩阵。marginal distribution (边缘分布) 可以表示为:
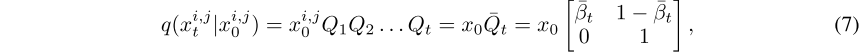
其中, 。鉴于此,可以在任何中间时间步t获得中间掩码 mt,而不需要逐步采样 q(xt | xt−1),从而允许更快的训练。 (本质上还是高斯扩散模型的前向过程,只是用状态转移矩阵表示)
3.2.2 Reverse diffusion process(反向扩散过程)
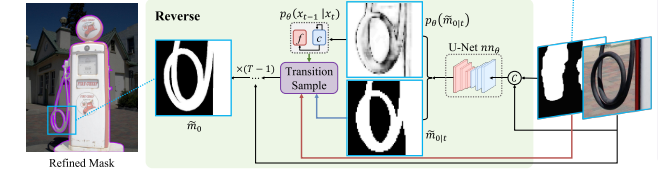
反向扩散过程采用粗掩码mT,并逐渐将其变换成精细掩码m0。然而,由于精细掩码m0和反转状态转移概率是未知的,依照DDPM,本文训练由 θ参数化的神经网络 fθ 来预测每个时间步的精细掩码 ,表示为:
![]()
其中i是对应的图像。 和
分别表示预测的二进制精细掩码及其置信度分数。根据公式求出反向转移概率,首先将时间步长 t−1 的后验公式表示为:
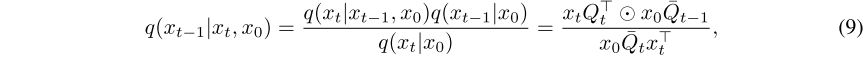
(DDPM反向推理公式代入)
其中,精细状态x0在训练期间设置为[1,0],表示ground truth。
问题1:在推断期间,x0是未知的,因为预测的 可能不是完全准确的。
解决方法:由于置信度分数 代表了模型对每个像素预测正确的确定性水平,因此
也可以解释为处于精细状态的概率。因此,直观地,通过简单的阈值化来获得
中每个像素的状态:
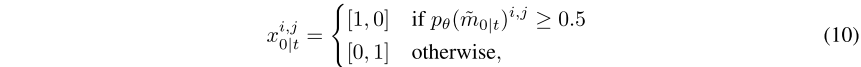
(简单理解,因为ground truth是二值化的并且扩散反向过程的预测可能不是完全准确的,因此直接对预测值进行阈值化来提高精度)
其中,具有较高置信度分数的像素具有 ,表示它们处于精细状态,反之亦然。
问题2:然而,在这种 one-hot 形式中,状态转移概率的值仅由预定义的超参数决定,导致了显著的信息损失。(这里的超参数是指,固定值)
解决方法:因此,本文保留了软过渡并制定 。有了这种设置,反向扩散过程可以重新表述为
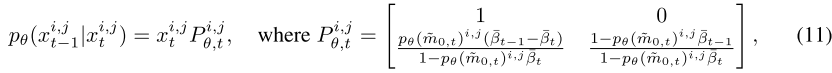
其中, 是反向状态转移矩阵。以上述反向状态转移概率、
和
作为输入,Transition Sample (过渡样本) 模块可以在每个时间步将一部分像素传输到精细状态,从而纠正错误的预测。
如下图所示,SegRefiner的推理过程的可视化示例:

和
分别表示状态和相应的掩码(在该图中将状态 [0,1] 和 [1,0] 表示为 0 和 1,即背景和前景)。
四、实验
4.1 Implementation Details(实验细节)
模型体系结构:使用U-Net作为去噪网络。修改U-Net以接受4通道的输入(图像和相应掩码mt的连接)并输出1通道的精细掩码。输入和输出分辨率都设置为256×256。
目标函数:使用二进制交叉熵损失和纹理损失相结合的方法来训练本文的模型,即 ,其中纹理损失被表征为预测掩码和ground truth掩码的分割梯度幅度之间的 L1 损失。α设置为5,以平衡这两个损失的幅度。
噪声调度:从理论上讲,SegRefiner的单向性保证了任何噪声调度都可以使前向过程收敛到给定无限时间步的粗掩码。然而,在实践中,使用更少的时间步(T=6)来确保有效的推理。指定,使得所有像素的
,并且
。依照DDIM,本文直接在βt上设置从0.8到0的线性噪声调度。
训练策略:SegRefiner模型已经发展成两个版本,用于细化不同分辨率的图像:低分辨率变体(以下称为LR-SegRefiner)和高分辨率变体(以下称为HR-SegRefiner)。LR-SegRefiner在LVIS数据集上训练,而HR-SegRefiner在从两个高分辨率数据集DIS5K和ThinObject-5K合并的复合数据集上训练。用于训练的粗掩码是通过各种形态操作得到的,例如随机扰动ground truth数据的一些边缘点,进行膨胀、侵蚀等。在训练过程中,首先在低分辨率数据集上训练LR-SegRefiner,直到收敛。随后,在高分辨率数据集上进行微调,以产生HR-SegRefiner。
数据增强:采用了双随机剪裁作为主要的数据增强技术。
实验设备:所有实验均在8台NVIDIA RTX 3090上进行。
4.2 Semantic Segmentation(语义分割)
数据集和指标:本文报告了在 BIG 数据集上的结果,BIG 数据集是专门为高分辨率图像设计的语义分割数据集。该数据集的分辨率从2048×1600到5000×3600,为评估精化方法提供了一个具有挑战性的试验台。使用的度量是标准分割度量IOU和边界度量MBA(平均边界精度),这是在以前的细化工作中常用的。

- 对比网络:本文将所提出的SegRefiner与三种与模型无关的语义分割精化方法SegFix、CascadePSP和CRM进行了比较。此外,还包括细粒度遮片方法MGMatting,它使用图像和掩码进行遮片,也可以用于细化目的。
- 实验结果:当使用来自四个不同语义分割模型的粗掩码时,所提出的SegRefiner表现出比以前的方法更好的性能,这在IOU和MBA指标中都很明显。值得注意的是,本文的SegRefiner优于专门为超高分辨率图像设计的CRM,展示了重大的进步。
- 稳定性报告:由于 BIG 数据集(由100个测试图像组成)的大小相对较小,在此实验中报告了误差条(±灰色)。误差条表示五次试验结果的最大波动值,表1中的结果为五次试验结果的平均值。在随后的实验中,大量的测试图像的可用性保证了结果的稳定性。
4.3 Instance Segmentation(实例分割)
数据集和指标:为了评估SegRefiner在细化实例分割方面的有效性,选择了广泛使用的带有LVIS注释的COCO数据集。评估指标为掩码AP和边界AP。边界AP度量是衡量预测模板边界质量的有价值的评价指标,对边缘预测的准确性高度敏感。它提供了对精细掩码捕捉对象边界的程度的详细评估。
实验设置:在这个实验中,本文使用了LR-SegRefiner模型。为了细化每个实例,根据粗略的掩码提取边界框区域,并将其每边扩展20个像素。然后调整提取区域的大小以匹配模型的输入大小。输出大小适合于COCO数据集中的实例,允许在所有时间步执行实例级精化,而不需要任何局部补丁精化。
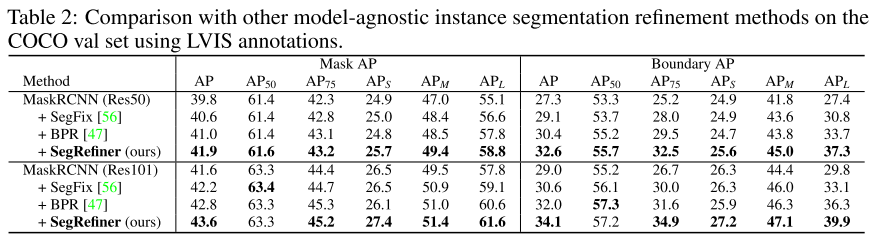
对比网络:将所提出的SegRefiner与两种模型无关的实例分割细化方法BPR和SegFix进行了比较。PointRend、RefineMask和Mask TransFiner。
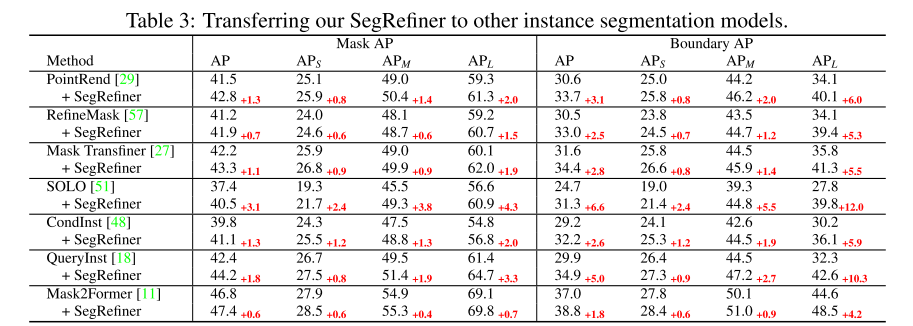
实验结果:如表2所示,与这两种方法相比,SegRefiner 取得了明显更好的性能。为保证与原始实验的一致性,使用的粗掩码由Mask R-CNN得到。然后在表3中,将 SegRefiner 应用于其他7个实例分割模型。该方法在不同性能水平的模型中产生了显著的增强。与PointRend、RefineMask和Mask TransFiner三种特定于模型的实例分割细化模型相比,所提出的模型始终提高了它们的性能。
4.4 Ablation Study (消融实验)
数据集:在具有高分辨率图像的 BIG 数据集上进行了消融研究。
消融策略:a. 丢弃Transition Sample (过渡样本) 模块 b. c. 评估了使用的各种替代方案(全局细化、局部细化和输入尺寸)
消融结果:a. 证明了基于扩散的迭代过程取得了最好的性能,验证了SegRefiner中扩散过程的有效性。
b. 可以看出,全局细化显著提高了IoU;然而,对于高分辨率图像,由此产生的较小输出尺寸导致较低的mBA。对原始大小的局部块进行局部细化,可以极大地提高mBA,而IoU由于缺乏全局信息,其增强效果不明显。局部和全局细化的结合在IoU和mBA中取得了更好的性能。
c. 给出了不同输入图像大小对应的结果。考虑计算量和内存使用情况,默认选择256 × 256,在不引入过多计算开销的情况下,性能较好。

五、结论
主要工作:本文提出了SegRefiner,这是第一种基于扩散的图像分割细化方法,它使用了新设计的离散扩散过程。SegRefiner 执行模型无关的分割精化,并在各种分割任务的精化方面取得了很强的经验结果。
不足:虽然 SegRefiner 在精度方面取得了显著的提高,但其局限性在于扩散过程导致推理速度变慢,这是由于多步迭代策略。本文对实例分割进行了实验,研究了模型的精度、计算复杂度、时间消耗(每张图像消耗的平均时间)和迭代步数之间的关系。可以观察到,虽然迭代策略在精度上有了明显的提高,但它在时间消耗和计算复杂度方面也随着步数的增加而线性增加。
展望:作为将扩散模型应用于精化任务的首次工作,所提出的模型主要致力于为一般的精化任务设计一个合适的扩散过程。而提高扩散模型的效率将是未来一个重要的研究方向,不仅在图像生成领域,在其他应用扩散模型的领域也是如此。
















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











