







老师让我帮他出卷哈,就自己做了细纲出了点题。可以参考着复习。
考点:
1.个体与集成(选择、填空)
集成学习概念、个体学习器特点
2. Boosting(选择、填空、问答)
概念、AdaBoost算法流程
3. Bagging与随机森林(选择、填空、判断)
概念、特点及与其他学习方法的区别
4. 结合策略(选择、填空、判断、名词解释)
学习器结合的好处,平均法和投票法的特点
5.多样性(填空、判断)
误差-分歧分解的原理、多样性增强的几种方法
大题:归属于Boosting一族的AdaBoost算法流程图如下:

请回答如下几个问题。
1、填补第5行空缺的算法,并解释其含义
答案:ϵt>0.5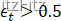 (4‘)
(4‘)
检查当前基分类器是否比随即猜测好(3‘)
2、第六行代码用于求得分类器的权重αt,请补充完整,并推导出αt的取值范围。

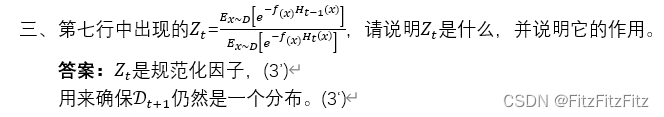
注意:AdaBoost算法的思想在于加大当前基学习器学习错误的样本在下一轮学习中的权重(图中的第7步),也因此能适应弱分类器各自的训练误差(也就是为什么叫做ada(adaptive自适应)-boost)。该算法最为巧妙的一点在于将样本权重调整和基学习器的权重结合起来了。算法的推导在p174-176。
这里我们在迭代基学习器时采用的是重赋权法,对于无法接受带权样本的基学习器,我们可以使用重采样(resampling)来处理。
从偏差-方差分解的角度来看,Boosting主要关注降低偏差。

















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











