







一、网页抓包
1、可知url、响应方式、爬虫结果的形式
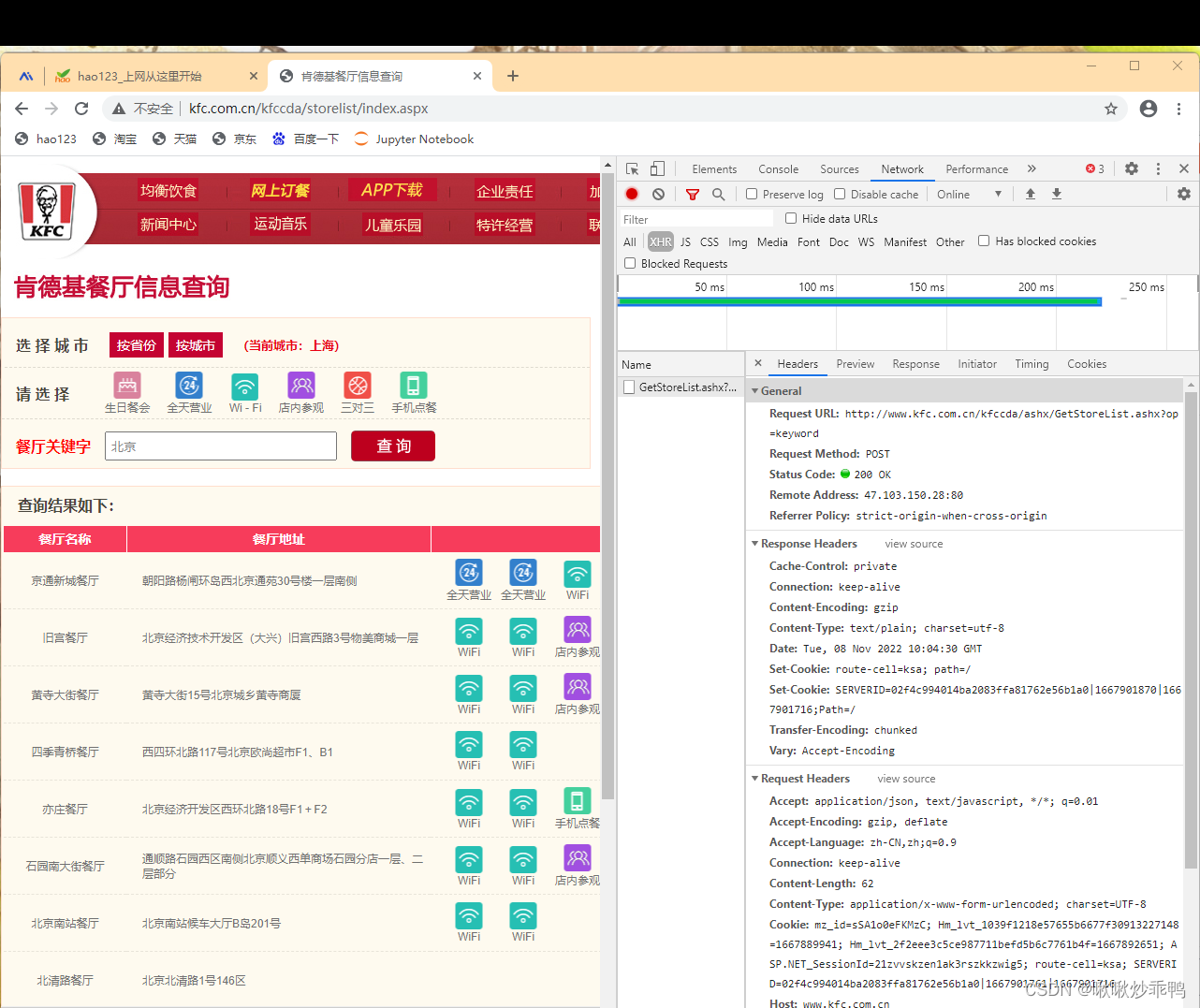
#指定url:
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求发送
response1 = requests.post(url=post_url, data=data, headers=headers)
#响应结果接收
text = response1.text2、可知爬虫参数信息
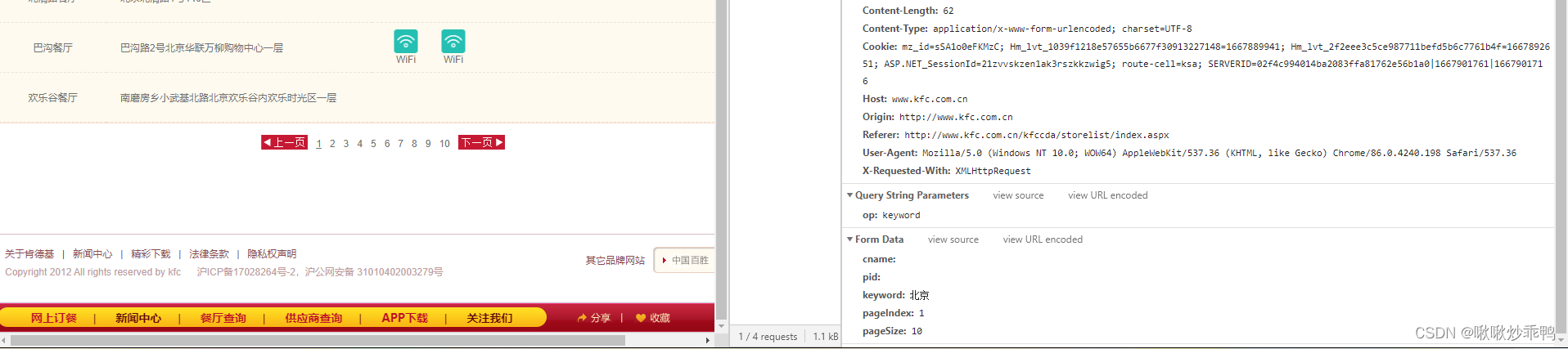
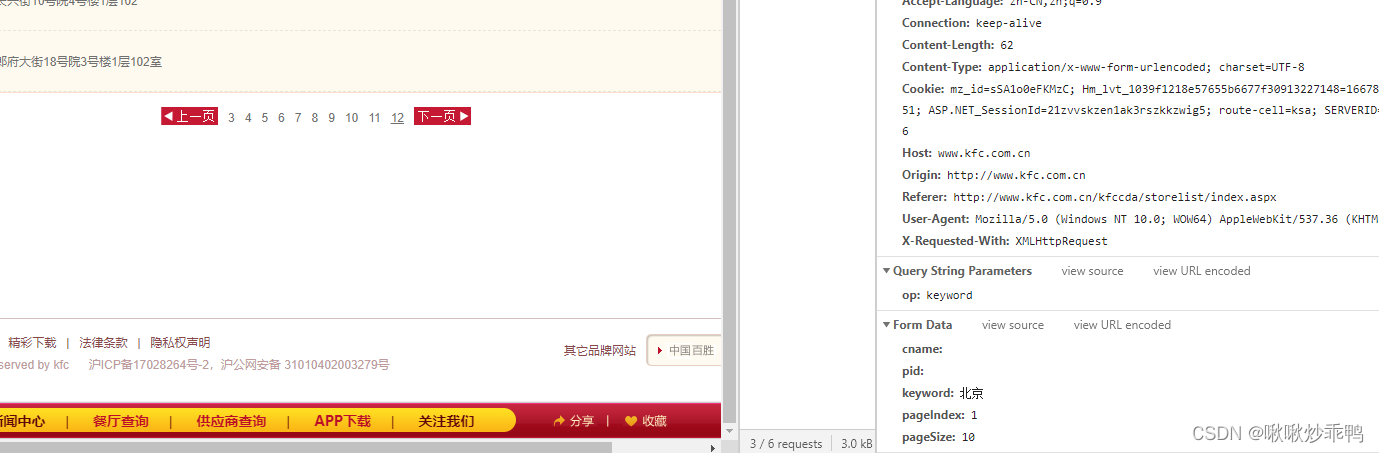
当前是第一页查询信息,一共有12页,
'pageIndex':当前是第几页
'pageSize': 每页有几条记录
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': 1,
'pageSize': '10'
}二、最终代码
难点主要在于确定页数进行循环。
#导包
import requests
import math
if __name__ == "__main__":
#指定url:
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求参数处理
kw = input('enter a query city:')
#第一次申请 解决页数不知道的问题
data = {
'cname': '',
'pid': '',
'keyword': kw,
'pageIndex': 1,
'pageSize': '10'
}
# 请求发送
response1 = requests.post(url=post_url, data=data, headers=headers)
text = response1.text
#{"Table":[{"rowcount":113}],"Table1":[{"rown 获取到的内容是这样的,是字典里面嵌套了一个列表,列表中又嵌套了一个字典
# 用eval将text转成字典
dictionary = eval(text)
# 取出[{"rowcount":113}] 是个只有一个元素的列表
table = dictionary['Table']
# 取出{"rowcount":113} 是个字典
dicts = table[0]
# 取出总查询条数,每页十条记录,所以除以十向上取整得出页数
number_page = math.ceil(dicts['rowcount']/10)
#正式记录
fileName = kw + '.txt'
file = open(fileName, "w", encoding='utf -8')
for i in range(1,number_page+1):
data ={
'cname':'',
'pid':'',
'keyword': kw,
'pageIndex': i,
'pageSize': '10'
}
# 请求发送
response = requests.post(url=post_url, data=data, headers=headers)
page_text = response.text
file.write(page_text)
file.close()
print('over!!!')
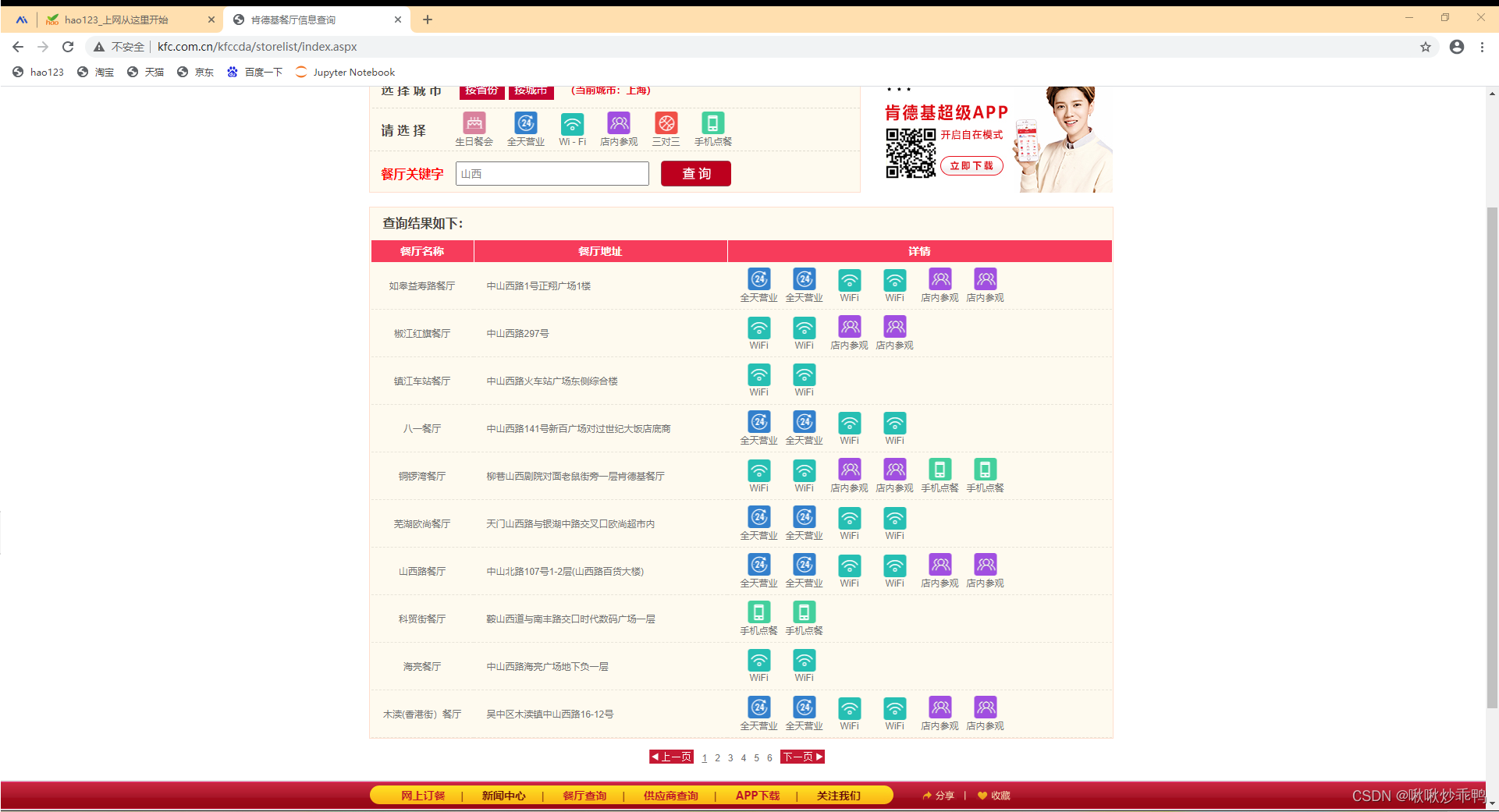
三、代码运行结果
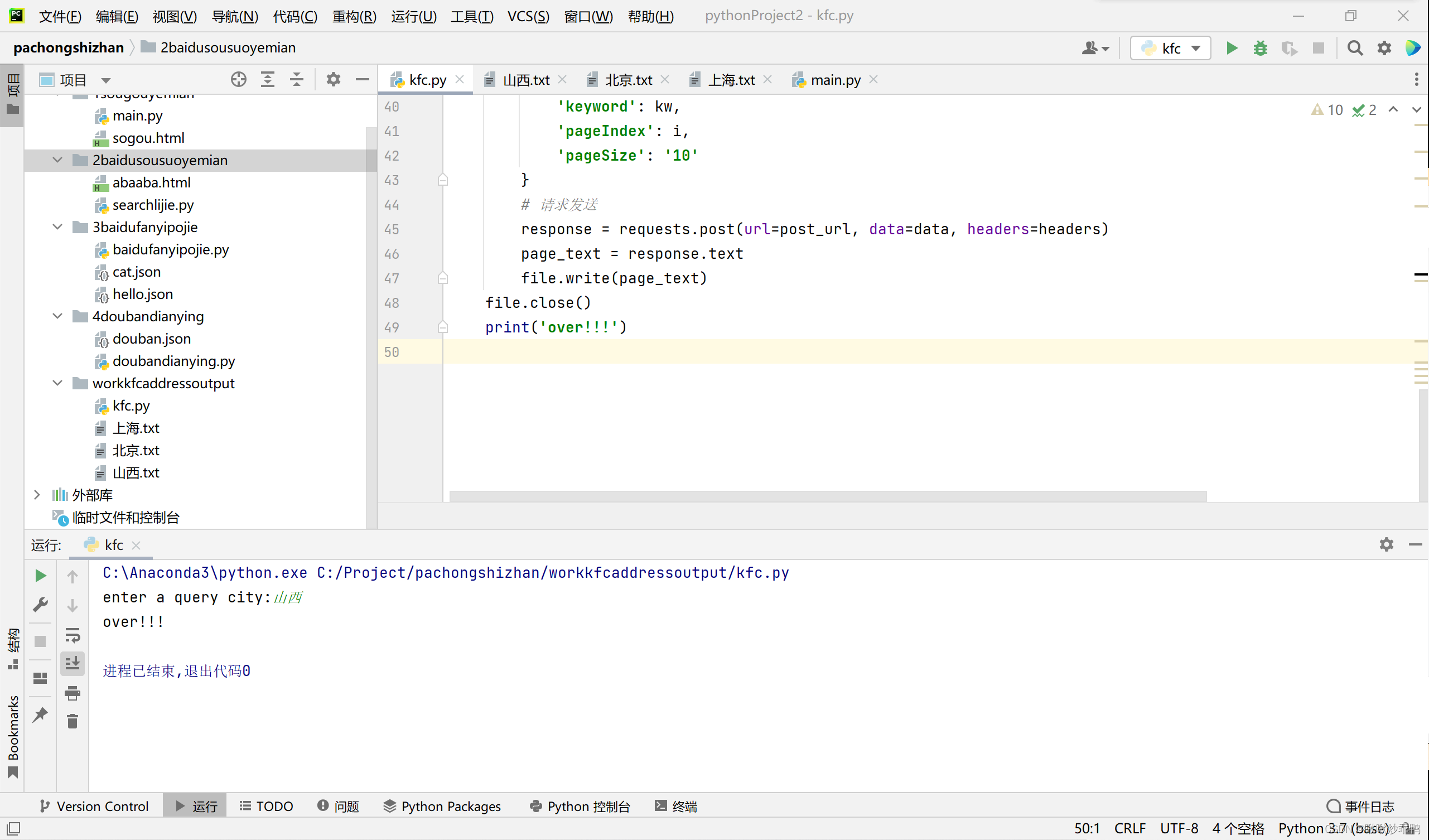

查看网页信息,与爬取的信息一致。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









