






1·Accelerating Federated Learning with Cluster Construction and Hierarchical Aggregation
模型权重与陈旧度有关
- 摘要:
- 提出了一种高效的FL机制FedCH,用于加速异构边缘计算中的FL。
- FedCH将构建一个特殊的簇拓扑结构,并对训练进行分层聚合。簇中的客户端将其本地更新同步转发到簇头进行聚合,而所有簇头采用异步方法进行全局聚合。
- 提出了有效的算法来确定资源预算的最佳集群数量,然后构造集群拓扑结构来解决客户端异构问题。
- 准备工作
- 梯度下降FL
- 设j表示训练样本,包括特征xj和标签yj。数据集D的损失函数为,w是模型向量,|D|是训练样本数,学习问题是找到最小化损失函数f(w)的最优模型向量w,表示为w *= arg min f(w)。
- 每个客户端将在每个本地更新中执行梯度下降以逐渐接近最优解。对于迭代t,局部更新规则描述如下:

- FedCH训练流程
- T是训练时期的总数,在每个时期中有一个全局聚合。令H表示本地更新的数目。
- 本地更新:客户端i 与基于局部数据集Dik的局部损失函数相关联,即,
 wik是集群k中客户端i的本地模型。
wik是集群k中客户端i的本地模型。 - 簇聚合:在H次迭代之后,本地模型转发到所选群首节点(表示为LNk)以进行聚合。簇聚合后的新模型定义为
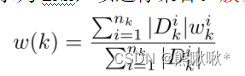
- 全局聚合:参数服务器接收到一个模型后立即执行全局聚合。通过陈旧性感知全局更新方法,服务器在t 时期更新全局模型wt。t个时期之后的全局损失函数F(wt)为
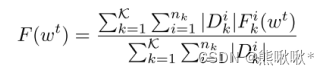
- 陈旧性感知全局更新
- 对于簇k,其陈旧度被定义为自其最后一次全局更新以来经历的迭代的数目。来自任意簇k的每个新接收的模型w(k)的权重将由τ确定,αtτ是w(k)在时间t的权重
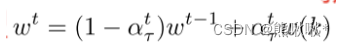
- 确定αtτ的值:
 α ∈(0,1)为初始模型权值,当τ〉a时,模型的权值随着陈旧度的增加而迅速下降。事实上,每个簇的模型权重会随着簇数目的增加而下降。将权值α初始化为α = φ(K)= 1 − (K−1 /N)。得到αt τ的表达式如下
α ∈(0,1)为初始模型权值,当τ〉a时,模型的权值随着陈旧度的增加而迅速下降。事实上,每个簇的模型权重会随着簇数目的增加而下降。将权值α初始化为α = φ(K)= 1 − (K−1 /N)。得到αt τ的表达式如下 
- 对于簇k,其陈旧度被定义为自其最后一次全局更新以来经历的迭代的数目。来自任意簇k的每个新接收的模型w(k)的权重将由τ确定,αtτ是w(k)在时间t的权重
- 梯度下降FL
2·BAFL:A Blockchain-Based Asynchronous Federated Learning Framework
权重与设备得分和旧模型权重有关
-
- 提高随机梯度下降 (SGD) 优化算法学习效率的最简单方法是确保每个设备并行迭代几轮,以改善参数估计。
- 之前的研究只考虑了同步场景,而不是异步场景,并且系统安全性不高。
- 同步FL中的问题在于上传时间仅与最慢的设备一样快。在异步FL中,本地模型在完成更新后立即上传,不会发生滞后。
- 本文将支持区块链的FL与异步FL相结合,提出了一种新的设备FL优化方法和权重指标。
- 系统模型
- 初始化
- 在本研究中,每个设备都分配了一个矿工,每个设备都必须确定自己的任务相关数据集大小,并将其上传到区块链系统以获得分数。
- 基于区块链的异步FL中的一个时代操作
- 1: 局部模型更新:局部训练的目标是最小化损失函数
 ,wi是本地模型,Si是其本地数据集。局部模型表示为
,wi是本地模型,Si是其本地数据集。局部模型表示为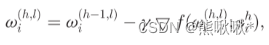 。
。 - 2:局部模型上传:将本地模型上传到矿工。
- 3: 局部模型的交叉验证:矿工将收到的本地模型写入新块,广播给其他矿工验证模型准确性并记录到新块。
- 4:模型和分数下载:设备从矿工下载当前全局模型、设备Di的局部模型、当前分数和更新的持续时间。
- 5: 全局模型和分数更新:(1)一次只能聚合一个局部模型。过程定义为:
 a (l )是新模型的权重(2)设备Di的新分数:每个设备使用设备Di的得分,设备Di的局部模型和全局模型来计算本轮设备Di的新得分
a (l )是新模型的权重(2)设备Di的新分数:每个设备使用设备Di的得分,设备Di的局部模型和全局模型来计算本轮设备Di的新得分 - 6: 全局模型和分数上传:设备都将新的全局模型和设备Di的新分数上传矿工。
- 7: 全局模型的交叉验证:所有设备上传的所有全局模型被广播到网络,所有矿工就比较模型的一致性,用最全局的模型作为正确的全局模型
- 8: 块生成:计算出低于目标值的哈希值的矿工将生成一个块。
- 9: 块传播:多个矿工同时发现随机数时,就会发生分叉。操作将返回到步骤8
- 10: 全局模型下载
- 1: 局部模型更新:局部训练的目标是最小化损失函数
- 设备有效性评估
- 设备得分计算
- sk i是Di设备k指标的归一化值。计算sk i的比例:

- sk i是Di设备k指标的归一化值。计算sk i的比例:
- 设备得分计算
- 初始化
k =1表示数据大小指标,k = 2表示设备Di的历史分数,k = 3表示全局模型更新期间的错误数量,k = 4表示局部模型更新与全局模型更新之间的相关性。
-
-
-
- 指标k的熵权为

- 设备得分:

- 指标k的熵权为
- 牛顿冷却定律的权重
- 在异步FL中,每个设备的上载定时是不确定的。较长的局部训练时间会导致局部模型过期,从而降低全局模型的精度。使用牛顿冷却定律来调整全局模型聚集中旧模型的权重。
- R(t)与θ有关,θ衰减系数越大,训练时间长的模型在全局模型中的比例越小。
- 局部模型在全局模型中的权重:

-
-
3.BAFL:An Efficient Blockchain-Based Asynchronous Federated Learning_ Framework
缩放因子被设计为平衡全局模型和局部模型之间的权重。
设计了一个动态比例因子,用于减轻来自滞后器件的影响、
-
- FL框架通过智能合约部署在节点上
- 缩放因子被设计为平衡全局模型和局部模型之间的权重。
- BSFL:与BAFL相同,不同之处在于学习过程是同步的,比例因子设置为恒定值,即0.75。
- APFL:一种半异步联邦学习方法,通过在学习过程中利用局部和全局模型之间的相关性来训练模型[8]。在没有区块链的情况下,节点之间的通信周期被设置为10次迭代。
- FedAVG:没有区块链的传统同步联邦学习方法[1]
- 本地培训:每个节点用自己的数据训练一个单独的模型。
- 用缩放因子进行聚合,缩放因子被设计为平衡全局模型和局部模型之间的权重
- 训练模型包括MLP和CNN。为了评估所提出的BAFL模型的收敛速度和精度,我们以一些最先进的同步和异步联邦学习方法作为基准。
- 摘要
- 已经进行了一些涉及异步FL的研究以加速训练过程,但是它们通常具有降低的模型性能。
- 本文提出了一个基于区块链的具有动态缩放因子的异步联邦学习框架。
- 提出了一种新的动态缩放因子,提高了FL的效率和精度。
- 动态比例因子
- 如果出现精度较高的局部模型,则最好为其分配较高的权重,以提高全局模型的收敛速度。
- 缩放因子被设计为平衡全局模型和局部模型之间的权重。比例因子表示为.在本地数据集上测试时,如果局部模型的准确度高于全局模型的准确度,将被分配更高的值。

- 令acclocal和accglobal分别表示局部模型和全局模型的精度。
- 新的全球模型wt+1 glob计算如下:
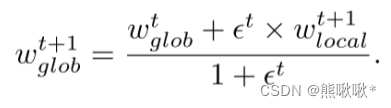
4· 4FedDual:Pair-Wise Gossip Helps Federated Learning in Large Decentralized_ Networks
局部模型聚合 梯度的权重Pi与数据集有关 噪声
- 摘要
- 提出了一种异步分层局部梯度聚合和全局模型更新算法FedDual。
- 引入局部差分隐私(LDP)来保护隐私,并通过成对的gossip算法来异步和分层地聚合局部梯度。
- 设计了一种基于私有集交集(PSI)的噪声削减技巧,以减轻全局模型预测性能损失。
在每个客户端上本地更新全局模型。
- 系统模型
- n个客户端的子组V = {c1,c2,···,cn},本地数据集Di,模型训练过程可以被视为优化目标函数,W * 表示最终收敛的全局模型

- 客户端ci计算局部梯度:

- 客户端以分散的方式聚集它们的局部梯度,并且通过执行梯度下降算法来更新局部模型:pi =|Di|/|Dtoal|是聚合权重。

- 由于缺乏中央服务器来聚集局部梯度和更新全局模型,因此不存在现实的全局模型。全局模型更新过程可以表示为:

- n个客户端的子组V = {c1,c2,···,cn},本地数据集Di,模型训练过程可以被视为优化目标函数,W * 表示最终收敛的全局模型
- 系统设计
- 系统初始化
- 局部梯度的局部训练
- 不考虑安全因素的FedDual
- 聚合过程分为两个阶段。
- 在第一阶段中,客户端协作地计算聚合权重。每个客户端可以计算聚合权重pi =pi =|Di|/|Dtoal|。
- 在第二阶段,客户端协作地计算局部梯度的加权平均值。首先计算加权局部梯度。

- 加权局部梯度的平均值αtave,全局梯度αt表示为:

- 更新个体局部模型ωti,
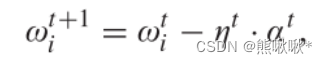
- 个体局部模型是通过相同的学习速率和全局梯度获得的
- 聚合过程分为两个阶段。
- FedDual下的安全注意事项
- 引入高斯机制对每个加权局部梯度进行扰动。
- 在第t轮聚合时,ci生成d维高斯噪声zt i,得到扰动加权局部梯度

- 经由成对gossip算法的局部模型更新过程可以表示为:
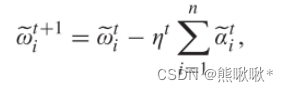
5· FedAT:A High-Performance and Communication-Efficient Federated Learning System with Asynchronous Tiers
层内同步更新局部模型参数,跨层异步更新全局模型。
掉队者感知加权聚合启发式算法:为较慢的层分配较高的权重。
- FEDAT:异步层的联邦学习
- FEDAT由三个主要组件组成:集中式服务器;客户机;分层模块。
- 每一层进行同步更新过程,随机选择一小部分客户机,计算其本地数据的丢失梯度,然后将压缩后的权值发送给服务器进行同步更新,并在服务器上更新层模型。
- 本地客户端训练:
- 通过限制局部更新使其更接近全局模型。客户机 k 使用 约束hk 更新:

- ftierm (w)作为模型的加权平均数,
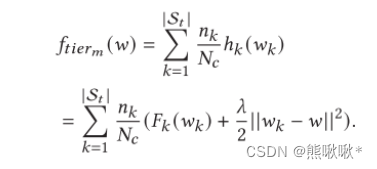
- 与数据样本数和选择的客户端有关
- 通过限制局部更新使其更接近全局模型。客户机 k 使用 约束hk 更新:
- 跨层加权聚合
- 将相对较高的权重分配给更新频率较低的较慢层,这样全局模型就不会偏向于更快的层。
- 设有 M 个层次,每个层次到现在的更新次数分别是 Ttier1,Ttier2,... ,TtierM,所有层次的更新总数是 T。将 FedAT 的目标函数定义为:,������������m的相对权重,

6· Efficient Asynchronous Federated Learning Research in the Internet of _ Vehicles
新鲜权重因子在聚合中应给予最近更新的模型更大的权重。
边缘服务器进行本地聚合,云服务器进行全局聚合。
- 摘要
- 提出了一种高效的分层异步联邦学习(EHAFL)算法,该算法可以根据带宽动态调整编码长度,从而大大降低通信开销。
- 车辆使用本地数据进行模型训练,路边单元RSU作为边缘服务器进行本地聚合,基站BS作为云服务器进行全局聚合。
- 为了减少过时梯度对全局模型的影响,在聚合过程中引入了新因子。
- 系统设计
- 边缘服务器接收到客户端上传的梯度参数后,开始基于新鲜权重因子进行异步聚合,云服务器等待边缘服务器的梯度传输到达后进行同步聚合。在聚合中应给予最近更新的模型更大的权重。
- 聚合方程为,Gt表示第t轮服务器端聚合的全局参数,αt i表示第t轮局部训练数据量,wt i表示第t轮客户端i上传的局部梯度参数,|U|表示客户端的数量

- 设计了一个权重方程来评估模型的新鲜度,f 的范围为[1,2]。
















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









