






1 A Multi-agent Reinforcement Learning Approach for Efficient Client Selection in Federated Learning
联合优化模型精度、处理延迟和通信效率
- 处理延迟合通信成本:
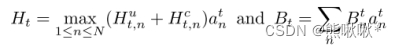 ,Hct,n表示局部训练时间,Hut,n表示通信延迟,at n ∈ {0,1}表示客户端n是否被选择。
,Hct,n表示局部训练时间,Hut,n表示通信延迟,at n ∈ {0,1}表示客户端n是否被选择。 - Acc(T)表示全局模型测试准确度。系统优化问题:
 w1、w2、w3是由FL应用程序设计者控制的目标的重要性。
w1、w2、w3是由FL应用程序设计者控制的目标的重要性。 - 我们的目标是最大化全局模型的精度,同时最小化总的处理延迟和通信成本。
- MARL Agent状态的设计
- 代理n在第t轮的状态向量st n:

- 代理n在第t轮的状态向量st n:
- Lt n表示探测损失,Hp t,n探测训练延迟,Hut,n模型上传的延迟,通信成本Btn,数据量Dn。
- 第t轮训练的奖励:

·2 TrustAugmented Deep Reinforcement Learning for Federated Learning Client Selection
考虑执行时间和信任值
-
-
- εm是训练局部模型所需的时间,αm是ES从E分配给IoT设备m的信任值。
- 引入两个函数:Θ1(ε1,ε2,...εn)是执行时间的聚合函数,以及Θ2(α1,α2,... αn)是n个设备的总体信任的聚合函数。
- 我们的调度解决方案的目标是最小化Θ1和最大化Θ2,服从约束等式:
-


局部状态sm ∈ Sm:

奖励函数R被定义为最大化对可信IoT设备的选择并且最小化总训练时间。设备m的奖励Ψ m:

· 3 An Efficiency-boosting Client Selection Scheme for Federated Learning with Fairness Guarantee、
考虑模型交换时间和公平性的客户端选择
-
- 系统模型基本假设
- 模型交换时间
- 模型交换的时间由其中花费最多时间在训练和模型上传上的客户端确定。
- 联邦回合的时间跨度:
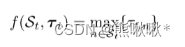 ,St是第t轮中的所选客户端,τt,n被用来表示从模型分发的最开始到来自客户n的模型被聚合的时刻之间的时间跨度
,St是第t轮中的所选客户端,τt,n被用来表示从模型分发的最开始到来自客户n的模型被聚合的时刻之间的时间跨度
- 长期公平约束
- 如果我们总是选择最快的客户端,随着选择偏差,全局模型的泛化能力会下降。
- 为了模拟这样一个公平问题,我们引入了一个长期的公平约束
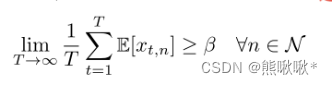 ,β建模了期望保证的客户端选择率,xt,n用于指示客户端n是否参与,
,β建模了期望保证的客户端选择率,xt,n用于指示客户端n是否参与,
- 客户的可用性
- It,n来示客户是否愿意参与。It,n = 1 ∀n ∈ St
- 选择部分
- |St|指第t轮中的所选客户端数量,当可用性的总数没有超过最大客户端数量的情况下,我们让所有活跃的客户参与新一轮的培训。

- |St|指第t轮中的所选客户端数量,当可用性的总数没有超过最大客户端数量的情况下,我们让所有活跃的客户参与新一轮的培训。
- 模型交换时间
- 一个离线的长期优化问题
- 系统模型基本假设
客户选择问题,如下:
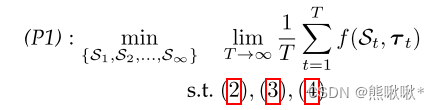
·4 Proximal Policy Optimization-based Federated Client Selection for Internet of Vehicles
- a)状态空间:Sj = {wdj,fj,ej,rj},权重差异、CPU周期频率、剩余能量和数据速率。
- d)奖励函数:在最小化系统开销的同时最大化模型精度。奖励函数定义为
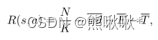 ,从K台志愿车中选择N台,归一化的本地数据质量、能量消耗和延迟。
,从K台志愿车中选择N台,归一化的本地数据质量、能量消耗和延迟。
·5 Adaptive Client Selection in Resource Constrained Federated Learning Systems
- 状态空间:Sk = {fk, ek, rk; fk ≤ F, ek ≤ E, rk ≤ R},cpu周期频率、能量单位和无线带宽的限制。
- 奖励函数:奖励函数应与客户端数量成正比,与能量消耗和训练延迟成反比,E是MEC系统在每次迭代中消耗的总能量单位
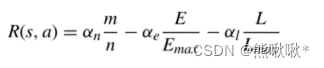















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









