







1.论文介绍
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
SAMUS:一种适用于临床友好和可推广的超声图像分割模型
arxiv 2023年
Paper Code
2.摘要
SAM是一种著名的通用图像分割模型,近年来在医学图像分割领域引起了极大的关注。尽管SAM在自然图像上有显著的性能,但在面对医学图像时,尤其是涉及低对比度、边界模糊、形状复杂和尺寸较小的对象时,SAM的性能显著下降和泛化有限。本文提出了一种适用于超声图像分割的通用模型SAMUS。与以往基于SAM的通用模型相比,SAMUS不仅追求更好的通用性,还追求更低的部署成本,使其更适合临床应用。具体地说,在SAM的基础上,引入了并行CNN分支,通过跨分支关注将局部特征注入到VIT编码器中,以实现更好的医学图像分割。然后,开发了位置适配器和特征适配器,使SAM从自然领域到医学领域,从需要大尺寸输入(1024×1024)到小尺寸输入(256×256),以实现更好的临床部署。收集了一个全面的超声数据集,包括大约30K个图像和69K个面具,覆盖了六个对象类别,用于验证。通过大量的对比实验,证明了SAMUS在特定任务评价和泛化评价下的性能优于现有的特定任务模型和通用基础模型。
Keywords:SAM、并行CNN、低分辨率图像
3.Introduction
由于缺乏可靠的临床注释,SAM在医学领域遇到了快速的性能下降。已经提出了一些基础模型,通过在医学数据集上调整SAM来使SAM适应医学图像分割。然而,与SAM一样,它们在特征建模之前对输入图像执行无重叠的16倍标记化,这破坏了对于识别小目标和边界至关重要的局部信息,使得它们难以分割具有复杂/线状形状、弱边界、小尺寸或低对比度的临床对象。此外,它们大多需要1024×1024的输入,由于生成的输入序列很长,对GPU的消耗造成了很大的负担。
在本文中,我们提出SAMUS将SAM优异的分割性能和强大的泛化能力转移到医学图像分割领域,同时降低了计算复杂度。Samus继承了SAM的VIT图像编码器、提示编码器和掩码解码器,并为图像编码器量身定做了设计。首先,我们通过减小输入大小来缩短VIT-BRANCH的序列长度,以降低计算复杂度。然后,开发了特征适配器和位置适配器,以将VIT图像编码器从自然领域微调到医用领域。为了补充VIT图像编码器中的局部(即低层)信息,我们引入了并行CNN分支图像编码器,并提出了跨分支注意模块,使VIT分支中的每个补丁能够吸收来自CNN分支的局部信息。
4.模型结构详解
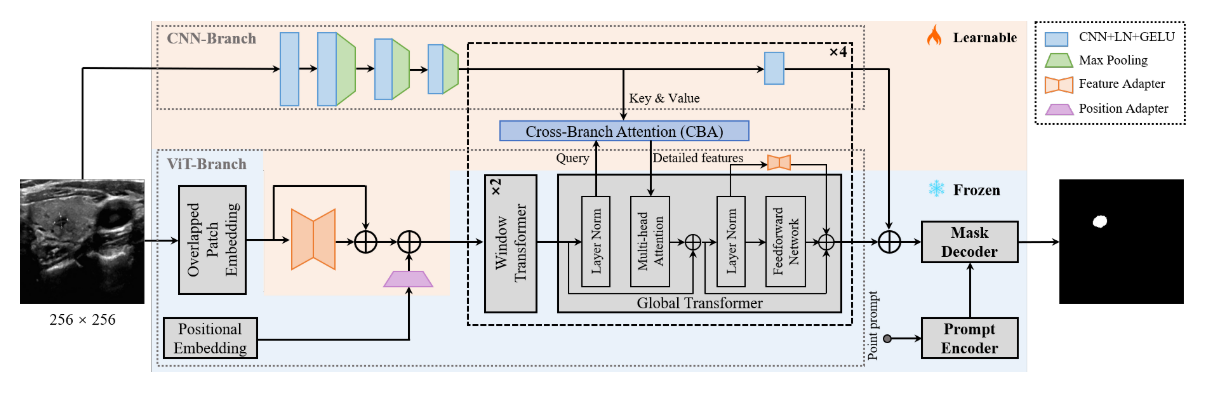
SAMU的整体架构继承自SAM,保留了提示编码器和掩码解码器的结构和参数,没有任何调整。相比之下,图像编码器经过了精心的修改,以解决局部特征不足和计算内存消耗过大的挑战,使其更适合于临床友好的分割。主要的修改包括减小输入大小、重叠补丁嵌入、向VIT分支引入适配器、增加CNN分支以及引入跨分支注意(CBA)。具体地说,输入空间分辨率从1024×1024像素缩减到256×256像素,由于transformer中的输入序列较短,因此大大降低了GPU内存成本。重叠块嵌入使用与SAM中的块嵌入相同的参数,但其块跨度是原始步长的一半,很好地保留了块边界的信息。VIT分支中的适配器包括一个位置适配器和五个特征适配器。由于较小的输入尺寸,位置适配器将适应较短序列中的全局位置嵌入。第一特征适配器遵循重叠补丁嵌入,以将输入特征与预先训练的VIT图像编码器所需的特征分布对准。其余的特征适配器连接到全局转换器中的前馈网络的剩余连接,以微调预先训练的图像编码器。在CNN分支方面,它与VIT分支平行,通过CBA模块向后者提供补充的本地信息,CBA模块将ViT分支的特征作为查询,并与CNN分支的特征建立全局依赖。需要注意的是,CBA仅集成到每个全局转换器中。最终将两个分支的输出组合在一起,作为Samus的最终图像特征嵌入。点提示:通过随机抽样标签前景区域中的一个点来模拟专家提供提示的过程。
VIT分支中的适配器:
为了便于将SAM的训练图像编码器(即VIT分支)推广到较小的输入尺寸和医学图像域,本文引入了一个位置适配器和五个特征适配器。这些适配器可以有效地调整VIT分支,而只需要更少的参数。具体地,位置适配器负责调整位置嵌入以匹配嵌入序列的分辨率。它首先通过最大池化对位置嵌入进行下采样,从而获得与嵌入序列相同的分辨率。随后,应用核大小为3×3的卷积运算来调整位置嵌入,进一步帮助VIT分支更好地处理较小的输入。所有特征适配器具有相同的结构,该结构包括三个组件:向下线性投影、激活函数和向上线性投影。每个功能适配器的程序可表述为:
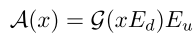
其中G表示GELU激活函数,
E
d
∈
R
d
×
d
/
4
E_d∈Rd×d/4
Ed∈Rd×d/4和
E
u
∈
R
d
/
4
×
d
Eu∈Rd/4×d
Eu∈Rd/4×d是投影矩阵,d是特征嵌入的维度。通过这些简单的操作,特征适配器使VIT分支能够更好地适应医学图像领域的特征分布。
CNN分支:
CNN分支由顺序连接的卷积池块组成。具体地说,输入最初通过单个卷积块,然后通过三个卷积池化块进行处理。然后,CNN分支中的特征图与VIT分支中的特征图共享相同的空间分辨率。在CNN分支的其余部分,这样的单个卷积块被顺序重复四次。更多细节如下图所示。CNN分部的这种简约和轻便的设计是为了防止在训练过程中过度适应。
跨分支机构注意:
跨分支注意(CBA)模块在CNN分支和VIT分支之间建立了一座桥梁,以进一步与VIT分支补充缺失的本地特征。对于来自VIT分支FV和CNN分支FC的一对特征图,单头中的跨分支注意可以表示为:
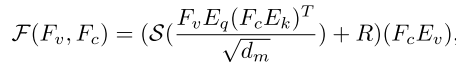
S代表Softmax的功能。EQ∈Rd×dm、Ek∈Rd×dm和EV∈Rd×dm是用于将Fc和Fv投影到不同特征子空间的可学习权重矩阵。R∈RHW×HW是相对位置嵌入,dm是CBA的维度。CBA的最终输出是这种单头注意力的线性组合。
在训练之前,Samus使用在SA-1B上训练的权重来初始化从SAM继承的参数。其余参数是随机初始化的。在训练过程中,只有来自适配器、CNN分支机构和CBA模块的参数被更新,而其他参数保持冻结。训练过程使用组合损失函数来监督,该组合损失函数包括骰子损失和二进制交叉熵损失。为便于使用,Samus仅使用最简单的正点提示。通过随机抽样标签前景区域中的一个点来模拟专家提供提示的过程。
这里根据网络图可以看得很清楚。正常SAM的image-encoder是分成patch,加上位置编码再经过encoder块编码得到最终结果,如下:
但本文的模型加上在位置编码上加了adapter,在patch上加了adapter,并且加入cnn分支的特征。具体cnn分支的特征首先通过交叉注意力以vit的特征为query,cnn特征为value和key得到的特征入encoder的多头注意力块,同时也要再次对cnn的特征进行调整,最后加上调整后的特征。

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









