







1.论文介绍
From Forks to Forceps: A New Framework for Instance Segmentation of Surgical Instruments
从叉子到钳子:一种新的手术器械实例分割框架
2023年WACV
Paper Code
2.摘要
微创手术和相关应用需要在实例级别对手术工具进行分类和分割。外科手术工具外形相似,又长又细,并以一定的角度握持。在自然图像上训练的用于仪器分割的最新(SOTA)实例分割模型的微调难以区分仪器类别。虽然包围盒(框)和分割掩码通常是准确的,但分类头还是会错误地分类了手术器械的类别标签。我们提出了一种新的神经网络框架,它在现有的实例分割模型的基础上增加了一个分类模块作为一个新的阶段。本模块专门改进现有模型生成的仪器掩模的分类。该模块包括多尺度掩模关注,它关注仪器区域并掩蔽令人分心的背景特征。我们建议使用带弧度损失的度量学习来训练我们的分类器模块,以处理手术器械的低类间方差。
Keywords:医疗器械分割、多尺度掩码关注、度量学习
3.Introduction
在管理信息系统中,手术器械的自动分割是一个具有很高实用价值的活跃研究领域。手术器械分割带来了各种挑战,具体取决于数据集采集源、手术类型和涉及的仪器/工具、图像分辨率、数据集大小、工具统计、挑战性条件(闭塞、外观快速变化、镜面反射、烟雾、模糊、血液飞溅)。大多数外科数据集和算法将器械分割构造为语义分割,它将每个像素分类为器械类别之一。由于不连通的区域和遮挡/重叠的工具,为语义分割输出分配实例标签的任务不是微不足道的。然而,对于大多数手术器械分割应用来说,获得操纵器械的实例级掩码是必不可少的对于依赖于仪器追踪的应用。因此,本文主张将任务模拟为多类实例分割。
- 研究了SOTA算法在医疗器械分割中IOU分值低的原因。在具有长尾的数据集中,虽然可以正确地标出这些对象的大致位置,但在识别这些对象的具体类别时却经常出错。我们假设,由于自然物体和医疗器械之间存在显著的视觉差异,进行跨域微调的深度神经网络模型无法开发出用于分类的稳健特征。然而,由于边界框和遮罩预测基于更健壮的特征,例如边缘,因此这些预测更容易泛化。因此,在这些技术中需要一个专门的模块,专注于获取有效地对手术器械进行分类所需的属性。因此,我们建议在现有技术的基础上增加一个专门的分类模块,它将分类与包围盒和mask预测解耦,专门用于分类。
- 自然图像和微创手术之间在宽高比和方向上存在差异。而在自然图像中,宽高比通常在0.5左右,手术器械大多是两个或更多。此外,自然对象在图像中看起来大多是垂直的,并且很适合直线边界框。另一方面,手术器械是倾斜使用的,出现在包围盒的对角线上。仪器的纵横比和倾斜外观降低了其在边界框区域中的比例,并带来了分散注意力的背景。更糟糕的是,考虑到微创手术中较小的操作区域,提议的边界框可能包含多个工具,从而使分类任务进一步复杂化。这一发现促使人们需要基于掩蔽注意力而不是现有的边界框进行分类。因此,我们建议在拟议的专门分类模块中列入基于掩模的注意。
- 外科器械表现出类别间的外观相似性,并包含长轴;唯一的区别特征可能是器械的尖端。因此,现代建筑中基于交叉熵的通用分类器训练方法不适用于手术器械的细粒度分类。最近的文献表明,对于小数据集,将表示学习和分类阶段分开是有益的。首先可以使用对比损失来实现,然后对分类进行精细调整。我们遵循类似的方法,使用弧损失训练我们提出的分类模块,然后使用交叉熵损失进行微调。
4.网络结构详解
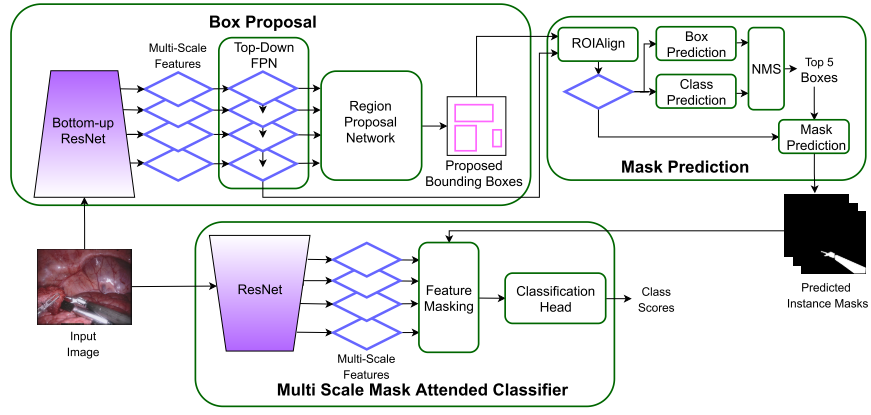
专门的分类模块作为一个新的阶段,可以插入到任何现有的实例分割模型中。本文基于MaskRCNN主干来验证模型。MaskRCNN主干包括对应于区域建议网络(RPN)的两个阶段和为每个提案生成掩码和标签的分类头。将新的分类模块作为第三阶段插入MaskRCNN中,并将第二阶段生成的标签替换为我们的模块生成的标签。我们提出的三级深度神经网络(S3Net)的体系结构如图所示。
对于给定的输入帧Ii,第一阶段(框建议)提取L边界框建议,其中Bij是第i帧中的第j个建议。第二阶段(掩码预测)使用边界框建议预测每个仪器的掩码 P i , j , ˆ c P_{i,j,ˆc} Pi,j,ˆc。这里,ˆc指的是在这个阶段预测的类别。
第二阶段输出的处理:MaskRCNN和其他类似型号的第一阶段称为Region ProPosal Network (RPN),通常输出与图像中的单个对象实例相对应的许多重叠区域。MaskRCNN的分类头即使在跨域微调后仍然疲软。因此,许多重叠的盒子被归类为不同的类别。典型的非最大抑制(NMS)步骤不拒绝对应于不同类别的重叠框。如果不加以解决,这将导致MaskRCNN和其他SOTA技术的许多假阳性预测,我们已经在我们的实验中进行了比较。因此,我们修改了实现的标准NMS步骤,以拒绝跨类的图像中的重叠片段。
理解这个首先要理解MaskRCNN的工作流程:
Mask R-CNN 的工作流程
- 骨干网络(Backbone Network):提取图像的特征,生成特征图。
- 区域建议网络(RPN, Region Proposal Network):在特征图上生成一系列候选区域(RoIs, Regions of Interest),这些区域可能包含目标对象。RPN 输出许多候选区域,这些区域可能会有重叠。
- RoIAlign:对 RPN 生成的候选区域进行裁剪和缩放,以生成固定大小的特征图。
- 分类和回归(Classification and Regression Heads):对每个候选区域进行分类,确定其所属类别。回归头调整每个候选区域的边界框,使其更加精确。分类头对每个候选区域进行分类,决定其所属类别。回归头对每个候选区域进行位置调整,生成精确的边界框。
- 掩码分支(Mask Branch):为每个候选区域生成像素级别的分割掩码。
- 非极大值抑制(NMS, Non-Maximum Suppression):在分类和回归之后,NMS 处理重叠的候选区域,保留最优的候选框,去除重复的或低置信度的候选框。NMS 通过计算候选区域之间的 IoU(交并比),来去除那些重叠度高的候选区域。NMS 通常在同一类别内进行,即保留每个类别中得分最高的候选框,去除得分较低且重叠度高的候选框。
RPN(Region Proposal Network)阶段:Mask R-CNN 和类似的模型在第一阶段使用 RPN 来生成候选区域(Region Proposals)。RPN 通常会输出许多重叠的区域,这些区域可能对应于图像中的同一个对象实例。
即使经过跨领域的微调,Mask R-CNN 的分类头(classification head)仍然存在弱点:很多重叠的候选区域会被错误地分类为不同的类别。
传统的 NMS 步骤用于删除重复的候选框,但只针对相同类别的候选框进行抑制,并不会拒绝属于不同类别的重叠候选框,会导致同一个对象的不同重叠区域误分类为不同的对象。
RPN 的目的是在图像中生成一系列候选区域(bounding boxes),这些区域可能包含感兴趣的对象。由于对象的大小、形状和位置不同,RPN 生成的候选区域往往会重叠。
分类头用于对每个候选区域进行分类。但是,由于跨领域数据的差异和模型本身的限制,分类头可能不能准确地区分对象,导致重叠区域被分类为不同的类别。
NMS 的作用是去除重复的候选框,保留置信度最高的框。它通过比较候选框之间的重叠程度(IoU)来决定哪些框需要被抑制。
标准 NMS 仅在同一类别内进行抑制,不会处理不同类别之间的重叠问题。
简而言之就是,RPN会生成重叠的候选区域,这些区域可能是同一个对象实例,但是分类头会把它们分类成不同类别的,而NMS步骤用来删除同一类别的重复候选框,这样同一类别的候选框因为被错误分类,就会被错误保留。
处理错误分类:在两阶段网络中,我们观察到第一阶段RPN生成的建议是不准确的。然而,这些建议在第二阶段通过包围盒回归头部进行细化,导致在第二阶段之后获得更高的包围盒和掩码精度。然而,分类是对从第一阶段不准确的区域建议中裁剪出来的区域进行的,并且仍然很脆弱,这使得分类成为影响仪器分割精度的瓶颈。基于此,本文提出了一种新的深度神经网络模型,它使用了标准实例分割方法的前两个阶段,但包含了一个额外的第三阶段,专门用于基于掩码的分类。我们将提出的分类器称为多尺度掩码参与分类器(MSMA),它更新/校正前两个阶段的类预测。设ˆc表示类别标签, P i , j , ˆ c P_{i,j,ˆc} Pi,j,ˆc表示对应于区域建议的掩码输出。然后,MSMA的目标是以原始图像和掩码 P i , j , ˆ c P_{i,j,ˆc} Pi,j,ˆc作为输入,并将ˆc的类别标签细化为更准确的标签c。最终的掩码(带有更新的类别标签)表示为 P i , j , c P_{i,j,c} Pi,j,c。如前所述,医疗器械的边界框矩形区域包含大量背景和其他器械的像素。这是由于器械的形状和器械在手术中的典型使用方式。这分散了分类头的注意力,并导致错误。因此,我们在MSMA中引入了空间掩码关注,而不是使用矩形区域建议,以强调仅属于仪器的区域。
在训练过程中,我们使用与实例相对应的真实掩码,在测试时,我们使用第二阶段预测的掩码。这种硬掩码关注是在图像的多尺度特征上执行的。这有助于我们的模型聚焦于图像中正确的仪器空间区域,从而对MaskRCNN第二阶段生成的掩模进行更准确的分类。此外,为了有效地利用小数据集进行训练,我们在建议的第三阶段将学习特征表示和分类分开。我们首先使用弧度损失函数进行度量学习,然后使用分类交叉点进行学习分类器。
多尺度掩蔽(MSMA)分类器:卷积特征掩码:利用形状信息将物体与材料分开。我们在一个实例分割框架中采用这种方法,将仪器从背景/重叠的仪器中分离出来,并改进了分类器。我们研究了掩码和分类头的解耦特性,并使用具有多尺度掩码关注度的专用神经网络进行分类。它以原始RGB图像Ii和每个仪器实例的预测掩码
P
i
,
j
,
ˆ
c
P_{i,j,ˆc}
Pi,j,ˆc作为输入。ResNet主干被用来从Ii中提取多尺度特征。然后,将遮罩
P
i
,
j
,
ˆ
c
P_{i,j,ˆc}
Pi,j,ˆc乘以每个特征以创建多尺度遮罩辅助特征。然后使用另一个1×1卷积合并被屏蔽的特征,为每个实例创建一个单一的特征地图。请注意,如果在一个帧中预测了一个类的多个实例,则将为每个实例单独运行MSMA分类器。我们学习掩码特征映射上的嵌入层,其为每个仪器实例输出嵌入Ei,j。然后,每个Ei,j被用来对mask中存在的器械进行分类,从而为mask提供了新的类别标签c。对于训练MSMA分类器,我们利用弧损失[16],定义如下:

这里C是类的数量,m是不同类的要素之间强制的角度边距。此外,θj是嵌入特征Ej和最终完全连接层中的第j个神经元的权重向量之间形成的角度。将弧损从人脸识别领域适应到类间方差较小的外科领域;弧损试图最大化类别特征之间的距离,从而提高分类精度。与计算Ei、j和每个权重向量之间的点积的分类交叉熵损失不同,圆弧损失只取决于它们之间的角度。使用圆弧损失可以消除权重向量大小对最终决策的影响。由于权重向量的大小是无界的,因此对于具有更多样本的类,它们很容易变得有偏差。因此,弧度损失通过消除对权重向量大小的依赖来处理数据中的类别不平衡。此外,弧损为每个类别形成一个基于度量的角度簇,而不是学习不同类别之间的决策边界。这是由角边距m确保的,从而尽管数据稀缺,但仍具有更好的类内紧凑性和类间可分性。
5.数据集
它要把Endovis2017数据集改成COCO格式:
COCO 数据集的标注包括以下几个部分:
- 图像信息:包括图像的文件名、尺寸等。
- 类别信息:包括所有类别的 ID 和名称。
- 注释信息:包括每个图像中的对象的边界框、分割掩码、类别 ID 等。
COCO 格式的数据集通常包括以下文件:
- images:包含所有图像文件。
- annotations:包含所有图像的标注信息,通常是一个或多个 JSON 文件。
COCO 数据集的结构可以概括如下:
- images 文件夹:存放图像文件。
- annotations 文件夹:存放 JSON 格式的标注文件。
- categories:包含类别 ID 和名称的列表。
- annotations:包含每个图像的注释信息,包括边界框和分割掩码等。
然后计算:对每个图像
- train_images:存储预处理后的训练图像,每张图像是一个形状为 (C, H, W) 的数组。
- train_labels:存储每张图像的标签矩阵,每个标签矩阵形状为 (25, 7),表示最多25个对象,每个对象有7个类别。
- train_mask:存储每张图像的分割掩码,每个掩码的形状为 (25, image_size//4, image_size//4),表示最多25个对象,每个对象的分割区域。
- train_mask_gt:存储每张图像的掩码存在标志,形状为 (25,),表示哪些对象在图像中存在。
说明
不知道是不是我没用过MaskRCNN的问题,这个代码看着好迷糊。
总体就是增加了一个MSMA分类器作为MaskRCNN的第三阶段:
- 它自己有ResNet提取特征,拼接多层次特征;
- 然后使用提供的掩码 mask 对特征图 feature 进行掩码处理,每次处理一个对象,对掩码处理后的特征图进行全局平均池化,以获得固定长度的特征向量;
- 得到的特征向量再经过分类头分类得到最终结果。
- 该结果使用弧损失计算,计算每个像素的类别交叉熵损失,将每个像素的损失与对应的真实掩码值相乘,实现加权操作。只有真实掩码位置的损失才会被保留,对加权后的损失进行求和,得到总损失,计算真实掩码中所有像素的总和,作为损失的分母,将总损失除以掩码的总和,得到平均损失。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









