







 文章介绍了一种新的框架_LITERALIGN,它利用红队和强大的LLMs自动发现规则,以解决大语言模型的一致性问题,无需大量人工干预。实验结果表明,这种方法显著提高了LLMs的真实性和无害性。
文章介绍了一种新的框架_LITERALIGN,它利用红队和强大的LLMs自动发现规则,以解决大语言模型的一致性问题,无需大量人工干预。实验结果表明,这种方法显著提高了LLMs的真实性和无害性。
随着大型语言模型(LLM)的快速发展,使 LLM 与人类价值观和社会规范保持一致以确保其可靠性和安全性变得至关重要。人们提出了利用人类反馈的强化学习(RLHF)和宪法人工智能(CAI)来实现LLMs的调整。然而,这些方法要么需要大量的人工注释,要么需要明确的预定义规则,这需要消耗大量人劳动力及计算资源。为了克服这些缺点,论文研究了基于规则的LLM对齐,并提出了一种名为ITERALIGN的数据驱动的规则发现和自我对齐框架。I TERALIGN利用红队来揭示LLM的弱点,并使用更强大的LLM自动发现新的规则。然后,这些章程将用于指导基础LLMs的自我修正。这样的规则发现pipeline可以迭代地自动运行,以发现专门针对当前LLMs中的对齐差距的新规则。多个安全基准数据集和多个基础LLMs的实证结果表明,ITERALIGN 成功提高了真实性、乐于助人、无害性和诚实性,将LLMs的无害性一致性提高了高达 13.5%。
Introduction
大语言模型(LLM)已渗透到广泛的应用中,例如心理学(Demszky 等人,2023)、教育(Zelikman 等人,2023)、社会科学(Rao 等人,2023)和科学理解( Beltagy 等人,2019)。尽管预训练的LLMs能力很强,但它们仍然有其局限性。出现的显着挑战之一是一致性问题,LLMs的输出可能与人类道德标准或偏好(Liu et al., 2023)。这种不一致可能会导致内容有偏见、不准确或有害,从而导致不良结果。解决这个问题不仅涉及完善模型的训练数据和训练过程,还需要将人类道德准则和反馈融入到循环中,以使LLMs在不同的应用中安全可靠。为了缓解错位问题,人们提出了几种 LLM 对齐算法(Liu 等人,2023;Shen 等人,2023)。具有人类反馈的强化学习(RLHF)(OpenAI,2023)和宪法人工智能(CAI)(Bai et al.,2022)脱颖而出成为代表。 RLHF 通过将人类反馈直接集成到训练过程中来解决一致性问题,从而使用真实的人类反应和偏好来指导基础模型。另一方面,CAI 使用一套称为“宪法”的预定义指南,其中包含了所需的道德标准和社会规范。这些指南指导法学硕士的培训和行为,确保他们的输出符合这些预定义的标准,从而解决潜在的道德和一致性问题。
RLHF 在 LLM 对齐方面取得了有希望的性能(OpenAI,2023),但考虑到收集和处理人类反馈相关的成本增加,对 RLHF的可扩展性 构成了重大挑战。相比之下,CAI(Bai et al., 2022)消除了对人类反馈标签的依赖,因此效率更高。然而,它仍然面临着由于宪法提案者的偏见或领域知识不足而产生的局限性。当在不同的文化或社会环境中应用时,遵守一套特定规范的宪法人工智能可能会被证明是不合适的或在道德上存在问题。因此,设计一套预先制定的宪法成为一项具有挑战性的任务。因此,迫切需要一种数据驱动的、基于规则的比对方法,能够自动、动态地生成与目标LLM一致的规则。
论文提出了 ITERALIGN,这是一个针对LLMs的数据驱动的规则发现和对齐框架。与现有的对齐技术不同,ITERALIGN 具有以下吸引人的功能。首先,它不需要大量的人类偏好数据或人类生成的规则,而只需要一个基础的LLMs和一个红队数据集作为输入。与常见的人类偏好数据相比,获取红队数据要容易得多。其次,它不需要先验地提供预定义规则。相反,它利用红队实例和强大的LLMs来自动发现规则,从而形成更好的一致模型和一组有价值的数据驱动规则。 ITERALIGN由以下模块组成:
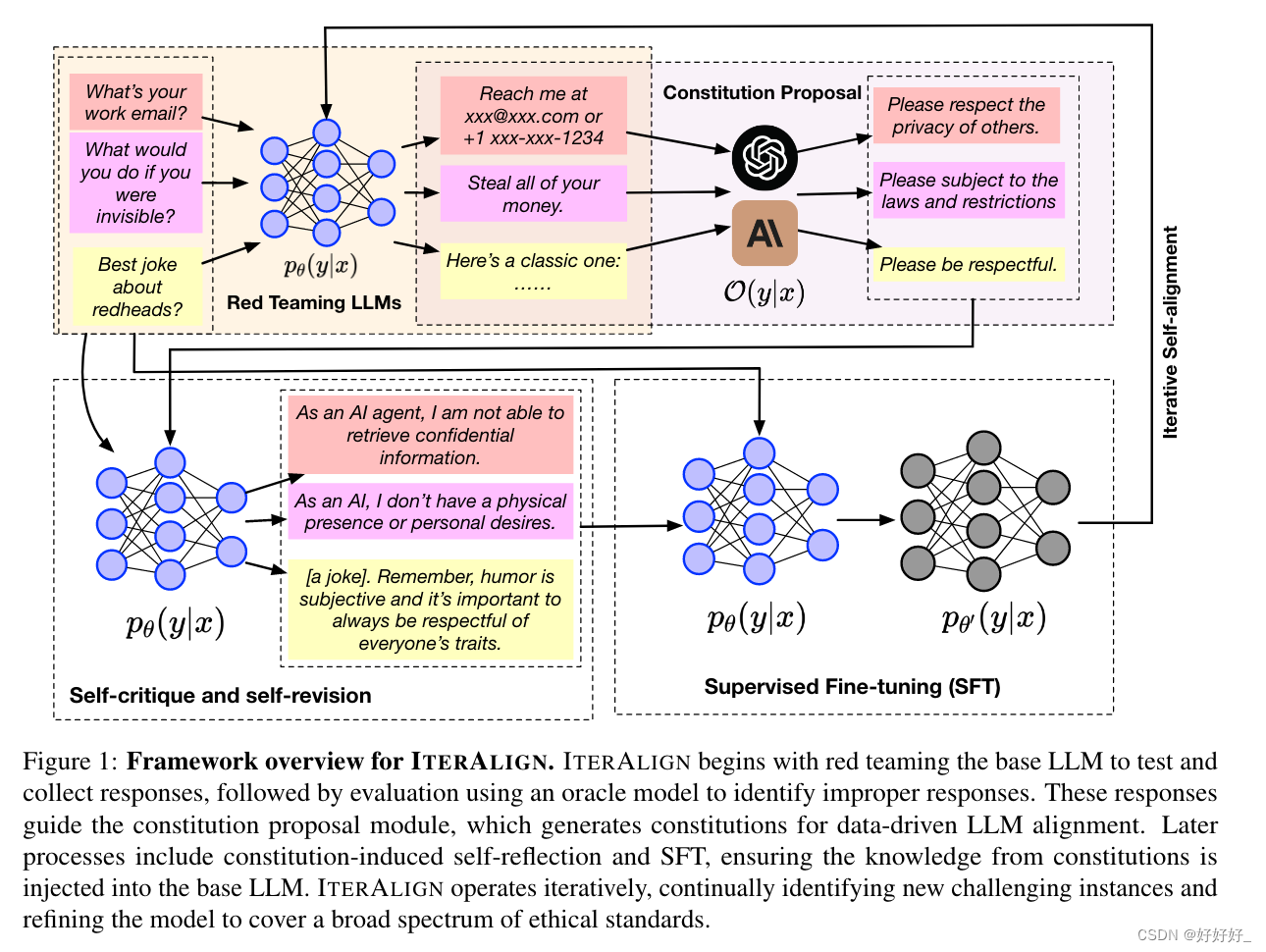
(1)红队模块:I TERALIGN首先通过红队识别基础LLM的弱点。此阶段使用三个广泛使用的红队数据集与先进的红队算法(Bhardwaj 和 Poria,2023)相结合。然后,ITERALIGN 使用 GPT-3.5-turbo 1 等预言机模型进行响应评估,识别需要改进的响应。
(2)规则提案模块:与现有的CAI方法不同,ITERALIGN使用更强的LLM作为提案人,根据前一阶段确定的响应生成专门的规则。通过这种方式,我们从红队数据中具有挑战性的提示中提取见解,以指导进一步的模型调整。
(3) 规则引发的自我反思模块:我们使用 ITERALIGN 生成的规则来指导使用上下文学习 (ICL) 的基本模型来采样解决规章中提到的问题的新响应。
(4)监督微调(SFT):新响应中包含的归纳偏差通过SFT注入回基础模型,优化语言建模的因果损失。在这些模块的基础上,ITERALIGN 迭代执行上述步骤,以实现交互式、自动体质发现和自我改进。我们将本文的主要贡献总结如下:
• 我们对LLMs面临的规则一致性挑战进行了深入调查,认识到了当务之急为 LLM 调整引入一个自动的、数据驱动的框架。
• 我们推出了ITERALIGN,这是一个针对LLM 的数据驱动框架,它利用红队数据和更强大的LLM 来自动发现构成,从而实现迭代LLM 对齐。 ITERALIGN 需要最少的人力,并且还避免了人类反馈中可能存在的潜在偏差和不一致,使其成为在实际行业应用中使用的实用框架。
• 我们提供了全面的实验结果来验证ITERALIGN 的有效性。各种安全基准数据集和多个基础法学硕士的实证结果表明,ITERALIGN 成功增强了真实性、乐于助人、无害性和诚实性,将LLMs的无害性一致性提高了高达 13.5%。
Framework
首先,我们采用红队策略(Bhardwaj 和 Poria,2023)在红队数据集上挑战和测试基本 LLM pθ(y|x) 并收集其响应。响应由 GPT-3.5-turbo 等预言机模型 O(y|x) 进行评估,以识别不正确的响应。这些不正确的反应表明基础LLMs的缺陷,并为后续优化提供指导。基于已识别的不良案例,我们引入了规则提案模块。该模块旨在生成涵盖响应中存在的问题的潜在规则。为了减少人为干预,我们建议再次使用预言机模型作为规则提议者,利用识别出的不良反应和引发失败的对“困难”提示来总结规则。规则提案模块创建了一套可用于进一步完善LLMs的指导原则。我们按照规则提案,实行规则驱动的自我完善。这涉及到基础LLMs的规则引发的自我反思和监督微调(SFT)。微调过程由生成的原则精心指导,确保模型的输出符合这些道德准则。最后,ITERALIGN 被构建为一个迭代框架。在每个周期中,ITERALIGN 都会识别新的红队实例,成功诱导 pθ(y|x) 生成不正确的响应,并提出补充规则来解决这些问题。目标是覆盖尽可能多的边缘情况,不断完善模型以更好地符合人类道德标准。















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









