







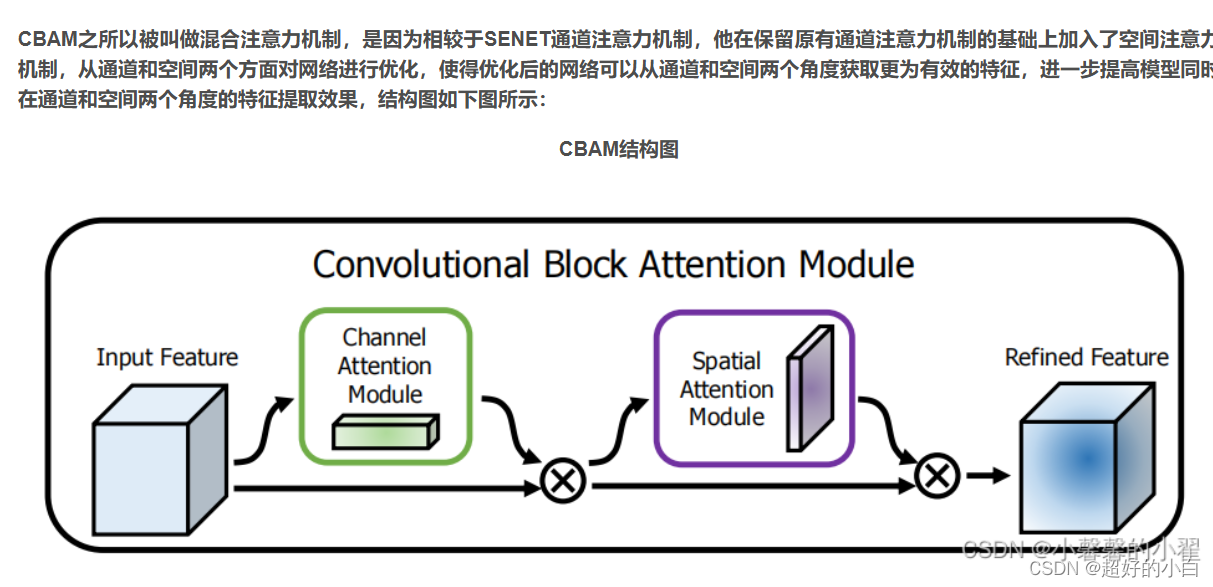
CBAM是结合了通道和空间信息的注意力机制。
参考:SE、CBAM、ECA注意力机制
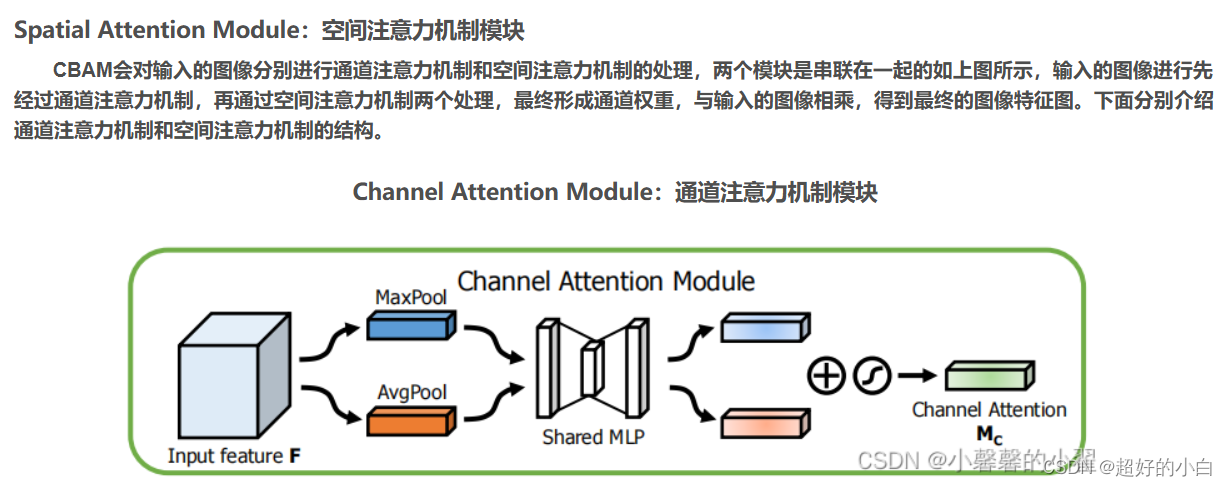
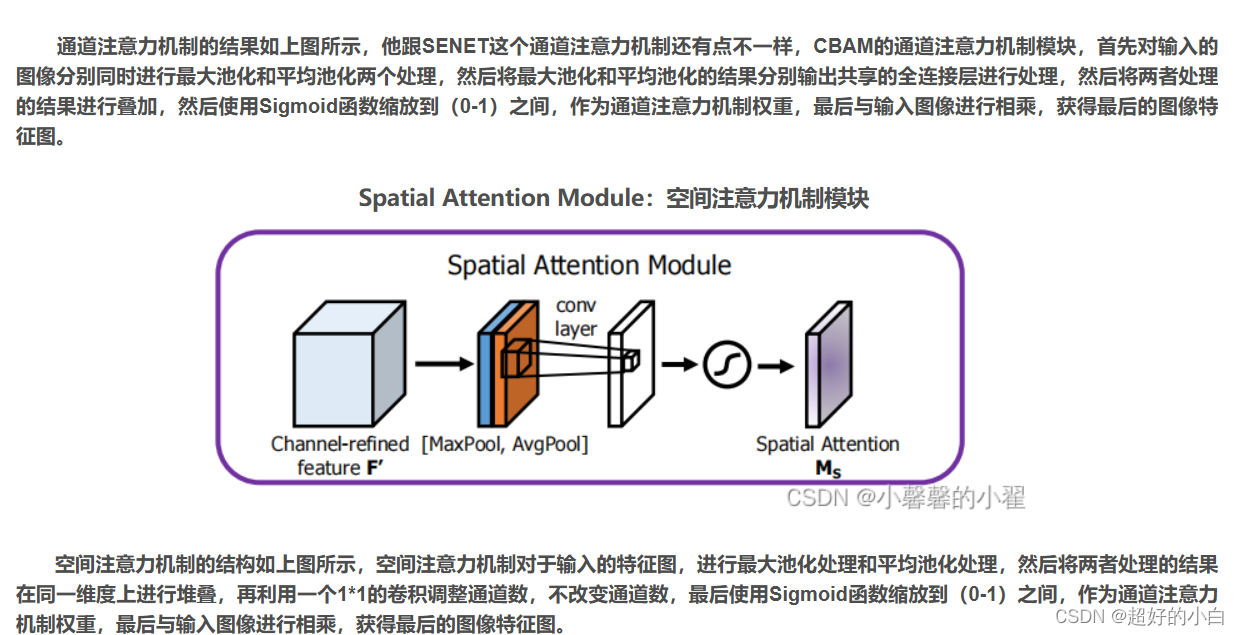
CBAM代码实现:
import torch.nn as nn
import torch
class ChannelAttention(nn.Module): #通道注意力机制
def __init__(self, in_planes, scaling=16):#scaling为缩放比例,
# 用来控制两个全连接层中间神经网络神经元的个数,一般设置为16,具体可以根据需要微调
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // scaling, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // scaling, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
out = self.sigmoid(out)
return out
class SpatialAttention(nn.Module): #空间注意力机制
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
x = self.sigmoid(x)
return x
class CBAM_Attention(nn.Module):
def __init__(self, channel, scaling=16, kernel_size=7):
super(CBAM_Attention, self).__init__()
self.channelattention = ChannelAttention(channel, scaling=scaling)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
CBAM Resnet
import torch
import torch.nn as nn
import torch.nn.functional as F
'''-------------一、CBAM模块-----------------------------'''
class CBAMLayer(nn.Module):
def __init__(self, channel, reduction=16, spatial_kernel=7):
super(CBAMLayer, self).__init__()
# channel attention 压缩H,W为1
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
# Conv2d比Linear方便操作
# nn.Linear(channel, channel // reduction, bias=False)
nn.Conv2d(channel, channel // reduction, 1, bias=False),
# inplace=True直接替换,节省内存
nn.ReLU(inplace=True),
# nn.Linear(channel // reduction, channel,bias=False)
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
'''-------------二、BasicBlock模块-----------------------------'''
# 左侧的 residual block 结构(18-layer、34-layer)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inchannel, outchannel, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(outchannel)
self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(outchannel)
# CBAM_Block放在BN之后,shortcut之前
self.CBAM = CBAMLayer(outchannel)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != self.expansion * outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, self.expansion * outchannel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * outchannel)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
CBAM_out = self.CBAM(out)
out = out * CBAM_out
out += self.shortcut(x)
out = F.relu(out)
return out
'''-------------四、搭建CABM_ResNet结构-----------------------------'''
class CABM_ResNet(nn.Module):
def __init__(self, num_blocks=[2, 2, 2, 2], num_classes=12):
super(CABM_ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, bias=False),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
self.layer1 = self._make_layer(BasicBlock, 64, num_blocks[0], stride=1) # conv2_x
self.layer2 = self._make_layer(BasicBlock, 128, num_blocks[1], stride=2) # conv3_x
self.layer3 = self._make_layer(BasicBlock, 256, num_blocks[2], stride=2) # conv4_x
self.layer4 = self._make_layer(BasicBlock, 512, num_blocks[3], stride=2) # conv5_x
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
# x5 = self.avgpool(x4)
# out = x5.view(x5.size(0), -1) # 512
# out = self.linear(out)
# return out
return x2, x3, x4
if __name__ == "__main__" :
# 实例化模型
model = CABM_ResNet()
# 生成随机输入张量,形状为 (batch_size, channels, height, width)
input_tensor = torch.randn(32, 3, 320, 1600)
# 获取模型输出
output_x2 = model(input_tensor)
# 打印输出张量的形状
print("Output x2 shape:", output_x2.shape)


















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











