









文章目录
selenium&playwright获取网站Authorization鉴权实现伪装requests请求
本文已实战为主,如果不熟悉selenium或playwright,建议补充相关知识点:
cookie、session、request、headers相关概念
selenium:get_log() 获取用户权限信息,打开指定浏览器,免登陆,伪造请求头
playwright:类方法-Page,Request,Route,Docs-Authentication,Network
本文使用的各个框架版本如下:
python-3.8.8
selenium-3.141.0
playwright-1.32.1
requests-2.27.1
其中selenium4与selenium3的操作有一些差异,这里不做研究。
吐槽一下,playwright的资料是真的很少(基础资料除外),只能自己去看官网,官网写的还是可以的,自己多试试还是可以搞出点东西来的,但真的好累,呜呜呜~
需求背景
1、登录google类web端,通过自动化手段登录会被google监控并屏蔽登录请求,严重有封号风险(在之前的文章有讲过)。
2、selenium或playwright打开指定已登录google账号的浏览器,获取用户鉴权信息。
3、伪造请求头,通过requests获取对应接口的信息,进行数据拉取。
本文实战背景以FireBase后台为列,https://console.firebase.google.com/
没有接触过的,可以用Gmail等其他系列的google应用,但重在思路和方法,详见后文一步步解析。
知识点:selenium获取已登录网站的用户鉴权信息
直接上代码
__author__ = "梦无矶小仔"
import json,time,requests
from datetime import datetime, timedelta
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def get_headers():
# 关键步骤 1:下面两行代码是用来设置特性,获取request的信息前提步骤。
d = DesiredCapabilities.CHROME
d['loggingPrefs'] = {'performance': 'ALL'}
options = webdriver.ChromeOptions()
options.add_experimental_option('useAutomationExtension', False)
# # 防止打印一些无用的日志
options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
options.add_argument("--disable-software-rasterizer")
chrome_options = Options()
chrome_options.add_experimental_option('w3c', False)
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_driver = "./chromedriver.exe" # 我是把chromedriver驱动放在项目根目录下
driver = webdriver.Chrome(executable_path=chrome_driver, options=options, chrome_options=chrome_options)
driver.get("https://console.firebase.google.com/")
info = driver.get_log('performance')
cookie_list = []
for i in info:
dic_info = json.loads(i["message"]) # 把json格式转成字典。
infom = dic_info["message"] # request 信息,在字典的 键 ["message"]['params'] 中。
if infom['method'] == 'Network.requestWillBeSentExtraInfo' and infom["params"]["headers"].get(":authority"):
if infom["params"]["headers"][":authority"] == "mobilesdk-pa.clients6.google.com" and \
infom["params"]["headers"][":method"] == 'POST':
cookie_list.append(infom["params"]["headers"])
authorization = cookie_list[0]["authorization"]
cookie = cookie_list[0]["cookie"]
# 伪造请求头
headers = {
"Host": "crashlytics-pa.clients6.google.com",
"content-type": "application/json",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/96.0.1054.62",
"referer": "https://console.firebase.google.com/",
"cookie": cookie,
"origin": "https://console.firebase.google.com",
"authorization": authorization
}
return headers
代码解析
1、好像没啥解析的,就是通过performance的log去过滤我要的接口,拿到接口中的各项信息
2、哪里看不懂给我留言吧
注意
我使用的是selenium3,如果你是selenium4,你需要使用如下方法获取:
from seleniumwire import webdriver #pip install selenium-wire
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://....') #打开
#获取Authorization_str
Authorization_str=''
for request in browser.requests: #遍历所有 请求
# if request.method == 'POST' and \
# request.url == 'http://....': #找到这个请求
if 'Authorization' in request.headers: #有这个标志
Authorization_str = request.headers['Authorization'] #找到了结果
break
要点:
1、装完selenium后,还得装selenium-wire
from seleniumwire import webdriver #pip install selenium-wire
代替
from selenium import webdriver
2、仅browser 使用 seleniumwire, 其他都不变,例如 By、keys等还用selenium
知识点:playwright获取cookie
playwright官方cookie代码:BrowserContext | Playwright Python
方法一:
自动打开浏览器,手动登录后通过playwright保存cookie到本地,之后需要直接通过文件读取这个cookie。
__author__ = "梦无矶小仔"
from playwright.sync_api import sync_playwright
import json
# 先手动登录,保存Cooies到文件。
def saveCookies():
with sync_playwright() as p:
# 显示浏览器,每步操作等待100毫秒
browser = p.chromium.launch(headless=False, slow_mo=100)
context = browser.new_context()
page = context.new_page()
page.goto('https://cq.meituan.com/', timeout=50000) # 设置超时时间为50s
time.sleep(80) # 此处手动登录,然后到个人信息页再获取cookie
cookies = context.cookies()
print(page.title())
browser.close()
f = open('cookies.txt', 'w+',,encoding="utf-8")
json.dump(cookies, f)
time.sleep(2)
browser.close()
print("cookie获取完毕")
saveCookies()#执行函数
方法二:
手动打开指定浏览器,使playwright指定改浏览器运行,获取已登录的cookie信息,保存到本地。
__author__ = "梦无矶小仔"
# 对已经打开的浏览器进行操作
import json
import subprocess
from pprint import pprint
from playwright.sync_api import Playwright,sync_playwright
playwright = sync_playwright().start()
# 连接已打开浏览器,指定端口
browser = playwright.chromium.connect_over_cdp("http://127.0.0.1:9222")
default_context = browser.contexts[0] # 注意这里不是browser.new_page()了
page = default_context.pages[0]
base_url = r"https://console.firebase.google.com/" # 我这里截去了项目网站的url进行脱敏
page.goto(base_url)
# page.wait_for_timeout(timeout=15000)
print(page.title()) #firebase标题
time.sleep(5)
cookies = default_context.cookies(urls=base_url) #指定url下的cookie值,不填则是所有的
pprint(cookies)
# 保存cookies到本地
filePath = r'cookies.txt'
with open(filePath,'w+',encoding="utf-8") as f:
json.dump(cookies,f)
playwright.stop()
知识点:playwright获取storage_state提取cookie
F12打开浏览器,在Aplication下可以看到本地存储的一些信息,比如cookie、session
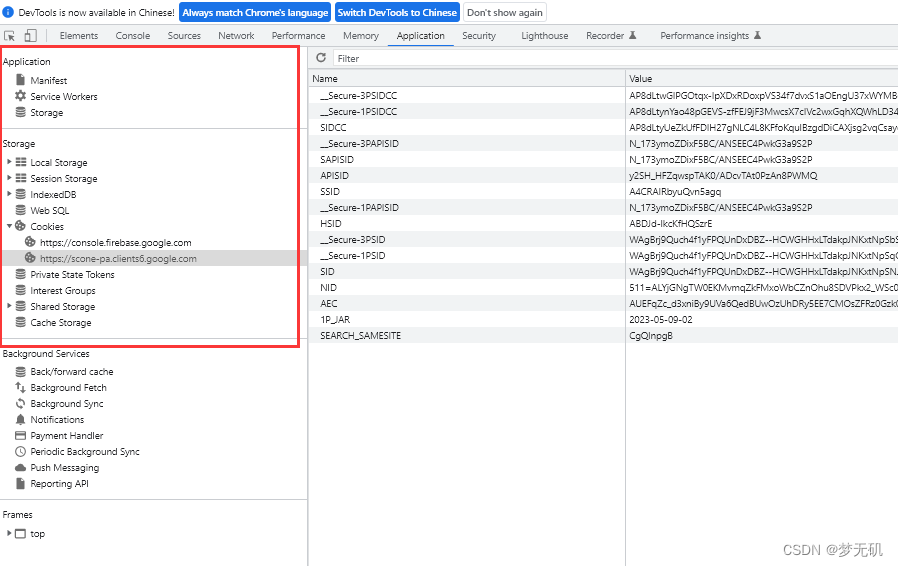
官方教程:BrowserContext | Playwright Python
__author__ = "梦无矶小仔"
# 对已经打开的浏览器进行操作
import json
import subprocess
import time
from pprint import pprint
from playwright.sync_api import Playwright,sync_playwright
playwright = sync_playwright().start()
# 连接已打开浏览器,找好端口
browser = playwright.chromium.connect_over_cdp("http://127.0.0.1:9222")
default_context = browser.contexts[0] # 注意这里不是browser.new_page()了
page = default_context.pages[0]
base_url = r"https://console.firebase.google.com" # 我这里截去了项目网站的url进行脱敏
page.goto(base_url)
print(page.title()) #firebase标题
filePath = r'storage_state.txt'
storage_state = default_context.storage_state(path=filePath)
pprint(storage_state)
playwright.stop()
# browser.close()
但这个方法会有个问题,这里面会把你当前浏览器所有的strong存储的内容拿出来。
如果是像我只是针对某个网站接口的cookie,这个方法就显得有点臃肿,还需要自己去整体过滤,而且本地的还存在一个及时刷新的问题(我遇到过有效期非常短的)。
秃发状况
2023.5.10这天,windows自动更新了,它更新就算了,还自动把我固定版本的chrome浏览器也给更新到了最新版本。
我原先就禁用了chrome自动更新的功能,这次windows更新竟然可以解禁,就很离谱。
这里更新一下windows禁止chrome浏览器自动更新。当前版本是 113.0.5672.93(正式版本) (64 位)
那么浏览器更新了我会遇到一个怎样的问题?
1、selenium是倚靠驱动进行浏览器操作,浏览器更新了我就得更新驱动,但我没有做自动更新驱动的功能
2、之前一直用的是固定某个版本,这样驱动一直用一个就行,现在不得不面临三个选择
-
更新驱动,再次禁用更新,以后遇到再说(麻烦)
-
增加自动更新驱动的功能(后续会意想不到的坑)
-
UI层面改为playwright,因为playwright无需依赖三方驱动(懒汉必备)
于是这三个我都研究了一下,接下来一一解析一下。
windows禁止chrome浏览器自动更新
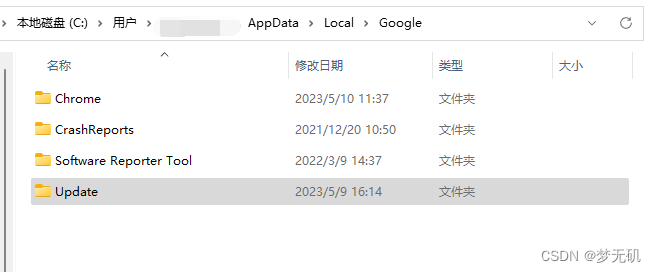
1、找到C:\Users\xiaozai\AppData\Local\Google目录下的Update文件夹
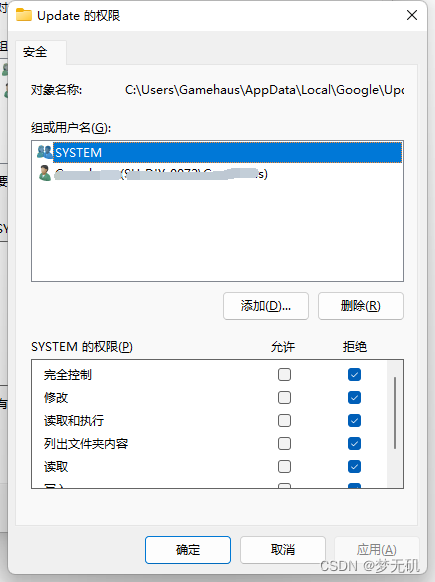
2、右键属性,选择安全选项,点击编辑,把这些用户的权限全部改成拒绝
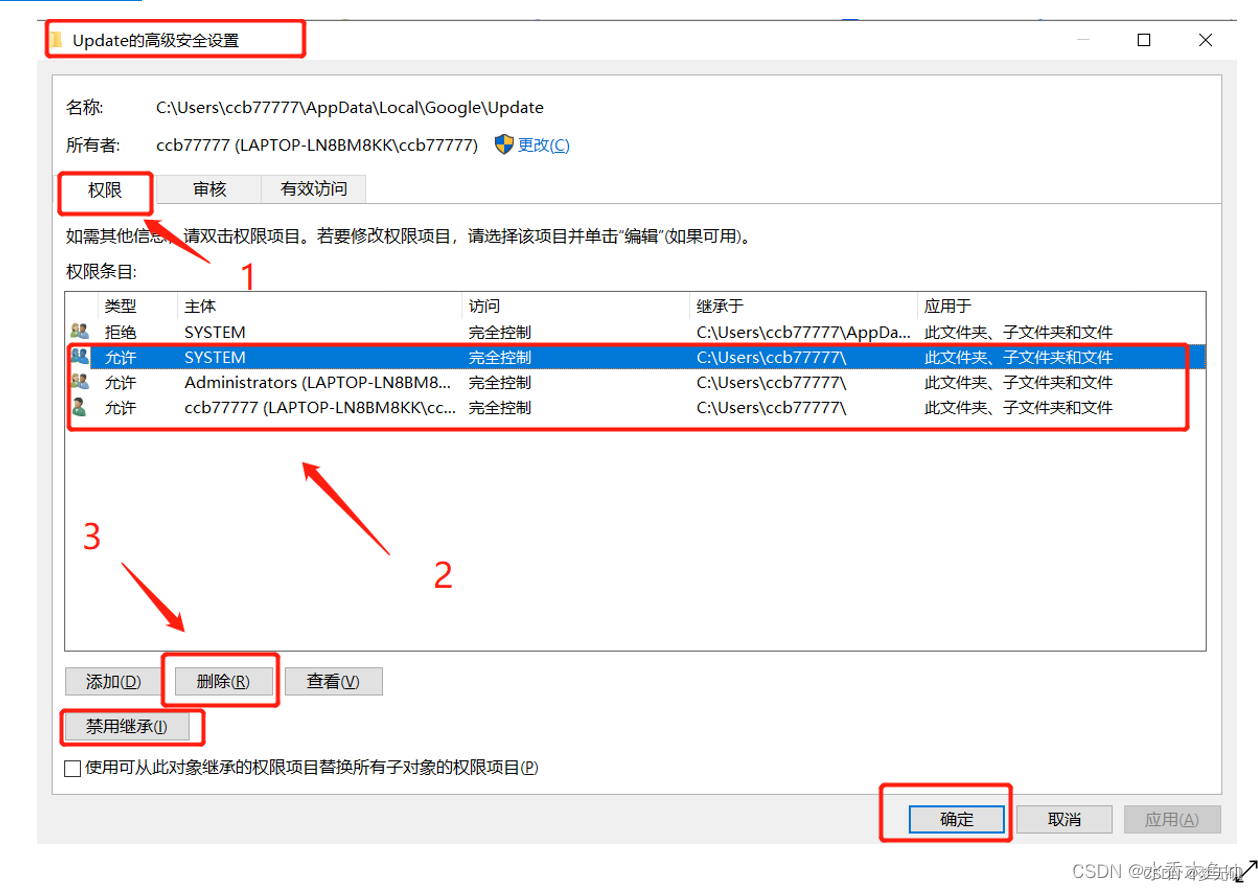
3、在安全选项下,点击高级,点击禁用继承,删除允许用户,点击确认
4、中途点击确认的时候,由于你禁止了权限,会有一堆弹窗,一直点确认就ok了
5、验证,之后你再双击Updata文件夹,发现是无权访问了
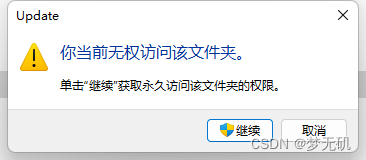
6、去chrome查看更新选项,发现已经无法更新了

selenium自动下载驱动
使用Drivers的方式
官方介绍:https://www.selenium.dev/documentation/webdriver/getting_started/install_drivers/
先安装库:
pip install webdriver-manager
webdriver-manager 支持selenium3.0、selenium4.0
具体可以看github上的说明:https://github.com/SergeyPirogov/webdriver_manager
基于 selenium3 的chrome示列
# pip install webdriver-manager
#selenium3
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(5)
driver.quit()
基于 selenium4 的chrome示列
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from webdriver_manager.chrome import ChromeDriverManager
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Ie(service=service)
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(5)
driver.quit()
是不是非常简单,非常nice?
官方的列子这里我就不放了,大家有兴趣自己去研究哈~
playwright无驱动操作已打开浏览器
详见我之前写的文章,这里就不赘述了,链接如下:
公众号:playwright连接已有浏览器操作 (qq.com)
CSDN:https://blog.csdn.net/qq_46158060/article/details/130429536?spm=1001.2014.3001.5501
Authorization鉴权
对于google类型的所有认证权限都含有一个Authorization,并且加密是SAPISIDHASH,这个我不会破解。
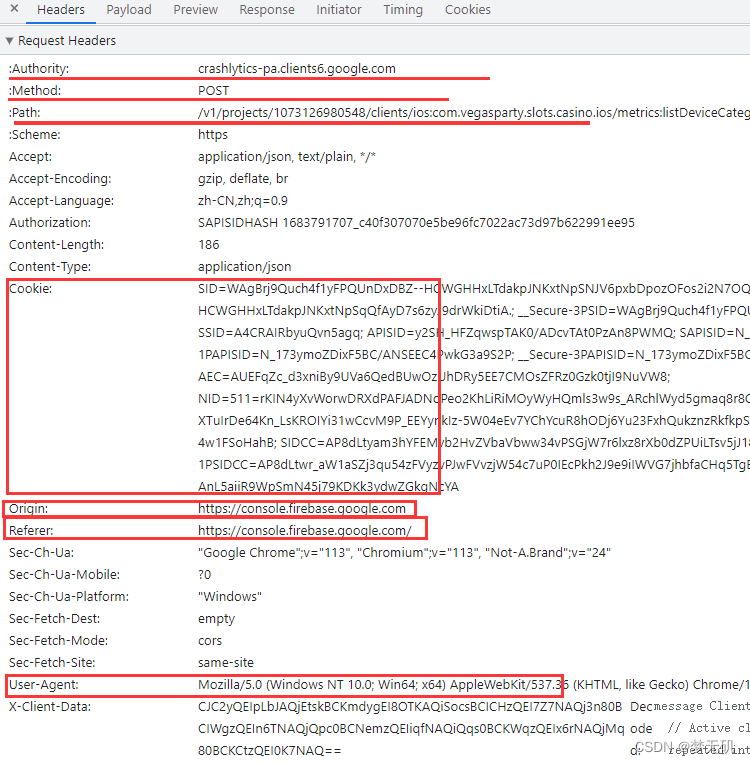
如果请求头不携带此鉴权字段,是无法访问相关接口的。
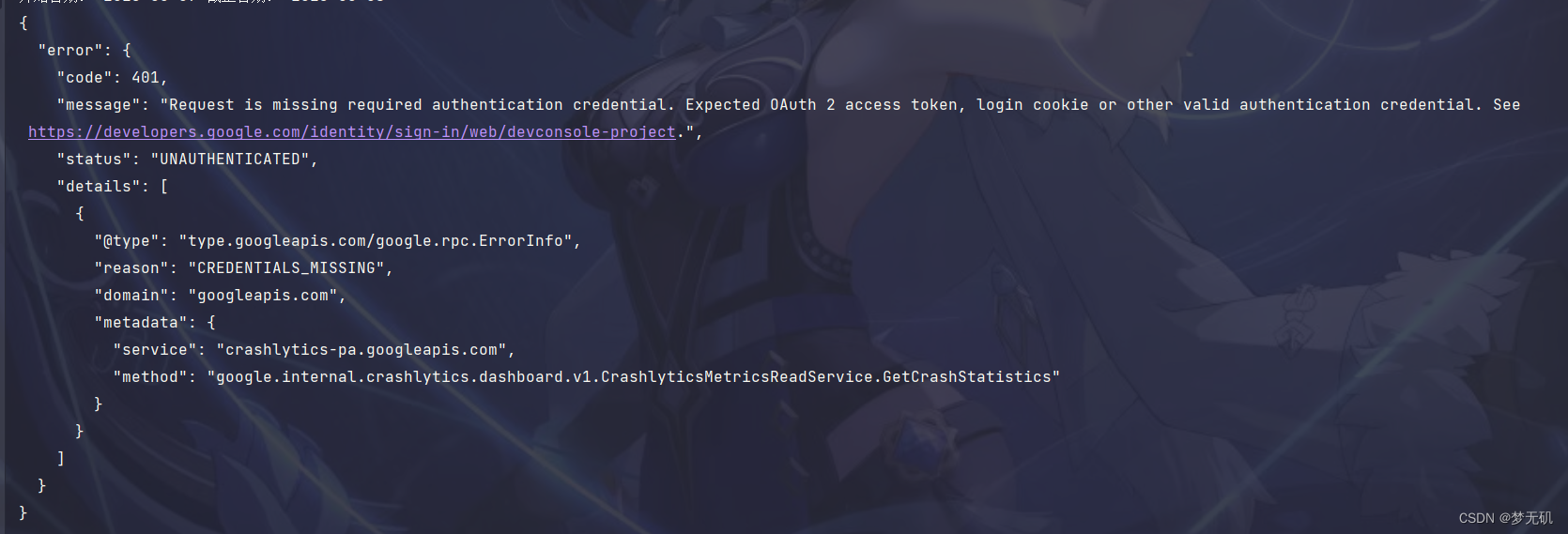
{
"error": {
"code": 401,
"message": "Request is missing required authentication credential. Expected OAuth 2 access token, login cookie or other valid authentication credential. See https://developers.google.com/identity/sign-in/web/devconsole-project.",
"status": "UNAUTHENTICATED",
"details": [
{
"@type": "type.googleapis.com/google.rpc.ErrorInfo",
"reason": "CREDENTIALS_MISSING",
"domain": "googleapis.com",
"metadata": {
"service": "crashlytics-pa.googleapis.com",
"method": "google.internal.crashlytics.dashboard.v1.CrashlyticsMetricsReadService.GetCrashStatistics"
}
}
]
}
}
通过selenium知道可以在performance获取request请求信息(前文有demo),那么playwright是否有类似的方法?
通过查阅官方文档发现,确实有,它叫事件监听。
目前我们就需要拿到请求头的这些信息,从而通过接口进行获取数据。
Authorization
Cookie
Origin
Referer
User-Agent
playwright 事件监听
官方文档:
page.on事件监听:https://playwright.dev/python/docs/api/class-page#page-event-request
request拦截接口:https://playwright.dev/python/docs/api/class-request
事件监听我们主要使用的是page.on("request",my_request),其他监听事件可以参考官网。
Request事件里面有个all_headers方法,会以字典的形式返回我们请求的请求头信息。
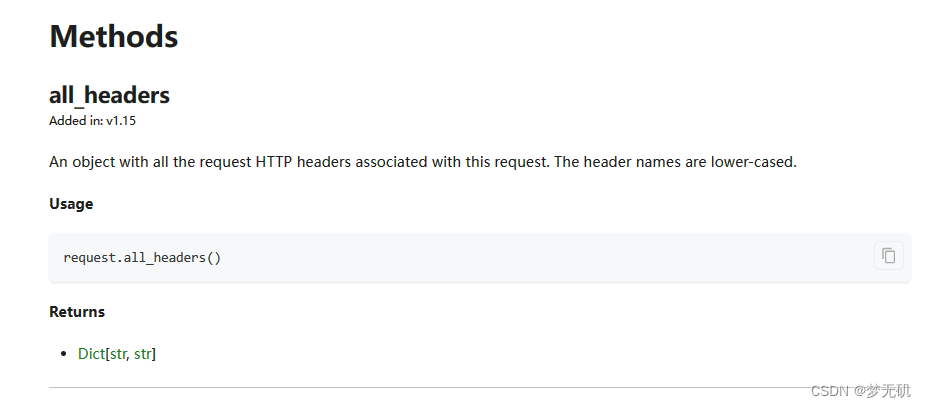
request拦截接口代码示列:
def my_request(request):
print(request.all_headers())
page.on("request",my_request) # 创建拦截请求,获取请求的hearders
# 这里推荐使用requestfinished
注意:page.on在page实例后就要创建,代表监控之后page上发生的对应事件。如果在事件发生后创建page.on方法,则无法监控该事件,只能监控创建page.on之后的操作。
如我监控了FireBase后台数据页面,示列代码如下
import json
from pprint import pprint
import requests
from playwright.sync_api import sync_playwright
def my_request(request):
print(request.all_headers())
# 对headers进行劫持处理
playwright = sync_playwright().start()
# 连接已打开浏览器,找好端口
browser = playwright.chromium.connect_over_cdp("http://127.0.0.1:9222")
default_context = browser.contexts[0] # 注意这里不是browser.new_page()了
page = default_context.pages[0]
page.on("requestfinished",my_request) # 创建拦截请求,获取请求的hearders
base_url = r"https://console.firebase.google.com/"
page.goto(base_url)
page.wait_for_load_state('networkidle') #等待资源加载,直到没有网络请求,否则得到的资源不完整,拿不到想要的鉴权信息
控制台输出监控到了的所有请求头信息,authorization字段赫然在列,我们可以继续改造my_request方法,拿到我们所需要的headers信息。

但这个时候还遇到个问题,这里获取到的authorization并不是我真正能够使用的,我还需要对referer字段进行过滤,但发现并没有我要找的,F12查看network发现前端是刷新出来了。打印出来的却全是https://console.firebase.google.com/
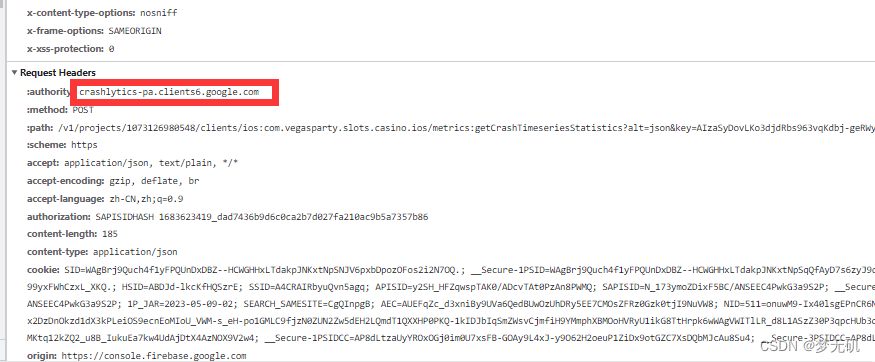
需要在请求后加上这句,表示等待资源加载,直到没有网络请求。详细可以看官网:https://playwright.dev/python/docs/api/class-page#page-wait-for-load-state
page.wait_for_load_state('networkidle')
但有时候也会有点不灵,所以我推荐使用强制等待。
page.wait_for_timeout(timeout=20000) # 这个timeout是毫秒
接下来需要对这些请求头进行过滤,我只需要拿到一个包含Authorization字段的headers字段的信息就可以结合前面拿到的cookie进行伪造了。
同时过滤:authority字段,注意,F12你看到的首字母是大写,playwright官方文档中有说明,headers返回的都是小写字段,所以我们拿的时候要以小写的方式进行提取。
改造后的my_request方法
# 全局变量
user_headers = {}
def my_request(request):
all_headers_dict = request.all_headers()
# 过滤请求(这里我对:path也进行了过滤,完整path我脱敏处理了)
if all_headers_dict.get(':path') == "/metrics:getCrashFree.." and not user_headers:
if all_headers_dict[":method"]=='POST' and all_headers_dict[":authority"]=='crashlytics-pa.clients6.google.com' :
# 提取我需要的信息
user_headers["cookie"] = all_headers_dict.get("cookie")
user_headers["user-agent"] = all_headers_dict.get("user-agent")
user_headers["authorization"] = all_headers_dict.get("authorization")
最终会将第一次获取到的headers信息记录到user_headers字典中。
接着我们就可以使用requests进行携带带有认证信息的请求头进行接口请求了。
使用route劫持
官方文档:Route | Playwright Python
用这个方法也可以获取到请求头的相关信息,它最终还是使用了request获取请求头。
我在使用的过程中发现有时候请求会被阻塞,不知道为啥,对这方面有研究的大佬请指教我一哈,万分感谢。
user_msg_list = []
def handler(route):
headers_dict = {}
all_headers_dict = route.request.headers
if all_headers_dict.get('authorization') and all_headers_dict.get('cookie'):
# if 'https://scone-pa.clients6.google.com/static/proxy' in all_headers_dict["referer"]:
# 提取我需要的信息
headers_dict["referer"] = all_headers_dict.get("referer")
headers_dict["user-agent"] = all_headers_dict.get("user-agent")
headers_dict["authorization"] = all_headers_dict.get("authorization")
headers_dict["cookie"] = all_headers_dict.get("cookie")
user_msg_list.append(headers_dict)
route.continue_()
page.route(**/*,handler)
page.wait_for_load_state('networkidle')
最终代码
注意:对敏感信息已脱敏
# -*- coding: utf-8 -*-
'''
@Time : 2023/5/10 13:42
@Author : Vincent.xiaozai
@Email : Lvan826199@163.com
@File : demo06_整合请求伪造.py
'''
__author__ = "梦无矶小仔"
import json
import subprocess
import time
from datetime import datetime, timedelta
from pprint import pprint
import requests
from playwright.sync_api import Playwright,sync_playwright
# 全局变量
user_headers = {}
def my_request(request):
all_headers_dict = request.all_headers()
# 过滤请求
if all_headers_dict.get(':path') == "/metrics:getCrashFreeTime..." and not user_headers:
if all_headers_dict[":method"]=='POST' and all_headers_dict[":authority"]=='crashlytics-pa.clients6.google.com' :
# 提取我需要的信息
user_headers["cookie"] = all_headers_dict.get("cookie")
user_headers["user-agent"] = all_headers_dict.get("user-agent")
user_headers["authorization"] = all_headers_dict.get("authorization")
user_headers["referer"] = all_headers_dict.get("referer")
user_headers["origin"] = all_headers_dict.get("origin")
playwright = sync_playwright().start()
# 连接已打开浏览器,找好端口
browser = playwright.chromium.connect_over_cdp("http://127.0.0.1:9222")
default_context = browser.contexts[0] # 注意这里不是browser.new_page()了
page = default_context.pages[0]
page.on("requestfinished",my_request) # 创建拦截请求,获取请求的hearders
base_url = "https://console.firebase.google.com/u/0/project/..." #完整url已脱敏
page.goto(base_url)
# 如果要保证刷新可以强制等待
page.wait_for_timeout(timeout=20000)
# 请求头伪造
headers = {
"Host": "crashlytics-pa.clients6.google.com",
"content-type": "application/json",
'user-agent':user_headers["user-agent"],
"referer": user_headers["referer"],
'cookie':user_headers["cookie"],
"origin": user_headers["origin"],
'authorization': user_headers["authorization"]
}
print("---------------用户cookie及Authorization--------------------------")
print(f"伪造的请求头:{headers}")
print("---------------用户cookie及Authorization--------------------------")
## 执行request请求获取数据
crashAndUsersUrl = "https://crashlytics-pa.clients6.google.com/v1/projects" # 完整url已脱敏
crashAndUsersNum = get_all_crashAndUser(day=2,headers=headers,url=crashAndUsersUrl,the_latest="None",version_bt_list="None",platform='Android',eventType=["FATAL"])
print("----------接口信息打印-------------------")
print(crashAndUsersNum)
这里的get_all_crashAndUser就是我的业务代码,里面是对接口的请求进行了处理,这里就不放出来了。
可以看到最终我们拿到了这个接口的信息。
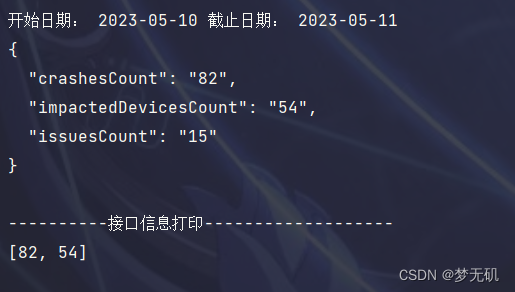
在之后的操作中,就可以一直使用requests进行接口请求了,如果cookie有使用有效期,那么每隔一段时间用playwright进行重新获取,重新伪造请求头就可以了。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









