







系统化、技术性、战略性 的 AlphaGo 深度解析。以下内容将从 五大板块 来全面展开:
🧠 一、AlphaGo 的诞生背景:为何围棋如此困难?
1. 围棋对AI的挑战
- 搜索空间极大:围棋盘是 19x19,总共有 361 个位置,一盘棋平均可能落子 200 步以上,每一步可能有 150+ 种选择。
- 状态总数:约为 (10^{170}),远远超过国际象棋(约 (10^{47}))和宇宙中原子的数量(约 (10^{80}))。
- 没有明确的中间胜负判断:不像国际象棋中可以“吃子”,围棋中的优劣通常很难直观判断,依赖对局势全局判断。
2. 传统AI方法的局限
- IBM 的 Deep Blue 依靠穷举搜索打败了卡斯帕罗夫,但这种方式无法适用于围棋。
- 早期围棋AI(如 Crazy Stone、Zen)虽然使用了蒙特卡洛方法,但难以与顶尖职业选手抗衡。
⚙️ 二、AlphaGo 的核心技术架构详解
核心模块一:深度神经网络
1. 策略网络(Policy Network)
- 输入:当前棋盘状态(使用特征编码,包括落子顺序、提子情况、禁入点等)
- 输出:对每个位置的落子概率预测
- 作用:指导搜索树中优先扩展的节点,减少不必要的搜索
2. 价值网络(Value Network)
- 输入:当前棋局
- 输出:该局面对 AlphaGo 而言的胜率(0~1)
- 作用:取代传统的“模拟完一局”来判断结果,节省大量计算时间
核心模块二:蒙特卡洛树搜索(MCTS)
工作流程:
- 选择(Selection):从根节点出发,按公式 (Q + U) 选择最优子节点。
- (Q):节点的平均价值
- (U):置信上界,代表探索值
- 扩展(Expansion):策略网络提供新的候选动作
- 评估(Evaluation):通过价值网络(或模拟)评估局势
- 回传(Backup):将结果反向传播更新树中各节点的统计值
MCTS 结合策略网络的先验知识与价值网络的评估能力,实现远优于纯搜索的效率与质量。
🧪 三、训练流程:从人类智慧到超越人类
1. 监督学习阶段(Supervised Learning)
- 使用 30 万份人类职业棋谱作为训练数据
- 训练策略网络模仿人类走法
- 精度达到人类职业水平(准确率约 57%)
2. 强化学习阶段(Reinforcement Learning)
- AlphaGo 自己和自己对弈,通过胜负奖励优化策略
- 策略网络不断进化,提升探索能力
3. 价值网络训练
- 收集自我对弈的局面和最终胜负
- 学习在任意状态下预测胜率,替代完全模拟的代价
4. 搜索优化
- 每次落子评估数千个分支,但利用神经网络有效压缩无意义搜索
- 强化后的模型胜率大幅超越监督学习版
🏆 四、三大战役回顾与战术分析
1. AlphaGo vs 樊麾(2015)
- 5:0 轻松取胜
- 樊麾评价:“它不像机器,更像是一个沉稳而高明的对手。”
2. AlphaGo vs 李世石(2016)
- 比分:AlphaGo 4:1 李世石
- 第4局:李世石第78手是反击奇招,打破了AlphaGo的预测路径
- 赛后李世石说:“AlphaGo让我更了解自己,也更尊重AI。”
3. AlphaGo vs 柯洁(2017)
- 3:0 完胜
- 柯洁泪洒赛场,表示“我拼尽全力,却无法找到胜机”
🌐 五、进化:AlphaGo Zero、AlphaZero 与 MuZero
1. AlphaGo Zero
- 训练时完全不使用人类棋谱
- 通过“自我博弈+强化学习”从0开始,仅3天超越原始AlphaGo
- 使用残差神经网络(ResNet)提升训练速度与稳定性
2. AlphaZero
- 通用版本,适配多种博弈游戏(围棋、国际象棋、日本将棋)
- 同样从零开始学习,仅数小时超越最强程序(如 Stockfish)
3. MuZero
- 不再需要明确的规则模型
- 仅通过观察状态和奖励序列,学习环境动态
- 可推广至控制任务、视频游戏(如 Atari)等非博弈领域
🔮 六、AlphaGo 对社会和科技的深远影响
| 领域 | 影响 |
|---|---|
| 围棋 | 促使人类棋手革新布局思维,如“AI流布局”“大模样消失” |
| AI研究 | 深度强化学习走向主流,带动 RL 和 Transformer 结合研究 |
| 产业界 | 医疗诊断、物流调度、量化投资等都开始借鉴 MCTS 框架 |
| 教育界 | 用 AlphaGo 案例讲解智能体、博弈论、强化学习等课程 |
✅ 总结:AlphaGo 是人工智能的里程碑
| 模块 | 内容概述 |
|---|---|
| 技术基础 | 深度神经网络 + 蒙特卡洛树搜索 |
| 训练过程 | 人类棋谱 → 自我博弈 → Zero化 |
| 比赛表现 | 连胜樊麾、李世石、柯洁等世界顶尖高手 |
| 后续进化 | AlphaZero、MuZero 打破规则和应用边界 |
| 科技影响 | 推动AI通用智能发展,启发多个交叉行业应用 |
如果你想继续深入,我们还可以聊:
- AlphaGo Zero 的代码架构设计;
- 柯洁大战的每一步解析;
- 如何用 Python 模拟一个小型 AlphaGo;
- AlphaGo 的强化学习部分(用到了什么样的 reward shaping 和 policy update)……
“状态空间复杂度”是理解 AlphaGo 成为突破性成就的一个核心概念。下面我们就从基础概念讲起,一步步展开讲清楚围棋的状态空间为何如此庞大、它给AI带来哪些挑战、以及 AlphaGo 是如何应对这一挑战的。
🧩 一、什么是状态空间复杂度?
状态空间复杂度(State Space Complexity) 指的是一个系统中所有**合法状态(局面)**的总数量。对于博弈类问题,比如棋类游戏,一个“状态”就是一个合法的棋盘布局。
- 更通俗地说:状态空间就是“你能走出多少种不同的完整棋局”。
📈 二、围棋的状态空间有多大?
1. 公式估算(近似值)
以标准 19x19 的围棋为例:
- 棋盘有 361 个位置,每个位置可以是 黑子、白子或空。
- 所有可能状态上限是 (3^{361} \approx 10^{172}),这是理论上限,但包含了非法状态(如“两个眼被提走”这种不合法情况)。
- 实际合法局面数量大约是:
[
\text{约 } 2 \times 10^{170}
]
2. 与其他游戏对比:
| 游戏 | 状态空间复杂度 | 动作空间(每一步选择数) |
|---|---|---|
| 井字棋 | (10^3) | < 9 |
| 国际象棋 | (10^{47}) | 平均 < 35 |
| 将棋 | (10^{71}) | 平均 < 80 |
| 围棋(19x19) | (10^{170}) 🔥 | 平均 200+ |
🔍 围棋的状态空间是国际象棋的 (10^{123}) 倍,是人类无法用枚举、启发式搜索解决的维度。
🧠 三、为何围棋的状态空间如此庞大?
1. 棋盘大(19x19)
- 多达 361 个位置
- 远多于国际象棋的 64 格
2. 每步棋几乎没有固定模板
- 国际象棋有“规则制约”,很多子力不能随意出现在特定位置
- 围棋几乎任何位置都能落子,只需不违反提子、禁入等规则
3. 棋局较长(对局平均200步)
- 局面变化连续、缓慢,形成更多中间状态
- 无“吃子清盘”机制,整局都需保持状态
⚠️ 四、AI 面临的挑战
1. 穷举搜索不可行
- 若每步选择 200 种可能,模拟 10 步需评估 (200^{10} \approx 10^{23}) 个状态
- 即使用超级计算机也无法穷举如此大的空间
2. 没有清晰中间状态评分
- 围棋不像国际象棋那样可以通过“吃子”来度量优势
- 只能通过模糊的地势、气、厚势来估算优劣
3. 延迟奖励问题
- 一步棋对胜负影响可能要在几十步后才体现(强化学习中称为 credit assignment problem)
🧬 五、AlphaGo 如何应对这一复杂性?
1. 策略网络(Policy Network)
- 用神经网络提前预测哪些落子是“高概率好手”
- 在搜索前就过滤掉大部分无效状态
2. 价值网络(Value Network)
- 评估当前棋局,预测胜率,避免搜索至棋局终局
3. 蒙特卡洛树搜索(MCTS)
- 利用模拟 + 神经网络估值,对搜索路径进行概率引导
- 只扩展潜在“好局面”,极大降低状态空间实际访问量
4. 自我博弈学习
- 只探索有效战术路径,强化有意义的状态
- 训练中不会遍历所有状态空间,而是聚焦于策略相关子空间
🔭 六、类比理解:状态空间 vs 地图探索
可以把状态空间类比为整个宇宙地图:
- 若没有指引(像传统搜索AI),就像宇航员盲目在宇宙中漂浮寻找目标星球。
- 而 AlphaGo 像是拥有了一台高精度导航仪(策略网络)和智能筛选系统(价值网络+MCTS),只在高价值区域“探索”。
✅ 总结:状态空间复杂度的意义
| 内容 | 说明 |
|---|---|
| 定义 | 所有合法棋局构成的空间大小 |
| 围棋难度 | 超过 (10^{170}),为地球最复杂策略类游戏之一 |
| 传统AI问题 | 无法穷举、不易评估、奖励延迟 |
| AlphaGo优势 | 降维搜索、策略引导、自我强化、高效评估 |

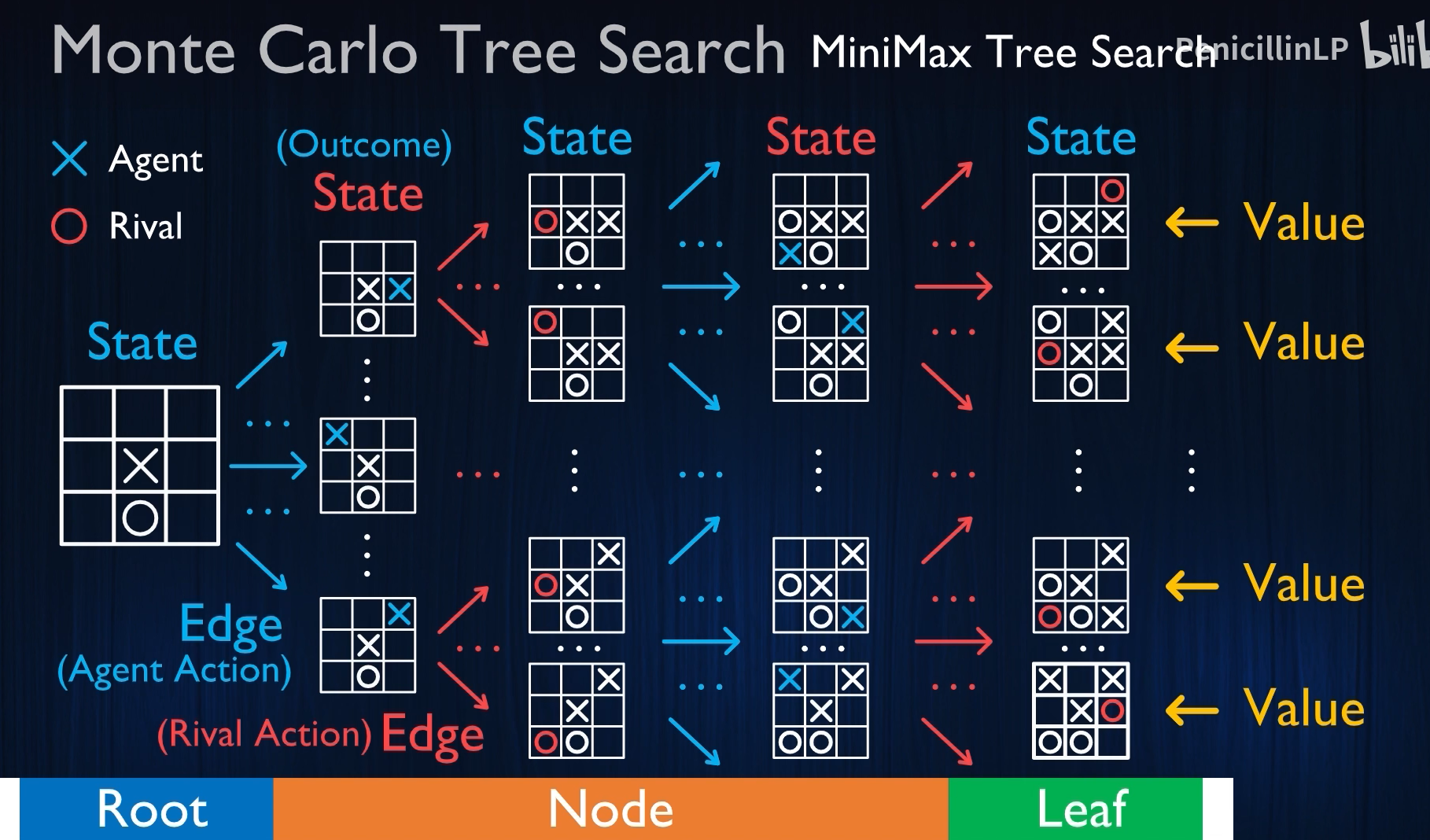
我们现在来深入讲解人工智能特别是在蒙特卡洛树搜索(MCTS) 和 博弈树搜索中经常出现的术语:“根(Root)”、“枝(Branch)”、“叶(Leaf)”。
这三个术语源于**树结构(Tree Structure)**的抽象模型,是理解 AlphaGo、AlphaZero、MuZero 等智能体决策机制的基础概念。
🌳 一、什么是树结构?(Tree Structure)
在 AI 中,特别是博弈问题、路径规划和搜索中,“树结构” 是一种有层级关系的状态模型。从一个初始状态出发,每一次行动都会进入一个新状态,逐步扩展出一个状态树。
就像一棵倒着长的树:
- 根(Root):树的起点,代表当前状态或初始状态。
- 枝(Branch):从一个状态走向另一个状态的动作或选择。
- 叶(Leaf):终端状态(局面已完结,或达到搜索深度限制)。
🧩 二、根(Root Node)详解
1. 定义:
“根”是整棵搜索树的起点,代表当前棋局或当前状态。
在 AlphaGo 中:
- 每次落子前,根节点就是当前的棋盘局面。
- 所有后续模拟、评估、扩展,都是从根节点出发。
2. 特点:
- 唯一(每棵树只有一个根)
- 每次决策更新根:一旦AlphaGo落子,原先选择的子节点就变成新的根
3. 示例:
根(当前棋局)
|
┌──┴──┐
分支1 分支2 ...
🌿 三、枝(Branch)详解
1. 定义:
“枝”代表的是从一个状态转移到另一个状态的动作,即“做出一个选择”。
在围棋中,每一个“落子”就是一条“枝”。
2. 特点:
- 每个节点可以有多个分支(例如可能落子的点)
- 分支数量决定了搜索空间宽度(围棋中平均 > 200)
3. 示例:
从根出发,你可以落子在:
- A3 → 分支1
- D4 → 分支2
- R16 → 分支3
根(当前棋局)
├── 落子A3 → 新局面1
├── 落子D4 → 新局面2
└── 落子R16 → 新局面3
4. 在 MCTS 中的意义
每一条枝代表一条“模拟路径”,通过策略网络评估后会为这条路径赋予概率与价值。
🍃 四、叶(Leaf Node)详解
1. 定义:
“叶”是当前模拟路径的终点:
- 可以是对局终局(胜负已定)
- 也可以是搜索深度限制的终点
- 或者是尚未扩展的节点
2. 在 AlphaGo 中的意义:
- 如果叶节点是已结束局面,则可以直接计算胜负;
- 如果是未结束,则由价值网络评估当前胜率。
3. 示例:
根(当前状态)
|
分支(动作)
|
中间节点
|
分支(动作)
|
叶(终止节点) ← 模拟终点
4. 叶的策略更新:
MCTS 中的**反向传播(Backup)**从叶节点把评估值传回根节点,更新各路径的价值期望。
🔁 五、它们之间的工作流程(以 AlphaGo 为例)
一次 AlphaGo 的决策过程:
- 根节点:当前棋局作为起点;
- 策略网络:预测每个可能落子的概率 → 生成若干条分支;
- 模拟路径:沿某条分支扩展(策略引导 + 探索引导);
- 叶节点:
- 若为终局 → 直接记录胜负;
- 若为中间局面 → 使用价值网络评估胜率;
- 反向传播:从叶将评估值回传给根,更新所有经过的分支路径;
- 重复执行上面步骤,直到模拟次数达到上限;
- 根节点选择模拟次数最多的分支执行落子。
🎓 六、图示理解
根(当前棋盘状态)
/ | \
分支1 分支2 分支3(落子选择)
| | \
中间状态1 中间状态2 中间状态3
| | |
叶1 叶2 叶3(终止局面或评估)
🧠 七、总结对照表
| 概念 | 定义 | 在 AlphaGo 中的作用 |
|---|---|---|
| 根(Root) | 当前棋局状态的起点 | 每一次决策开始的状态 |
| 枝(Branch) | 动作选择、落子行为 | 决定搜索的路径方向 |
| 叶(Leaf) | 模拟终点、局面终结或中止 | 提供评估信息,反向传播值函数 |


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









