







overfitting过拟合
拥有大量自由参数的模型能够描述特别神奇的现象。但是即使这样的模型能够很好的拟合已有数据,他并不是一个好模型。因为这可能只是因为模型中⾜够的⾃由度使得它可以描述⼏乎所有给定⼤⼩的数据集,⽽不需要真正洞察现象的本质(即并没有找到他们的公共特征)。所以发⽣这种情形时,模型对已有的数据会表现的很好,但是对新的数据很难泛化。对⼀个模型真正的测验就是它对没有见过的场景的预测能⼒。
让我们通过构造⼀个网络泛化能⼒很差的例⼦使这个问题更清晰。我们的⽹络有 30 个隐藏神经元,共 23,860 个参数。但是我们不会使⽤所有 50,000 幅 MNIST 训练图像。相反,我们只使⽤前 1,000 幅图像。使⽤这个受限的集合,会让泛化的问题突显。我们使⽤交叉熵代价函数,学习速率设置为
η
\eta
η = 0.5,并且将Mini-Batch设置为 10。不过这⾥我们要训练 400 个epoch,
使用上述网络,我们可以画出当网络学习时代价变化的情况:
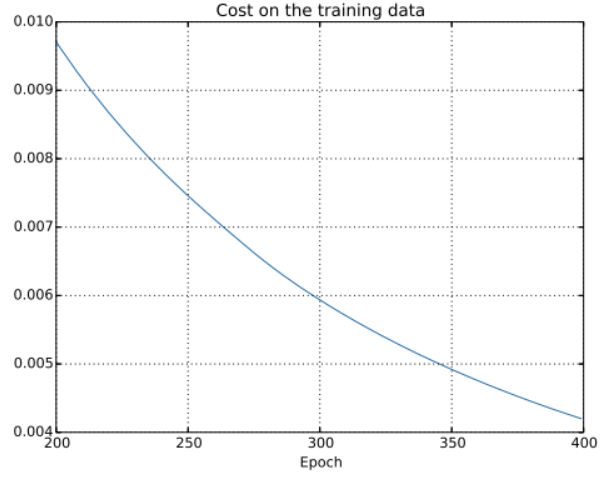
这看起来非常不错,因为代价函数有一个光滑的下降,跟我们预期一致(这里仅给出了后面200个迭代期)。
接下来我们看看分类准确率在测试集上的表现:
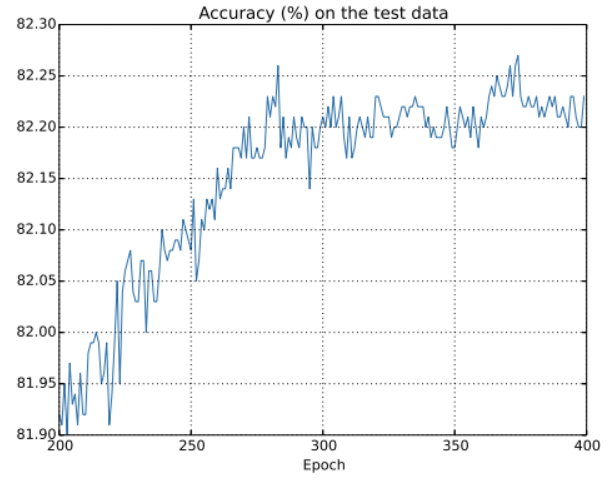
这里还是聚焦到了后面的过程。在前二百个周期中准确率提升到了82%,然后学习逐渐变缓,最终,在280个epoch左右时分类准确率就停止了增长。后面的Epoch,仅仅看到了在280个迭代期所得到的准确率周围随机小波动。
将这幅图与前面的图进行对比,前面的图中和训练数据相关的代价持续平滑下降,如果我们仅看那个代价,会发现我们的模型变得更好。但是测试准确率展示了这种提升只是一种假象。我们的网络在280个迭代期后就不在能够推广到测试数据上,所以这不是有用的学习。我们这时候就认为我们的网络在280个Epoch后就 过度拟合(overfitting) 或者 过渡训练(overtraining) 了
接下来我们再看一下代价函数在测试数据上的变化:
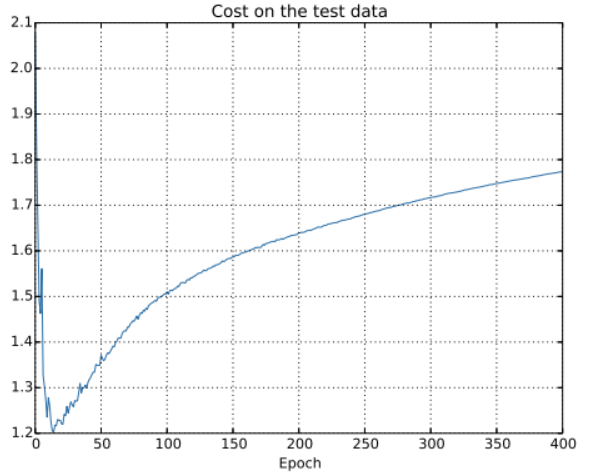
我们可以看到测试集上的代价在15个Epoch前一直在降低,随后越来越差尽管训练数据集上的代价表现是越来越好的。这其实是另一种模型过渡拟合的迹象。
但是,我们又碰到了另一个问题,从测试数据的准确率来看,过渡拟合是在280个Epoch之后的;从代价函数来看,过渡拟合是在15个Epoch之后的,那么究竟是将15还是280当做是过渡拟合开始影响学习的时间点呢?从实践的角度来看,我们真正关心的是提升测试数据集上的分类准确率,而测试集合上的代价不过是分类准确率的一个反映,所以更加合理的选择是将280迭代期看成过度拟合开始影响学习的时间点。
过度拟合是神经网络的⼀个主要问题。因为网络权重和偏置数量巨⼤,这在现代网络中特别正常。为了高效地训练,我们需要⼀种检测过度拟合是不是发⽣的技术,这样我们不会过度训练。并且我们也想要找到⼀些技术来降低过度拟合的影响。
检测过度拟合的明显方法是使用上面的方法 —— 跟踪测试数据集合上的准确率随训练变化情况。如果我们看到测试数据上的准确率不再提升,那么我们就停止训练。也就是说,一旦分类准确率已经饱和,就停止训练。这个策略被称为 early stopping(提前结束)
Regularization 规范化
增加训练样本的数量是一种减轻过拟合的方法。另一种可行的方法就是降低网络的规模。然而不幸的是,大的网络拥有一种比小网络更强的前路,所以这里存在一种应用冗余性的选项。
除此之外,还有其他的技术能够缓解过渡拟合,这里讲到的就是Regularization(规范化)。这里会给出一种最为常用的规范化手段——有时候被称为weight decay(权重衰减)或者L2规范化。
L2规范化的想法是增加一个额外的项到代价函数上,这个项叫做regularization term(规范化项)。
下面是规范化的cross-entropy:
C
=
−
1
n
∑
x
j
[
y
j
ln
a
j
L
+
(
1
−
y
j
)
ln
(
1
−
a
j
L
)
]
+
λ
2
n
∑
w
w
2
(1)
C=-\frac 1 n \sum_{xj}[y_j \ln a_j^L + (1-y_j)\ln(1-a_j^L)]+\frac \lambda {2n} \sum_w w^2 \tag1
C=−n1xj∑[yjlnajL+(1−yj)ln(1−ajL)]+2nλw∑w2(1)
其中第一项就是常规的cross-entropy表达式。第二个现在加入的就是所有权重的平方和。然后使用一个因子
λ
2
n
\frac \lambda {2n}
2nλ进行量化调整,其中
λ
>
0
\lambda \gt 0
λ>0称为regularization parameter(规范化项),
n
n
n表示的还是训练集合的大小。需要注意的是,规范化项里面并不包含偏置。
当然,对于其他的代价函数也可以进行规范化,类似的规范化形式可以写成这样,其中
C
0
C_0
C0是原始的代价函数:
C
=
C
0
+
λ
2
n
∑
w
w
2
(2)
C=C_0+\frac \lambda {2n} \sum_w w^2 \tag2
C=C0+2nλw∑w2(2)
直觉地看,规范化的效果是让网络倾向于学习小一点的权重,其他东西都是一样的。大的权重只有能够给出代价函数的第一项足够的提升后才会被允许。换言之,规范化可以当做一种寻找小的权重和最小化原始的代价函数之间的折中。这两部分之间相对的重要性就由
λ
\lambda
λ的值来控制,
λ
\lambda
λ越小,就越倾向于最小化原始代价函数,反之,则倾向于小的权重。
接来下我们来了解一下如何将梯度下降算法应用在一个规范化的神经网络上。我们首先对式(2)求导得:
∂
C
∂
w
=
∂
C
0
∂
w
+
λ
n
w
(3)
\frac {\partial C}{\partial w} =\frac {\partial C_0}{\partial w}+\frac \lambda n w \tag3
∂w∂C=∂w∂C0+nλw(3)
∂ C ∂ b = ∂ C 0 ∂ b (4) \frac {\partial C}{\partial b} =\frac {\partial C_0}{\partial b}\tag4 ∂b∂C=∂b∂C0(4)
通过公式我们可以看到其实计算规范化的代价函数的梯度是很简单的,$\frac {\partial C_0}{\partial w}
和
和
和\frac {\partial C_0}{\partial b}
可
以
通
过
反
向
传
播
进
行
计
算
,
然
后
加
上
可以通过反向传播进行计算,然后加上
可以通过反向传播进行计算,然后加上\frac \lambda n w$得到所有权重的偏导数。而偏置的偏导数就不要变化,所以偏置的梯度下降和学习规则不会发生变化:
b
→
b
−
η
∂
C
0
∂
b
(5)
b\rightarrow b-\eta \frac{\partial C_0}{\partial b} \tag5
b→b−η∂b∂C0(5)
权重的下降规则则变成了:
w
→
w
−
η
∂
C
0
∂
w
−
η
λ
n
w
=
(
1
−
η
λ
n
)
w
−
η
∂
C
0
∂
w
(6)
\begin{aligned} w&\rightarrow w-\eta \frac {\partial C_0}{\partial w}-\frac{\eta \lambda}n w\\ &=(1-\frac {\eta \lambda}{n})w-\eta \frac{\partial C_0}{\partial w} \end{aligned} \tag 6
w→w−η∂w∂C0−nηλw=(1−nηλ)w−η∂w∂C0(6)
这正和通常的梯度下降学习规则相同,除了通过一个因子
1
−
η
λ
n
1-\frac {\eta \lambda}{n}
1−nηλ重新调整了权重
w
0
w_0
w0。这种调整被称为weight decay(权重衰减),因为它使得权重变小。
这就是梯度下降工作的原理,接下来再说一下随机梯度下降是怎么工作的。
正如在没哟规范化的随机梯度下降中,我们可以通过平均m个训练样本的小批量数据来估计 ∂ C 0 ∂ w \frac {\partial C_0}{\partial w} ∂w∂C0。
因此,随机梯度下降的规范化学习规则就变成了:
w
→
(
1
−
η
λ
n
)
w
−
η
m
∑
x
∂
C
x
∂
w
(7)
w\rightarrow(1-\frac {\eta \lambda}{n})w-\frac \eta m \sum_x \frac{\partial C_x}{\partial w} \tag7
w→(1−nηλ)w−mηx∑∂w∂Cx(7)
其中后面一项是在训练样本的小批量数据
x
x
x上进行的,而
C
x
C_x
Cx是对每个训练样本的(无规范化的)代价。这其实和之前通常的随机梯度下降的规则是一样的,除了有一个权重下降的因子
1
−
η
λ
n
1-\frac {\eta \lambda} n
1−nηλ。
偏置的规范化的学习规则与非规范化的情形一致:
b
→
b
−
η
m
∂
C
0
∂
b
(8)
b\rightarrow b-\frac \eta m \frac{\partial C_0}{\partial b} \tag8
b→b−mη∂b∂C0(8)
规范化对神经网络性能的影响
接下来规范化对于神经网络带来的性能提升。这里大多数和第一个例子一致,使用30个隐藏神经元,Mini-Batch为10,学习速率为0.5,使用交叉熵的神经网络,并且设置 λ = 0.1 \lambda = 0.1 λ=0.1。
训练集上的代价函数如下,和前面无规范化的情况一样的规律:
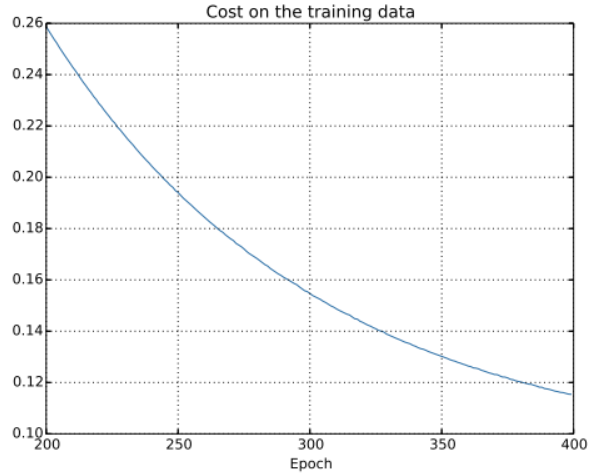
但是这次测试集上的准确率在整个400个Epoch内持续增加
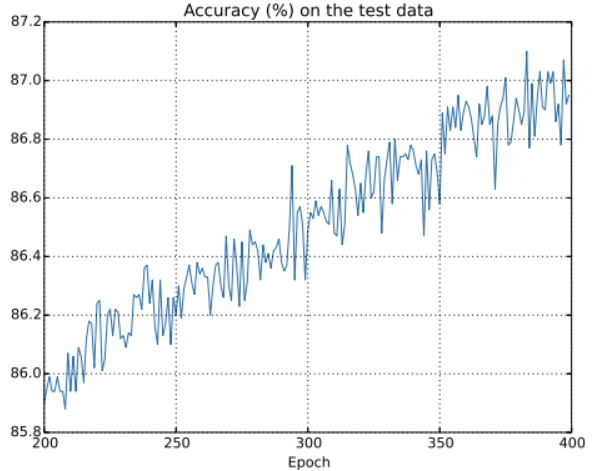
显然,规范化的使用能解决过渡拟合的问题,并且准确率相当高。同时,我们也可以确定,在400个Epoch后如果继续训练可以得到更好的结果
我们可以将规范化描述为一种减轻过度拟合和提高分类准确率的方法。实际上,这不是仅有的好处。实践标明,在使用不同的(随机)权重初始化进行多次MNIST网络训练的时候,无规范化的网络会偶然被限制住,明显困在了代价函数的局部最优值出。结果就是不同的运行会给出相差很大的结果。对比来看,规范化的网络能够提供更容易复制的结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











