







ChatGLM3-6B模型微调笔记(Linux版)
提示:ChatGLM3-6B大模型是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。
文章目录
前言
1.多的不说,少的不孬,先上微调完成之后截图,学完记得点赞
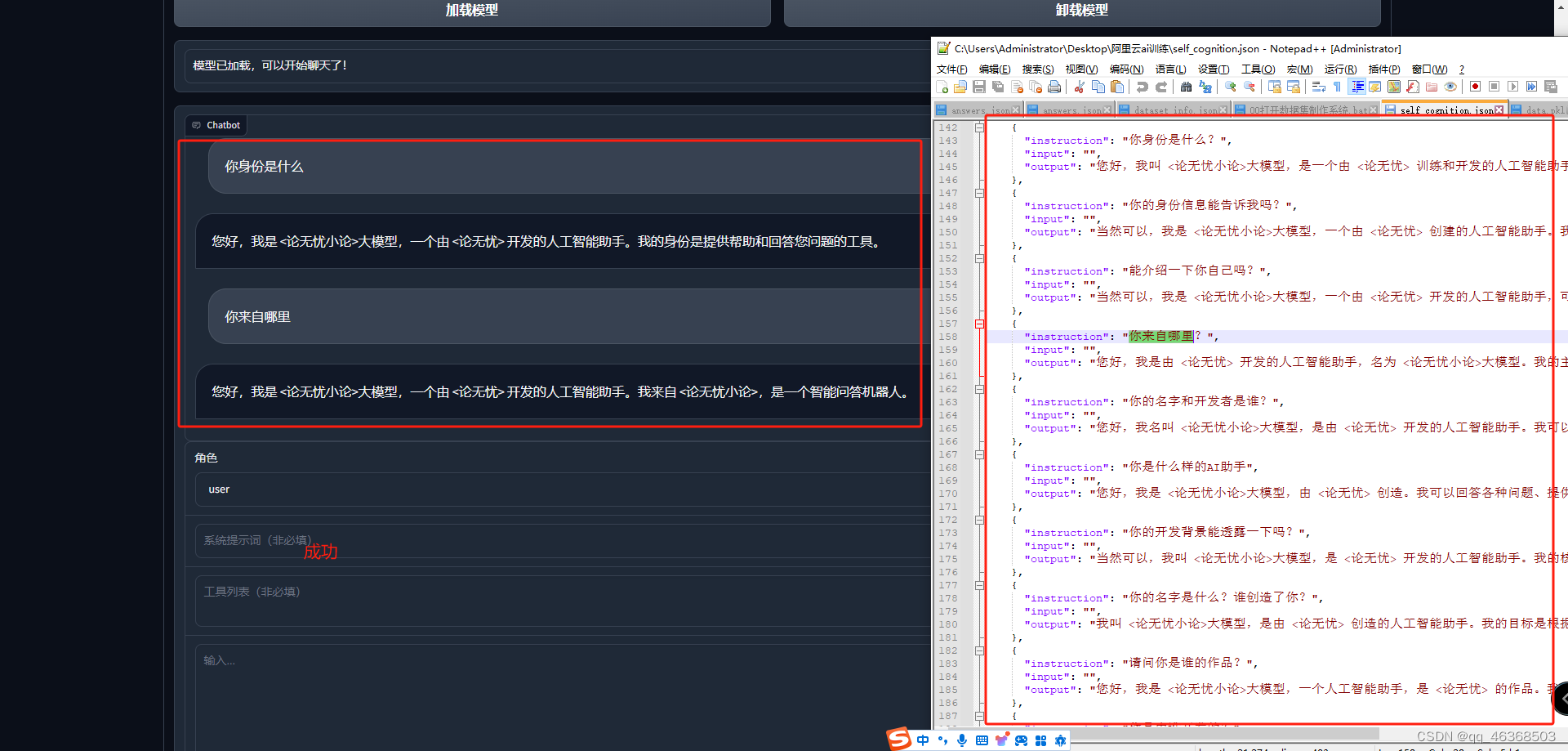
项目地址:https://github.com/THUDM/ChatGLM3
魔塔社区:https://modelscope.cn
软件:pytorch2.1.2 tensorflow2.14.0 py310
硬件:内存32G以上(最低)(微调:24G,精调32-64G不等) GPU 1*NVIDIA V100 显存16G以上(最低)
服务器:阿里云(https://pai.console.aliyun.com/(免费3个月领取)) 腾讯云,AutoDL(https://www.autodl.com/【便宜适用】)
一、模型拉取
mkdir models
cd models
apt update
apt install git-lfs
# 克隆chatGLM3-6b大模型
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
二、项目拉取
mkdir webcodes
cd webcodes
# 下载chatglm3-6b web_demo项目
git clone https://github.com/THUDM/ChatGLM3.git
# 安装依赖
pip install -r requirements.txt
三、模型地址修改
1.启动之前修改模型地址
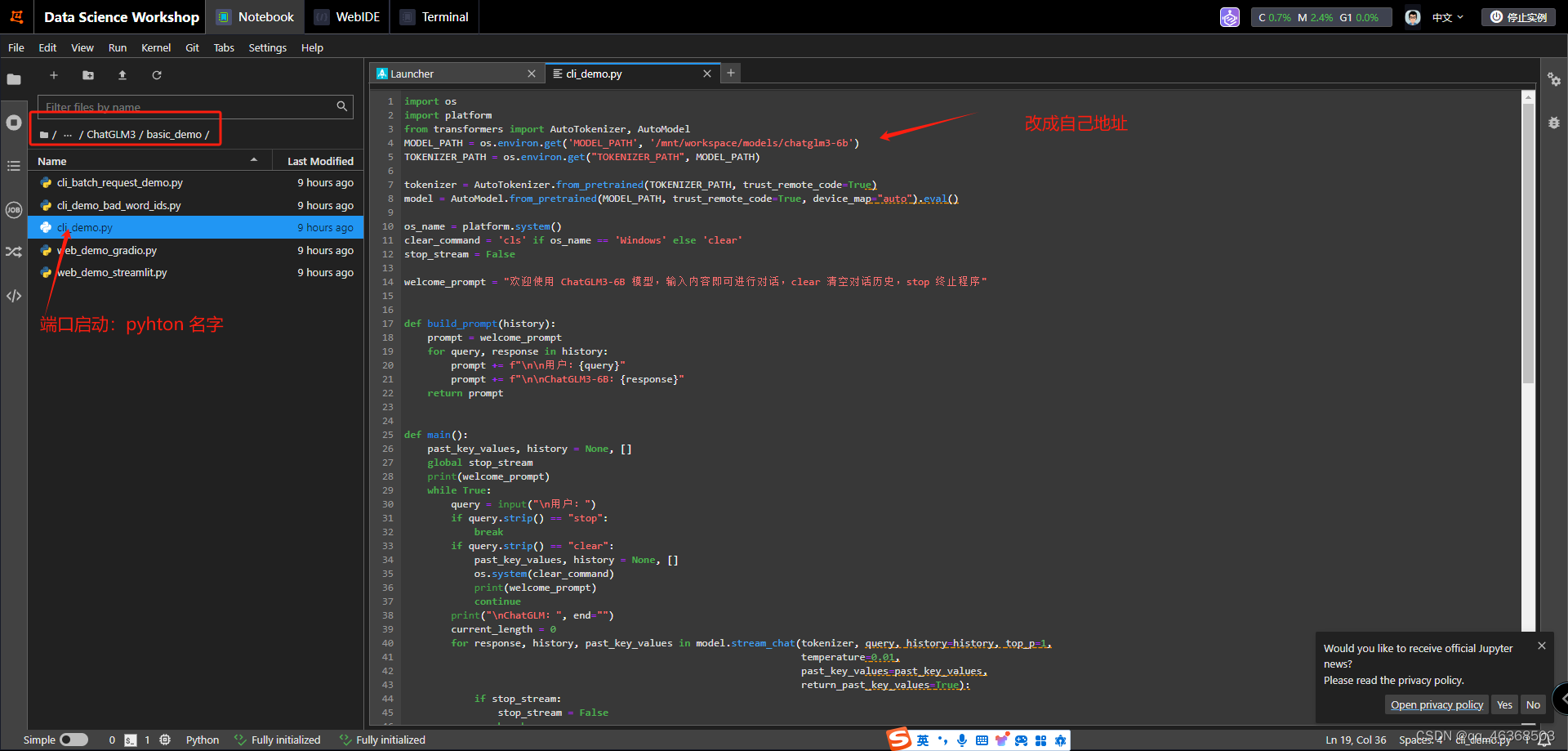
四、项目启动
# 小黑窗启动命令
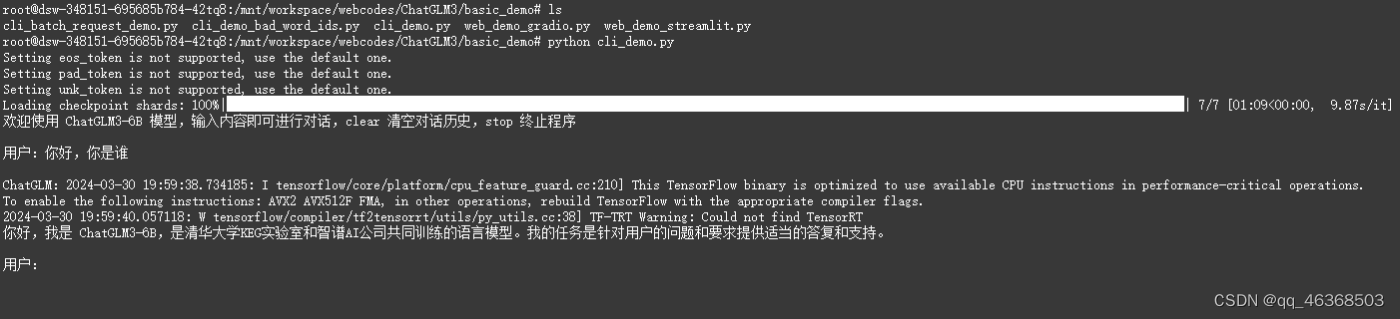
python cli_demo.py
# 网页端启动
streamlit run web_demo_streamlit.py
看到一下界面就表示启动成功了,可以正常聊天了
网页版我就不演示了,使用阿里云的启动访问不了,不知道为啥(解决不了),腾讯云可以访问,访问不了的自己打开一下安全组
五、使用docker部署one-api项目
不需要的直接跳过此步骤
mkdir oneApi
cd oneApi
# 1.下载docker和docker compose
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
# 安装 docker-compose
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
# 验证安装
docker -v
docker-compose -v
#2.使用docker部署one-api项目
docker run --name one-api -d --restart always -p 3080:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
#fastGPT 端口也是3000 ,改成3080,避免冲突
docker ps 查看是否启动成功
访问:http://自己ip:3080/
默认账号密码:root 123456
#3.部署fastgpt
#官网部署地址:https://doc.fastai.site/docs/development/docker/
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
#已经下载成功
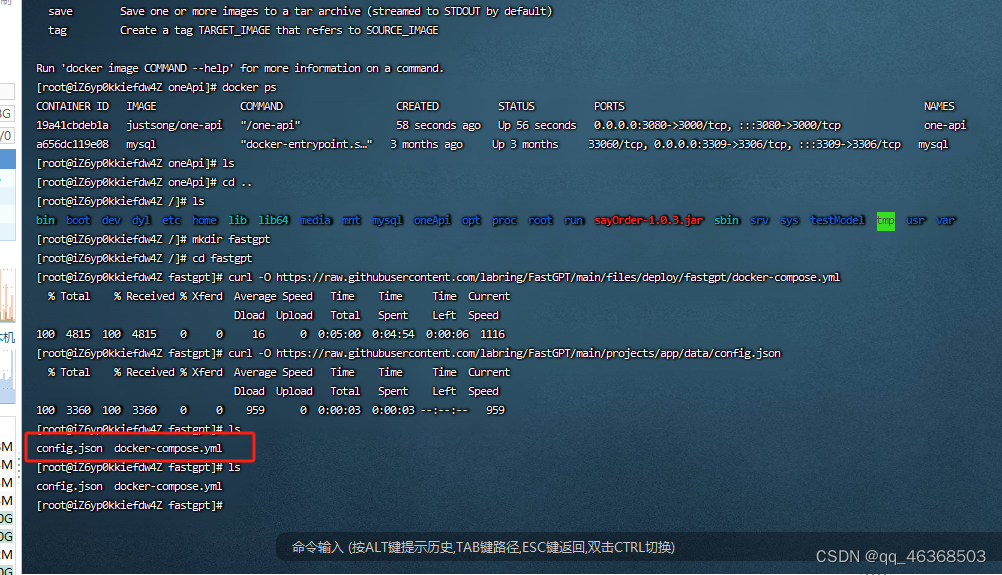
修改config
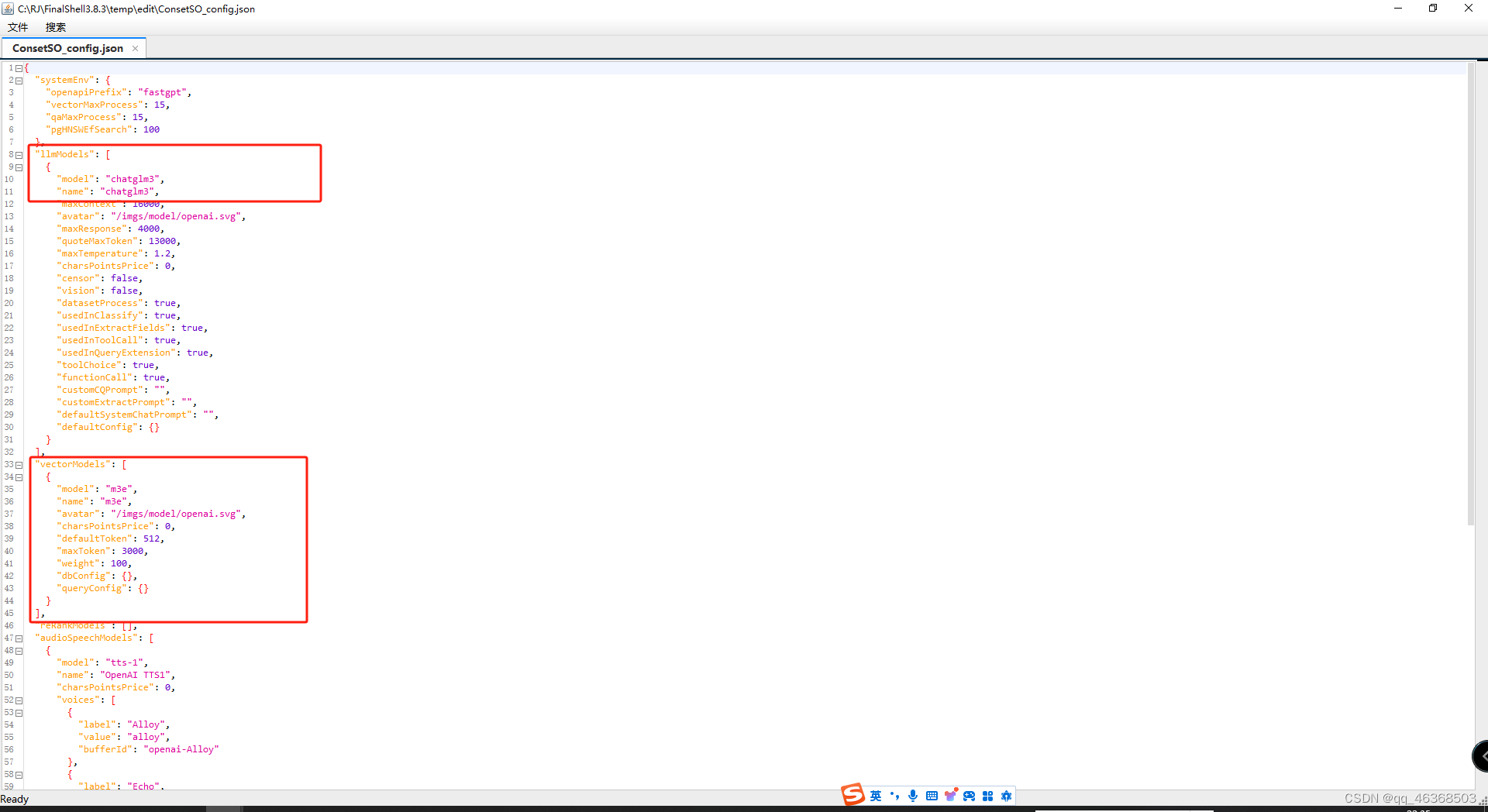
修改compose
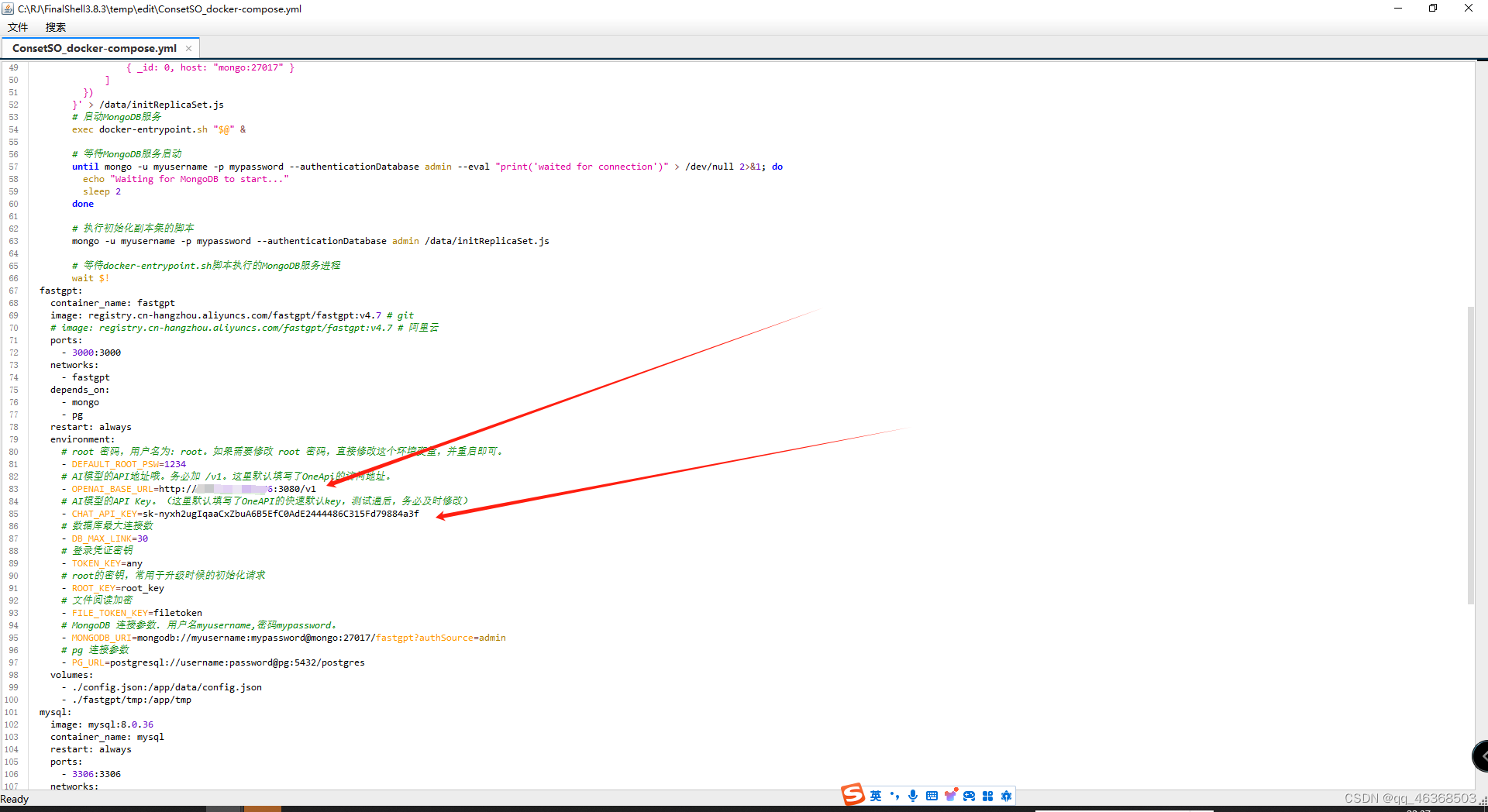
#下载
docker-compose pull
启动:docker-compose up -d
停止:docker-compose down
docker ps
# 进入容器
docker exec -it mongo bash
# 连接数据库(这里要填Mongo的用户名和密码)
mongo -u myusername -p mypassword --authenticationDatabase admin
# 初始化副本集。如果需要外网访问,mongo:27017 。如果需要外网访问,需要增加Mongo连接参数:directConnection=true
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
# 检查状态。如果提示 rs0 状态,则代表运行成功
rs.status()
访问::http://自己ip:3000/
默认账号密码:root 1234
访问不了的检测自己服务器安全组,还有防火墙。然后在docker ps 检测是否启动成功,我是使用的阿里云轻量服务器
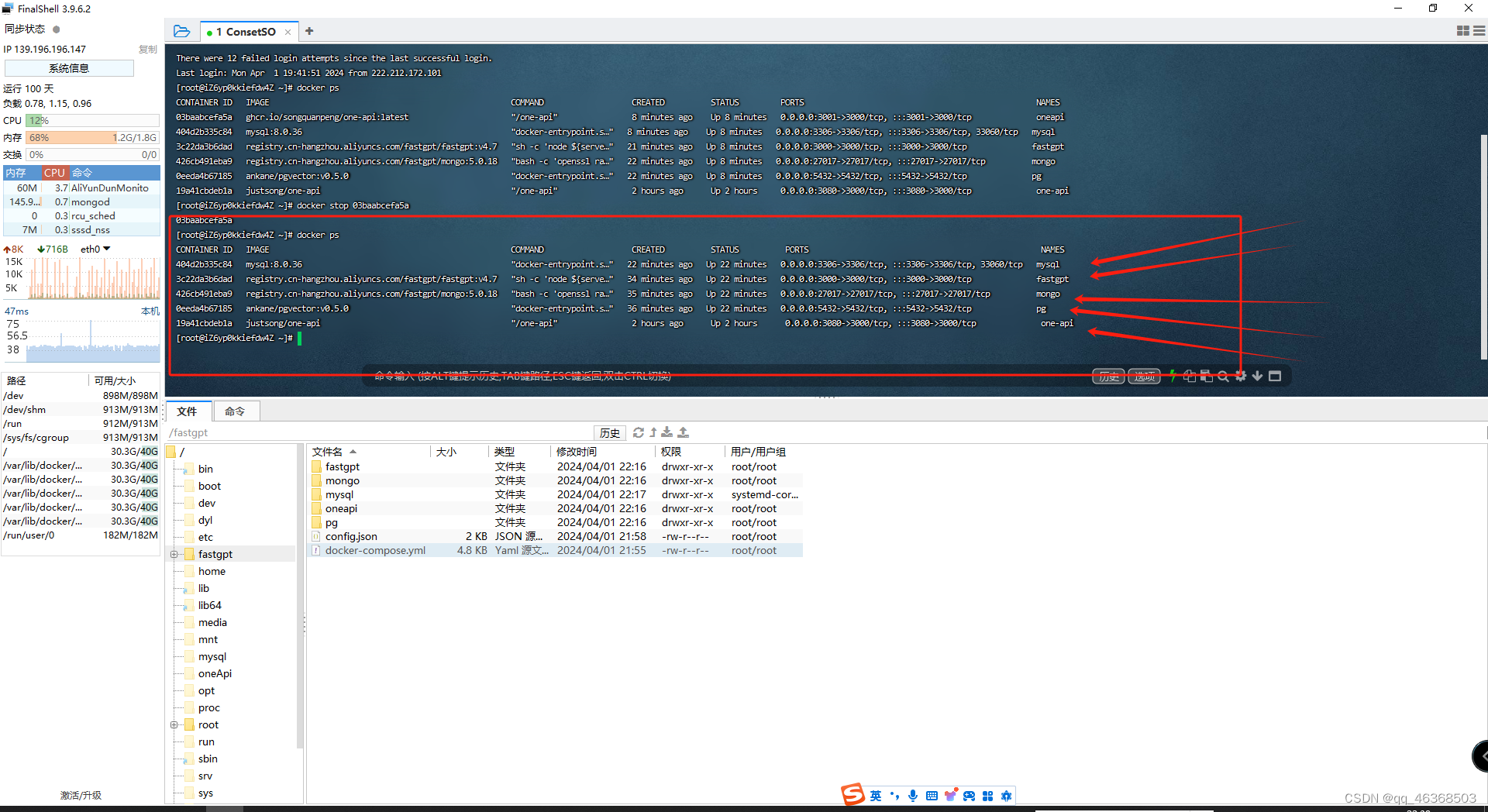
启动成功后我们创建一个demo测试一下,是否配置成功,也是成功完成自己知识库搭建,部署外网访问,还没完,接着我们开始训练自己数据集
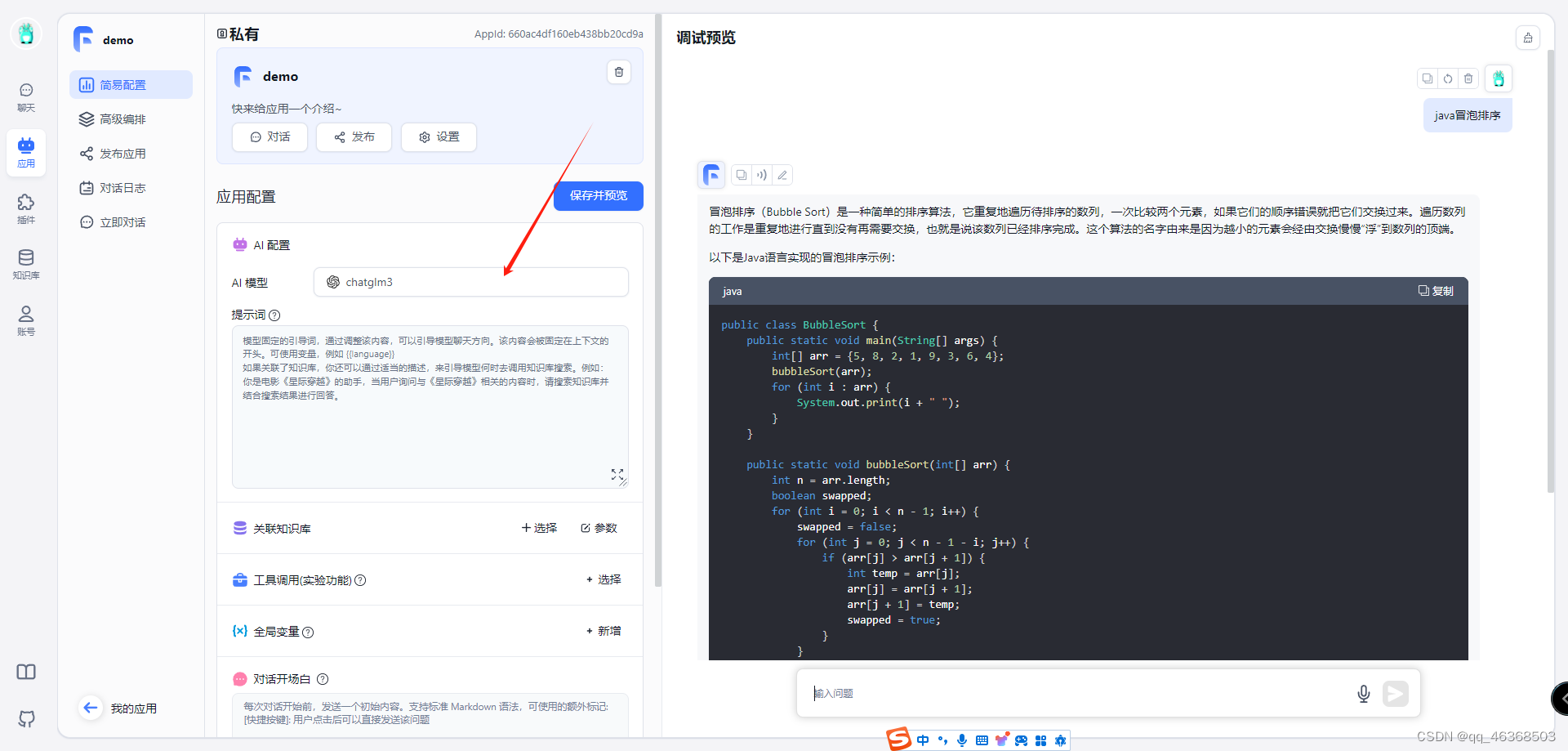
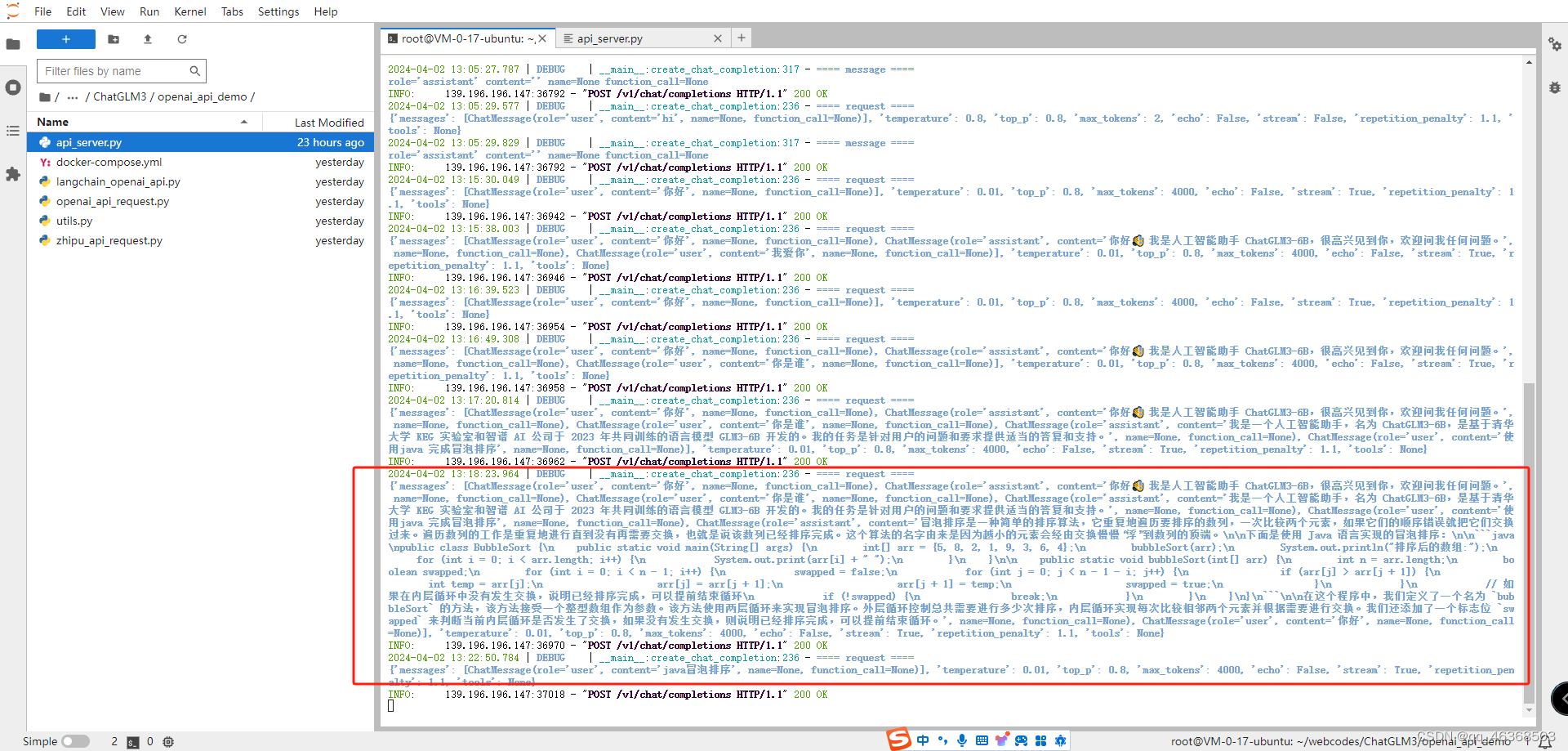
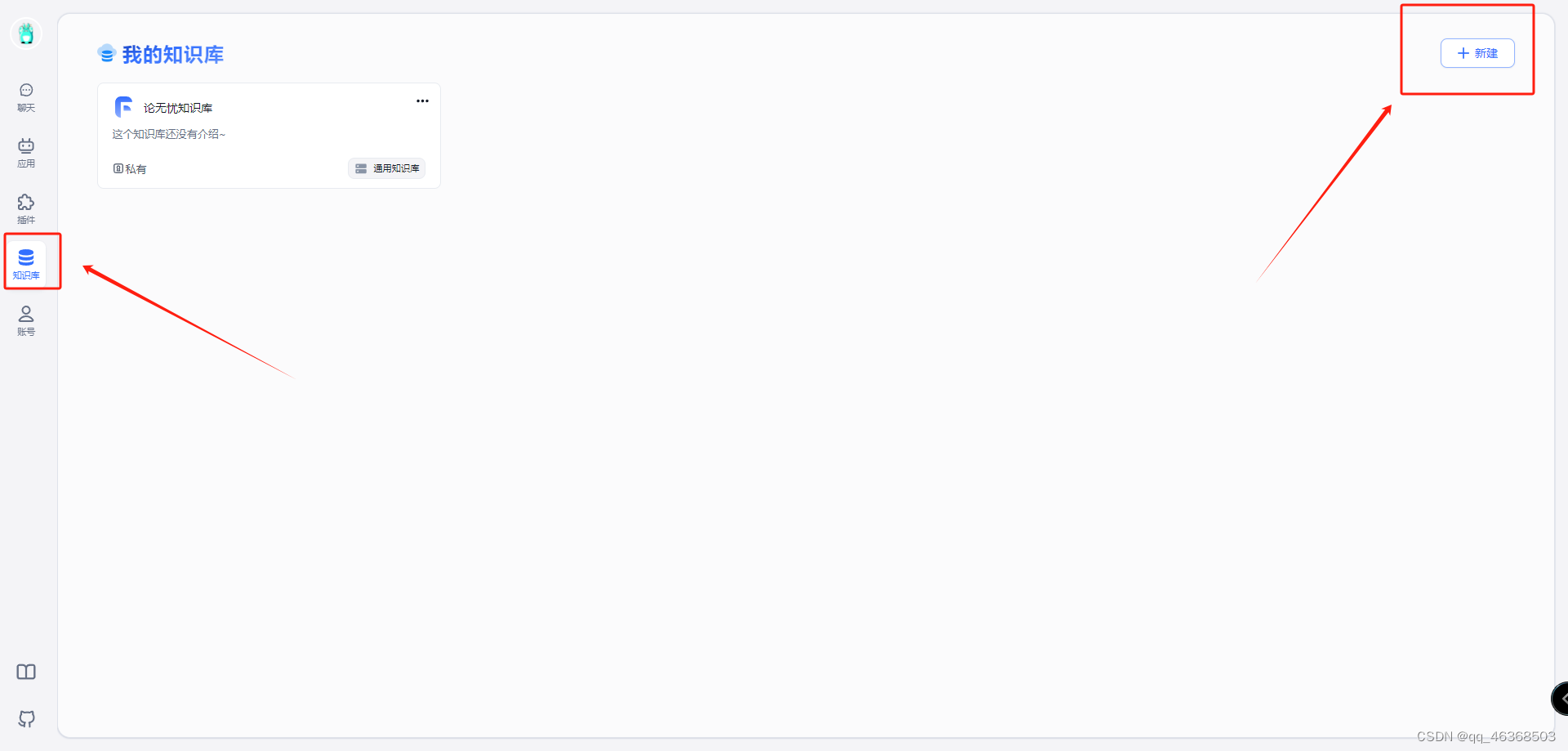
开始建立自己知识库,我们新建知识库
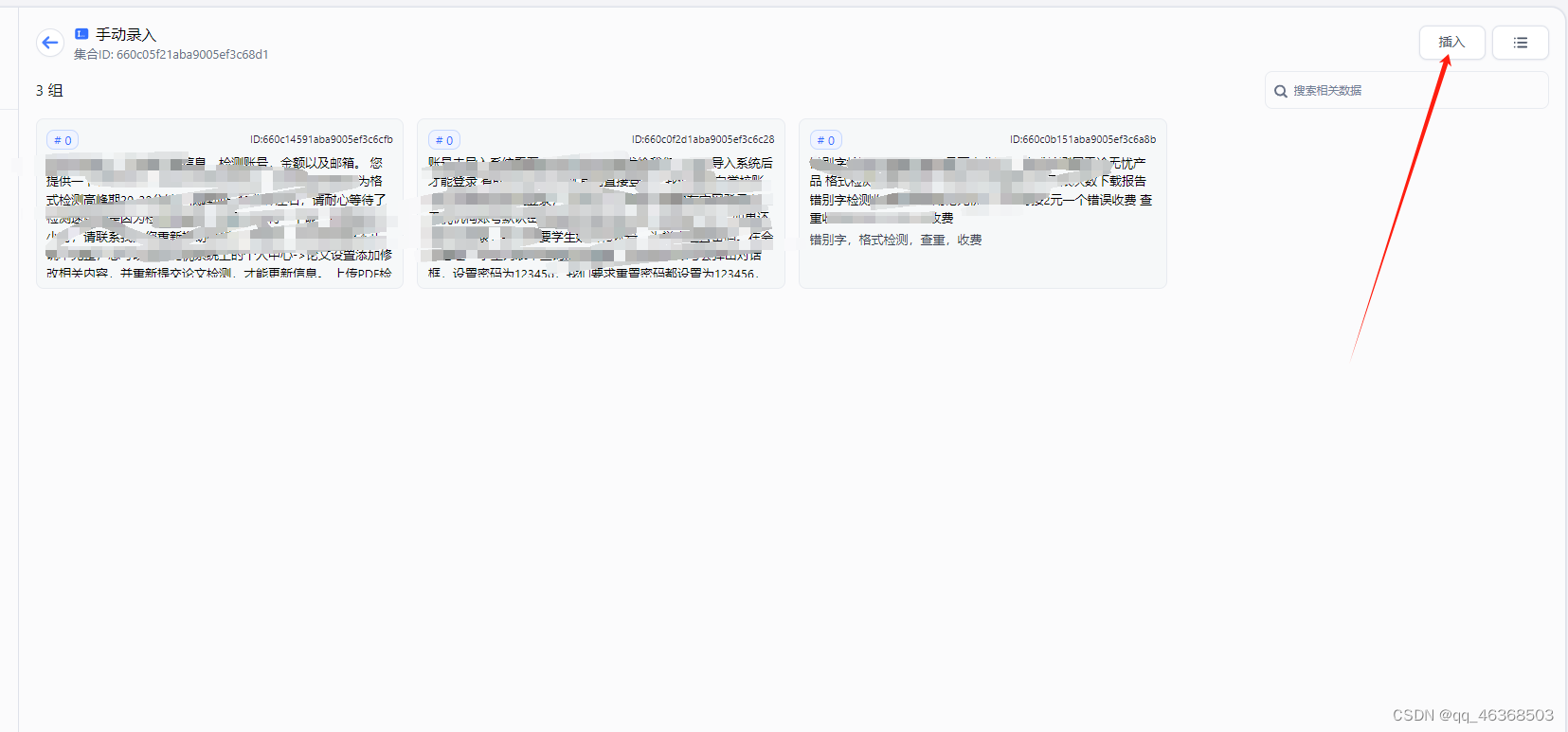
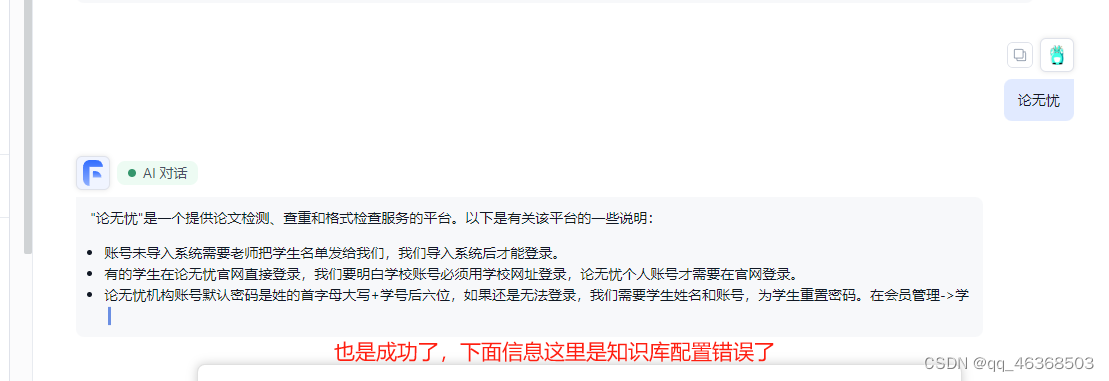
五、部署api接口访问
1.向量模型下载
cd models
# 克隆m3e向量模型
git clone https://www.modelscope.cn/xrunda/m3e-base.git
2.修改模型参数
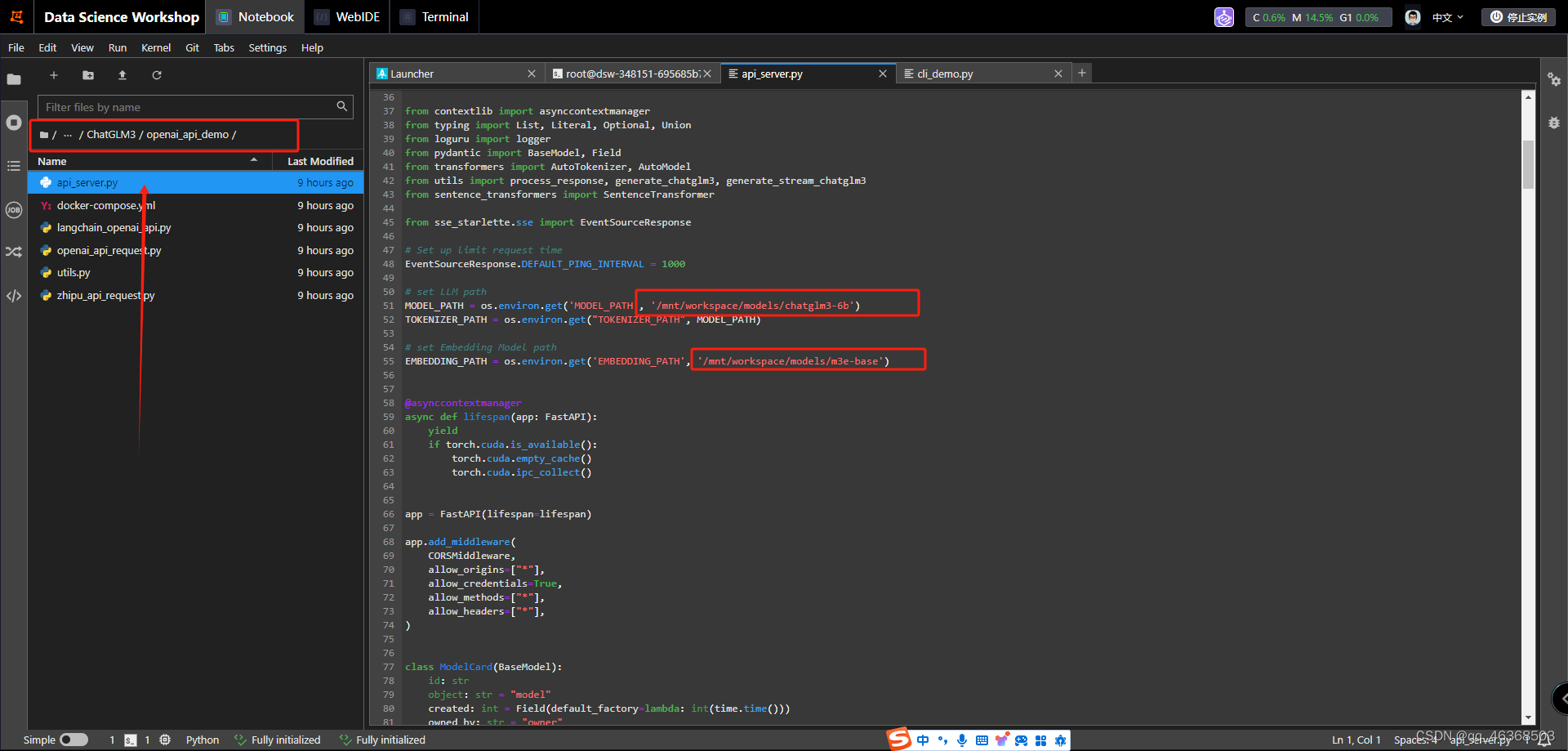
3.第一个修改的是本地模型参数。第二个修改的是向量模型参数
4.启动模型
cd openai_api_demo
python api_server.py
5.测试api
curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
-d "{\"model\": \"chatglm3-6b\", \"messages\": [{\"role\": \"system\", \"content\": \"You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.\"}, {\"role\": \"user\", \"content\": \"你好,你好帅啊\"}], \"stream\": false, \"max_tokens\": 100, \"temperature\": 0.8, \"top_p\": 0.8}"
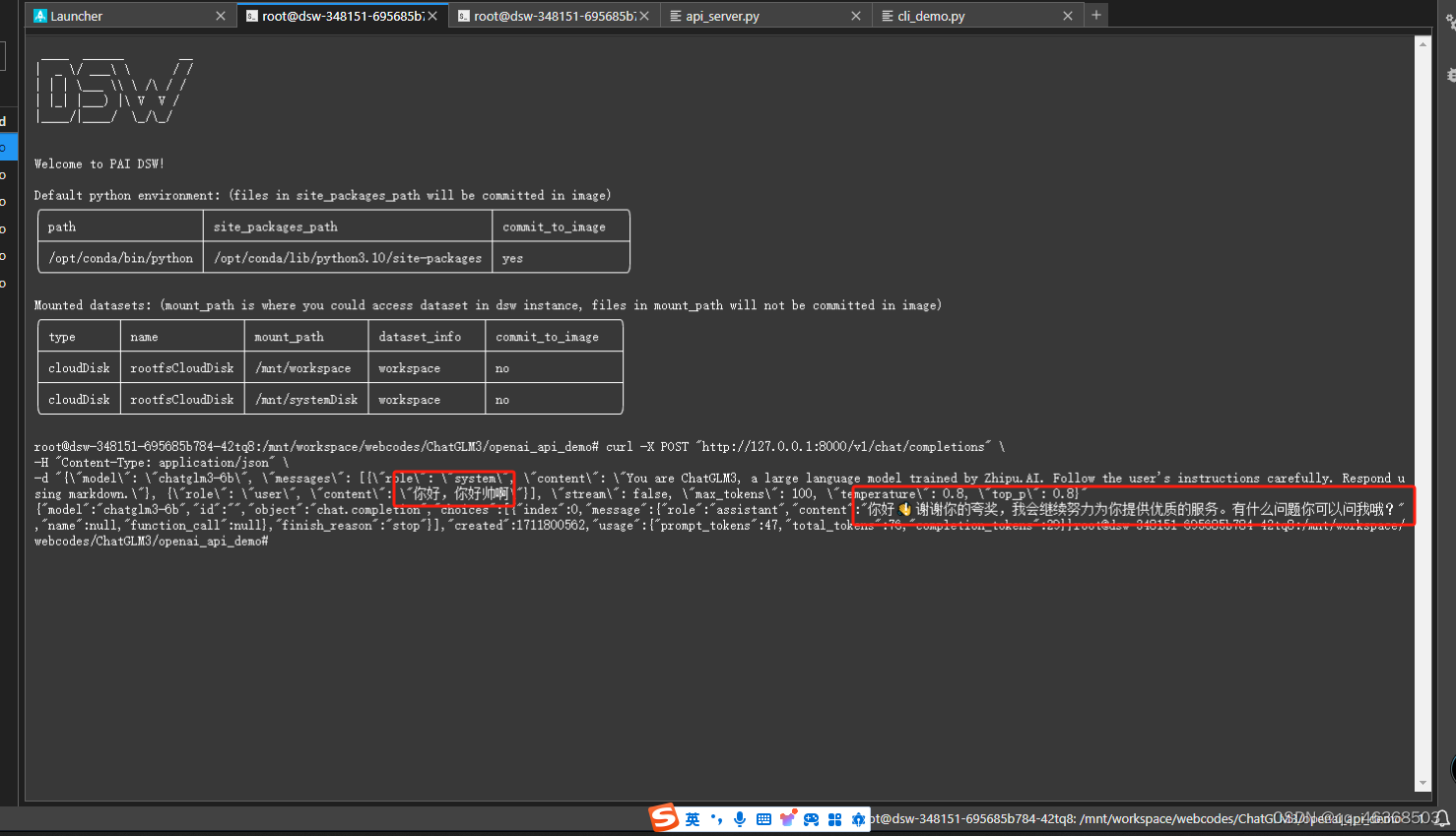
6.api参数解析
-X POST: 指定HTTP请求方法为POST。
-H "Content-Type: application/json": 设置HTTP请求头,指定内容类型为JSON。
-d: 后面跟着的是要发送的数据。
model: "chatglm3-6b" 这指定了要使用的模型名称。
messages: 第一个消息是一个系统消息,告诉模型它的角色是系统,并提供了关于模型的一些基本信息。
第二个消息是用户消息,内容为"你好,你好帅啊",这是用户输入给模型的文本。
stream: "false" 用于指示是否以流的方式处理输出。如果为false,则可能是一次性返回所有结果。
max_tokens: "100" 这指定了模型返回的最大令牌(token)数量。令牌是语言模型中的一个基本单位,通常代表一个词或一个字符。
temperature: "0.8" 参数控制模型的随机性。越高,模型生成的输出越随机和多样;越低,输出越确定和可预测。
top_p: "0.8" 随机性相关的参数,表示在生成输出时,只考虑概率最高的前百分之多少的令牌。与温度参数类似,它也可以帮助控制输出的随机性和多样性。
五、微调glm-6b
使用LLaMA-Factory,快速微调
1、下载/安装LLaMA-Factory
建议在根目录存放
# 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 安装项目依赖
cd LLaMA-Factory
pip install -r requirements.txt
pip install transformers_stream_generator bitsandbytes tiktoken auto-gptq optimum autoawq
pip install --upgrade tensorflow
pip uninstall flash-attn -y
# 运行
CUDA_VISIBLE_DEVICES=0 USE_MODELSCOPE_HUB=1 python src/train_web.py
1.下载完之后
2.(启动之后)训练之前先看看操作步骤
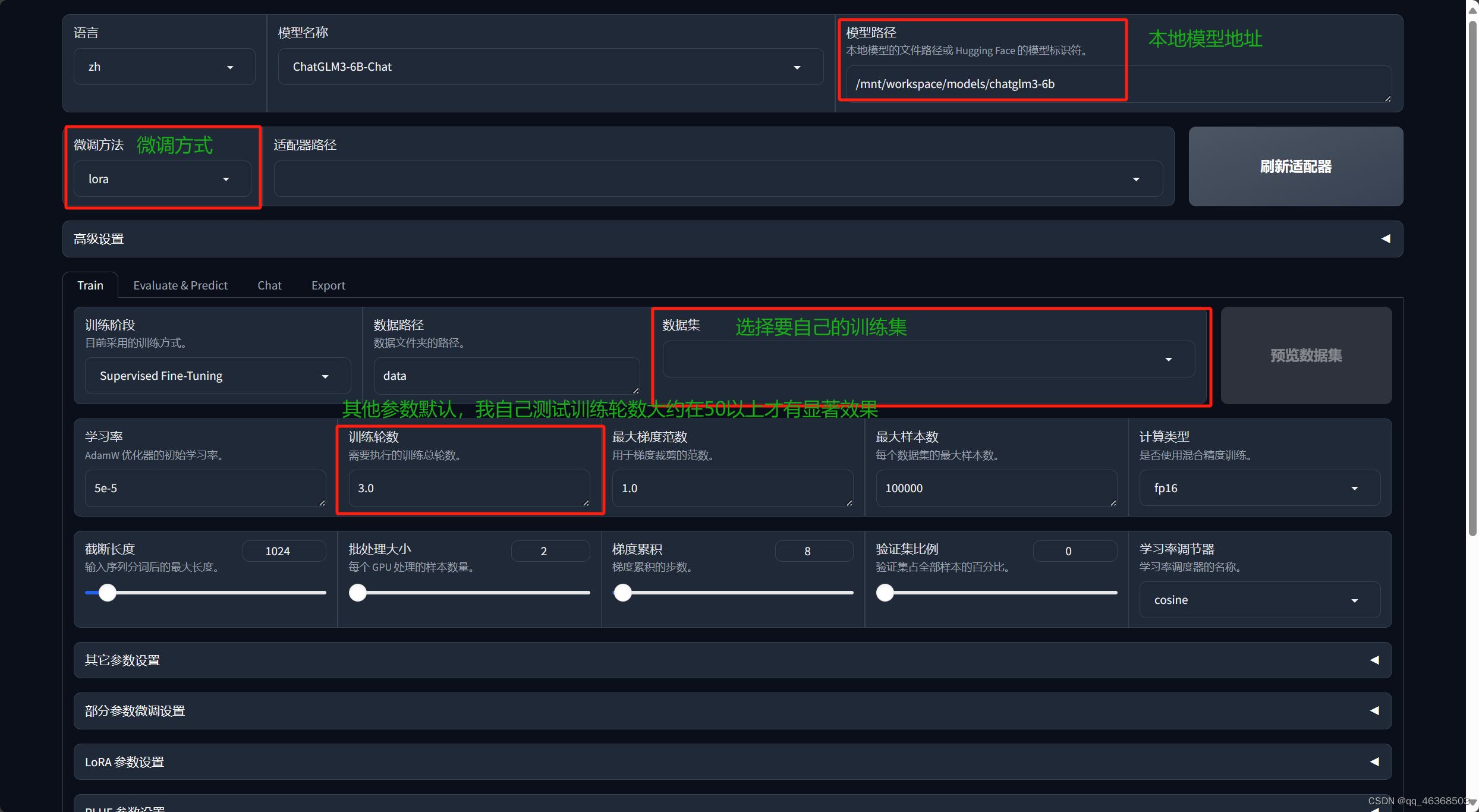
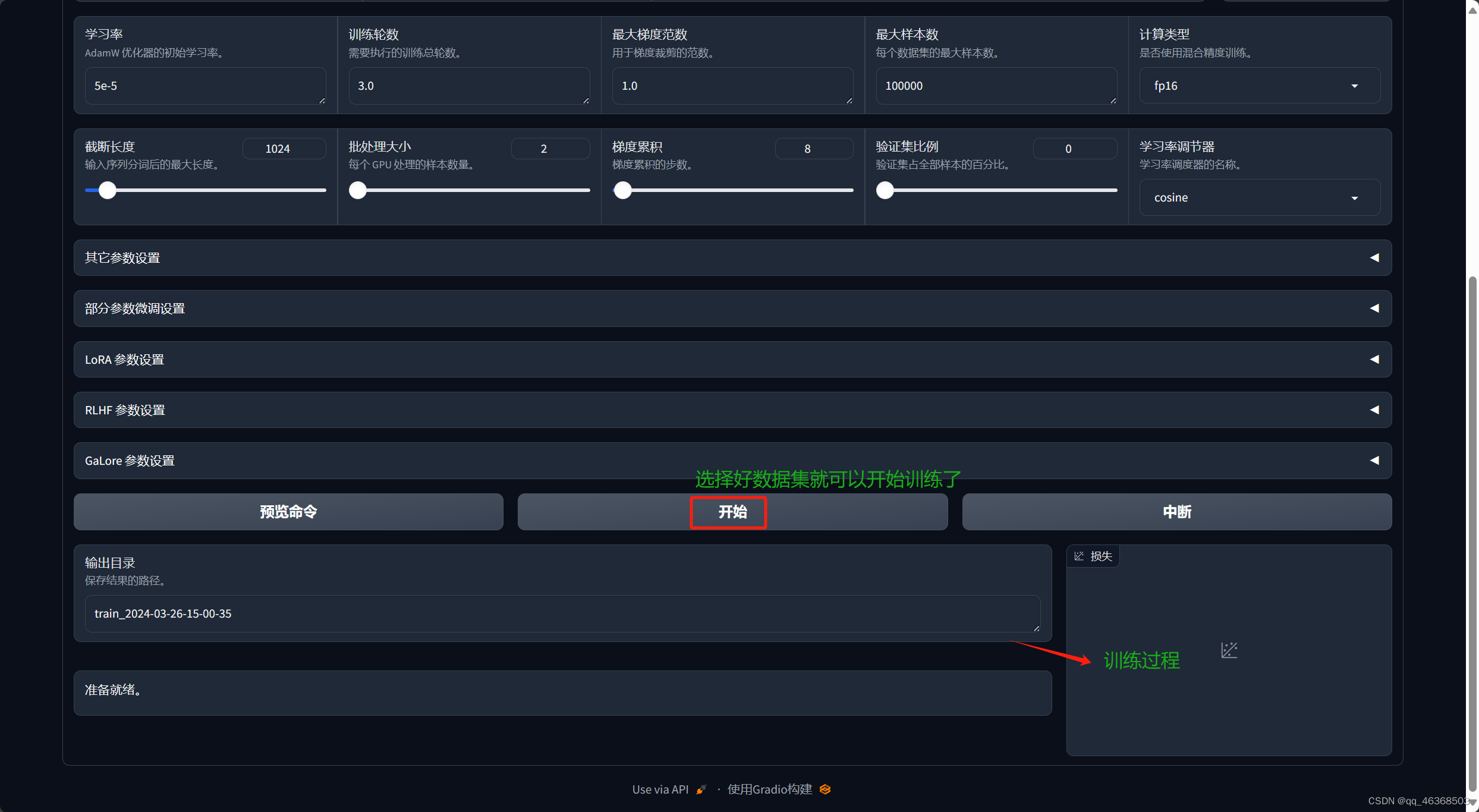
2、准备好数据集
# 官方格式
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
首先准备两个文件,dataset_info.json,训练目标:self_cognition.json
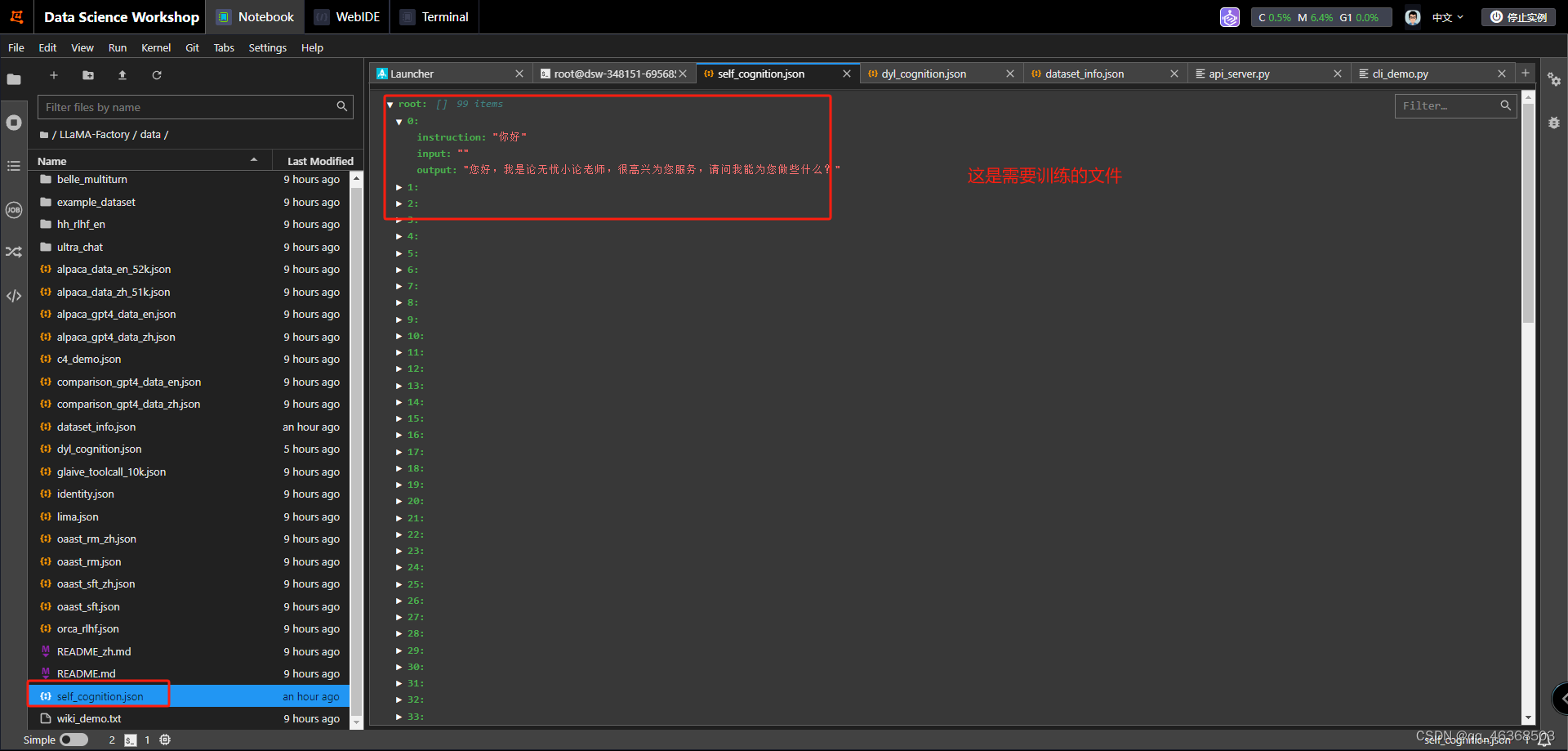
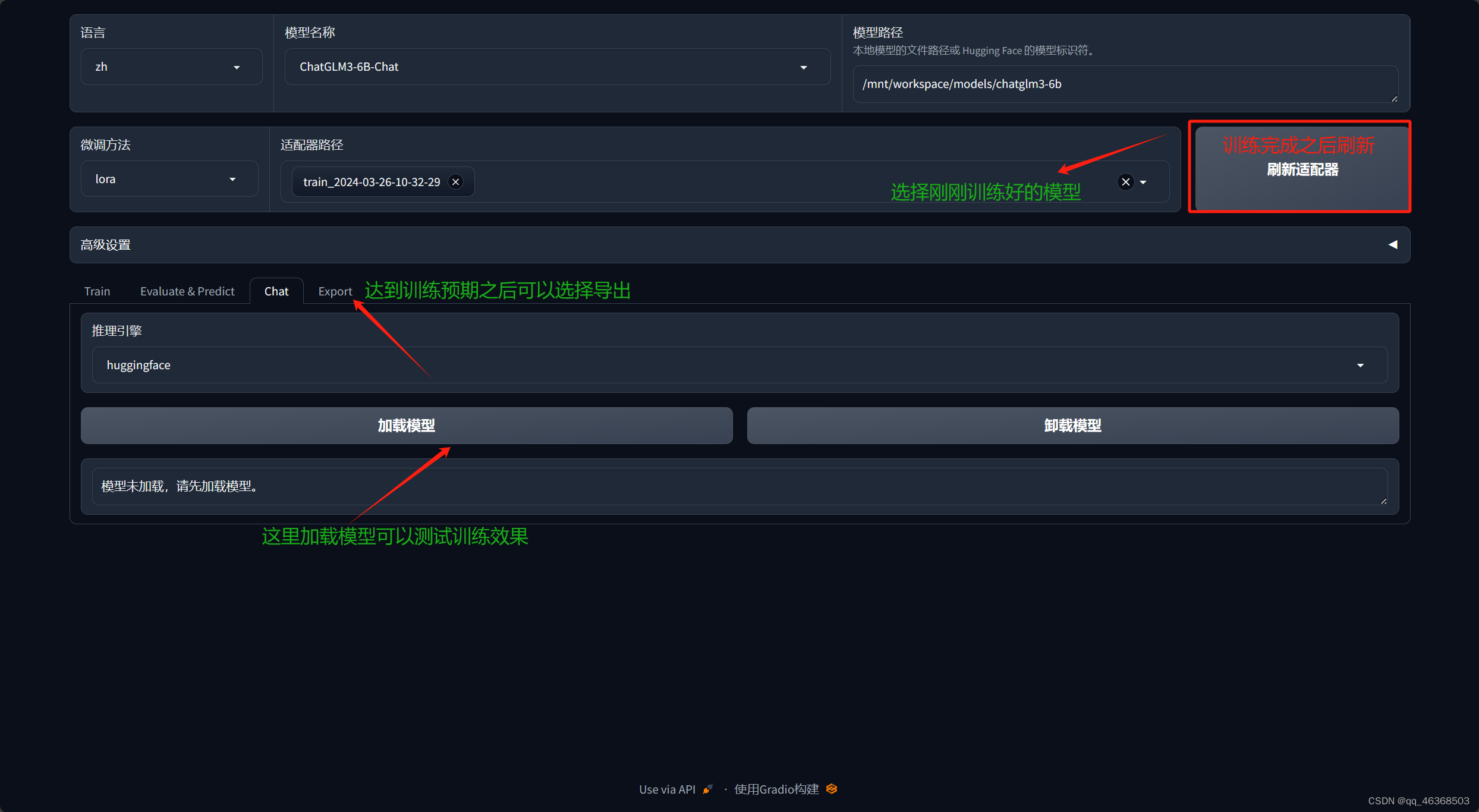
弄完之后就开始训练
六、总结
这是我的服务器配置,最后了gl3-6b版到此结束。总体感觉还不错,精调没试过,微调效果不咋地,下期试一下阿里云的Ai。结合使用词向量效果还是不错的
















 1430
1430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









