







 本文详细介绍了逻辑斯蒂回归的理论基础,包括基于Logistic回归和Sigmoid函数的分类原理,以及模型训练中的代价函数。通过sklearn库展示了如何实现逻辑斯蒂回归,并提供了从零开始的Python代码示例,解释了算法的训练过程和模型评估。此外,还讨论了随机梯度上升算法在优化过程中的应用。
本文详细介绍了逻辑斯蒂回归的理论基础,包括基于Logistic回归和Sigmoid函数的分类原理,以及模型训练中的代价函数。通过sklearn库展示了如何实现逻辑斯蒂回归,并提供了从零开始的Python代码示例,解释了算法的训练过程和模型评估。此外,还讨论了随机梯度上升算法在优化过程中的应用。
逻辑斯蒂回归(二分类算法)理论+Python代码实现
文章目录
一、理论基础
逻辑回归 Logistic Regression又名 Logit Regression.通常用来估计样本属于某一类的概率。
p
^
=
h
θ
(
x
)
=
σ
(
θ
T
x
)
\hat p = h_\theta(x) = \sigma(\theta^Tx)
p^=hθ(x)=σ(θTx)
-
Logistic回归的一般过程
(1) 收集数据:采用任意方法收集数据。
(2) 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
(3) 分析数据:采用任意方法对数据进行分析。
(4) 训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5) 测试算法:一旦训练步骤完成,分类将会很快。
(6) 使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;
接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
(一) 基于 Logistic 回归和 Sigmoid 函数的分类
-
Logistic回归:
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。 -
Logistic回归分类器:【概率估计】
我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。其分布函数 σ ( t ) \sigma(t) σ(t)为:
σ ( t ) = 1 1 + e − t \sigma(t)=\frac 1{1+e^{-t}} σ(t)=1+e−t1
密度函数
f
(
t
)
f(t)
f(t)为:
f
(
t
)
=
σ
′
(
t
)
=
e
−
t
(
1
+
e
−
t
)
2
f(t)=\sigma'(t)=\frac{e^{-t}}{(1+e^{-t})^2}
f(t)=σ′(t)=(1+e−t)2e−t
- 分析:联系线性回归模型产生的预测值 z = w T x + b z=w^Tx+b z=wTx+b是实数,而二分类任务输出标记 y ∈ { 0 , 1 } y\in \{0,1\} y∈{0,1},于是我们考虑使用“单位跃阶函数”实现转换;
y
=
{
0
,
z
<
0
0.5
,
z
=
0
1
,
z
>
0
y= \begin{cases} 0,&z<0\\ 0.5,&z=0\\ 1,&z>0 \end{cases}
y=⎩
⎨
⎧0,0.5,1,z<0z=0z>0
但“单位跃阶函数”不连续,故我们考虑使用对数几率函数(Sigmoid函数)实现连续化。

(二) 模型训练与代价函数
对于给定的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}, 其中 x i ∈ R n , y i ∈ { 0 , 1 } x_i\in {\bf R}^n, \, \, y_i\in \{0, 1\} xi∈Rn,yi∈{0,1}。可以应用极大似然估计法估计模型参数,从而得到逻辑斯蒂回归模型。
- 定义(逻辑斯蒂回归模型) 二项逻辑斯蒂回归模型是如下条件概率分布:
P ( Y = 1 ∣ x ) = exp ( w ⋅ x + b ) 1 + exp ( w ⋅ x + b ) P(Y=1 \,|\,x) = \frac{\exp(w\cdot x+b)}{1+\exp(w\cdot x+b)} P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)
P ( Y = 0 ∣ x ) = 1 1 + exp ( w ⋅ x + b ) P(Y=0 \,|\,x) = \frac{1}{1+\exp(w\cdot x+b)} P(Y=0∣x)=1+exp(w⋅x+b)1
其中, x ∈ R n x\in {\bf R}^n x∈Rn 是输入, Y ∈ { 0 , 1 } Y\in \{0, 1\} Y∈{0,1}是输出, w ∈ R n w\in {\bf R}^n w∈Rn 和 b ∈ R b\in {\bf R} b∈R 是参数, w w w 成为权值向量, b b b 称为偏置, w ⋅ x w\cdot x w⋅x为 w w w 与 x x x 的内积。
- 代价函数与参数最优解:对数曲率函数是任意阶可导的凸函数,具有很好的数学性质,为求取最优解,我们将权值向量和输入向量加以扩充,仍记 w , x w, x w,x, 即 w = ( w ( 1 ) , w ( 2 ) , ⋯ , w ( n ) , b ) T w=(w^{(1)}, w^{(2)},\cdots, w^{(n)},b)^T w=(w(1),w(2),⋯,w(n),b)T, x = ( x ( 1 ) , x ( 2 ) , ⋯ , x ( n ) , 1 ) T {\bf x}=(x^{(1)}, x^{(2)},\cdots, x^{(n)}, 1)^T x=(x(1),x(2),⋯,x(n),1)T。这时,逻辑斯蒂回归模型如下:
P ( Y = 1 ∣ x ) = exp ( w ⋅ x ) 1 + exp ( w ⋅ x ) P(Y=1 \,|\,x) = \frac{\exp(w\cdot x)}{1+\exp(w\cdot x)} P(Y=1∣x)=1+exp(w⋅x)exp(w⋅x)
P ( Y = 0 ∣ x ) = 1 1 + exp ( w ⋅ x ) P(Y=0 \,|\,x) = \frac{1}{1+\exp(w\cdot x)} P(Y=0∣x)=1+exp(w⋅x)1
利用
P
(
Y
=
0
∣
x
)
=
1
−
P
(
Y
=
1
∣
x
)
P(Y=0 |x) = 1-P(Y=1 |x)
P(Y=0∣x)=1−P(Y=1∣x),可得
log
P
(
Y
=
1
∣
x
)
1
−
P
(
Y
=
1
∣
x
)
=
w
⋅
x
\log\frac{P(Y=1 |x)}{1-P(Y=1 |x)} = w\cdot x
log1−P(Y=1∣x)P(Y=1∣x)=w⋅x
Sigmoid函数的输入为z,由下面公式得出:
z
=
w
0
x
0
+
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
z=w_0x_0 + w_1x_1 +w_2x_2 + ...+w_n x_n
z=w0x0+w1x1+w2x2+...+wnxn
x是分类器的输入数据,w是我们需要找的最佳参数。
- 从直观上来讲:单训练样本下的代价函数
c
(
θ
)
=
{
−
log
(
p
^
)
,
i
f
,
y
=
1
,
−
log
(
1
−
p
^
)
,
i
f
,
y
=
0
,
\begin{equation} c(\theta)= \left\{\begin{array}{lcl} -\log(\hat p), \quad\qquad\,\,\, if, \,\,y=1, \\ -\log(1-\hat p), \qquad if, \,\,y=0, \end{array}\right.\end{equation}
c(θ)={−log(p^),if,y=1,−log(1−p^),if,y=0,
而cost function就是多个单样本的误差求和后平均。Logistic回归的代价函数 (log loss)
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
log
(
p
^
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
p
^
(
i
)
)
]
J(\theta) = -\frac 1m\sum_{i=1}^m\left[y^{(i)}\log\left(\hat p^{(i)}\right )+ \left(1-y^{(i)}\right)\log\left(1-\hat p^{(i)}\right )\right]
J(θ)=−m1i=1∑m[y(i)log(p^(i))+(1−y(i))log(1−p^(i))]
-
从概率和最大似然的角度来讲: y y y 的取值(0或1)可以用下式来建模:
Logistic Regression 中类别 y y y 的概率估计
P r ( y ∣ x ; θ ) = h θ ( x ) y ( 1 − h θ ( x ) ) 1 − y Pr(y|x;\theta) = h_\theta(x)^y(1-h_\theta(x))^{1-y} Pr(y∣x;θ)=hθ(x)y(1−hθ(x))1−y
假设所有的观测本件都是独立的,有(似然估计函数)Likelihood function:
L
(
θ
∣
x
)
=
P
r
(
Y
∣
X
;
θ
)
=
∏
i
P
r
(
y
i
∣
x
i
;
θ
)
=
∏
i
h
θ
(
x
i
)
y
i
(
1
−
h
θ
(
x
i
)
)
(
1
−
y
i
)
L(\theta|x)=Pr(Y|X;\theta)=\prod_i Pr(y_i |x_i; \theta)\\ \qquad =\prod_i h_\theta(x_i)^{y_i}(1-h_\theta(x_i))^{(1-y_i)}
L(θ∣x)=Pr(Y∣X;θ)=i∏Pr(yi∣xi;θ)=i∏hθ(xi)yi(1−hθ(xi))(1−yi)
两边取对数有对数似然估计(log likelihood),再用
1
m
\frac 1m
m1进行归一化:
1
m
log
L
(
θ
∣
x
)
=
1
m
log
P
r
(
Y
∣
X
;
θ
)
\frac 1m \log L(\theta |x) = \frac 1m\log Pr(Y |X; \theta)
m1logL(θ∣x)=m1logPr(Y∣X;θ)
极大似然估计问题可以建模为:
max
1
m
log
L
(
θ
∣
x
)
=
1
m
log
P
r
(
Y
∣
X
;
θ
)
\max\frac 1m\log L(\theta |x) = \frac 1m\log Pr(Y |X; \theta)
maxm1logL(θ∣x)=m1logPr(Y∣X;θ)
即为
min
J
(
θ
)
=
min
{
−
1
m
∑
i
=
1
m
[
y
i
log
(
h
θ
(
x
i
)
)
+
(
1
−
y
i
)
log
(
1
−
h
θ
(
x
i
)
)
]
}
=
min
{
−
1
m
∑
i
=
1
m
[
y
i
log
P
(
y
i
=
1
∣
x
i
)
+
(
1
−
y
i
)
log
(
1
−
P
(
y
i
=
1
∣
x
i
)
)
]
}
=
min
{
−
1
m
∑
i
=
1
m
[
y
i
log
P
(
y
i
=
1
∣
x
i
)
1
−
P
(
y
i
=
1
∣
x
i
)
+
log
(
1
−
P
(
y
i
=
1
∣
x
i
)
)
]
}
=
min
{
−
1
m
∑
i
=
1
m
[
y
i
(
θ
⋅
x
i
)
−
log
(
1
+
exp
(
θ
⋅
x
i
)
]
}
\begin{align} \min J(\theta) & = \min\left\{ -\frac 1m\sum_{i=1}^m\left[y_i\log(h_\theta(x_i))+(1-y_i)\log(1-h_\theta(x_i))\right]\right\}\\ & = \min\left\{ -\frac 1m\sum_{i=1}^m\left[y_i\log P(y_i=1 |x_i)+(1-y_i)\log(1-P(y_i=1 |x_i))\right]\right\}\\ & = \min\left\{ -\frac 1m\sum_{i=1}^m\left[y_i \log\frac{ P(y_i=1 |x_i)}{1-P(y_i=1 |x_i)}+\log(1-P(y_i=1 |x_i))\right]\right\}\\ & = \min\left\{ -\frac 1m\sum_{i=1}^m\left[y_i(\theta\cdot {\bf x}_i)-\log(1+\exp(\theta\cdot{\bf x}_i)\right]\right\} \end{align}
minJ(θ)=min{−m1i=1∑m[yilog(hθ(xi))+(1−yi)log(1−hθ(xi))]}=min{−m1i=1∑m[yilogP(yi=1∣xi)+(1−yi)log(1−P(yi=1∣xi))]}=min{−m1i=1∑m[yilog1−P(yi=1∣xi)P(yi=1∣xi)+log(1−P(yi=1∣xi))]}=min{−m1i=1∑m[yi(θ⋅xi)−log(1+exp(θ⋅xi)]}
线性回归问题一般有两种解决方式:1)利用闭式解求解 2)利用迭代算法求解。不幸的是,Logistic回归问题目前没有闭式解,但由于代价函数是凸的,所以能够利用GD或者其他优化算法求解全局最优值:首先利用Logistic代价函数对
j
j
j 个参数依次求偏导数 ,得到各参数的偏导数后进一步求得其梯度向量,进而可由批量梯度下降求解最优解。
∂
∂
θ
j
J
(
θ
)
=
1
m
∑
i
=
1
m
(
σ
(
θ
T
x
i
)
−
y
i
)
x
i
(
j
)
\frac{\partial}{\partial\theta_j} J(\theta) = \frac 1m\sum_{i=1}^m\left(\sigma\left(\theta^T {\bf x_i}\right)-y_i\right) x_i^{(j)}
∂θj∂J(θ)=m1i=1∑m(σ(θTxi)−yi)xi(j)
对随机梯度下降(Stochastic GD)来说,每次只能利用一个样本进行计算;同样,对小批量梯度下降(mini-batch GD)来说,每次需要用一个 mini-batch 进行计算。
二、算法实现(skic-learn调库)
from sklearn.linear_model import LogisticRegression
#调用机器学习库中的逻辑回归模型 若无skic-learn,命令行输入pip install sklearn 安装
from sklearn import datasets
import pandas as pd
#数据准备-鸢尾花数据集 可直接联网下载 不用本地导入
iris = datasets.load_iris()
list(iris.keys())
X1=iris["data"][:,2:] #petal width花瓣宽度
y1=(iris["target"]==0).astype(np.int) #1 if Iris_Virginica, else 0是鸢尾花为1,否为0
data2=pd.DataFrame(X1, columns=["A","B"]) #训练数据的X(包含A/B两个特征)
data2["C"]=y1 #训练数据的Y
# 模型建立和预测
log_reg = LogisticRegression() #调用逻辑回归库
log_reg.fit(X1,y1) #训练模型
#print(a)
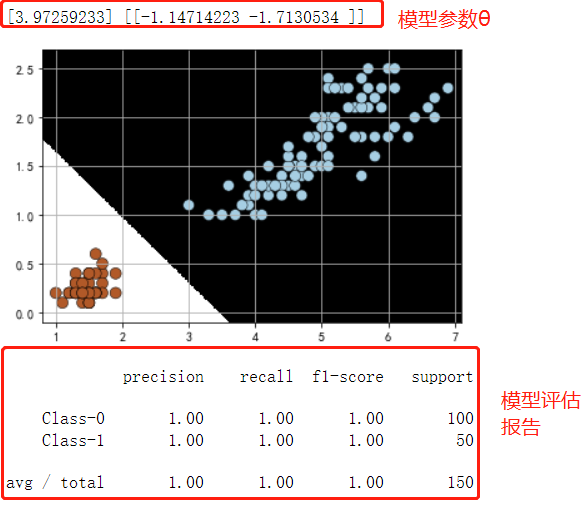
print(log_reg.intercept_,log_reg.coef_) #输出预测参数
#plt.scatter(X1[:,0],X1[:,1])
log_reg.predict([[1.5,1.7]])#单例预测,预测(A=1.5,B=1.7时的C(Y)为?
log_reg.score(X1,y1)#模型训练结果评估,输出准确率
# 将分类器绘制到图中
def plot_classifier(classifier, X, y):
x_min, x_max = min(X[:, 0]) - 0.2, max(X[:, 0]) + 0.2 # 计算图中坐标的范围
y_min, y_max = min(X[:, 1]) - 0.2, max(X[:, 1]) + 0.2
step_size = 0.01 # 设置step size
x_values, y_values = np.meshgrid(np.arange(x_min, x_max, step_size),
np.arange(y_min, y_max, step_size))
# 构建网格数据
mesh_output = classifier.predict(np.c_[x_values.ravel(), y_values.ravel()])
mesh_output = mesh_output.reshape(x_values.shape)
plt.figure()
plt.pcolormesh(x_values, y_values, mesh_output, cmap=plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c=y, s=80, edgecolors='black',
linewidth=0.5, cmap=plt.cm.Paired)
# specify the boundaries of the figure
#plt.xlim(x_values.min(), x_values.max())
#plt.ylim(y_values.min(), y_values.max())
# specify the ticks on the X and Y axes
# plt.xticks((np.arange(int(min(X[:, 0])), int(max(X[:, 0])), 0.5)))
#plt.yticks((np.arange(int(min(X[:, 1])), int(max(X[:, 1])), 0.5)))
plt.grid()
plt.show()
# 模型结果可视化
plot_classifier( log_reg,X1,y1)
log_reg_pred = log_reg.predict(X1)
target_names = ['Class-0', 'Class-1']
print(classification_report(y1, log_reg_pred, target_names=target_names))
三、从零实现案例(非调库函数实现)
示例∶使用Logistic回归估计马疝病的死亡率
疝病是描述马胃肠痛的术语。然而,这种病不一定源自马的胃肠问题,其他问题也可能引发马疝病
(1)收集数据∶给定数据文件。
(2)准备数据∶用Python解析文本文件并填充缺失值。
(3)分析数据∶可视化并观察数据。
(4)训练算法∶使用优化算法,找到最佳的系数。
(5)测试算法∶为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,通过改变迭代的次数和步长等参数来得到更好的回归系数。
(6)使用算法
- 准备数据∶处理数据中的缺失值
- 使用可用特征的均值来填补缺失值;
- 使用特殊值来填补缺失值,如-1;
- 忽略有缺失值的样本;
- 使用相似样本的均值添补缺失值;
- 使用其他算法预测缺失值。
- 测试算法∶用Logistic回归进行分类
# 它以回归系数和特征向量作为输入来计算对应的Sigmoid值。
# 如果Sigmoid值大于0.5函数返回1,否则返回0。
'''
**改进的随机梯度上升算法**
+ alpha在每次迭代的时候都会调整,缓解数据波动,设置常数项使其不会减小到0
+ 在降低alpha的函数中,alpha每次减少1/j+i),其中j是迭代次数,i是样本点的下标①。这样当j<<max(i)时,alpha就不是严格下降的
+ 通过随机选取样本来更新回归系数,减少周期性的波动
+ 增加了一个迭代次数作为第3个参数
'''
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m, n = np.shape(dataMatrix)
weights = np.ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(np.random.uniform(0, len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open('./逻辑斯蒂/horseColicTraining.txt'); frTest = open('./逻辑斯蒂/horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, 1200)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr), trainWeights)) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print("the error rate of this test is: %f" % errorRate)
return errorRate
def multiTest():
numTests = 10; errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests)))
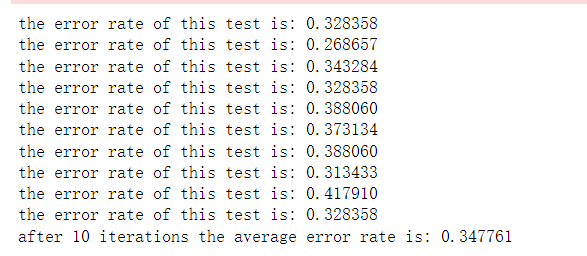
# 迭代次数为1000次
# 步长为0.0001
multiTest()
# 调整步长为0.0003
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m, n = np.shape(dataMatrix)
weights = np.ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0003 #apha decreases with iteration, does not
randIndex = int(np.random.uniform(0, len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
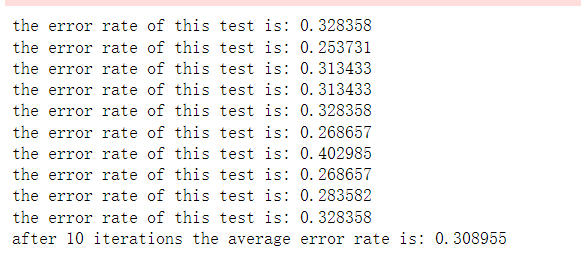
# 迭代次数为1200次
# 步长为0.0003
multiTest()
Tip:逻辑斯带算法对于分类问题比较简便,尤其是二分类问题,但是在调参过程中很难找到收敛的点,且对训练数据的好坏有较高要求。
参考文献:
[1] 机器学习-周志华
[2] 机器学习实战(中文版)-Peter Harrington
本文链接:http://t.csdn.cn/oNG7K
转载请显示来源~~

















 7529
7529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









