







文章目录
监督学习: 回归分析,主要应用在预测连续目标变量
- 探索和可视化数据集。
- 研究实现线性回归模型的不同方法。
- 训练有效解决异常值问题的回归模型。
- 评估回归模型并诊断常见问题。
- 拟合非线性数据的回归模型。
1. 线性回归简介
线性回归的目的是针对一个或多个特征与连续目标变量之间的关系建模。与监督学习分类相反,回归分析的主要目标是在连续尺度上预测输出,而不是在分类标签上。
在下面的小节中,我将介绍线性回归的最基本类型,即简单线性回归,并将它与更一般的多元情形(多特征的线性回归)联系起来。
1.1 简单线性回归
简单(单变量)线性回归的目的是针对单个特征(解释变量x)和连续目标值(响应变量y)之间的关系建模。拥有一个解释变量的线性回归模型的方程定义如下:
y = w 0 + w 1 x y=w_0+w_1x y=w0+w1x
权重 w 0 w_0 w0 代表 y y y 轴截距, w 1 w_1 w1 为解释变量的权重系数。我们的目标是学习线性方程的权重,以描述解释变量和目标变量之间的关系,然后预测训练数据集里未见过的新响应变量。根据前面的定义,线性回归可以理解为通过采样点找到最佳拟合直线,如图10-1所示。
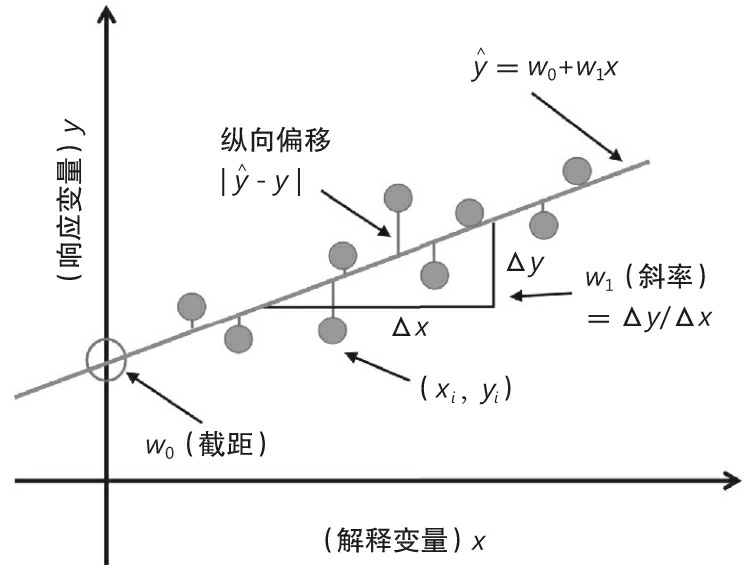
这条最佳拟合线也被称为回归线,从回归线到样本点的垂直线就是所谓的偏移(offset)或残差(residual)—— 预测的误差。
1.2 多元线性回归
前一节引入了单解释变量的线性回归分析,也称为简单线性回归。当然,也可以将线性回归模型推广到多个解释变量,这个过程叫作多元线性回归:
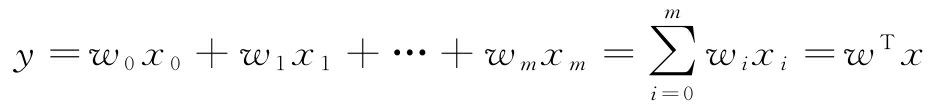
这里, w 0 w_0 w0 是当 x 0 = 1 x_0=1 x0=1 时的 y y y 轴截距。
图 10-2 显示了具有两个特征的多元线性回归模型的二维拟合超平面
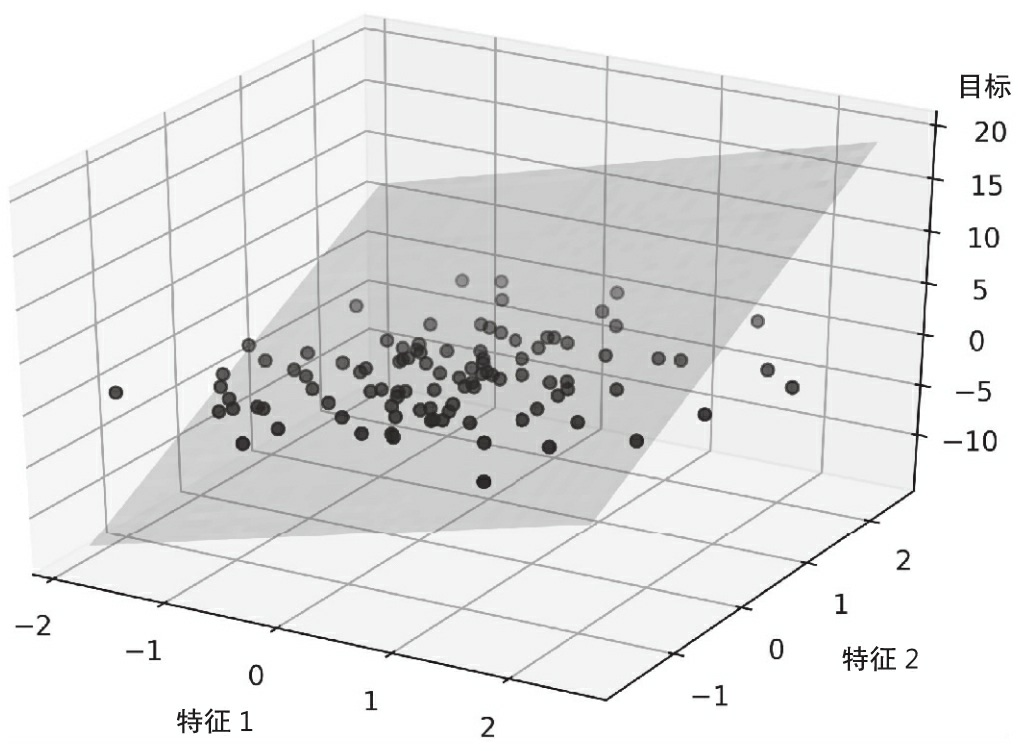
正如我们所看到的,三维散点图中多元线性回归超平面的可视化在静态图像时已经很难描述了。由于我们没有更好的方法来可视化二维平面的散点图(多元线性回归模型拟合三个或多个特征的数据集),本章的示例和可视化将主要集中在采用简单线性回归的单变量情况。然而,简单和多元线性回归基于相同的概念和评估技术,本章所讨论的代码实现也与这两种回归模型兼容。
2. 探索住房数据集
在实现第一个线性回归模型之前,我们先介绍一个新数据集,即住房数据集,其中包含了由D·Harrison和D. L. Rubinfeld在1978年收集的波士顿郊区的住房信息。现在住房数据集已经可以免费获取,并包含在本书的代码包中。该数据集最近已从UCI机器学习库中删除,但是我们仍
然可以从 https://raw.githubusercontent.com/rasbt/pythonmachine-learning-book-3rd-edition/master/ch10/housing.data.txt 或者scikit-learn(https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/datasets/data/boston_house_prices.csv)获取。像每个新数据集一样,通过简单的可视化来探索对我们会有所帮助,这可以更好地理解我们所面对的工作和数据。
2.1 加载住房数据
本节我们将调用pandas的read_csv函数加载住房数据,该工具快速灵活,是处理纯文本格式表格数据的推荐工具。
我们在这里总结了住房数据集中所包含的506个样本的特征,来源于先前共享的原始数据源
(https://archive.ics.uci.edu/ml/datasets/Housing):
- CRIM:城镇人均犯罪率。
- ZN:占地面积超过25000平方英尺(1平方英尺=0.092903平方米)的住宅用地比例。
- INDUS:城镇非零售营业面积占比。
- CHAS:查尔斯河虚拟变量(如果是界河,值为1,否则为0)。
- NOX:一氧化氮浓度(每千万分之一)。
- RM:平均每户的房间数。
- AGE:1940年以前建造的业主自住房屋比例。
- DIS:房屋距离波士顿五个就业中心的加权距离。
- RAD:辐射公路可达性指数。
- TAX:每10000美元全额财产的税率。
- PTRATIO:城镇师生比例。
- B:1000(Bk-0.63)2,其中Bk是城镇中非裔美国人的比例。
- LSTAT:弱势群体人口的百分比。
- MEDV:业主自住房的中位价(以1000美元为单位)。
我们将在本章的其余部分把房价(MEDV)作为目标变量,即基于13个解释变量中的1个或多个来预测房价。在进一步探讨该数据之前,我们先把数据从UCI导入到pandas的DataFrame:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/rasbt/'
'python-machine-learning-book-2nd-edition'
'/master/code/ch10/housing.data.txt',
header=None,
sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS',
'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df.head()
为了确认数据集已被成功加载,我们显示数据集的前五行如表10-1所示。
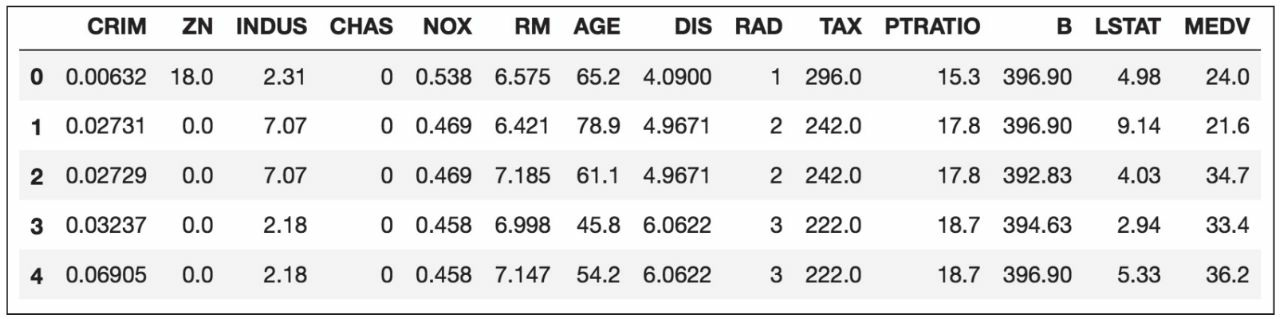
你可以在本文的代码包中找到该住房数据集(以及用到的所有其他数据集)的副本,如果脱机工作或网络链接中断,你可以从下面的链接获得:https://raw.githubusercontent.com/rasbt/pythonmachine-learning-book-3rd-edition/master/code/ch10/housing.data.txt
2.2 可视化数据集的重要特点
探索性数据分析(EDA) 是在进行机器学习模型训练之前值得推荐的重要一步。在本节的其余部分,我们将使用图形化EDA工具箱中的一些简单而有用的技术,这些技术有助于直观地发现异常值、数据分布以及特征之间的关系。
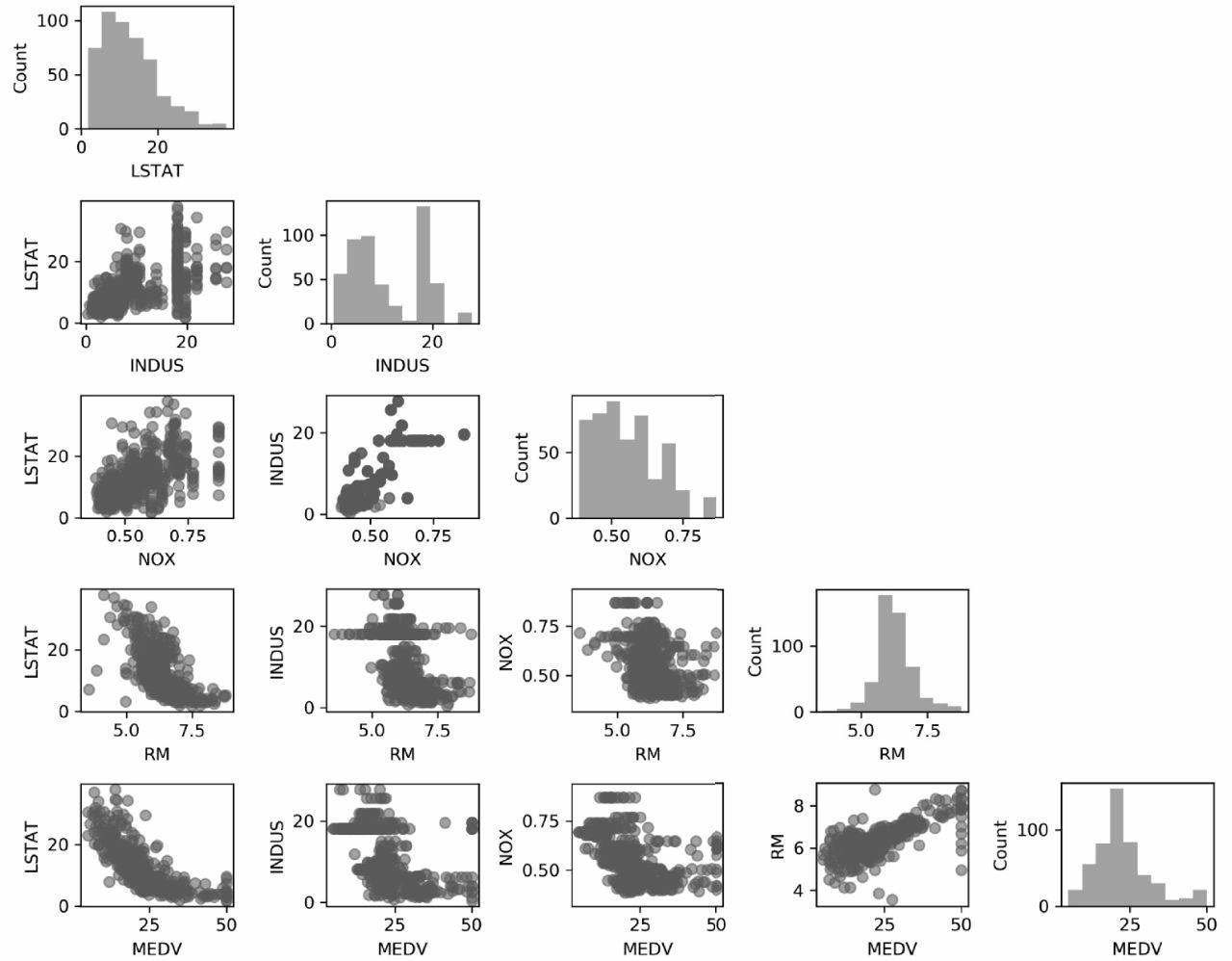
首先,我们创建一个散点图矩阵,把数据集中不同特征之间的成对相关性放在一张图上直观地表达出来。调用MLxtend库(http://rasbt.github.io/mlxtend/)的scatterplotmatrix函数绘制散点图矩阵,这是包含机器学习和数据科学应用各种便捷功能的Python库。
我们可以通过 conda install mlxtend 或者 pip install mlxtend 安装 mlxtend 软件包。在安装完成之后,我们导入软件包并创建散点图矩阵,具体的示例代码如下:
import matplotlib.pyplot as plt
from mlxtend.plotting import scatterplotmatrix
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
scatterplotmatrix(df[cols].values, figsize=(10, 8), name=cols, alpha=0.5)
plt.tight_layout()
plt.show()
从图10-3可以看到,散点图矩阵展示了数据集内部特征之间的关系,是一种有价值的图形汇总。
或者用如下代码:
import matplotlib.pyplot as plt
import seaborn as sns
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
sns.pairplot(df[cols], size=2.5)
plt.tight_layout()
# plt.savefig('images/10_03.png', dpi=300)
plt.show()
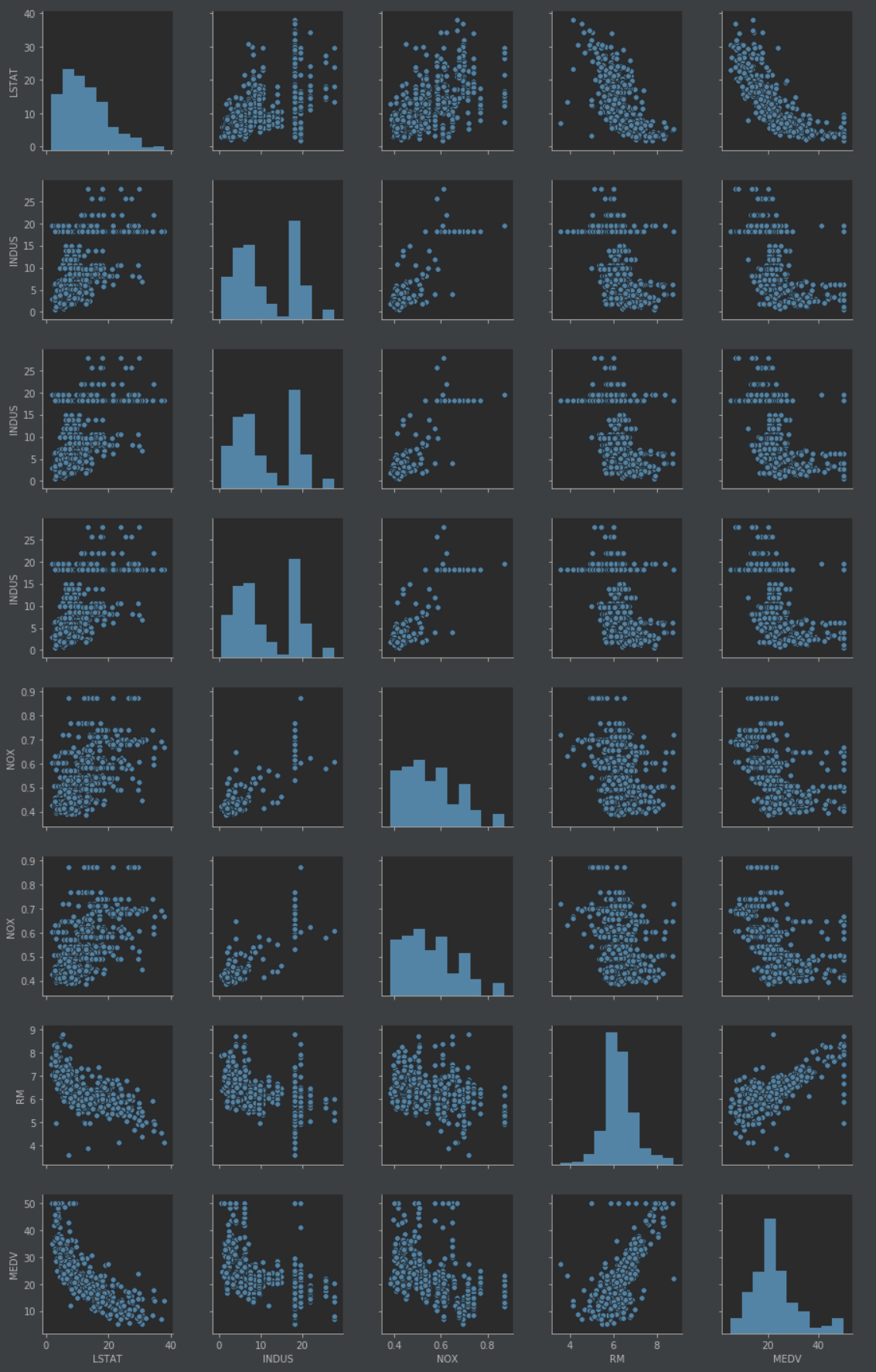
由于篇幅限制同时考虑到读者的兴趣,我们在本章只绘制数据集中的五列:LSTAT、INDUS、NOX、RM和MEDV。然而,你可以创建一个基于DataFrame的全散点图矩阵,调用前面的scatterplotmatrix函数来选择不同列的名称,或通过省略列选择器来直接包括在散点图矩阵中的所有变量,然后进一步探索该数据集。
可以利用散点图矩阵快速分辨出数据的分布情况以及是否含有异常值。例如,可以看到房间数RM和房价MEDV(第四行第五列)之间存在着线性关系。此外,我们还可以从散点图矩阵右下角的直方图看到,MEDV变量似乎呈正态分布,但包含了几个异常值。
线性回归的正态假设
注意,与一般的想法相反,训练线性回归模型并不要求解释变量或目标变量呈正态分布。正态假设只是针对某些统计和假设检验的要求,关于这部分的讨论超出了本书的范围[1]。
2.3 用相关矩阵查看关系
上一节我们把住房数据集变量的数据分布以直方图和散点图的形式可视化。下一步将创建相关矩阵来量化和概括变量之间的线性关系。相关矩阵与协方差矩阵密切相关。直观地说,我们可以把相关矩阵理解为对协方差矩阵的修正。事实上,相关矩阵与协方差矩阵在标准化特征计算方面保持一致。
相关矩阵是包含皮尔逊积矩相关系数(通常简称为皮尔逊r)的方阵,我们用它来度量特征对之间的线性依赖关系。相关系数的值在-1到1之间。如果r=1,则两个特征之间呈完美的正相关;如果r=0,则两者之间没有关系;如果r=-1,则两者之间呈完全负相关的关系。如前所述,我们可以把皮尔逊相关系数简单地计算为特征x和y之间的协方差(分子)除以标准差的乘积(分母):
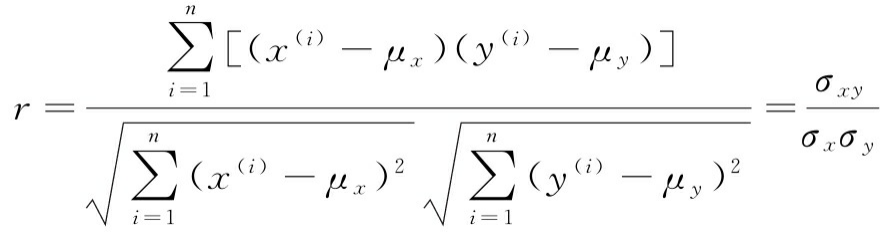
这里, μ μ μ 为样本的均值, σ x y σ_{xy} σxy 为样本 x x x 和 y y y 之间的协方差, σ x σ_x σx 和 σ y σ_y σy 为样本的标准差。
标准化特征的协方差与相关性
可以证明,一对经标准化的特征之间的协方差实际上等于它们的线性相关系数。为了证明这一点,我们先标准化特征
x
x
x和
y
y
y以获得它们的
z
z
z分数,分别用
x
′
x^′
x′和
y
′
y^′
y′来表示:
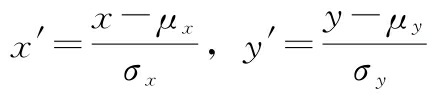
请记住,计算两个特征之间的(总体)协方差如下:
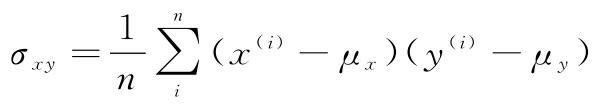
因为标准化一个特征变量后,其均值为0,所以现在可以通过下式计算缩放后特征之间的协方差:
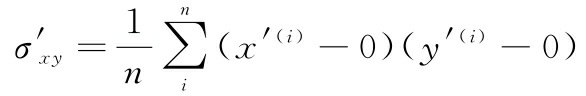
通过代入 x ′ x^′ x′和 y ′ y^′ y′得到下面的结果:
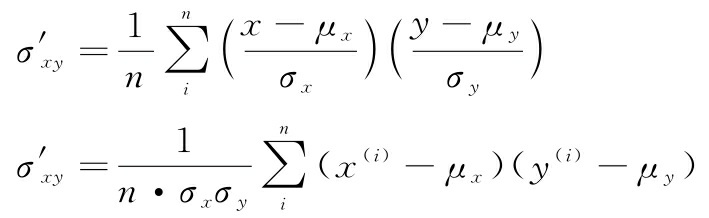
最后,我们简化该等式如下:
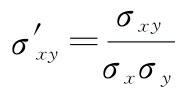
在下面的代码示例中,我们将调用NumPy的corrcoef函数处理前面可视化散点图矩阵的5个特征列,调用MLxtend的heatmap函数绘制相关矩阵对应的热度图:
import numpy as np
cm = np.corrcoef(df[cols].values.T)
#sns.set(font_scale=1.5)
hm = sns.heatmap(cm,
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 15},
yticklabels=cols,
xticklabels=cols)
plt.tight_layout()
# plt.savefig('images/10_04.png', dpi=300)
plt.show()
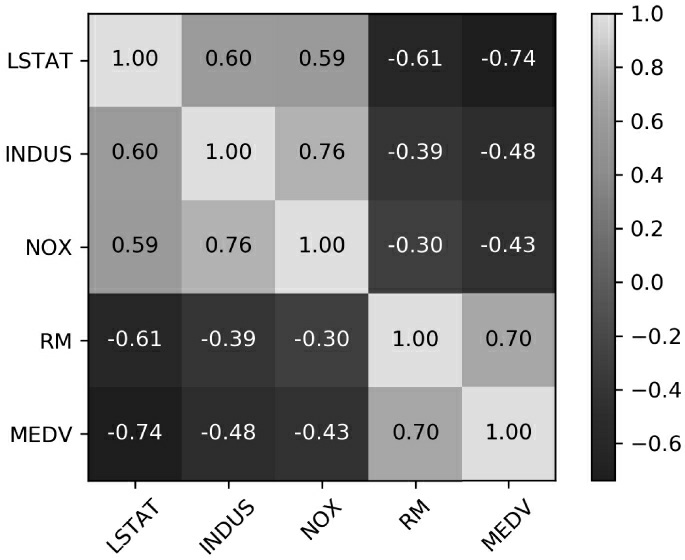
为了拟合线性回归模型,我们只对那些与目标变量MEDV高度相关的特征感兴趣。分析前面的相关矩阵,我们发现目标变量MEDV与变量LSTAT(-0.74)之间的相关性最大。然而,可能你还记得在检查散点图矩阵时,我们曾经发现LSTAT和MEDV之间存在着明显的非线性关系。另一方面,RM和MEDV之间的相关性相对来说也比较高(0.70)。因为从散点图观察到两个变量之间存在着线性关系,RM似乎是下面要介绍的简单线性回归模型中探索变量的合适选择。
3. 普通最小二乘线性回归模型的实现
在本章的开头部分,我们提到过可以把线性回归理解为通过训练数据的样本点获得最佳拟合直线。然而,我们既没有定义最佳拟合(best-fitting),也没有讨论过拟合模型的不同技术。下面的小节,我们将用普通最小二乘(OLS)法(有时也称为线性最小二乘)来填补缺失的部分并估计线性回归的参数,从而使样本点与线的垂直距离(残差或误差)之平方和最小
3.1 用梯度下降方法求解回归参数
还记得人工神经元采用线性激活函数吗?在第2章中,我们实现了自适应线性神经元(Adaline)。同时,我们还定义了代价函数J(w),并通过优化算法来最小化代价函数的学习权重,这些算法包括梯度下降(GD)和随机梯度下降(SGD)。Adaline的代价函数是误差平方和(SSE),它与OLS所用的代价函数相同。
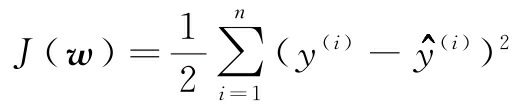
这里,
y
^
\hat{y}
y^ 为预测值
y
^
=
w
T
x
\hat{y} = w^Tx
y^=wTx(注意
1
2
\frac{1}{2}
21 只是为了方便推导 GD 的更新规则)。OLS回归基本上可以理解为没有单位阶跃函数的Adaline,这样我们就可以得到连续的目标值,而不是分类标签-1和1。为了证明这一点,以第2章中的Adaline GD实现为基础,去除单位阶跃函数来实现第
一个线性回归模型:
class LinearRegressionGD(object):
def __init__(self, eta=0.001, n_iter=20):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
self.w_ = np.zeros(1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
output = self.net_input(X)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors**2).sum() / 2.0
self.cost_.append(cost)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
return self.net_input(X)
附:用梯度下降更新权重
为了观察LinearRegressionGD回归器的具体实现,我们用住房数据的RM(房间数)变量作为解释变量,训练可以预测MEDV(房价)的模型。此外通过标准化变量以确保GD算法具有更好的收敛性。示例代码如下:
X = df[['RM']].values
y = df['MEDV'].values
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
sc_y = StandardScaler()
X_std = sc_x.fit_transform(X)
y_std = sc_y.fit_transform(y[:, np.newaxis]).flatten()
lr = LinearRegressionGD()
lr.fit(X_std, y_std)
你可能已经注意到有关用np.newaxis和flatten变通y_std的方法。scikit-learn的大多数转换器期望数据存储在二维数组中。前面的代码示例用y[:, np.newaxis]为数组添加了一个新维度。然后,StandardScaler返回缩放后的变量,为了方便用flatten()方法将其转换回原来的一维数组。
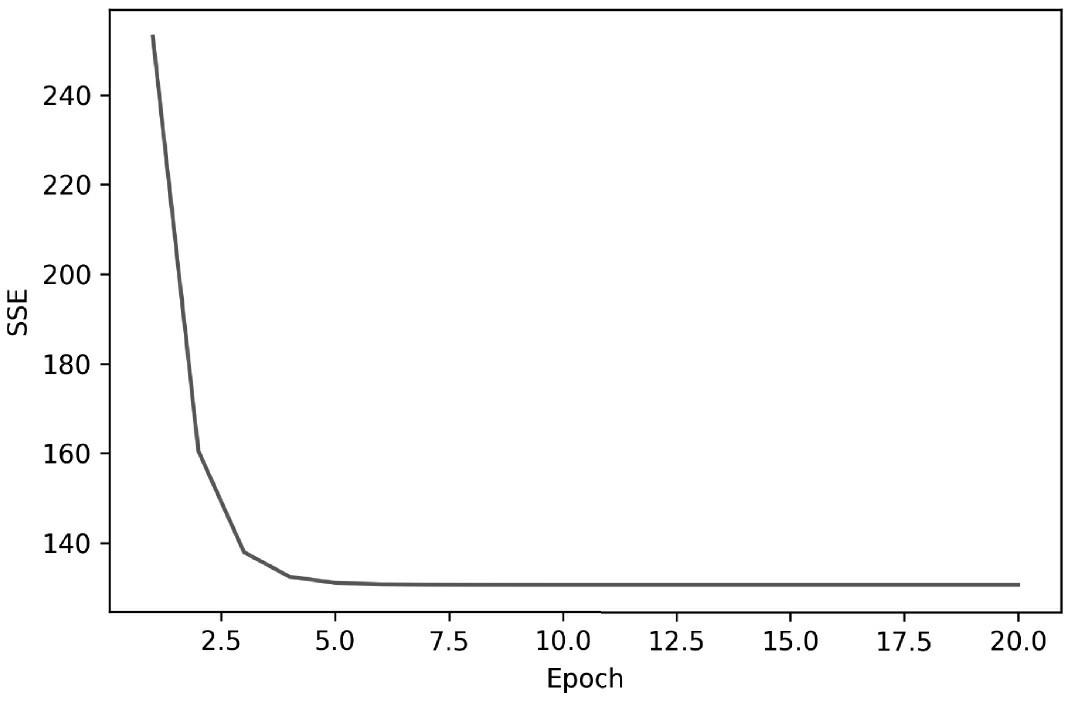
在第2章中,我们曾经讨论过将代价作为训练数据集上迭代次数的函数,用诸如梯度下降这样的优化算法来检查是否收敛到了最低代价(这里指的是全局性最小代价值),以此为基础绘制代价图确实是个不错的主意:
plt.plot(range(1, lr.n_iter+1), lr.cost_)
plt.ylabel('SSE')
plt.xlabel('Epoch')
#plt.tight_layout()
#plt.savefig('images/10_05.png', dpi=300)
plt.show()
正如图10-5所示,GD算法在第五次迭代后开始收敛
接着,我们通过可视化手段,观察线性回归与训练数据的拟合程度。为此,我们定义简单的辅助函数来绘制训练样本的散点图并添加回归线:
def lin_regplot(X, y, model):
plt.scatter(X, y, c='steelblue', edgecolor='white', s=70)
plt.plot(X, model.predict(X), color='black', lw=2)
return
现在,我们用lin_regplot函数来绘制房间数目与房价之间的关系图:
lin_regplot(X_std, y_std, lr)
plt.xlabel('Average number of rooms [RM] (standardized)')
plt.ylabel('Price in $1000s [MEDV] (standardized)')
#plt.savefig('images/10_06.png', dpi=300)
plt.show()
如图10-6所示,线性回归反映了房价随房间数目增加的基本趋势。
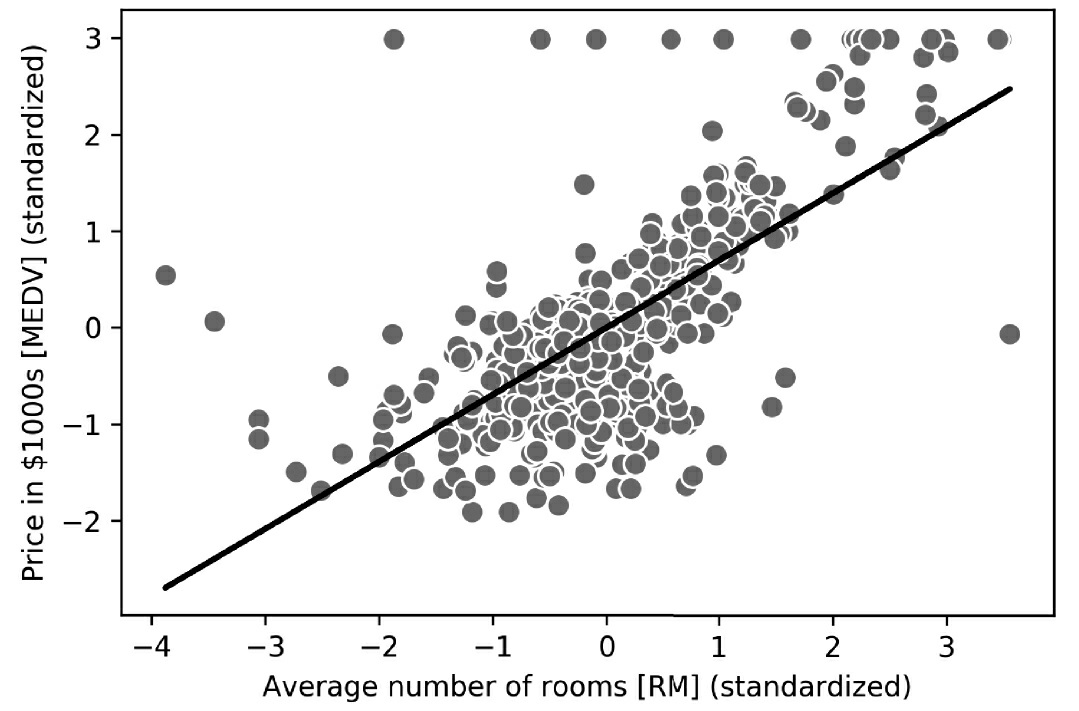
虽然该观察结果很自然,但是数据也告诉我们,在许多情况下,房间数目并不能很好地解释房价。本章后面将讨论如何量化回归模型的性能。有趣的是观察到在y=3的时候有几个数据点形成了一个横排,这表明价格对房间数目可能已经不再敏感。在某些应用中,将预测结果变量以原始缩放进行报告也很重要。我们可以直接调用StandardScaler的inverse_transform方法,把我们对价格预测的结果恢复到以Price in$1000s坐标轴上:
num_rooms_std = sc_x.transform(np.array([[5.0]]))
price_std = lr.predict(num_rooms_std)
print("Price in $1000s: %.3f" % sc_y.inverse_transform(price_std))

这个示例代码用我们以前训练过的线性回归模型来预测有五个房间的房屋的价格。根据模型计算,这样的房屋的价值为10840美元。另一方面,值得一提的是如果我们处理标准化变量,从技术角度来说,并不需要更新截距的权重,因为在这种情况下,y轴的截距总是0。因此可以通过显示权重来快速确认:
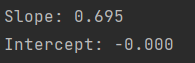
print('Slope: %.3f' % lr.w_[1])
print('Intercept: %.3f' % lr.w_[0])
3.2 通过scikit-learn估计回归模型的系数
上一节,我们实现了一个可用的回归分析模型;然而,在实际应用中,我们可能对所实现模型的高效性更感兴趣。例如,许多用于回归的scikit-learn估计器都采用SciPy(scipy.linalg.lstsq)中的最小二乘法来实现,而后者又采用在线性代数包(LAPACK)的基础上高度优化过的代码进行优化。scikit-learn中所实现的线性回归也可以(更好)用于未标准化的变量,因为它不采用基于(S)GD的优化,因此我们可以跳过标准化的步骤:
from sklearn.linear_model import LinearRegression
slr = LinearRegression()
slr.fit(X, y)
y_pred = slr.predict(X)
print('Slope: %.3f' % slr.coef_[0])
print('Intercept: %.3f' % slr.intercept_)

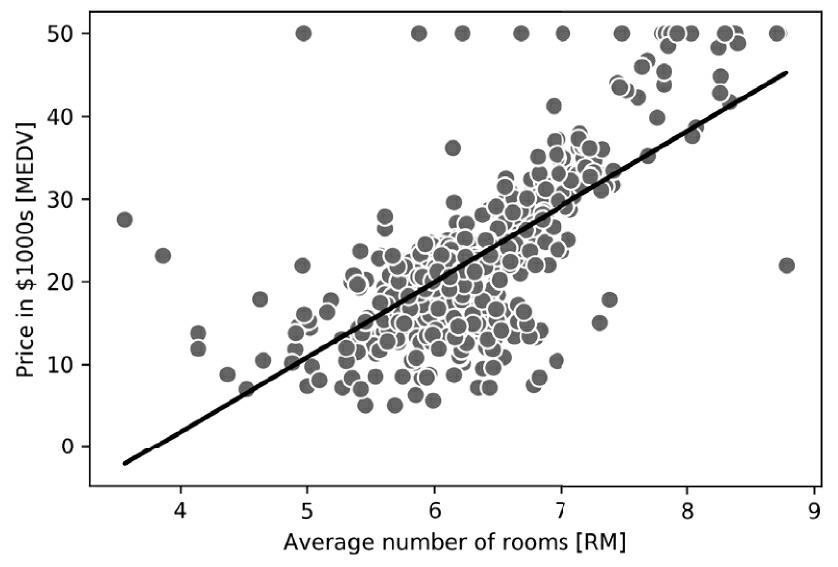
执行该代码后可以看到,由于函数尚未标准化,因此scikit-learn的LinearRegression模型(使用未标准化的RM和MEDV变量进行筛选)产生了不同的模型系数。但是,当我们通过绘制MEDV与RM的关系图来将其与GD实现进行比较时,可以定性地看到它也能很好地拟合数据:
lin_regplot(X, y, slr)
plt.xlabel('Average number of rooms [RM]')
plt.ylabel('Price in $1000s [MEDV]')
#plt.savefig('images/10_07.png', dpi=300)
plt.show()
执行这些代码绘制训练数据和拟合模型,从图10-7可以看到预测结果在总体上与前面所实现的GD一致。
附:线性回归的分析解
除机器学习库外,另一个选择是用封闭形态的OLS解决方案,这涉及线性方程组,可以从大多数入门级统计教科书中找到相应的介绍:
w
=
(
X
T
X
)
−
1
X
T
y
w=(X^TX)^{-1}X^Ty
w=(XTX)−1XTy
用Python实现如下:
# adding a column vector of "ones"
Xb = np.hstack((np.ones((X.shape[0], 1)), X))
w = np.zeros(X.shape[1])
z = np.linalg.inv(np.dot(Xb.T, Xb))
w = np.dot(z, np.dot(Xb.T, y))
print('Slope: %.3f' % w[1])
print('Intercept: %.3f' % w[0])
这种方法的优点是保证能通过分析找到最优解。但是,如果我们面对的是非常大的数据集,那么在该公式中矩阵求逆(有时也称为正规方程)计算可能就非常昂贵,包含训练样本的矩阵有可能成为奇异矩阵(不可逆),这就是在某些情况下我们可能更喜欢迭代的原因。
4. 利用RANSAC拟合鲁棒回归模型
线性回归模型可能会受到异常值的严重影响。在某些情况下,一小部分数据可能会对估计的模型系数有很大的影响。有许多统计检验可以用来检测异常值,这超出了本书的范围。然而,去除异常值需要数据科学家的判断以及相关领域知识。
除了淘汰异常值之外,我们还有一种鲁棒回归方法,即随机抽样一致性(RANdom SAmple Consensus,RANSAC)算法,根据数据子集(所谓的内点,inlier)来拟合回归模型。
总结迭代RANSAC算法如下:
- 1)随机选择一定数量的样本作为内点来拟合模型。
- 2)用模型测试所有其他的数据点,把落在用户给定公差范围内的点放入内点集。
- 3)用内点重新拟合模型。
- 4)估计模型预测结果与内点集相比较的误差。
- 5)如果性能达到用户定义的阈值或指定的迭代数则终止算法;否则返回到步骤1。
现在用scikit-learn的RANSACRegressor类实现基于RANSAC算法的线性模型:
from sklearn.linear_model import RANSACRegressor
ransac = RANSACRegressor(LinearRegression(),
max_trials=100,
min_samples=50,
loss='absolute_loss',
residual_threshold=5.0,
random_state=0)
ransac.fit(X, y)
inlier_mask = ransac.inlier_mask_
outlier_mask = np.logical_not(inlier_mask)
line_X = np.arange(3, 10, 1)
line_y_ransac = ransac.predict(line_X[:, np.newaxis])
plt.scatter(X[inlier_mask], y[inlier_mask],
c='steelblue', edgecolor='white',
marker='o', label='Inliers')
plt.scatter(X[outlier_mask], y[outlier_mask],
c='limegreen', edgecolor='white',
marker='s', label='Outliers')
plt.plot(line_X, line_y_ransac, color='black', lw=2)
plt.xlabel('Average number of rooms [RM]')
plt.ylabel('Price in $1000s [MEDV]')
plt.legend(loc='upper left')
#plt.savefig('images/10_08.png', dpi=300)
plt.show()
我们设置RANSACRegressor的最大迭代次数为100,用min_samples=50设置随机选择的最小样本数量为50。我们用’absolute_loss’作为形式参数loss的实际参数,该算法计算拟合线和采样点之间的绝对垂直距离。通过将residual_threshold参数设置为5.0,使内点集仅包括与拟合线垂直距离在5个单位以内的采样点,这对特定数据集的效果很好。
在默认情况下,scikit-learn用MAD估计内点选择的阈值,MAD是目标值y的中位数绝对偏差(Median Absolute Deviation)的缩写。然而,选择适当的内点阈值将因问题而异,这是RANSAC的不利之处。最近几年,我们研究了许多种不同的方法来自动选择适宜的内点阈值。更详细的讨论见Automatic Estimation of the Inlier Threshold in Robust Multiple Structures Fitting, R. Toldo, A. Fusiello’s, Springer, 2009(in Image Analysis and Processing-ICIAP 2009, pages: 123-131)。
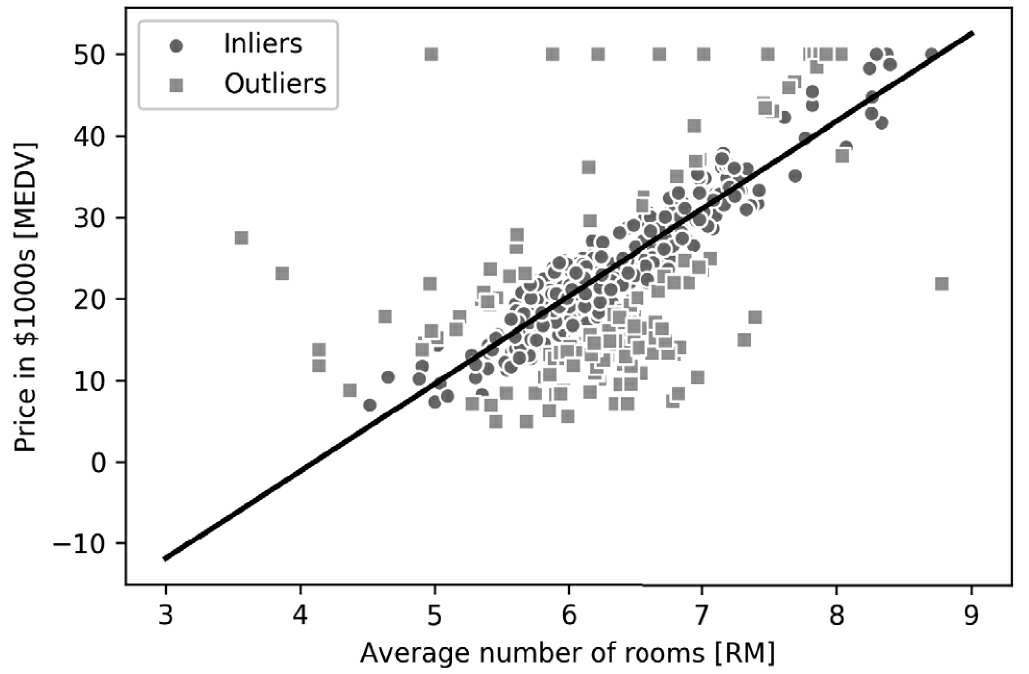
在拟合RANSAC模型之后,我们可以根据用RANSAC算法拟合的线性回归模型获得内点和异常值,并且把这些点与线性拟合的情况绘制成图:
从图10-8的散点图中,我们可以看到线性回归模型是通过检测出的内点集合(以圆形表示)拟合得到的。
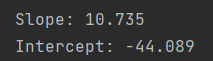
执行下面的代码,在利用模型计算出斜率和截距之后,我们可以看到线性回归拟合的线与前一节未用RANSAC拟合的结果有些不同:
print('Slope: %.3f' % ransac.estimator_.coef_[0])
print('Intercept: %.3f' % ransac.estimator_.intercept_)
RANSAC降低了数据集中异常值的潜在影响,但是,我们并不知道这种方法对未见过数据的预测性能是否有良性影响。因此,我们将在下一节研究评估回归模型的不同方法,这是建立预测模型系统的关键。
5. 评估线性回归模型的性能
在前一节,我们学习了如何在训练数据上拟合回归模型。然而,我们在前几章中了解到,用训练期间从未见过的数据对模型进行测试,可以获得对性能的无偏估计,这非常重要。
还记得在第6章中,我们把数据集分成单独的训练数据集和测试数据集,我们用前者拟合模型,用后者来评估当模型推广到从未见过的新数据时的泛化性能。我们不再使用简单回归模型,而是用数据集中的所有变量来训练多元回归模型:
from sklearn.model_selection import train_test_split
X = df.iloc[:, :-1].values
y = df['MEDV'].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)
slr = LinearRegression()
slr.fit(X_train, y_train)
y_train_pred = slr.predict(X_train)
y_test_pred = slr.predict(X_test)
由于模型使用了多个解释变量,因此我们无法在二维图中可视化线性回归线(或者更准确地说是超平面),但是可以通过绘制残差(实际值和预测值之间的差异或垂直距离)与预测值来判断回归模型。残差图是判断回归模型常用的图形工具。这有助于检测非线性和异常值,并检查这些误差是否呈随机分布。
执行下面的代码,我们可以绘制出残差图,这里的残差为预测值直接减去真实目标变量:
plt.scatter(y_train_pred, y_train_pred - y_train,
c='steelblue', marker='o', edgecolor='white',
label='Training data')
plt.scatter(y_test_pred, y_test_pred - y_test,
c='limegreen', marker='s', edgecolor='white',
label='Test data')
plt.xlabel('Predicted values')
plt.ylabel('Residuals')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=-10, xmax=50, color='black', lw=2)
plt.xlim([-10, 50])
plt.tight_layout()
# plt.savefig('images/10_09.png', dpi=300)
plt.show()
在执行代码后,我们将会看到残差图中有一条线通过x轴原点,如图10-9所示。
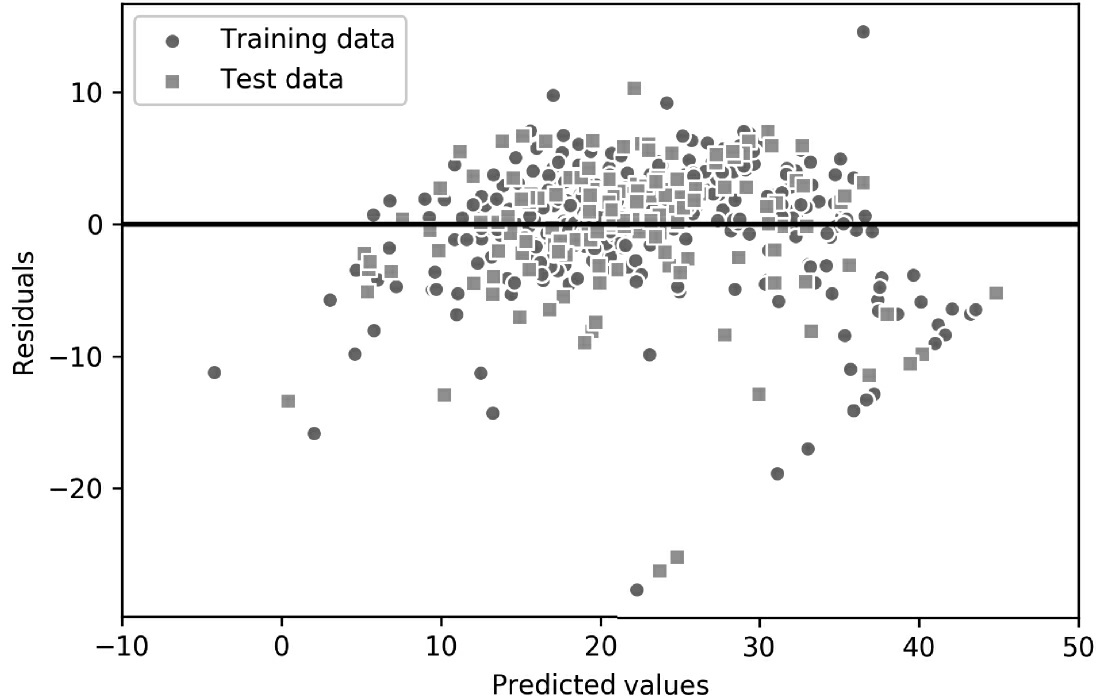
在完美预测的情况下,残差刚好为零,这是在现实和实际应用中可能永远都不会遇到的。然而,我们期望好的回归模型的误差呈随机分布,残差应该随机分布在中心线附近。如果从残差图中看到模式存在,就意味着模型无法捕捉到一些解释性信息,这些信息已经泄露到了残差中,如前面的残差图所示。此外,我们还可以用残差图来检测异常值点,这些异常值点由图中与中心线存在很大偏差的那些点来表示。
另一个有用的模型性能定量度量是所谓的均方误差(MSE),它仅仅是为了拟合线性回归模型而将SSE代价平均值最小化的结果。MSE对比较不同的回归模型或通过网格搜索和交叉验证调整其参数很有用,因为我们通过样本规模归一化SSE。
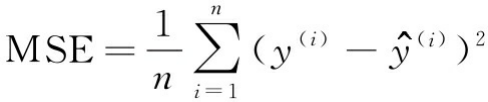
下面的代码将计算根据训练数据集和测试数据集进行预测的MSE:
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
print('MSE train: %.3f, test: %.3f' % (
mean_squared_error(y_train, y_train_pred),
mean_squared_error(y_test, y_test_pred)))
print('R^2 train: %.3f, test: %.3f' % (
r2_score(y_train, y_train_pred),
r2_score(y_test, y_test_pred)))

可以看到训练数据集的MSE为19.96,而测试数据集的MSE为27.20,测试数据集的MSE比较大,这是模型过拟合训练数据的标志。但是,请注意,例如,与分类准确率相比,MSE不受限制。换句话说,对MSE的解释取决于数据集和特征缩放。例如,如果以1000(用K表示)为单位计算房价,与未使用特征缩放的模型相比,该模型所产生的MSE较低,为了进一步说明这一点,(10K美元-15K美元)2<(10000美元-15000美元)。
有时候,报告决定系数(
R
2
R^2
R2)可能更为有用,我们可以把这理解为MSE的标准版,其目的是为更好地解释模型的性能。换句话说,
R
2
R^2
R2 是模
型捕获到的响应方差函数的一部分。我们定义
R
2
R^2
R2 值如下:
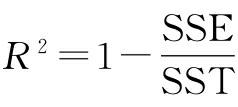
这里,SSE是平方误差之和,而SST是平方和之总和:
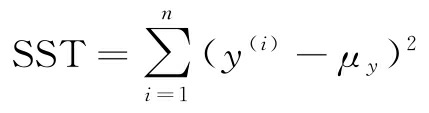
换句话说,SST只是反应的方差。下面将很快证明 R 2 R^2 R2的确只是修正版的MSE:

对于训练数据集, R 2 R^2 R2 的取值范围在0到1之间,但是它也可以是负值。如果 R 2 R^2 R2 = 1,当相应的MSE=0时,模型可以完美地拟合数据。
在训练数据集上进行评估,我们获得模型的 R 2 R^2 R2 为 0.765,这听起来并不太坏。但是,在测试数据集上进行评估,我们所获得的 R 2 R^2 R2 只有0.673,可以通过执行下面的代码来计算:
from sklearn.metrics import r2_score
print('R^2 train: %.3f, test: %.3f' % (
r2_score(y_train, y_train_pred),
r2_score(y_test, y_test_pred)))

6. 用正则化方法进行回归
正如我们在第3章所讨论的那样,正则化是通过添加额外信息解决过拟合问题的一种方法,而缩小模型参数值却引来复杂性的惩罚。正则线性回归最常用的方法包括所谓的岭回归、最小绝对收缩与选择算子(LASSO)以及弹性网络(Elastic Net)。
岭回归是一个L2惩罚模型,我们只需要把加权平方添加到最小二乘代价函数:
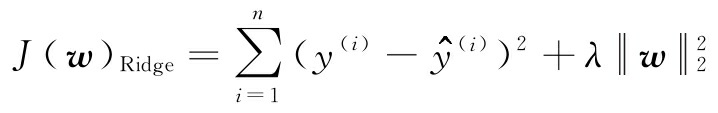
这里:
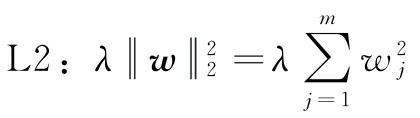
通过加大超参数λ的值,增加正则化的强度,同时收缩模型的权重。注意,不要正则化截距项w0。另一种可能导致稀疏模型的方法是LASSO。取决于正则化的强度,某些权重可能成为零,这也使LASSO成为监督特征选择的有用技术:
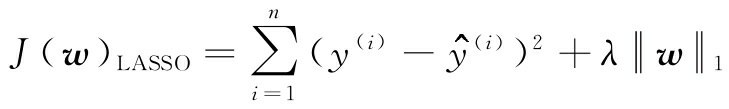
这里,对LASSO的L1惩罚定义为模型权重的绝对值之和,如下所示:
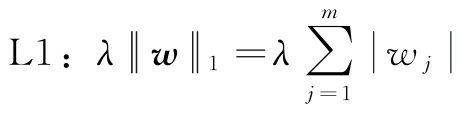
但是,LASSO的局限性在于,如果m>n,则最多可以选择n个特征,其中n为训练样本的数量。这在特征选择的某些应用中可能是不希望的。但是,LASSO的这种属性实际上是一个优势,因为它避免了模型饱和。如果训练样本的数量与特征的数量相同,就会出现模型饱和问题,这是过参数化的一种现象。因此,虽然饱和模型总能完美地拟合训练数据,但是这仅仅是插值的一种形式,无法泛化。
弹性网络是在岭回归和LASSO之间的折中,它以L1惩罚产生稀疏性,以L2惩罚用于选择n个以上的特征,条件是m>n:
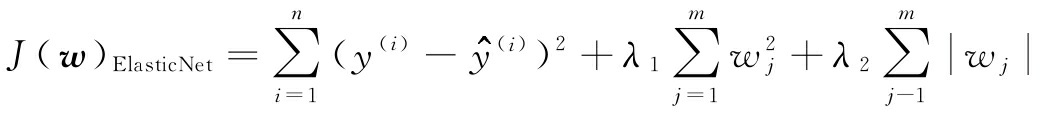
我们可以通过scikit-learn获得所有那些正则化回归模型,具体用法与普通回归模型类似,除了必须通过参数λ指定正则化强度之外,例如通过k折交叉验证优化。我们可以通过下述代码初始化岭回归模型:
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.0)
需要注意的是正则化强度依靠参数alpha的调节,这类似于参数λ。同样可以从linear_model模块初始化LASSO回归:
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=1.0)
最后,实现ElasticNet能够调整L1与L2的比例:
from sklearn.linear_model import ElasticNet
elanet = ElasticNet(alpha=1.0, l1_ratio=0.5)
例如,如果我们把l1_ratio设置为1.0,那么ElasticNet回归等同于
LASSO回归。有关线性回归不同实现的详细信息,请参阅http://scikit-learn.org/stable/modules/linear_model.html。
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
y_train_pred = lasso.predict(X_train)
y_test_pred = lasso.predict(X_test)
print(lasso.coef_)

print('MSE train: %.3f, test: %.3f' % (
mean_squared_error(y_train, y_train_pred),
mean_squared_error(y_test, y_test_pred)))
print('R^2 train: %.3f, test: %.3f' % (
r2_score(y_train, y_train_pred),
r2_score(y_test, y_test_pred)))

7. 将线性回归模型转换为曲线——多项式回归
我们在前面假设解释变量和响应变量之间存在着线性关系。一种有效解决违背线性假设的方法是,通过增加多项式项利用多项式回归模型:
y
=
w
0
+
w
1
x
+
w
2
x
2
+
…
+
w
d
x
d
y=w_0+w_1x+w_2x_2+…+w_dx_d
y=w0+w1x+w2x2+…+wdxd
这里d为多项式的次数。虽然可以用多项式回归来模拟非线性关系,但是因为存在线性回归系数w,它仍然被认为是多元线性回归模型。从下面的小节,我们将看到如何更方便地在现有数据集上,通过增加多项式项来拟合多项式回归模型。
7.1 用scikit-learn增加多项式项
现在,我们开始学习如何用scikit-learn的PolynomialFeatures转换类在只含一个解释变量的简单回归问题中增加二次项(d=2)。然后根据下面的步骤来比较多项式拟合与线性拟合:
1)增加一个二次多项式项:
X = np.array([258.0, 270.0, 294.0,
320.0, 342.0, 368.0,
396.0, 446.0, 480.0, 586.0])\
[:, np.newaxis]
y = np.array([236.4, 234.4, 252.8,
298.6, 314.2, 342.2,
360.8, 368.0, 391.2,
390.8])
from sklearn.preprocessing import PolynomialFeatures
lr = LinearRegression()
pr = LinearRegression()
quadratic = PolynomialFeatures(degree=2)
X_quad = quadratic.fit_transform(X)
2)为了比较,拟合一个简单线性回归模型:
# fit linear features
lr.fit(X, y)
X_fit = np.arange(250, 600, 10)[:, np.newaxis]
y_lin_fit = lr.predict(X_fit)
3)用转换后的特征针对多项式回归拟合一个多元回归模型:
# fit quadratic features
pr.fit(X_quad, y)
y_quad_fit = pr.predict(quadratic.fit_transform(X_fit))
4)绘制出结果:
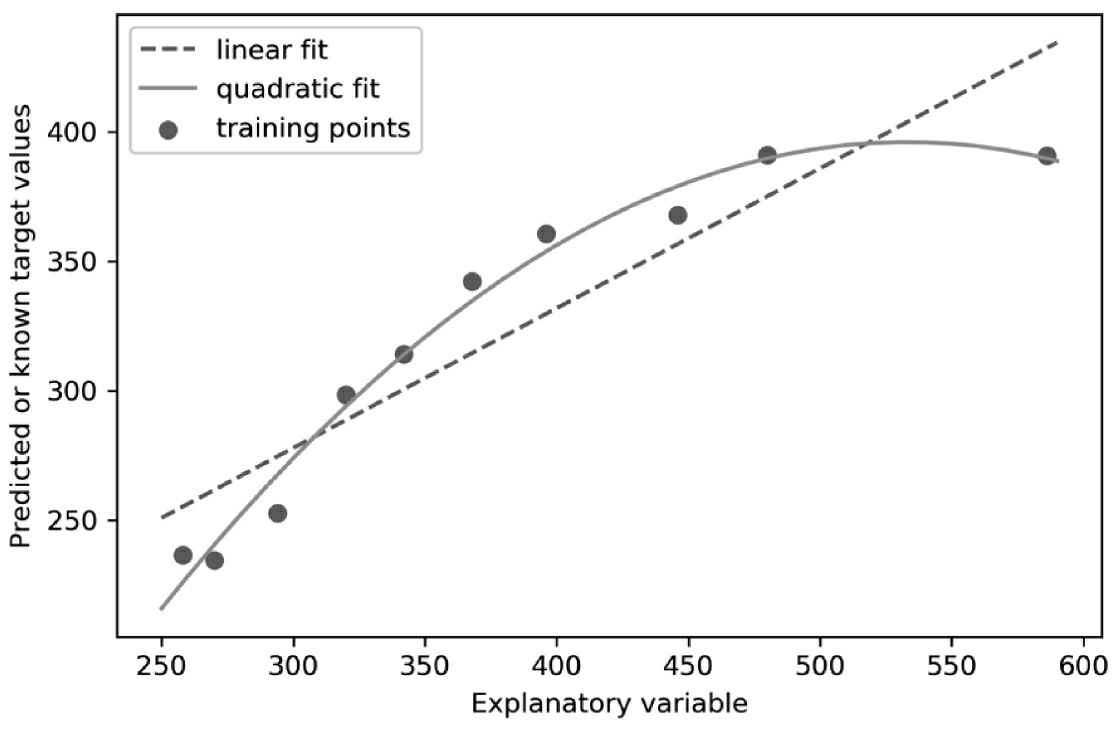
# plot results
plt.scatter(X, y, label='training points')
plt.plot(X_fit, y_lin_fit, label='linear fit', linestyle='--')
plt.plot(X_fit, y_quad_fit, label='quadratic fit')
plt.legend(loc='upper left')
plt.tight_layout()
#plt.savefig('images/10_10.png', dpi=300)
plt.show()
在图10-10中可以看到,多项式拟合比线性拟合能更好地反映响应变量和解释变量之间的关系。
接着,我们将计算MSE和 R 2 R^2 R2评估指标:
y_lin_pred = lr.predict(X)
y_quad_pred = pr.predict(X_quad)
print('Training MSE linear: %.3f, quadratic: %.3f' % (
mean_squared_error(y, y_lin_pred),
mean_squared_error(y, y_quad_pred)))
print('Training R^2 linear: %.3f, quadratic: %.3f' % (
r2_score(y, y_lin_pred),
r2_score(y, y_quad_pred)))

执行代码后,我们可以看到MSE从570(线性拟合)下降到61(二次项拟合);同时,对这个特定问题,决定系数反映出二次项模型拟合(R2=0.982)比线性拟合(R2=0.832)更加合适。
7.2 为住房数据集中的非线性关系建模
学习了如何构建多项式特征以拟合非线性关系后,现在我们可以通过一个更具体的例子,将这些概念应用于住房数据集。通过执行下面的代码,将用二次和三次多项式构建房价和LSTAT(弱势群体人口的百分比)之间关系的模型,并与线性拟合进行比较:
X = df[['LSTAT']].values
y = df['MEDV'].values
regr = LinearRegression()
# create quadratic features
quadratic = PolynomialFeatures(degree=2)
cubic = PolynomialFeatures(degree=3)
X_quad = quadratic.fit_transform(X)
X_cubic = cubic.fit_transform(X)
# fit features
X_fit = np.arange(X.min(), X.max(), 1)[:, np.newaxis]
regr = regr.fit(X, y)
y_lin_fit = regr.predict(X_fit)
linear_r2 = r2_score(y, regr.predict(X))
regr = regr.fit(X_quad, y)
y_quad_fit = regr.predict(quadratic.fit_transform(X_fit))
quadratic_r2 = r2_score(y, regr.predict(X_quad))
regr = regr.fit(X_cubic, y)
y_cubic_fit = regr.predict(cubic.fit_transform(X_fit))
cubic_r2 = r2_score(y, regr.predict(X_cubic))
# plot results
plt.scatter(X, y, label='training points', color='lightgray')
plt.plot(X_fit, y_lin_fit,
label='linear (d=1), $R^2=%.2f$' % linear_r2,
color='blue',
lw=2,
linestyle=':')
plt.plot(X_fit, y_quad_fit,
label='quadratic (d=2), $R^2=%.2f$' % quadratic_r2,
color='red',
lw=2,
linestyle='-')
plt.plot(X_fit, y_cubic_fit,
label='cubic (d=3), $R^2=%.2f$' % cubic_r2,
color='green',
lw=2,
linestyle='--')
plt.xlabel('% lower status of the population [LSTAT]')
plt.ylabel('Price in $1000s [MEDV]')
plt.legend(loc='upper right')
#plt.savefig('images/10_11.png', dpi=300)
plt.show()
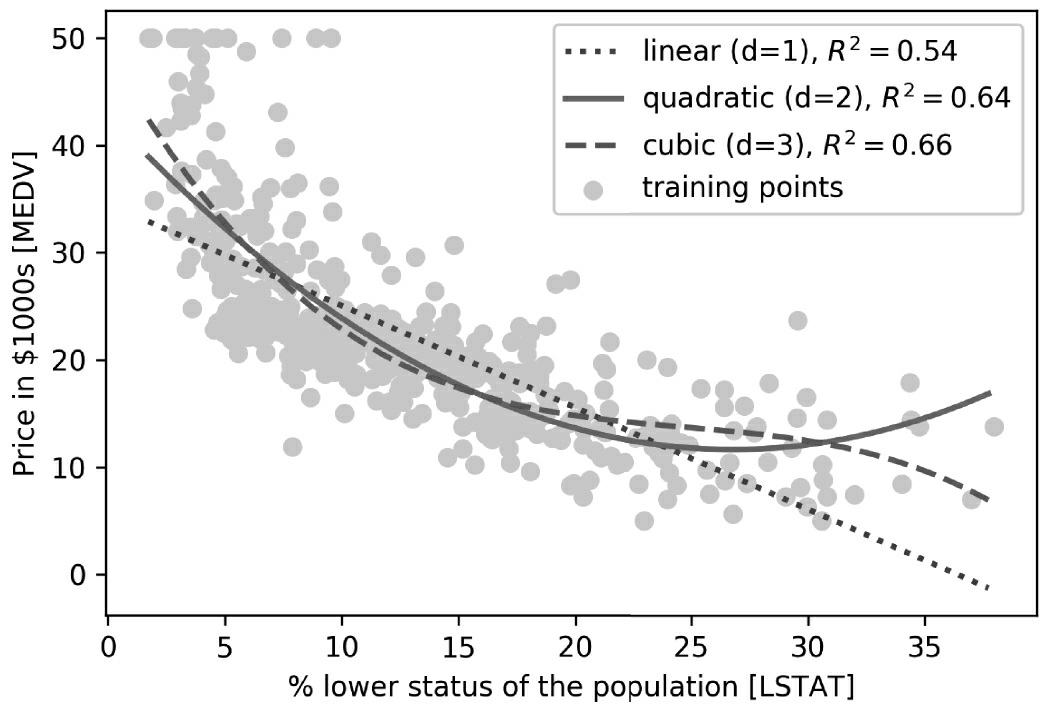
我们可以看到,三次拟合捕捉房价与LSTAT之间的关系优于线性拟合和二次拟合。然而应该意识到,增加越来越多的多项式特征也提高了模型的复杂性,因此增加了过拟合的机会。因此,我们在实践中总是建议在单独的测试数据集上评估模型的泛化性能。
此外,多项式特征对非线性关系建模并非总是最佳的选择。例如,如果我们有一些经验或直觉,只是看看MEDV-LSTAT的散点图就可能会得出这样的假设,LSTAT特征变量的对数变换和MEDV的平方根可能把数据投影到适合线性回归拟合的线性特征空间。例如,我认为这两个变量之间的关系看起来与指数函数相似:
f ( x ) = e − x f(x)=e^{-x} f(x)=e−x
由于指数函数的自然对数是一条直线,因此我认为这种对数变换用在这里应该很有效:
l
o
g
(
f
(
x
)
)
=
−
x
log(f(x))=-x
log(f(x))=−x
让我们通过执行下面的代码来检验这个假设:
X = df[['LSTAT']].values
y = df['MEDV'].values
# transform features
X_log = np.log(X)
y_sqrt = np.sqrt(y)
# fit features
X_fit = np.arange(X_log.min()-1, X_log.max()+1, 1)[:, np.newaxis]
regr = regr.fit(X_log, y_sqrt)
y_lin_fit = regr.predict(X_fit)
linear_r2 = r2_score(y_sqrt, regr.predict(X_log))
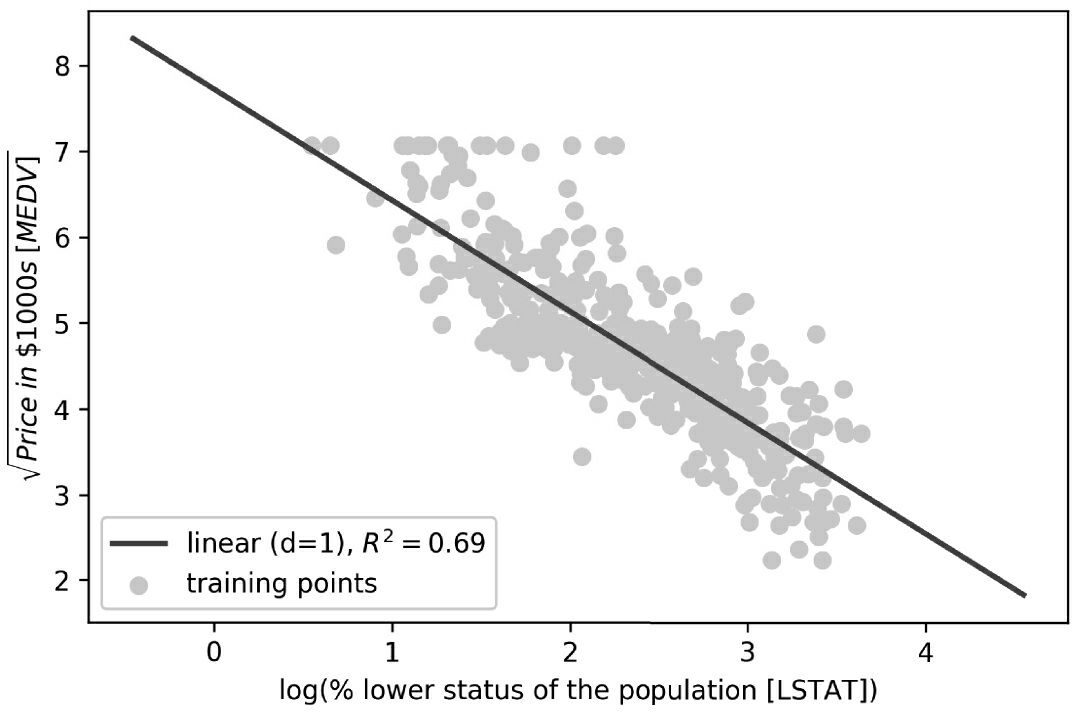
# plot results
plt.scatter(X_log, y_sqrt, label='training points', color='lightgray')
plt.plot(X_fit, y_lin_fit,
label='linear (d=1), $R^2=%.2f$' % linear_r2,
color='blue',
lw=2)
plt.xlabel('log(% lower status of the population [LSTAT])')
plt.ylabel('$\sqrt{Price \; in \; \$1000s \; [MEDV]}$')
plt.legend(loc='lower left')
plt.tight_layout()
#plt.savefig('images/10_12.png', dpi=300)
plt.show()
在将解释变量转换到对数空间并把目标变量取平方根之后,我们就能用线性回归捕捉两个变量之间的关系。这似乎比以前任何多项式特征变换都能更好地拟合数据变量( R 2 R^2 R2=0.69),如图10-12所示。
8. 用随机森林处理非线性关系
本节将讨论随机森林回归,它与本章以前的回归模型在概念上有所不同。随机森林是多棵决策树的组合,可以理解为分段线性函数之和,与以前讨论过的全局性线性和多项式回归模型相反。换句话说,通过决策树算法,我们可以进一步将输入空间细分为更小的区域,这些区域也因此变得更易于管理。
.8.1 决策树回归
决策树算法的一个优点是,如果处理非线性数据,它不需要对特征进行任何转换。因为决策树一次只分析一个特征,而不是考虑加权组合。(同样,决策树也不需要归一化或标准化函数)。还记得在第3章中,我们通过迭代分裂节点,直到叶子是纯的,或者满足停止分裂的标准为止,以培养一棵决策树。当用决策树进行分类时,定义熵作为杂质的指标以确定采用哪个特征分裂可以最大化信息增益(InformationGain, IG),二进制分裂可以定义为:
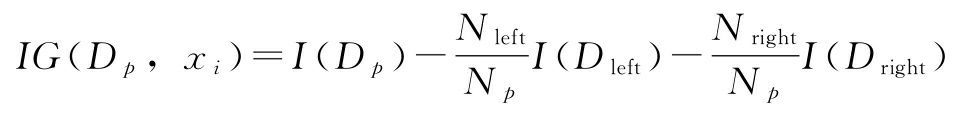
这里 x i x_i xi 是要分裂的样本特征, N p N_p Np 为父节点的样本数, I I I 为杂质函数, D p D_p Dp 是父节点训练样本子集。 D l e f t D_{left} Dleft和 D r i g h t D_{right} Dright 为分裂后左右两个子节点的训练样本集。记住,目标是要找到可以最大化信息增益的特征分裂,换句话说,希望找到可以减少子节点中杂质的分裂特征。在第3章中,我们讨论过基尼杂质和度量杂质的熵,这两个都是有用的分类标准。然而,为了把回归决策树用于回归,我们需要一个适合连续变量的杂质指标,所以,作为替换,我们把节点 t t t的杂质指标定义为MSE:
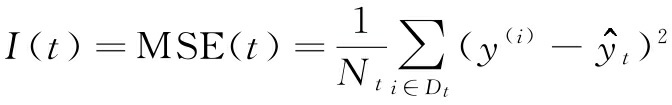
这里 N t N_t Nt为节点t的训练样本数, D t D_t Dt为节点 t t t的训练数据子集。 y ( i ) y^{(i)} y(i)为真实的目标值, y ^ t \hat{y}_t y^t 为预测的目标值(样本均值):
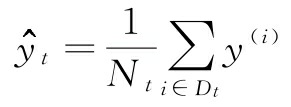
在决策树回归的背景下,通常我们也把MSE称为节点方差(within-node variance),这就是我们也把分裂标准称为方差缩减(variance reduction)的原因。用scikit-learn实现的DecisionTreeRegressor为变量MEDV和LSTAT之间的非线性关系建立模型,我们看下决策树线拟合的情况:
from sklearn.tree import DecisionTreeRegressor
X = df[['LSTAT']].values
y = df['MEDV'].values
tree = DecisionTreeRegressor(max_depth=3)
tree.fit(X, y)
sort_idx = X.flatten().argsort()
lin_regplot(X[sort_idx], y[sort_idx], tree)
plt.xlabel('% lower status of the population [LSTAT]')
plt.ylabel('Price in $1000s [MEDV]')
#plt.savefig('images/10_13.png', dpi=300)
plt.show()
正如我们在图10-13中所看到的那样,决策树捕获了数据中的基本趋势。然而,这种模式的一个局限性在于它并不捕获所需预测的连续性和可微性。此外,在选择树的适当深度值时要小心,既要确保不过拟合也要避免欠拟合。这里深度为3似乎是个不错的选择。

下一节将研究一种鲁棒的回归树拟合方法:随机森林。
8.2 随机森林回归
正如我们在第3章中学到的,随机森林算法是一种组合了多棵决策树的技术。由于随机性,随机森林通常比单决策树具有更好的泛化性能,这有助于减少模型的方差。随机森林的其他优点还包括它对数据集中的异常值不敏感,而且也不需要太多的参数优化。随机森林中通常唯一需要试验的参数是集成中决策树的棵数。基本的回归随机森林算法,与我们在第3章中讨论过的随机森林分类算法几乎相同,唯一不同的是用MSE准则来培育每棵决策树,并用决策树的平均预测值来计算预测的目标变量。
现在,让我们用住房数据集中的所有特征来拟合随机森林回归模型,采用其中60%的样本做拟合,其余40%的样本做性能评估。示例代码如下:
X = df.iloc[:, :-1].values
y = df['MEDV'].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=1)
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor(n_estimators=1000,
criterion='mse',
random_state=1,
n_jobs=-1)
forest.fit(X_train, y_train)
y_train_pred = forest.predict(X_train)
y_test_pred = forest.predict(X_test)
print('MSE train: %.3f, test: %.3f' % (
mean_squared_error(y_train, y_train_pred),
mean_squared_error(y_test, y_test_pred)))
print('R^2 train: %.3f, test: %.3f' % (
r2_score(y_train, y_train_pred),
r2_score(y_test, y_test_pred)))

不幸的是,我们看到随机森林趋向于过拟合训练数据。然而,它仍然能够很好地解释目标变量和解释变量之间的关系(测试数据集 R 2 R^2 R2=0.878)
最后,让我们来看看预测残差:
plt.scatter(y_train_pred,
y_train_pred - y_train,
c='steelblue',
edgecolor='white',
marker='o',
s=35,
alpha=0.9,
label='training data')
plt.scatter(y_test_pred,
y_test_pred - y_test,
c='limegreen',
edgecolor='white',
marker='s',
s=35,
alpha=0.9,
label='test data')
plt.xlabel('Predicted values')
plt.ylabel('Residuals')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=-10, xmax=50, lw=2, color='black')
plt.xlim([-10, 50])
plt.tight_layout()
# plt.savefig('images/10_14.png', dpi=300)
plt.show()
正如 R 2 R^2 R2系数所总结的,如y轴方向上的异常值所示,我们可以看到该模型拟合训练数据要比拟合测试数据更好。此外,残差分布似乎并不是围绕零中心点完全随机,这表明该模型不能捕捉所有的探索性信息。然而,残差图比本章前面所述的线性模型残差图有了很大的改进,如图10-14所示
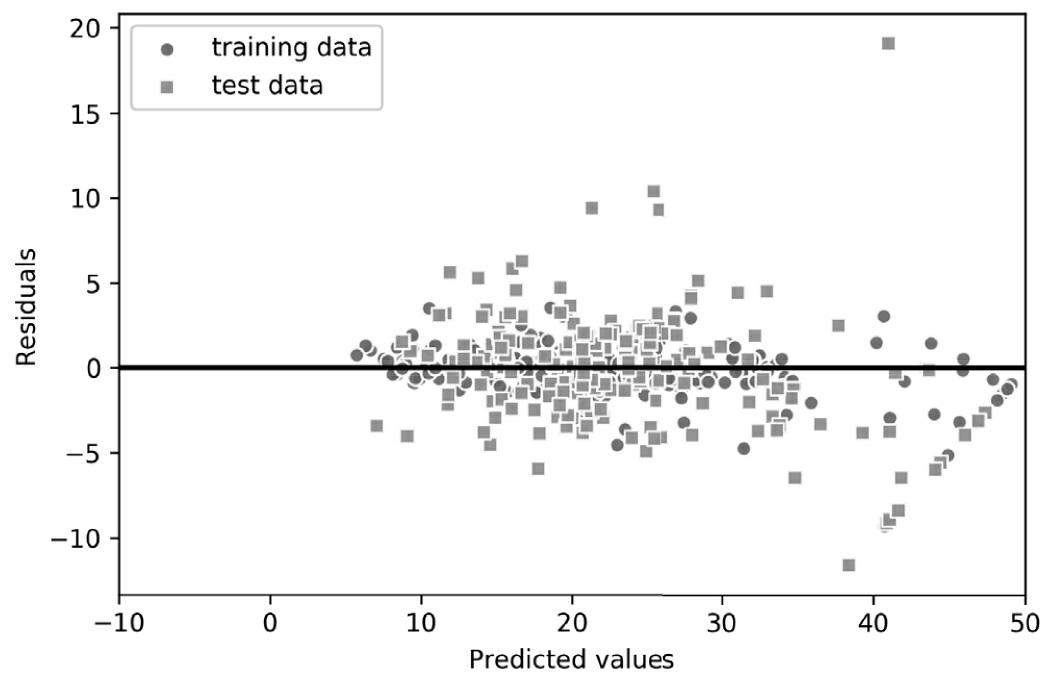
理想情况下的模型误差应该是随机或不可预测的。换言之,预测误差不应该与解释变量中所包含的任何信息有关,而应反映现实世界的分布或模式的随机性。如果通过检查残差图发现了预测误差中的模式,那就意味着残差图中包含着预测信息。一个常见原因可能是解释性信息泄露到了这些残差中。
幸好现在有处理残差图中非随机性的通用方法,不过这仍然需要试验。取决于能得到的数据,或许能通过转换变量、优化学习算法的超参数、选择更简单或更复杂的模型、除去异常值或者增加额外的变量来改善模型。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









