







 主要工作
主要工作
提出了一种新的用于人体动作识别的跨模态Transformer---CMF-Transformer,有效地融合了时空视频和骨架特征两种模态。在时空模态中,视频帧被用作输入,并且在Transformer中使用方向性注意来获得不同时空块之间的识别顺序。在骨架关节模态中,骨架关节被用作输入,通过Transformer中的时空交叉注意来探索不同骨架关节之间更完整的相关性。然后,采用多模态协同识别策略,分别识别两种模态下的特征和连通性特征,并对识别结果分别加权,融合两种模态下的特征,协同识别目标动作。
CMF-Transformer
由Transformer输出的用于两种模态的类别标记经历后续的共融合策略以获得最终的识别结果
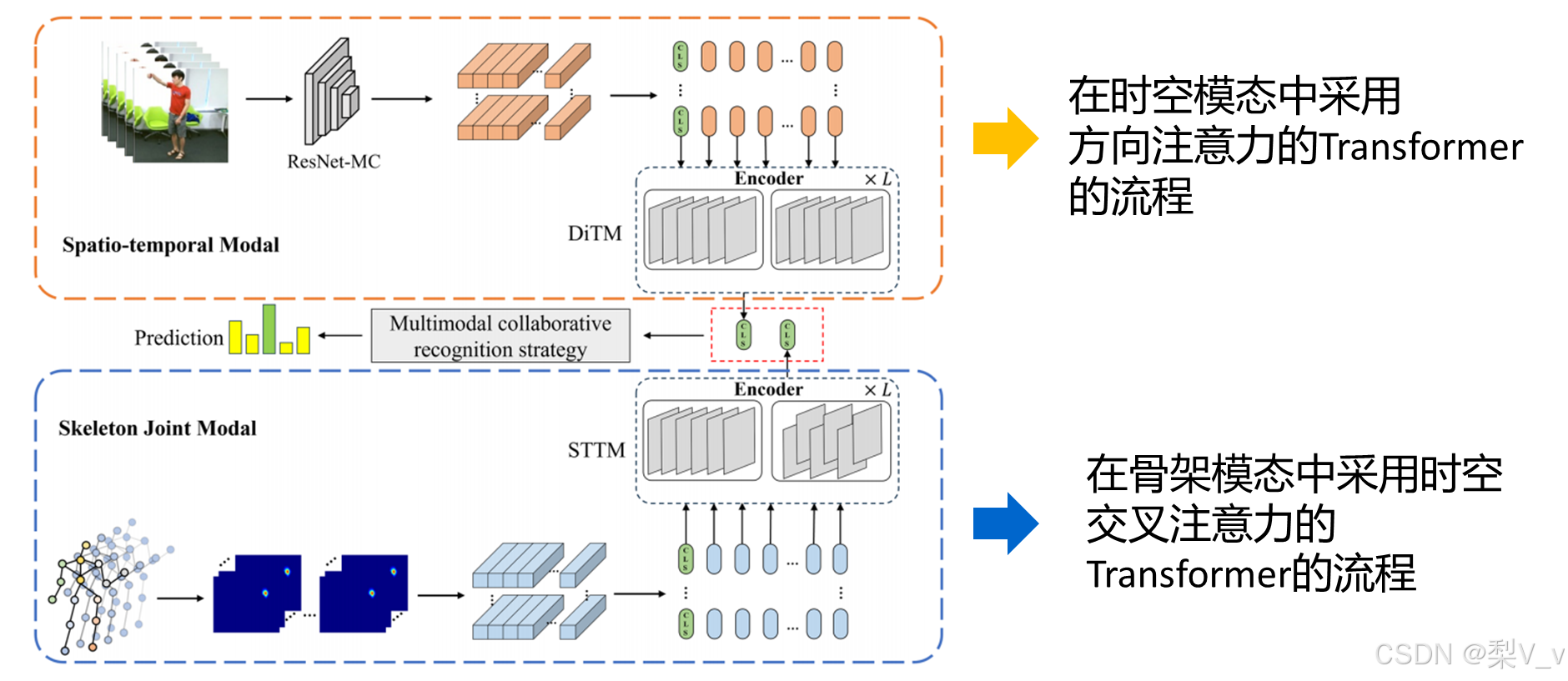
时空模型中具有方向性注意的Transformer
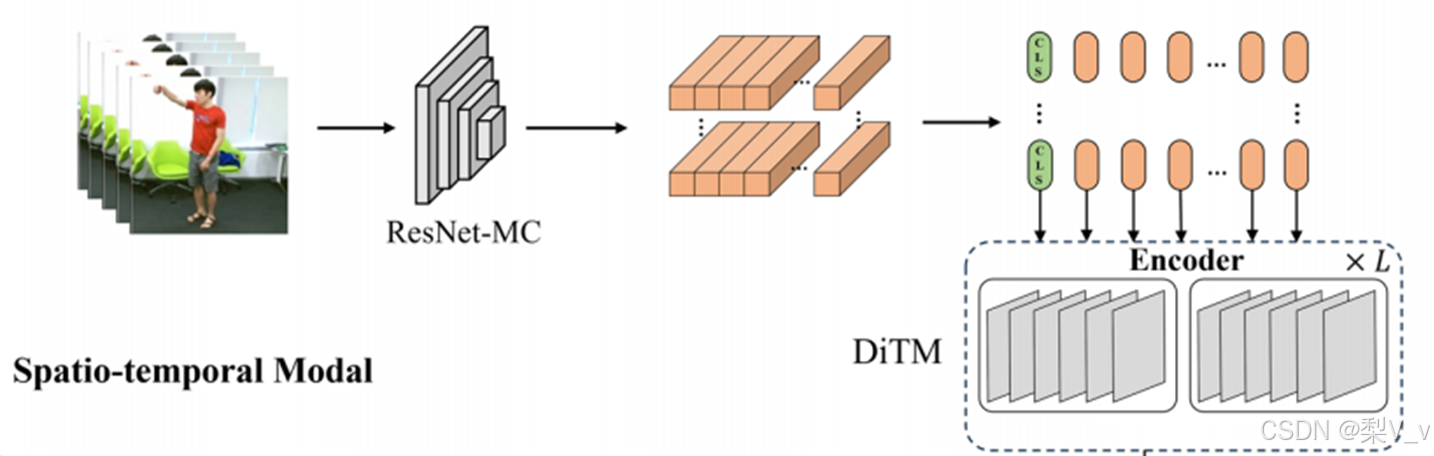 我们将输入视频的每帧的大小固定为224 × 224,随后由ResNet MC 18 生成全局特征图,将全局特征图扩展以获得向量序列输入到编码器获得时空特征。
我们将输入视频的每帧的大小固定为224 × 224,随后由ResNet MC 18 生成全局特征图,将全局特征图扩展以获得向量序列输入到编码器获得时空特征。
我们利用余弦相似性使用了一种新的方向性注意,分别将方向注意力嵌入到时间维度和空间维度中。
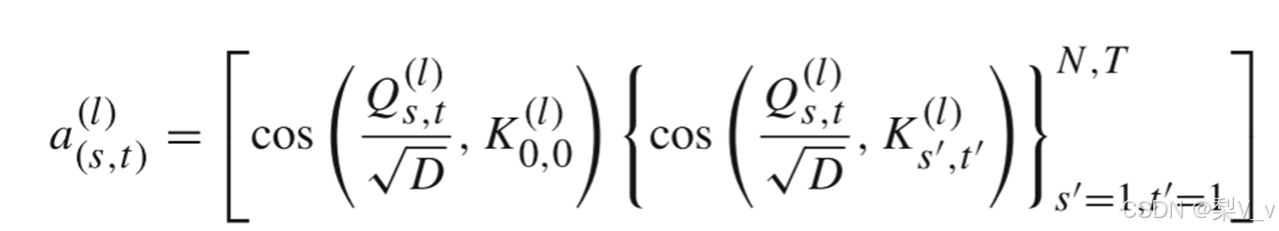
时空交叉注意并不关注时间维度T上的所有标记,而是选择性地关注一些标记。在该过程中,所有的令牌被划分为两个令牌组,利用上述两种时空交叉注意模型,我们分别提取了两个完全相反的锯齿形矩阵。

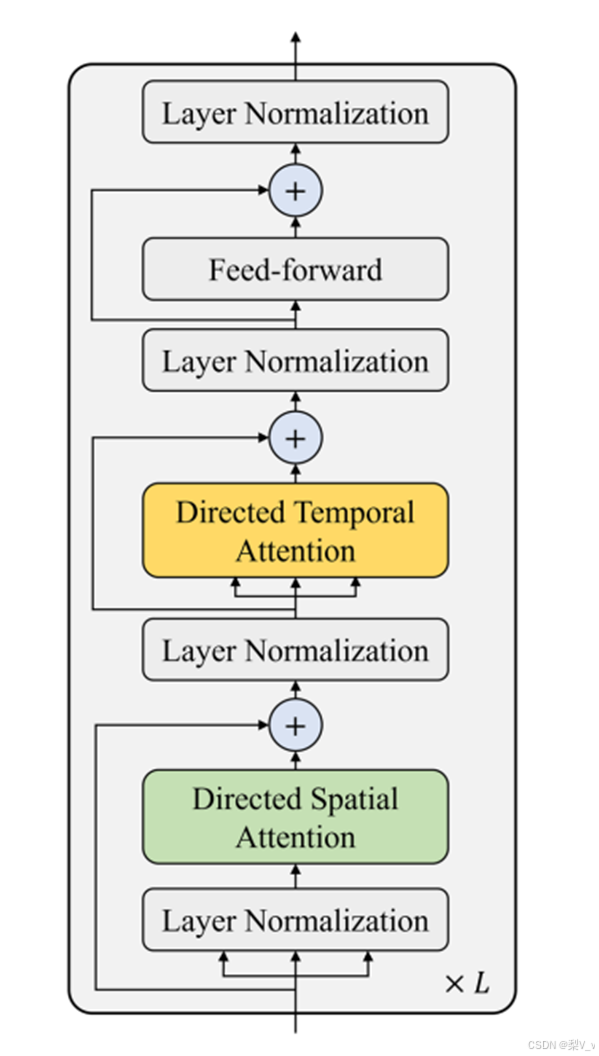
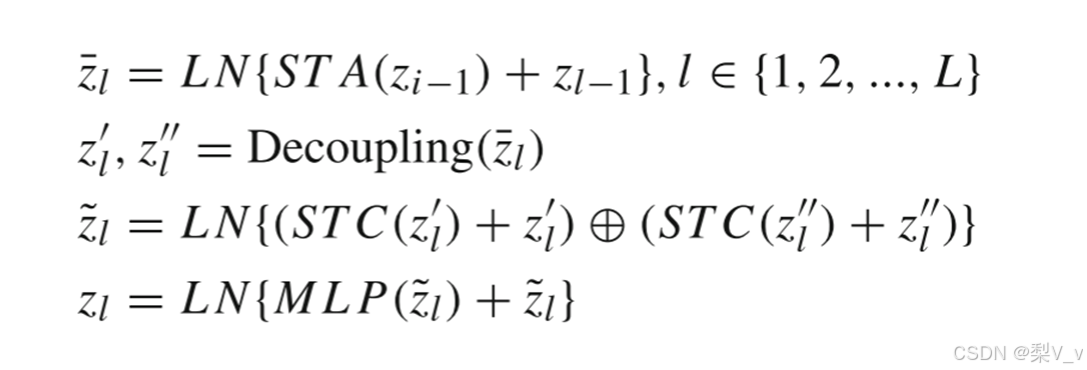 编码器由L层时空对齐注意(AttnSTA)和L层时空交叉注意(AttnSTC)组成,其中时空对齐注意AttnSTA用于关注特征之间的全局关系,而时空交叉注意AttnSTC更关注人类动作变化的更详细关系。
编码器由L层时空对齐注意(AttnSTA)和L层时空交叉注意(AttnSTC)组成,其中时空对齐注意AttnSTA用于关注特征之间的全局关系,而时空交叉注意AttnSTC更关注人类动作变化的更详细关系。
LN是层归一化,STA表示AttnSTA的多头自注意,STC表示AttnSTC的时空交叉注意。将骨架关节模型中各个帧对应的类标记组合成一个专用的类标记,作为该模型的最终特征表示。

多模态协同识别策略
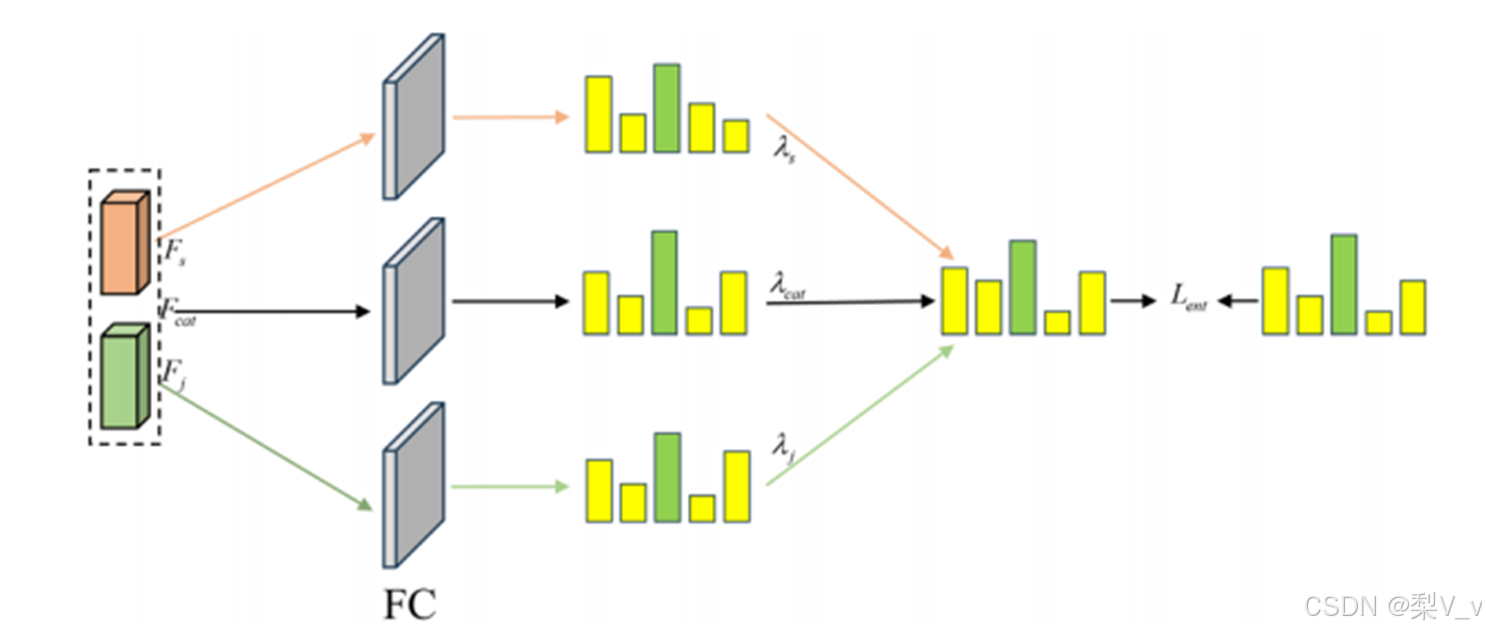
橙色模块表示时空模型中的特征,绿色模块表示骨骼关节模型中的特征,黑色虚线模块表示将两个特征连接后的融合特征。三个分支分别表示时空模态特征、骨架关节模态特征和融合特征的分类。
本文将两个模态的个体特征识别与连接特征识别融合,并对每个分支的识别赋予不同的权重,即通过全连接层对每个分支进行评分分类后,得到每个分支下的评分,分别记为Ss、Scat和Sj,将这三个来自不同分支的分类评分融合成一个矩阵:
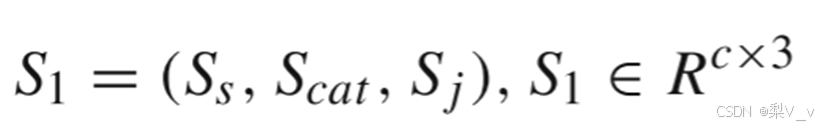
我们训练一个简单的线性层来学习和安排这三个得分向量的自适应权重矩阵Wλ:
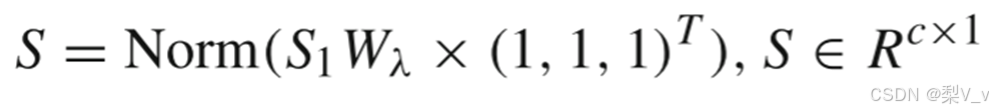
该过程是将融合得分S1与融合权重向量Wλ点乘,然后将它们按列相加并归一化,以获得最终分类得分S。
实验
数据集: NTU-RGB+D 60、 NTU-RGB+D 120.
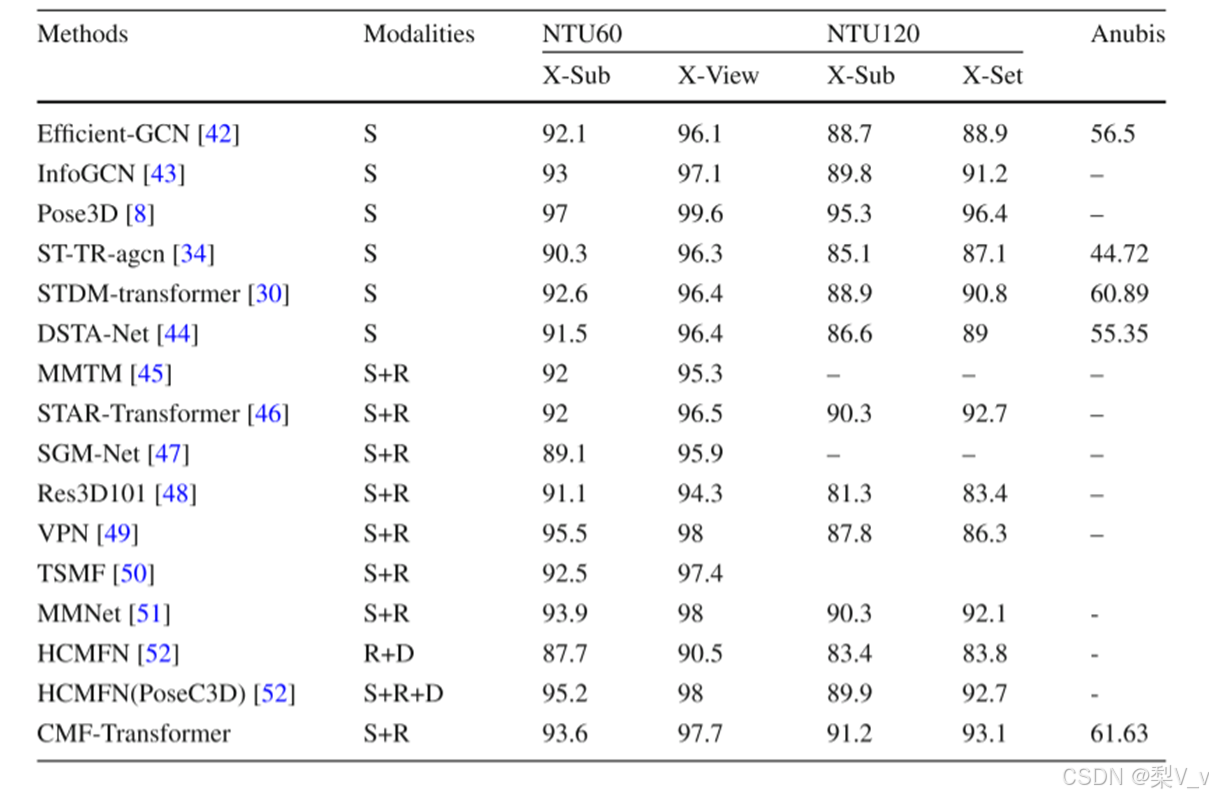
在三个基准数据集上与不同的最先进方法的性能比较。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









