







目的
统一人类运动表示学习:提出一种统一的框架,通过从大规模异构数据资源中学习人类运动表示,解决多种以人类为中心的视频任务,如三维姿态估计、动作识别和人体网格恢复。 多功能性与泛化能力:开发一种多功能的人类运动表示,能够适应不同的下游任务,并在不同任务中表现出色,同时具备良好的泛化能力。
摘要
提出了一种统一的视角,通过从大规模异构数据资源中学习人类运动表示来解决各种以人类为中心的视频任务。具体而言,我们提出了一个预训练阶段,其中运动编码器被训练以从嘈杂的部分二维观测中恢复底层三维运动。以这种方式获得的运动表示包含了关于人类运动的几何、运动学和物理知识,可以轻松地转移到多个下游任务中。我们使用双流时空变换器(DSTformer)神经网络实现运动编码器。它可以全面且自适应地捕获骨骼关节之间的长程时空关系,并且在从头开始训练时实现了迄今为止最低的三维姿态估计误差。此外,我们提出的框架仅通过微调预训练的运动编码器和一个简单的回归头(1-2层),就在所有三个下游任务上实现了最先进的性能,这证明了所学到的运动表示的多功能性。
研究方法
双流时空变换器(DSTformer):设计了一个双流时空变换器网络,能够全面且自适应地捕获骨骼关节之间的长程时空关系。
预训练与微调框架:采用两阶段框架,包括预训练阶段(从被破坏的二维骨骼序列中恢复三维运动)和微调阶段(针对具体任务进行调整)。
异构数据整合:利用大规模的三维动作捕捉数据和野外 RGB 视频数据,通过预训练任务学习通用的运动表示。
框架
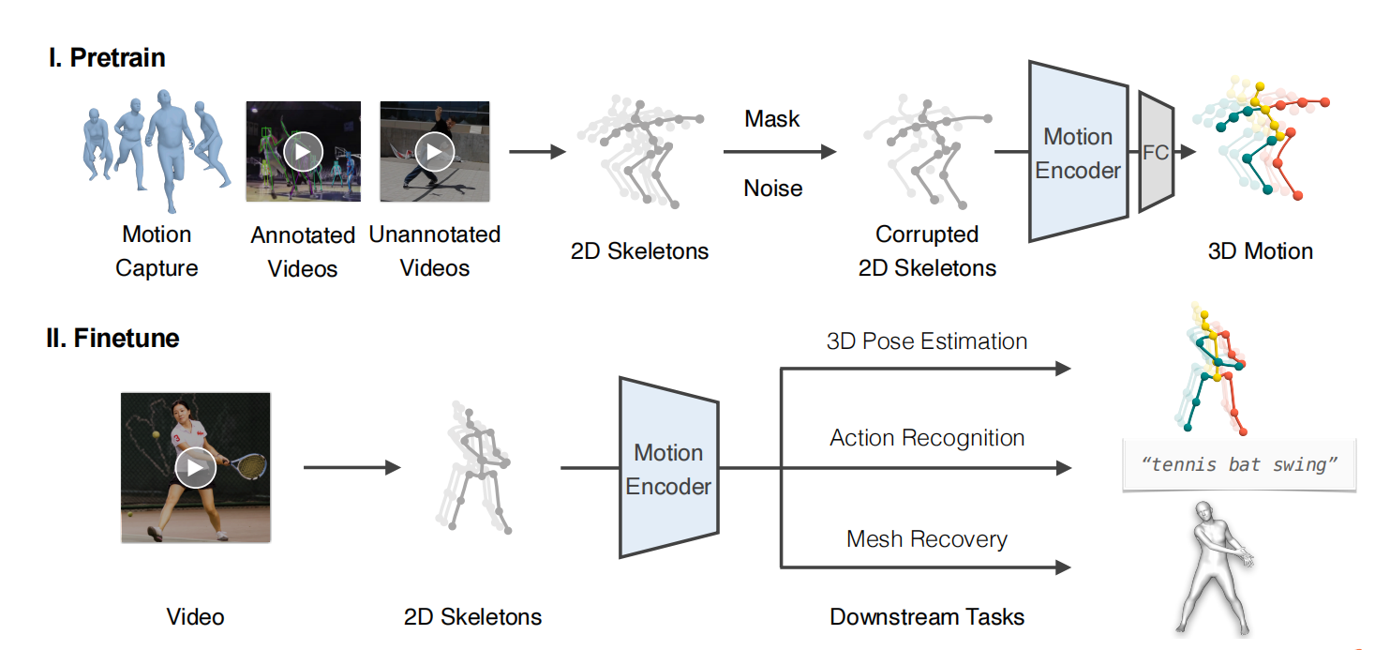
利用运动编码器通过从被破坏的二维骨骼序列中恢复三维人体运动来学习人类运动表示。为了适应不同的下游任务,我们使用线性层或简单的 MLP 对预训练的运动表示进行微调。
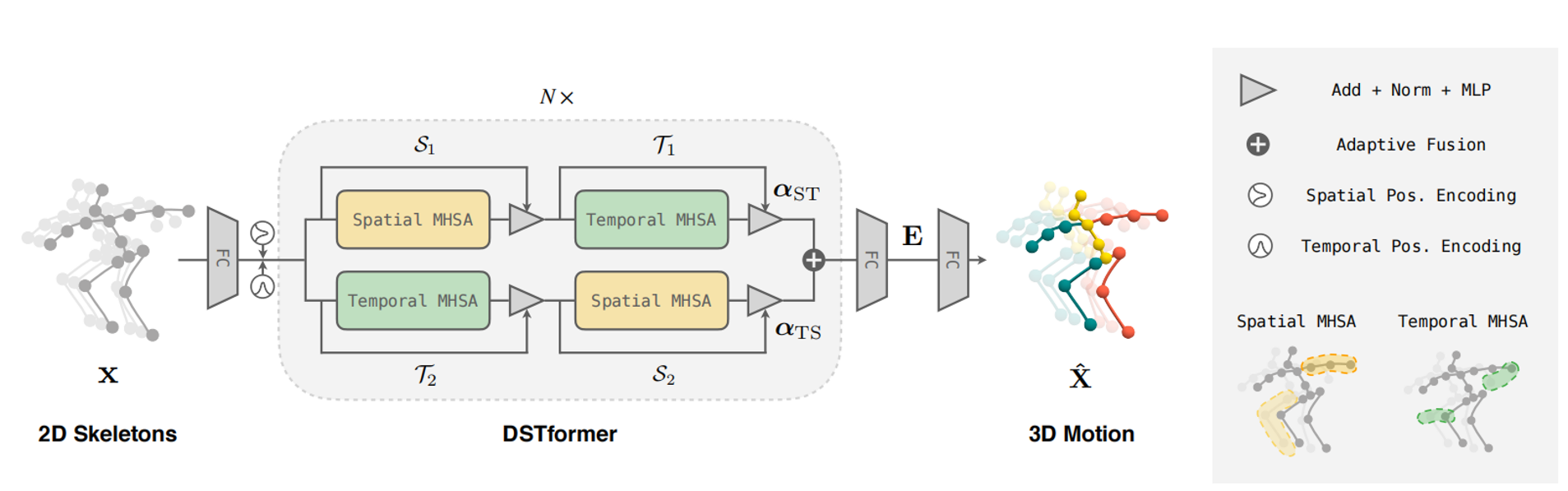
提出了双流时空变换器(DSTformer)作为人类运动建模的通用骨干网络。DSTformer 由 N 个双流融合模块组成。每个模块包含两个分支的空间或时间 MHSA 和 MLP。空间 MHSA 建模同一时间步内不同关节之间的连接,而时间 MHSA 建模一个关节的运动。
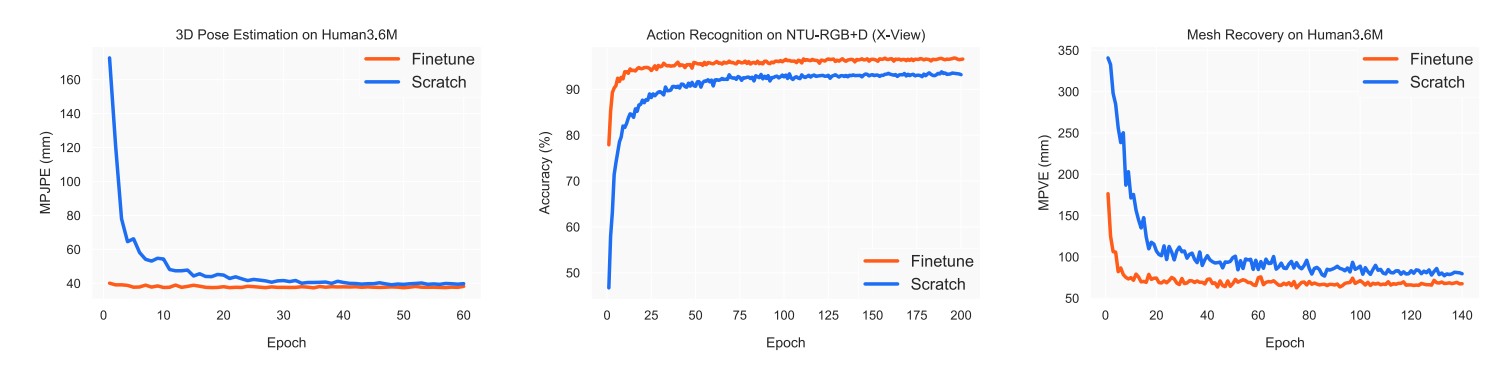
使用预训练权重初始化的模型与从头开始训练的模型在所有三个任务上的训练进度对比。预训练模型表现出优越的性能和更快的收敛速度。
实验结果
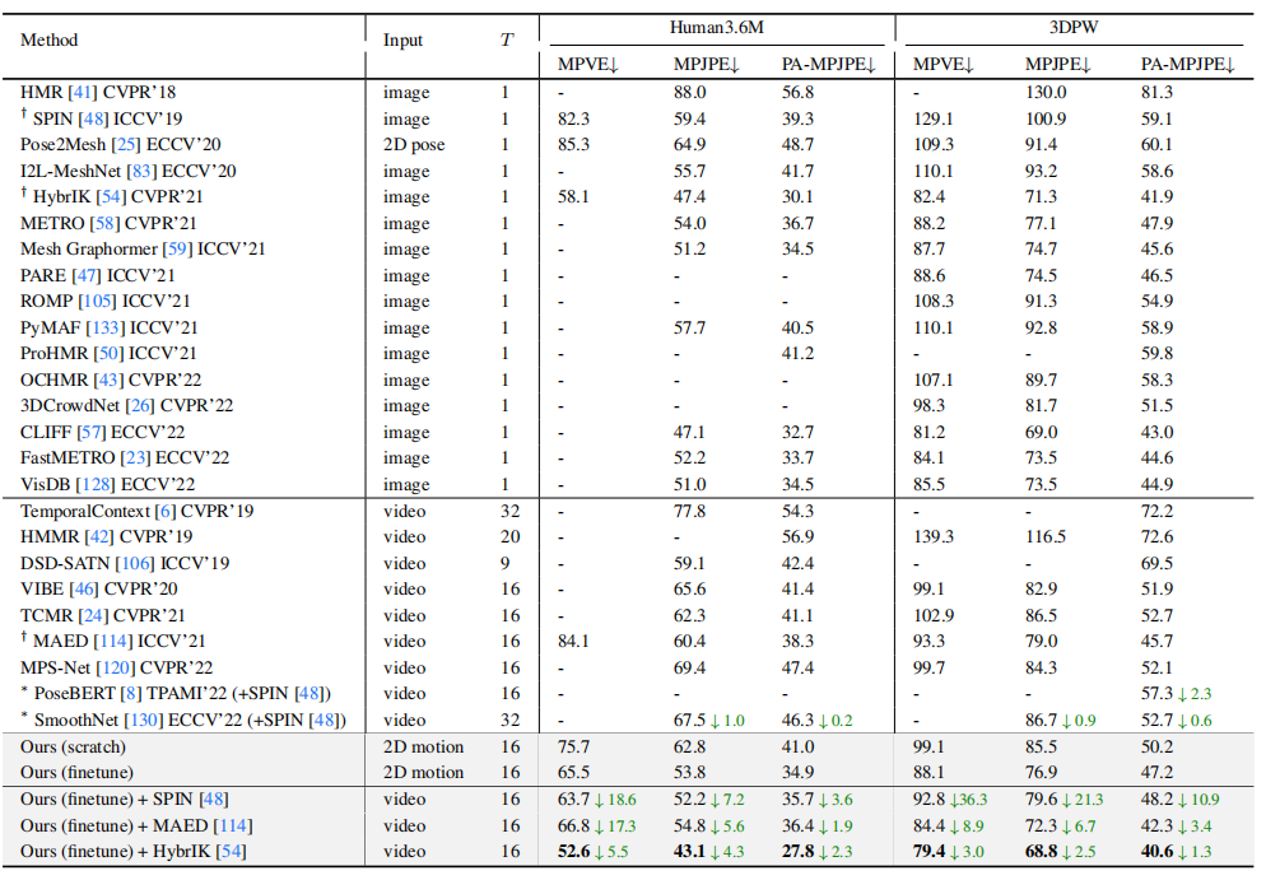
比较了在 Human3.6M 和 3DPW 数据集上的人体网格恢复性能,展示了所提出方法在 MPJPE、PA-MPJPE 和 MPVE 指标上的优势。
创新点
统一框架:提出了一个能够处理多种人类运动相关任务的统一框架,避免了为每个任务单独建模的复杂性。
多功能运动表示:通过预训练阶段学习到的运动表示能够适应多种下游任务,证明了其多功能性和泛化能力。
双流时空变换器:设计了一个双流时空变换器网络,能够更好地捕捉骨骼关节的时空关系,优于现有的单一流方法。
启发概述
跨任务学习:展示了如何通过预训练任务学习通用的特征表示,并将其应用于多个相关任务,为跨任务学习提供了新的思路。
异构数据利用:强调了整合不同类型数据资源的重要性,为处理大规模异构数据提供了有效的方法。
模型设计:双流时空变换器的设计为处理时空数据提供了新的视角,可以应用于其他需要建模时空关系的任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









