









在面试中,集合是大概率都会被问到的一个技术点,尤其是HashMap,无论你是应届生面试还是有个三五年的工作经验的,有工作经验的问的就会深一点,可能会被问到底层吧,不过小编就是个应届生而已,上次面试的时候就被问到底层了,呜呜呜呜呜呜呜呜。回到家,我百度查资料整理了一份关于HashMap的知识点。
Hash的底层结构是什么
回答:在jdk1.8之前,HashMap的底层数据结构是数组+链表,也称为哈希表。
jdk1.8以及1.8之后,HashMap的底层数据结构是数组+链表+红黑树,也称为哈希表。
你有看过HashMap的底层吗?了解其键值对的存储过程吗?
关于这个面试题,我真的很想吐槽一下,我一个应届生,就问我这个问题,害,当时觉得真的太难为我了吧。其实后来回到家想了想,其实也不是他们为难我,他们可能在用这个问题来衡量我学习能力的强弱吧。面试之前我是真的没有看过底层,当时我只能无奈都说没了解过,最后也没应聘上。后来我就开始借助一些视频来辅助我看底层。
首先可以先给大家看一个图,这个图不是我自己画的,是看视频的时候觉得挺不错的,就截下来了。
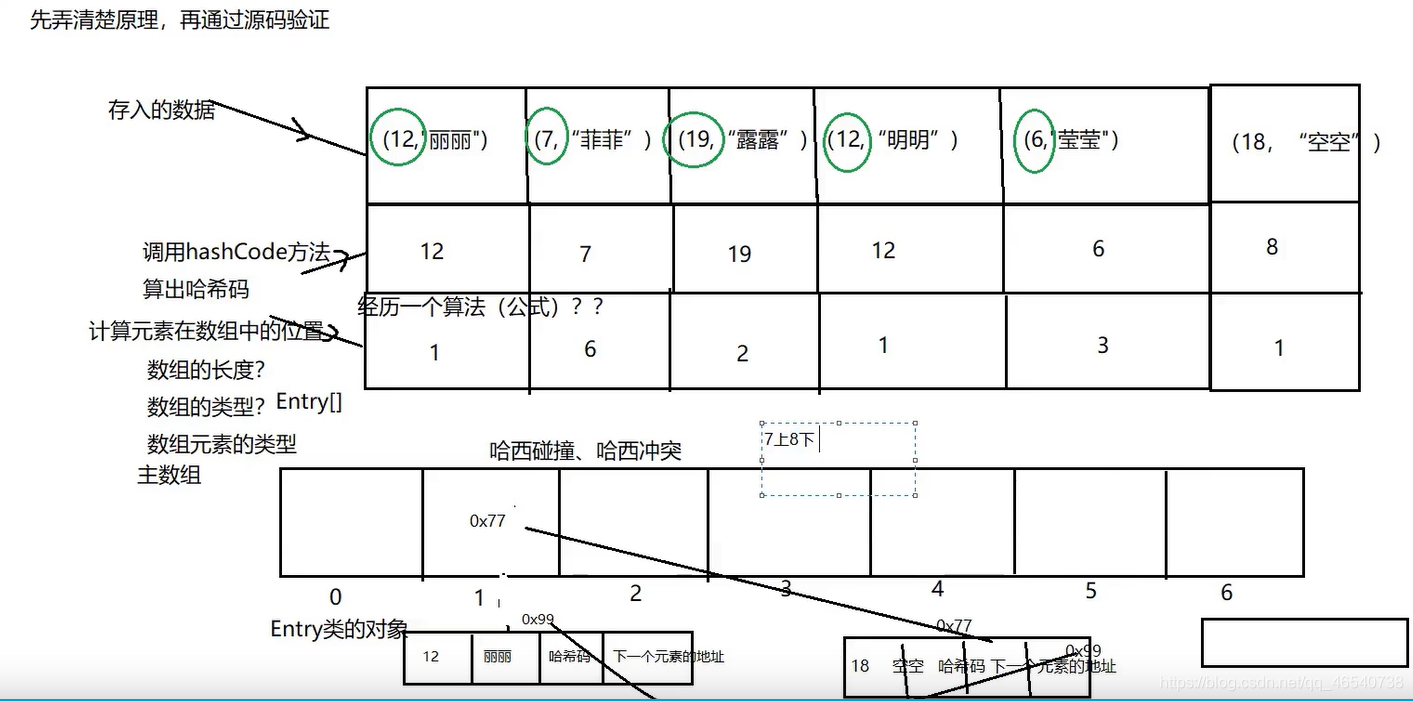
- 比如现在有一批数据需要插入到HashMap这个集合中,也就是上面那一批数据。要想往集合里插入数据,肯定得现new出一个集合,此时集合的构造器会为我们创建一个数组。因为jdk版本的不太,创建的数组类型也就不一样。
- jdk1.8之前构造方法会创造一个长度为16的Entry[] table数组,jdk1.8以及只有不再构造方法的时候创建数组,而是在第一次调用put方法的时候创建一个Node[] table数组,这点类似于ArrayList集合。
- 如下图所示,当要向HashMap中存入如下这些数据的时候,比如第一组数据“12,丽丽”的时候,首先会调用hash(key)方法计算出以key值为代表的对象的hashCode值,然后再根据某种算法,也就是方法indexFor(hash,length)(这个算法小编暂时也没搞明白,太难了)计算出k-value这个数据的哈希值,即这个数据在底层数组中的存储位置。如果计算出的哈希值对应的数组的索引地址刚好没有储存数据的话,就会直接将当前这个数据存储进去。比如:“12,丽丽”计算的哈希值是1,那么如果数组索引为1的位置没有储存数据的话,就会直接把丽丽这个数据存储进去。后面数据的存储方式就以此类推。
- 如果要插入的数据计算出的哈希值刚好与之前的某一个相同了,就比如下图中举的例子“12,明明”,刚好计算出的哈希值也是1,这样的话就与前面丽丽的一样了,这种情况我们称为哈希碰撞,也是哈希冲突。后面的“明明”的值就会替换掉“丽丽”的值,但是key值并没有替换,还是“丽丽”的key12。
- 如果,有一组要插入的数据“18,空空”,根据key计算的hashcode比如是8,但是呢,然后经过某种算法之后计算出的哈希值依旧是1,也就是存储在数组中索引的位置。由于空空计算出的哈希值也是1,那么就会与之前的丽丽、明明发生哈希碰撞,但是他们的key通过hashcode()方法计算出的hashcode不一样,也就不能替换,会在“明明”的前或者后面的位置重新创建一个位置,这样就会形成一种单链表。到底是在原来数据的前面位置插入还是后面插入,HashMap会采用“7上8下的原则”,也就是说,jdk版本是1.7以及之前的话,就会选择在前面插入从而形成链表,jdk1.8之后的话,就会选择在后面插入从而形成链表。这也对应了HashMap的底层为什么是数组+链表的原理了。
上面说了那么多,其实总结HashMap的存储过程就一句话:HashMap内部维护了一个存储数据的Entry[]或者Node[]数组,采用链表来解决哈希冲突,每一个Entry或者Node节点其实都是一个单向链表。
HashMap与HashTable的区别?
- 线程安全不同。HashMap是非线程安全的,而HashTable是线程安全的。
- 继承的父类不同。HashMap继承AbstractMap类,HashTable继承Dictionary类,但是它们都实现了Map接口。
- 是否允许为空。HashMap的key和value都可以为空的,而HashTable的k-value都不能为空的,否则报空指针异常。
- 计算hash值的方式不同。
- 扩容的方式不同。HashMap扩容的话必须要求为原容量的2倍,而且每次扩容必须得是2的幂次方的倍数扩容,扩容之后,原数组的数据还得依次计算哈希值来确定存放的位置,重新插入。而HashTable扩容是原来容量的2倍+1。
HashMap的key可以为空吗?
回答:可以,但是依旧遵循“key唯一”这一规则。
HashMap底层的理解
1,HashMap继承的父类AbstractMap已经实现类Map接口,可是HashMap集合自己又实现了一次Map接口,重复操作, 集合的创始人也承认这是一个多余的操作。
2,HashMap底层的一些重要属性:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 这是要赋值给数组的长度
static final int MAXIMUM_CAPACITY = 1 << 30; //定义了一个很大很大的数
static final float DEFAULT_LOAD_FACTOR = 0.75f; //定义了一个浮点类型数值:0.75,也称负载因子,加载因子
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //底层主数组
transient int size; //数组中实际添加的数量
int threshold; //定义了一个变量,没赋值,默认为0。表示底层数组扩容时的界限值,边界
final float loadFactor; //用来操作、接收加载因子
*
HashMap负载因子、加载因子、装填因子为什么是0.75?
回答:
如果装填因子设置大的话为1:空间利用率得到了很大的满足,但是呢,容易发生碰撞,产生链表,从而大致查询效率低。
如果装填因子设置小的话为0.5:碰撞率低,不容易产生链表,查询效率高,但是空间利用率减低了
所以负载因子就取了一个中间值,在空间和时间上一个折中。
主数组的长度为什么是2^n幂?
回答:
原因1:h & (length-1) 等效 h%length的操作 等效的前提就是:length的长度必须是2的整数倍。
原因2:防止哈希值冲突,位置冲突。
















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











