







摘要
Open-Domain Question answering(ODQA)要求模型在没有给定上下文的情况下回答虚假问题。该任务的常用方法是在大规模带注释的数据集上训练模型以检索相关文档并基于这些文档生成答案。本文通过将大型语言模型(Large Language Models, LLMs)视为知识语料库,大大简化了ODQA体系结构,并提出了LLMs执行ODQA的self - prompt框架,从而消除了对训练数据和外部知识语料库的需求。具体来说,我们首先通过逐步提示LLMs,生成多个带有背景段落和对这些问答的一句话解释的伪QA对,然后利用生成的QA对进行上下文学习。实验结果表明,我们的方法在三个广泛使用的ODQA数据集上优于现有的最先进的方法,平均增加8.8 EM,甚至在几个检索增强微调模型上也达到了相当的性能。
1.简介
Open-Domain Question answer(ODQA)是自然语言处理中一项长期存在的任务,其目的是在没有给定上下文的情况下,回答有关广泛世界知识的问题(Voorhees et al., 1999;Huang et al., 2020;Zhu et al., 2021;Zhang et al., 2022a)。无法访问大量外部知识语料库,即使对于人类来说,这也是一项挑战。现在最常见和事实上的ODQA方法是检索器-阅读器管道(Chen等人,2017):首先检索与问题最相关的文档,然后应用reader model提取或生成以这些文档为条件的最终答案(Karpukhin等人,2020;Lewis et al., 2020;伊扎卡德和格雷夫,2021)。尽管表现不错,但这些方法常常需要索引整个维基百科,导致了巨大的储存成本,而且pipeline也相当复杂。
随着GPT3 (Brown et al., 2020)、FLAN (Wei et al., 2022a)、OPT (Zhang et al., 2022b)、InstructGPT (Ouyang et al., 2022)等大型语言模型(LLMs)的出现,一些搜索者开始将它们用于ODQA任务。通过大规模的无监督预训练,LLMs已经在其参数中存储了足够的知识来回答大多数open-domain问题,并且可以在给定简单的自然语言查询时精确地召回它们。从理论上讲,它们能够在没有任何训练数据和外部语料库的情况下生成正确的答案,但在实践中,LLMs与完全微调的模型之间仍然存在明显的差距。为了激发他们更多的潜力,在之前的工作中已经做了一些尝试,比如鼓励模型在最终答案之前产生一个称为chain-of-thought的基本原理(Wei et al., 2022b;Kojima等人,2022),或者要求模型首先生成上下文文档,并在第二次向前传递中基于它回答问题(Yu等人,2022)。但是,这些方法只使用了LLMs功能的一小部分,并且没有充分利用可能对ODQA有帮助的大量其他技能。
在本文中,我们关注的场景是没有训练数据和外部语料库的ODQA,我们提出了self - prompt LLM,显式激活LLMs的各种不同能力,并将这些能力组合起来,进一步探索性能的上限。在准备阶段,需要LLM生成一个伪QA数据集,具体步骤如下:编写一篇维基百科短文,提取该短文中的命名实体作为答案,对答案提出相应的问题,并根据短文用短句解释生成的每个QA对。依靠LLMs强大的指令理解能力,所有这些子任务都可以在简单的自然语言提示下完美完成。我们可以通过重复这些步骤自动构建一个伪数据集,其中每个item都是一个高质量的QA对,带有相关的上下文段落和一个简短的句子来解释它。在推理过程中,我们提出了一种新的基于聚类的检索方法,从该伪数据集中选择相似和不同的示例作为每个测试样本的上下文演示。这些选定的QA对,以及段落和解释,以特定的顺序与测试问题连接起来,形成最终的输入序列,然后将其输入LLM以获得最终答案。
我们在三个ODQA基准上评估了我们的方法,包括WebQ (Berant等人,2013)、NQ (Kwiatkowski等人,2019)和TriviaQA (Joshi等人,2017)。实验结果表明,我们的方法明显超过了普通的zero-shot基线(平均+16 EM),也超过了以前的SOTA方法GENREAD (Yu et al., 2022)(平均+9 EM)。我们还进行了广泛的消融研究、案例研究和分析,以讨论不同生成组件的效果、将它们放入序列的格式、从伪数据集中选择演示的方式、生成的QA的质量以及我们框架的许多其他方面。
总的来说,我们的贡献可以概括如下:
1.我们提出了self - prompt,将LLMs的多种功能综合起来,实现zero-shot ODQA。它能够提前自动构建一个伪但高质量且带注释的ODQA数据集,并以上下文学习的方式使用它。
2.我们提出了一种基于聚类的检索方法,以有效地利用构建的伪数据集为每个测试样本选择语义相似和不同的示例。
3.我们进行了大量的实验来证明self-prompting在三个ODQA任务上的有效性。它在zeroo-shot设置下优于以前的SOTA,并且可以与几个微调的检索阅读器模型相媲美。
2.相关工作
Retriever-Reader Models for ODQA:处理ODQA任务的主流方法是Retriever-Reader结构。它首先利用检索器在像Wikipedia这样的大型知识语料库上选择可能包含答案的几个相关文档,然后使用阅读器处理检索到的文档并预测最终答案。传统模型使用TF-IDF或BM25等稀疏检索方法,而最近的研究选择基于预训练语言模型编码的表示向量的密集检索(Karpukhin et al., 2020;Lewis et al., 2020;Guu et al., 2020;伊扎卡德和格雷夫,2021)。至于Reader,也有两种不同的选择:抽取Reader,如BERT (Devlin等人,2019)或生成Reader,如T5 (rafael等人,2020)。在这个分支中有一个类似的工作是PAQ (Lewis et al., 2021),它首先基于维基百科的完整转储生成了6500万个可能被问到的问题,并直接检索这些问题而不是文档。
LLM and In-context Learning:通常,大型语言模型(Large Language Models, llm)是指具有数百亿或数千亿参数的预训练模型。一些突出的例子是GPT3、FLAN、PaLM、OPT和InstructGPT (Brown et al., 2020;魏等人,2022a;Chowdhery et al., 2022;张等,2022b;欧阳等人,2022)。这些模型通过大规模无监督学习进行训练,并且能够通过将输入转换为自然语言查询来执行NLP任务,而无需进一步训练。对这些模型进行微调的成本是非常巨大的,所以通常使用它们的方法是上下文学习,即在测试样本前放置一些输入输出对作为演示。之前的一些工作研究了校准(Zhao et al., 2021)、样本选择(Liu et al., 2022a;Rubin et al., 2022)和排序(Lu et al., 2022b)的上下文学习,而据我们所知,我们是第一个使用LLM本身来生成上下文学习中使用的示例的人。
Enhancing Models with LLM generation:最近的一系列研究旨在利用LLMs的生成输出来促进小模型的训练。例如,Ye等人(2022)使用GPT2 (Radford等人,2019)生成伪数据来训练微小的语言模型,Wang等人(2022)将GPT3的知识提取到GPT2中用于常识性问答。另一行工作尝试直接使用LLM本身生成的内容。一些工作使用LLMs首先生成相关的上下文或背景文件,然后在回答问题时将其作为额外的输入提供(Liu et al.,2022b;Yu et al.,2022),而另一些作品则专注于引出一系列被称为算术问题思维链的中间推理步骤(Wei et al.。2022b;小岛等人,2022;Zhang等人,2022c)。
3.方法
我们将在本节中介绍自我提示的详细信息。它可以分为准备和推理两个阶段。在第一阶段,我们要求LLM通过提示它生成带有上下文段落和解释的QA对来自动构建一个伪ODQA数据集。在第二阶段,我们通过基于聚类的检索方法动态地从pool中选择几个例子作为上下文演示,以帮助理解和回答给定的问题。总体框架如图1所示。
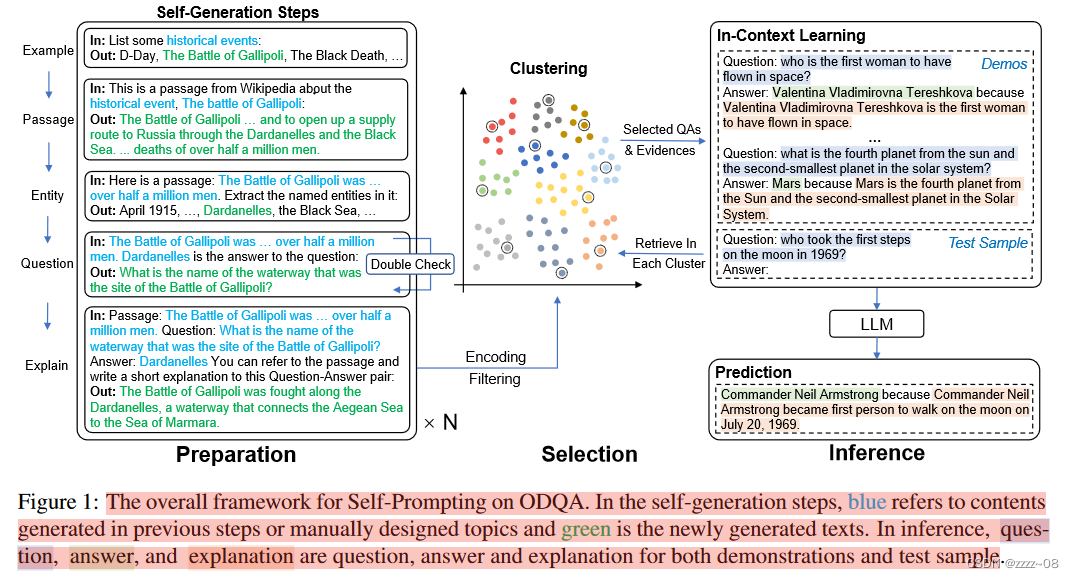
3.1 QA Pool Generation
作为提前准备,我们首先要求LLM自动生成QA池作为伪数据集。它遵循以下步骤:
Passage Generation:为了确保生成段落的多样性,我们首先参考TriviaQA中的数据集统计,手动设计一些可能出现在ODQA中的主题(如国家、书籍、旅游景点等)(Joshi et al., 2017)。对于每个主题,要求LLM列出一些示例,并使用类似于“list some {topic}:”的指令,重复这一步骤,直到我们为该主题收集了一定数量的不同示例。通过这种方式,我们获得了涵盖不同类别的大量示例,并利用它们生成简短的维基式段落,提示符如下:“This is a passage from Wikipedia about the {topic}, {example}:”。
Named Entity Recognition:我们提取这些生成的段落中的命名实体作为候选答案。通常,这个NER步骤是由一个微调的小模型进行的。在我们的框架中,这也是由LLM本身完成的。对于给定的生成通道,提示符可能是“Here is a passage: {passage} Extract the named entities in it:”,我们可以获得该通道中的实体。
Question Generation:在前一步中提取的命名实体(如日期、名称、位置)用作候选答案。然后,我们要求LLM根据给定的段落为这个答案输出一个合适的问题,并提示“{passage} {entity} is the answer to the question:”。为了保证QA对的正确性,我们要求LLM做一次复核,即根据文章重新回答问题,看是否可以恢复实体。在实践中,我们观察到新预测与原始实体之间的冲突通常是由于无法生成相关问题引起的,而相反,新预测通常与问题匹配得很好。所以我们把新的预测作为最终答案。
Explain the QA pair:对于每一对QA,我们要求LLM根据文章返回一段一句话的解释。提示是这样的:“Passage: {passage} Question: {question} Answer: {answer} You can refer to the passage and write a short explanation to this Question-Answer pair:”。在这一步中,我们试图引出LLM的总结和归纳技能,为生成的QA对提供细粒度的注释。
3.2 Dynamic In-context Demonstrations Selection for Inference(动态上下文演示选择推理)
如何使用LLM在准备阶段生成的伪QA数据集是一个悬而未决的问题。我们注重两个方面,即选择和格式。
Clustering-based Retrieval(基于聚类的检索):一些先前的研究指出,使用语义相似度高的示例作为上下文演示会带来好处(Liu et al., 2022a),而另一些研究则认为基于聚类的固定示例集更好(Zhang et al., 2022c)。我们建议把这两种方法结合起来。首先,使用Sentence-BERT将每个QA对编码为整个QA池的向量表示(Reimers和Gurevych, 2019)。假设上下文演示需要k个示例,则通过k-means算法将伪QAs聚类到k个类别中。对于给定的问题,我们也使用Sentence-BERT对其进行编码,并以简单的余弦相似度从每个聚类中检索最相似的示例。这种选择方法兼顾了论证的相似性和多样性。
Answer then Explain:最后是所选例题的组织格式。在输入序列中,我们首先按照Question→Answer→Explanation的格式将这些示例按顺序排列,并将测试问题放在序列的最后。具体模板见附录。通过这样做,LLM能够查看更多的信息,而不是仅仅切换到QA模式,它也可以给出一个简短的解释,它的答案。这与思维链提示的常见做法截然不同,即在答案之前产生一个基本原理,但我们的实验证明了前一种选择的有效性。
4.实验
4.1数据集和设置
在本文中,我们在三个ODQA基准上进行了实验,包括WebQ (Berant等人,2013),NQ (Kwiatkowski等人,2019)和TriviaQA (Joshi等人,2017)。数据集统计信息如表1所示。

我们使用InstructGPT (Ouyang et al., 2022) (GPT3 (Brown et al., 2020)的text-davinci-002)作为LLM,与之前的作品(Wei et al., 2022b;小岛等人,2022;Yu等人,2022)。我们用作SentenceBERT的确切模型是all-mpnet-base-v2,上下文学习的演示次数是10次。
在文章生成中,我们提前设计了29个主题。每个主题所需示例的名称和数量见附录。在问题生成中,我们通过在API调用中将它们的logit_bias设置为-100来禁止像they, he, shei这样的代词,以防止得到模棱两可的问题(例如,what did he do In 1997?)在生成过程之后,我们过滤答案超过5个单词或LLM输出一个没有答案跨度的解释句的QA对。对于每篇文章,生成QA对的上限为10。在过滤重复问题后,我们收集了1,216篇文章和4,883对带有解释的QA对。每个步骤中用于LLM生成的max_tokens或temperature等参数见附录。我们评估的指标是精确匹配(EM),与Karpukhin等人(2020)的答案归一化相同。我们还观察到,在WebQ中,如果正确答案包含多个列出的实体,则引用通常仅作为其中一个给出,因此我们对该数据集执行额外的后处理,以便在LLM预测多个实体时仅提取第一个实体(例如,如果原始预测是A, B和C,则仅返回A)。我们选择的基线包括直接提示:InstructGPT(Ouyang et al.,2022)、GENREAD(Yu et al.,2021);检索增强LLM提示:DPR+InstructGPT,Google+Instruct GPT;无检索的微调模型:T5-SSM 11B(Roberts等人,2020);检索增强细化模型:REALM(Guu等人,2020)、DPR(Karpukhin等人,2020。
4.2 主要结果
主要结果如表2所示。与直接提示方法相比,我们的self - prompt方法平均超过InstructGPT基线+15.5 EM,之前的SOTA方法GENREAD平均超过+8.8 EM。这强烈表明,首先生成高质量、带注释的伪数据集并将其用于上下文学习的方式可以全面调用LLM在不同方面的能力,相对于直接使用LLM提示的简单粗暴的方式有了显著的改进。自提示也优于检索增强提示方法,这表明LLM本身在其参数中已经存储了足够的世界知识,因此不需要显式地收集大量的外部语料库进行检索。
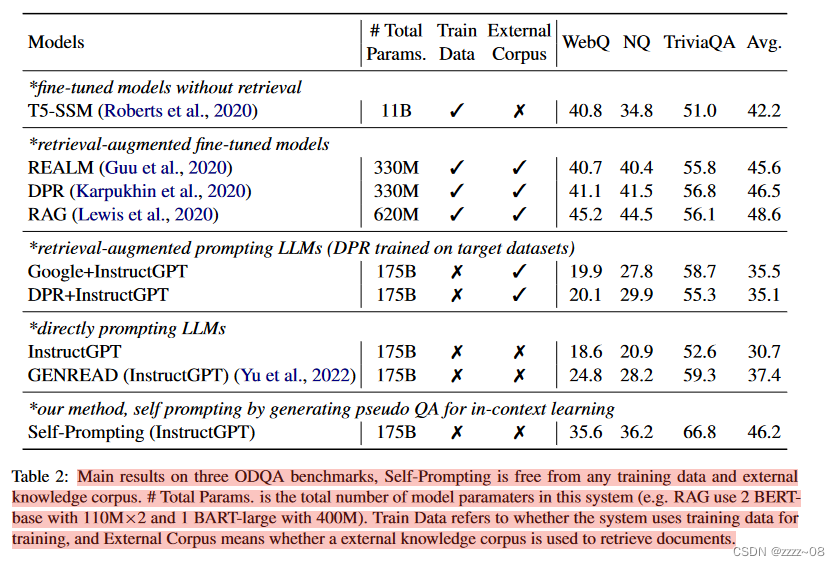
我们注意到,除了WebQ之外,self - prompt在两个数据集上的EM比T5-SSM 11B更高,尽管我们没有给InstructGPT提供任何训练数据,这表明LLM在零射击设置下的ODQA潜力很大。最后,我们发现self - prompt在三个数据集上的平均得分与一些强大的检索增强微调模型相当,特别是在TriviaQA上,我们看到超过10个EM。在WebQ和NQ上,self - prompt落后于这些方法,但我们发现这主要是由于这两个数据集的特征,如每个问题的参考答案较少或过时的答案。我们将在案例分析部分详细介绍这种现象。
5.分析
为了节省使用OpenAI API的成本,我们对这三个数据集的子集进行了多次消融研究,从它们的测试集中随机选择1000个样本。
5.1如何使用生成的文章和解释
一个关键的问题是如何使用副产品,即段落和解释,形成更好的情境学习模式。给定一个包含10个演示(Q, A, P, E)× 10的列表(通过基于聚类的检索),我们研究了几种输入格式,如表3所示。一个迭代方法意味着只需要调用一次API来生成答案和段落/解释,而在两个迭代方法中,LLM需要先生成段落/解释,然后将它们放入输入序列中,在第二次API调用中生成答案。这些方法的详细模板见附录。从表3中我们可以看到,最简单的QA格式足以输出良好的性能,只有QAE能够超越它。其他三种问答格式QAP、QAEP、QAPE比QA差,说明段落中的冗余信息对LLMs有害。我们还发现,两种思维链格式,QEA和QPA,比基线差得多。Lu等人(2022a)和Wei等人(2022b)得出了类似的结论,即思维链有利于复杂的多跳数学推理任务,但对常识性问题影响不大。最后,两种迭代方法也会导致较大的性能下降,考虑到加倍的推理时间和成本,这使它们成为最差的设置。

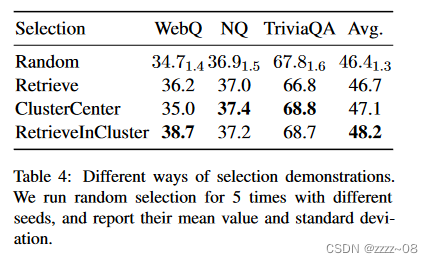
5.2示范选择方式
由于LLM自动生成的伪QA数据集的大小远大于我们在上下文学习的输入序列中放入的示例数量,因此需要适当的选择方法。我们用四种设置进行实验:从Pool中随机选择QA(Random),全局检索具有余弦相似性的最相似的QA(Retrieve),在每个集群中选择最接近质心的QA(ClusterCenter),以及在每个集群(RetrieveInCluster)中检索最相似的QA。其他超参数保持不变,即10个演示和QAE格式。表4的结果表明,随机选择的性能最差,并且存在不稳定性。Retrieve和ClusterCenter方法都比Random有一些改进,但是在这三种数据集上的改进并不普遍。我们提出的方法RetrieveInCluster可以结合两种方法的优点来选择不同和语义相似的演示,因此它足够鲁棒,可以在所有数据集中获得令人满意的分数。
5.3 不同数量的Demonstrations
上下文学习的一个自然想法是在输入序列中放入尽可能多的例子,因此我们还研究了不同数量的演示的影响,如图2中的绿线所示。我们报告了三个数据集的平均EM得分,其中{2,4,…,14,16}中的Demonstrations次数。当数量在2-10时,我们的方法的性能通常会随着数量的增加而变得更好,并且使用10个以上的例子并不能带来显著的改进。因此,出于性能和成本的考虑,我们在主要实验中选择了10个演示。
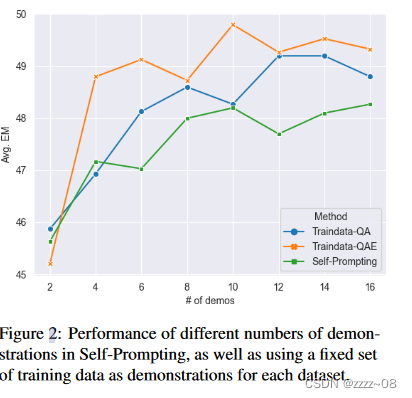
5.4 自我提示与使用训练数据的比较
为了评估由LLM生成的伪数据集的质量,我们从他们的训练集中随机选择一组样本进行上下文学习,并用相关的Wiki段落和简短的解释句子注释它们,就像在self - prompt中自动完成的那样。根据第5.3节,我们报告了3个子集的平均EM分数,其中有2 - 16个演示,并尝试了QA和QAE格式。图2中的结果显示,我们的self - prompt方法的性能与使用手动注释的训练数据相当。与Traindata-QA相比,self - prompt在不同数量的演示中只比它低约1 EM,这表明LLM本身足够强大,即使没有任何训练数据,也可以通过细粒度和分步指导来解决ODQA。我们还观察到从Traindata QA到Traindata QAE的稳定提升,表明QAE格式不仅对LLM构建的伪数据有效,而且对真实的训练数据也有效。
5.5数据生成质量分析
为了进一步探索LLM生成的伪数据集的质量,我们选择了三个示例,并将它们作为案例研究放在表5中,其中段落中的关键句子用蓝色突出显示,回答实体用蓝色突出显示。总的来说,这些生成的段落是准确的,但它们仍然包含一些事实错误,或幻觉(Ji et al., 2022),在文本中(用红色突出显示)。为抽取实体生成的问题包括不同的类型(例如,人、项目、位置)。即使在没有上下文的情况下,这些问题也是适当的和可回答的,这符合常见的开放领域问题。作为自我激励的重要组成部分,我们可以看到LLM所写的解释是高质量的。在第一个例子中,LLM精确地从文章中提取出关键句子;在第二个例子中,LLM成功地进行了共同引用解析,将He替换为George Clooney,并删除了冗余文本;在最后一个例子中,LLM不仅总结了关键句子,还在输出中添加了本文未提到的额外信息。总之,self - prompt可以自动生成伪但高质量的ODQA数据集,并将段落和解释作为注释。

5.6 误差分析
最后,我们进行了一个误差分析的研究,以了解为什么自我提示在一些问题上失败。我们从每个数据集中随机选择100个self - prompt获得EM Score=0的问题,并手动检查它们。从这300个样本中,我们总结出3个主要类型和8个次要类型:1)真阴性- AW, EW(预测和解释都不正确),Need Details(预测不具体);2)假否定-形式(预测和参考是同一件事,但形式不同),多重(预测不在参考列表中,但也是正确答案),RW(参考本身不正确);3)不好的问题:开放式(没有确切答案的开放式问题),时间(如果不明确时间就无法回答),无法回答(回答问题的信息不完整)。结果如表6所示。我们观察到在所有三个数据集中都存在大量的假阴性(58,43,37),因此自我提示在很大程度上被低估了。其中大多数是Form,这表明EM Score不是评估ODQA系统的最佳指标。根据表格,WebQ和NQ的质量较低,因为它们有很多没有注释的答案(Multiple, RW)和糟糕的问题(Open, Time, unanswable)。特别是,这两个数据集中的许多问题都依赖于某个时间点的Wiki Dump,使用最新的Wiki Dump甚至会损害性能(Izacard et al., 2022;Yu等人,2022)。在TriviaQA中,True Negative的比率比其他两个要高得多,所以它更能反映self - prompt的表现。这也解释了为什么selfprompt的表现明显优于微调基准,但在WebQ和NQ上得分较低。

6.总结
在本文中,我们提出了用于开放领域问答(ODQA)的自提示大语言模型(LLMs)。我们的方法要求LLM生成具有匹配段落和解释的伪QA数据集,并将其用于上下文学习。它通过显式激活各种语言理解能力,并在其参数中引出世界知识,成功地激发了ODQA LLM的潜力。在没有训练数据和外部语料库的情况下,self - prompt大大超过了以前的SOTA,并且与几个检索增强的微调模型相当。未来,我们将对框架进行改进,例如消除生成中的幻觉,减少手工设计。我们还将把self - prompt扩展到其他类型的NLP任务中,以证明其普遍有效性,并进一步释放LLM在不同领域的力量。















 2742
2742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









