







 文章研究了视觉提示在大规模视觉模型中的应用,通过不修改模型参数,只改变输入图像,来适应新任务。实验表明,特别是在CLIP模型中,视觉提示表现出高效率,对分布迁移具有鲁棒性,且在某些任务上与线性探测方法的性能相当。文章还探讨了提示设计、输出转换对性能的影响,并指出视觉提示为适应预训练视觉模型提供了新视角。
文章研究了视觉提示在大规模视觉模型中的应用,通过不修改模型参数,只改变输入图像,来适应新任务。实验表明,特别是在CLIP模型中,视觉提示表现出高效率,对分布迁移具有鲁棒性,且在某些任务上与线性探测方法的性能相当。文章还探讨了提示设计、输出转换对性能的影响,并指出视觉提示为适应预训练视觉模型提供了新视角。
目录
2.1Natural Language Prompting(自然语言提示)
2.2 Prompting with Images(图像提示)
2.3 Adversarial Reprogramming and Unadversarial Examples(对抗性重编程和非对抗性例子)
2.4 Adapting Pre-trained Models in Vision(在视觉中调整预训练模型)

代码:https://hjbahng.github.io/visual_prompting
动机:看到prompting在NLP领域变得越来越火,作者提出问题:Why not visual prompting?为证明在CV领域,Prompt是可行的,并且在某些任务和数据集上效果不错。也就是说本文目的是想证明visual prompting的有效性。
方法:使用预训练模型的方法(迁移),在CV中,将一个预训练模型迁移到新任务上的方法主要包括Fine-tuning,Linear Probe,Visual Prompting。 Fine-tuning会修改预训练模型参数,Linear Probe不会修改预训练模型参数,但是会在预训练模型后增加和任务相关的线性层,Visual Prompting则是不修改预训练模型参数,只修改原图像。
论文原文翻译
摘要
我们研究了视觉提示(visual prompting)对大规模视觉模型的适应性。根据最近的从prompt tuning和adversarial reprogramming(对抗性重编程)的方法,我们学习了一个单一的图像扰动,这样一个被该扰动提示的冻结模型执行一个新的任务。通过综合实验,我们证明了视觉提示对CLIP尤其有效,并且对分布迁移具有鲁棒性,达到了与标准线性探测方法(Linear probes)相竞争的性能。我们进一步分析了下游数据集、提示设计和输出转换的特性,以适应性能。视觉提示的惊人效果为适应预训练的视觉模型提供了一个新的视角。
迁移学习是将前一项任务中获得的知识为基础来学习如何执行另一项任务,同时可以任意更改模型参数。而重编程只能通过操纵输入来改变模型。
1.简介
当我们人类学习一项新任务时,我们倾向于从我们现有的知识基础开始并进行推断。一个开始说话和理解句子的孩子很快就能发展出分析句子所包含的情感语境的能力。例如,“I missed the school bus”这句话承载了一种特定的情感,如果后面跟着“I felt so [MASK]”,小孩就能提供一个适当的情感词。这种范式被恰当地命名为提示,最近在NLP中得到普及,通过将下游数据集转换为预训练任务的格式,使大型预训练的语言模型适应新任务。在不更新任何参数的情况下,语言模型使用其现有的知识库在提供的提示中填写掩码,从而成为新任务的专家。目前,提示方法主要是NLP特定的,尽管该框架有一个通用的目的:通过修改数据空间来适应一个冻结的预训练模型。考虑到通用性,我们能否以像素的形式创建提示符?广义上,我们能否通过修改像素空间来引导冻结的视觉模型来解决新的任务?
对抗性重编程是一类对抗性攻击,其中输入扰动重新利用模型来执行对手选择的任务。尽管有不同的术语和动机,这种输入扰动本质上是作为一个视觉提示——它通过修改像素使模型适应新的任务。然而,现有的方法专注于对抗性目标,或在相对小规模的数据集和模型中应用有限。对抗性重编程和提示起源于不同的领域(communities),但它们有一个共同的思想:通过转换输入(即提示工程)和/或者输出(即回答工程,answeer engineering)执行数据空间适应(data-space adaptation b)。
受自然语言提示成功的启发,我们旨在研究视觉提示对规模视觉模型的适应性。由于像素空间本身是连续的,我们遵循最近的方法,将提示作为连续的特定于任务的向量。我们通过反向传播在模型参数冻结的情况下学习单个图像扰动(即“soft prompt”)。通过使用CLIP的离散文本提示和视觉模型的硬编码映射,我们将模型输出映射到下游标签(图1)。
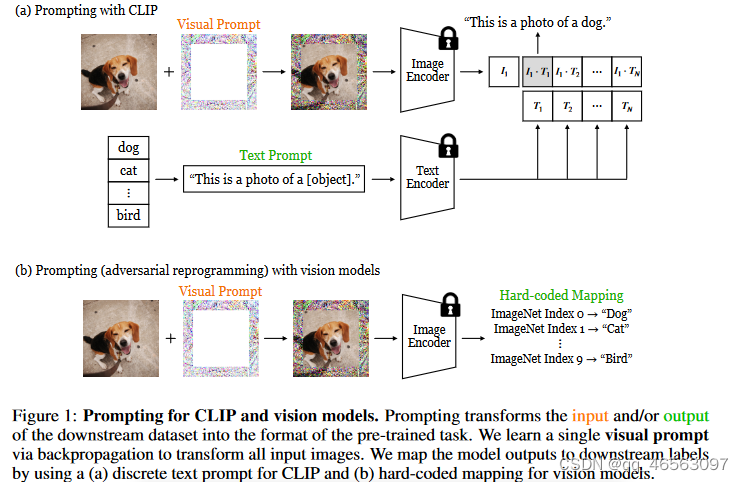
视觉提示与现有的适应方法有何不同?目前在视觉领域,标准的适应方法是fine-tuning和线性探测。这两种方法都需要对模型进行某种level的访问:在fine-tuning的情况下是整个参数,在线性探测的情况下是模型输出(通常在倒数第二层激活)。相比之下,视觉提示使输入适应模型。在获得可视化提示之后,它在测试时不需要访问模型。这打开了独特的应用程序;输入空间自适应将控制权交给了系统的最终用户。例如,行人可以佩戴一个视觉提示,提高他们对汽车的可见度,而无需接触汽车本身或汽车的视觉系统。
我们通过4个预训练的模型和15个图像分类数据集进行了综合实验。我们证明了视觉提示对于CLIP是惊人的有效的,并且对分布迁移具有鲁棒性,实现了与标准线性探针竞争,有时甚至超过标准线性探针的性能。我们进一步分析了下游数据集、提示设计和输出转换的哪些属性会影响性能。请注意,我们的目标不是在特定任务上达到最先进的性能,而是广泛地探索视觉适应的新范式。视觉提示的惊人效果为如何适应和使用预先训练的视觉模型提供了一个新的视角。
2.相关工作
2.1Natural Language Prompting(自然语言提示)
(动机)我们的调查灵感来自于最近自然语言提示的成功。NLP中的提示将下游数据集重新表述为(masked)语言建模问题,以便冻结的语言模型直接适应新的任务,不需要更新任何参数。提示包括构造一个特定于任务的模板(例如,“I felt so [MASK]”)和标签词(例如,“happy/ terrible”)来填充空白。然而,手工制作正确的提示符需要领域的专业知识和大量的努力。
前缀调优或提示调优通过反向传播学习“soft prompt”来缓解这个问题,同时固定模型参数。前缀调优学习特定于任务的连续向量(即前缀),该向量允许语言模型适应各种生成任务。前缀调优为每个编码器层预先准备前缀,而提示调优通过仅为输入预先准备可调tokens来进一步简化。当应用于具有数十亿参数的大型模型时,经过适当优化的提示可以实现有竞争力的性能,从而微调整个模型,同时显著减少内存使用和每个任务存储。由于像素空间中的提示本质上是连续的,我们遵循这条工作线并直接优化像素。
2.2 Prompting with Images(图像提示)
已经有了尝试用图像进行提示的初步方法。与前缀调优类似,Frozen通过使用来自冻结语言模型的梯度训练视觉编码器来创建图像条件提示符。图像被表示为来自视觉编码器的连续embedding,并用作视觉前缀,以允许冻结的语言模型执行多模态任务。CPT通过使用彩色块和基于颜色的文本提示创建可视化提示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









