







阅读了Design Space Exploration for Chiplet-Assembly-Based Processors这篇论文,是关于chiplet设计空间探索的,个人感觉核心贡献有两个:1.提出使用整数线性规划算法进行Chiplet的选择;2.基于RE和NRE提出了一个cost模型,具体的一些记录如下:
目录
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
一、Article:文献出处(方便再次搜索)
(1)作者
- Saptadeep Pal, Puneet Gupta (美国加州大学洛杉矶分校电气与计算机工程系,美国加州大学洛杉矶分校)
- Daniel Petrisko, Rakesh Kumar (美国伊利诺伊州香槟大学香槟分校电气与计算机工程系)
(2)文献题目
- Design Space Exploration for Chiplet-Assembly-Based Processors
(3)文献时间
- APRIL, 2020
- IEEE Transactions on Very Large Scale Integration (VLSI) Systems(是全球半导体行业与ISSCC齐名的最重要会议)
(4)引用
- S. Pal, D. Petrisko, R. Kumar and P. Gupta, "Design Space Exploration for Chiplet-Assembly-Based Processors," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 28, no. 4, pp. 1062-1073, April 2020, doi: 10.1109/TVLSI.2020.2968904.
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
- 不断增加的处理器设计、验证、制造和管理成本——正在给可用于目标应用程序的系统数量带来巨大的压力。随着这些成本的增加,设计和制造大量的片上系统(SoC)可能变得不可行。
- 由于新的设计和组装方法(eg:EMIB)正在被开发和商业化,一个大型处理器SoC现在可以分解成多个、更小的Chiplet component,不同的Chiplet可以使用类似SoC的低延迟和高带宽互连的substrate进行连接,然后重新集成到一个完整的处理器系统中。
- Chiplet的优势:更高的良率,可能会降低系统成本(多个Chiplet可以均摊设计和制造成本,且不同的Chiplet可以基于不同的技术节点),可以实现异构设计,低成本的硬件定制(针对不同的应用程序,可以选择不同的Chiplet组合来构建许多系统)
(2)目的
作者在introduction中提出了三个问题,这三个问题也是本文探究的目标:
- 当一组Chiplet component将被用来构建一组系统以针对不同的应用程序时,应该如何设置微体系结构DSE(Design Space Exploration)问题?也就是说,应该如何设计Chiplet 微体系结构,以满足不同应用程序的需求,并优化系统的性能和功耗?
- 当每个系统仅针对一个应用子集而不是整个应用集时,不同Chiplet的微体系结构特征以及相应的系统是什么?也就是说,在这种情况下,不同的Chiplet应该具有何种微体系结构特征,以及相应的系统应该如何设计,以满足不同应用程序的需求?
- 当考虑到设计和制造的总成本时,Chiplet组装方法有什么好处,以及需要构建哪些Chiplet和相应的系统?也就是说,Chiplet组装方法可以带来哪些成本上的优势,以及应该构建哪些Chiplet和相应的系统,以达到最优的性能和功耗?
(3)结论
- 开发了第一个Chiplet-assembly-based processor的微架构设计空间探索框架,使我们能够确定设计和制造所需要的最小Chiplet集,以使用最小的Chiplet集为应用程序提供近乎定制的系统性能;
- 作者考虑通过同时解决Chiplet和制程技术选择来最小化总体设计/制造成本,并且在成本意识优化时(指在设计和制造过程中,考虑成本因素,以最小化总体成本的优化过程),Chiplet组装可以比SoC节省更多的成本;
- 展示了在不同的应用程序套件(从高性能到嵌入式应用程序)上执行Chiplet DSE的价值,而不是每个套件都进行探索。Chiplet可以在不同的基准套件中重复使用,从而最大限度地实现设计成本摊销的机会。(这句话我理解了好久,我感觉是因为multi-Chiplet可以每个Chiplet承担一个测试套件?所以可以一次测试多个,就不用挨个测试,从而节省时间和资源)
(4)主要实现手段
A. 基于IntLP(整数线性规划)的Chiplet选择框架:
表示哪些Chiplet是系统的一部分。可以在初始Chiplet集合(D)中包含多个相同Chiplet微体系结构的副本,代表不同的技术节点。系统配置集(S)是由Chiplet组成的所有系统的集合。每个应用程序可以分配到任何系统上运行,与之相关的成本[n-tuple]包含功率、CPI性能、每条指令的能量(EPI)、EDP和总成本]由
给出,示意图如下:
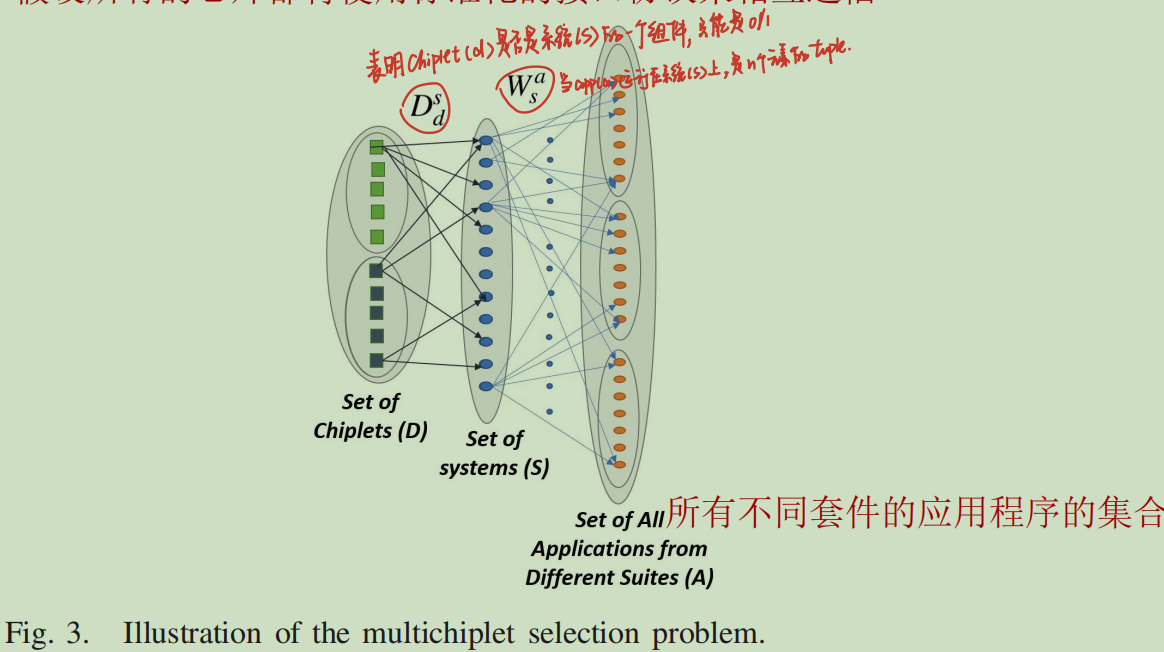

一些假设:
- 所有的Chiplet都采用标准的接口协议来相互通信,可拓展支持所有宽度的接口,并只增加一个额外的延时;
- 在双核系统的不同内核上运行的两个应用程序不相互干扰,它们的总体性能是每个工作负载在单核上运行时IPC的总和;
- 对于性能模拟,假设L2 Cache 有 12-cycle access,将latency更改一个周期导致的性能差异可以忽略不计;
- 计算平均能耗时排除了DRAM的能耗,因为其对结果影响不大;
- 不同制程技术节点的Chiplet具有相同的微架构参数,即性能相同;
DSE的方法是一个包含三个主要步骤的迭代过程:
- 首先,我们确定了一组有趣的初始系统配置来探索。
- 下一步,我们对这些初始系统配置进行了全因子探索。全因子探索是一种研究方法,它可以用来研究多个变量之间的相互作用,以及它们对结果的影响。它可以帮助研究人员更好地理解系统的行为,并确定最佳配置。
- 最后,根据IntLP DSE Framework优化算法来选择最佳的芯片和系统来覆盖给定的工作负载。
总的来说,生成设计空间的实验方法的整个步骤就是:
(1)确定设计参数;(2)确定设计空间;(3)确定设计变量;(4)确定设计约束;(5)确定设计目标;(6)确定设计优化算法;(7)运行设计优化算法;(8)评估设计空间。
B. Chiplet-assembly-based 成本模型:
关于Chiplet的成本可以分成两种,NRE和RE,分别如下:
- NRE:Nonrecurring engineering cost,一次性开销,包括:体系结构、RTL设计、IP验证、物理设计、prototype、验证和掩模制造成本。
- RE:recurring engineering cost(volume-dependent),非一次性开销,包括:晶圆制造的成本,产率和工艺复杂性是决定制造成本的主要因素。
考虑到制程技术会随着时间增长逐渐成熟,那yield也会随着时间提高,这个学习公式如下:
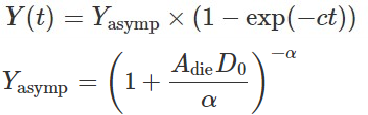
其中,t指制程已投入使用年数, 是由diea area(
),缺陷密度(
)和clustering factor(a)共同决定的渐进yield。
现在考虑RE Cost(即晶圆制造成本,),由die的数量(Vd)、晶圆成本(Cw)、yield(Y)和每个晶圆的die数量(Ndie)共同决定,公式如下:
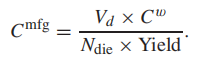
当考虑到基于Chiplet assemblies的总成本最小化时,我们使用以下目标函数:
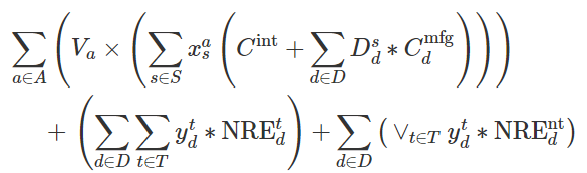
其中,Va是应用程序a所需的系统数量。是Chiplet的组装/集成成本,
是Chiplet d的制造成本,并使用第三个式子进行估算。
是一种依赖于制程技术的NRE成本,它包括物理设计、IP验证、原型、掩模集成本等。
是一种与制程技术无关的NRE成本,包括体系结构、RTL开发和验证等。当使用特定的微体系结构在两个不同的技术节点上构建芯片时,
被摊销;但是,每个技术节点的Chiplet都需要
费用。
注意:作者假设RE是晶圆制造的成本,且产率和工艺复杂性是决定制造成本的主要因素。考虑到核心Chiplet和缓存Chiplet之间的IO通信,增加了0.5mm2的面积开销。
(5)实验结果
- 实验配置

- benchmarks

注意:模拟器将将运行100M条指令,以确保模拟器已经达到稳定状态,然后运行30M条指令,以获得更详细的性能数据
- Chiplet Microarchitecture

Chiplet数目从2-4时,CPI Threshold从1.1到2时,每个Chiplet的微体系结构设置,如上图,我没太懂的是:论文中提到当Threshold=1.1时,Chiplet需要大于等于4才能work,但是看论文的意思却只写了2个Chiplet,我有些迷惑。
- 实验一:在不同的技术节点上的标准化成本组件
为了更准确地估计Chiplet的成本,作者还考虑了Logic和DRAM的cost difference(一般考虑单个Chiplet时最多考虑core+cache),其中:
- Logic指的是逻辑电路,它是用来实现计算机系统中的功能的电路,包括控制电路、运算电路和存储电路等。
- SRAM是静态随机存取存储器,它是一种高速存储器,常用于制作Cache,SRAM成本包括:内存编译器许可证的费用以及工程师的费用
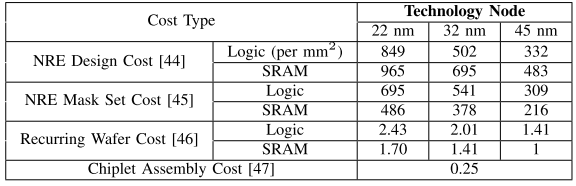
根据算法部分的成本公式进行计算,一些参数是参考以往论文来的,但是我没有很懂这个结果说明了什么。
- 实验二:不同系统大小和技术成熟度下,Chiplet组装技术相对于SoC技术的成本效益

在EDP阈值约束下,以总成本最小化目标进行DSE操作。 其中,NRE设计成本只考虑一个核心的副本,相同的核心IP被复制多次并连接到互连IP上,所产生的设计成本将大致与具有互连的单核系统相似。如图6所示,基于Chiplet的组装比基于SoC的方法提供了巨大的成本效益。
- 当系统尺寸较小时,SoC产率较好。然而,在多核系统中,随着系统尺寸的增加,超过一定的die size后,SoC产率根据其良率曲线公式迅速下降。
- 此外,Chiplet的良率基本不变,但开发这些Chiplet的NRE成本随着系统规模的增长而摊销。虽然互连基板和Chiplet的组装成本随着系统的尺寸的增大而增加,但它占总成本的比例较小。因此,尽管系统集成成本略有增加,但降低了每个Chiplet的总成本。
- 当集成成本越高时,SoC与Chiplet组装之间的差距就越小。事实上,当系统尺寸较小时,Chiplet组装可能比SoC更昂贵。随着技术的成熟,SoC的成本会逐渐下降,但集成成本下降空间不大。
- 实验三:使用CPI约束来最小化EDP
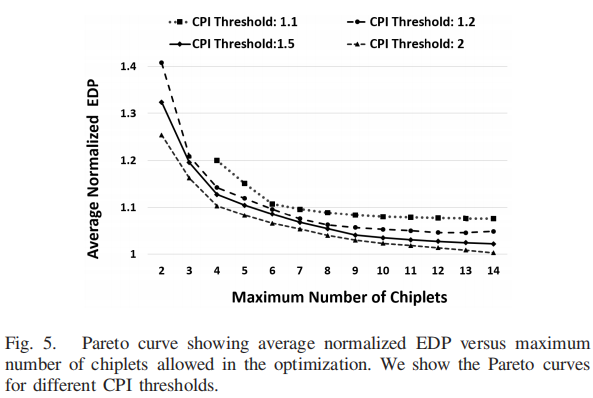
- 更多的Chiplet可以显著降低平均EDP。最初,添加更多Chiplet的好处非常明显(曲线下降速度非常快),因为从Chiplet中选择的前几个系统针对的是广泛的工作负载类,如内存绑定/计算绑定的应用程序。随着更多的Chiplet被添加,新系统主要针对outlier workload,从而导致增量比较缓慢。
- 当CPI Threshold非常严格(小)时,只有少数系统可供选择,因此EDP很快就会饱和。但是,对于更宽松(大)的CPI阈值,需要七到八个Chiplet才能获得接近最优的EDP。
- 实验四:在不同技术成熟度水平下EDP和总成本的tradeoff
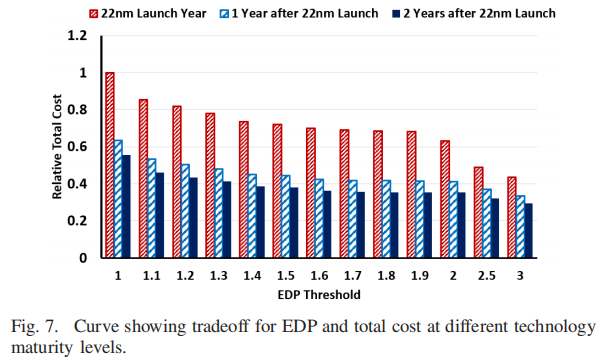
- 较低的EDP阈值要求更多的系统来最小化成本,从而削减每个工作负载的设计空间,使得可供选择的系统较少。这会导致over costume,使得工作负载之间几乎没有系统共享。因此,需要构建这些系统的不同Chiplet的数量增加,从而导致NRE成本更高。
- 随着EDP阈值的放宽,优化开始选择较小的内核和较小的L2芯片块。总的来说,芯片块和系统的数量减少,在工作负载之间增加共享。增加共享有助于分摊NRE成本,从而降低总成本。
- 对于一个特定的总成本预算,随着技术的成熟,人们可以实现更好的整体EDP。因为技术逐渐成熟时,可以以相同的总成本构建更多的Chiplet,从而实现相同的目标性能。
- 实验五:最小化Chiplet数量 V.S. 最小化总成本
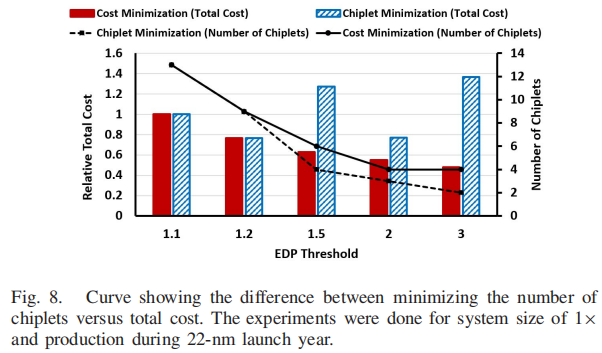
以最小化Chiplet数量为目标的优化并不一定会导致最小的总成本。如图8所示,当EDP阈值放宽时,Chiplet Minimization导致的Chiplet数量比Cost Minimization时更少。然而,设计和制造的总成本仍然远远高于Cost Minimization时的目标。这是因为Chiplet Minimization选择了更少但更大的Chiplet (低良率和成本)来满足所有工作负载的EDP阈值,而Cost Minimization选择了更多更小(更低成本)的Chiplet 来构建多个系统,每个Chiplet 片针对不同类型的工作负载。
(6)其他积累
什么是设计空间:
指的是可以用来设计工作负载的可用资源,包括计算能力、存储能力、网络能力等。
关于测试指标:
- CPI:指令周期指数,表示每条指令的平均执行时间,可以用来比较不同处理器的性能;
- EDP:能耗密度,它是一种衡量系统能耗和性能之间的比率,用于衡量系统的能耗效率;EDP越低,说明能耗效率越低,即能耗小,性能高,此时系统数量就多,这样可以更好的分摊总成本,从而最小化成本,满足工作负载的需求;
- EDAP:功能耗密度百分比,是系统能耗和性能之间的比率,用于衡量系统的能耗效率;系统供应商偏爱EDAP指标;
- EDA2P:能耗密度的平方,也是系统能耗和性能之间的比率,可以更准确地衡量系统的能耗效率。芯片供应商偏爱这个指标,因为A2可以近似表示die的成本。
关于测试套件:
- SPEC2006是一个由Standard Performance Evaluation Corporation(SPEC)开发的基准测试,用于衡量计算机系统性能。它包括了一系列的测试,包括多种应用程序,如数据库、视频编辑、游戏等,以及多种操作系统,如Linux、Windows等。
- EEMBC是Embedded Microprocessor Benchmark Consortium(嵌入式微处理器基准测试联盟)的简称,是一个用于衡量嵌入式系统性能的基准测试。它包括了一系列的测试,包括多种嵌入式处理器,如ARM、MIPS等,以及多种嵌入式操作系统,如Linux、Android等。
- SPLASH-2是一个用于衡量超级计算机系统性能的基准测试,由Stanford University开发。它包括了一系列的测试,包括多种超级计算机,如IBM Blue Gene、Cray XMT等,以及多种操作系统,如Linux、Unix等。
- NPB是一个用于衡量并行计算机系统性能的基准测试,由NASA Ames Research Center开发。它包括了一系列的测试,包括多种并行计算机,如IBM Blue Gene、Cray XMT等,以及多种操作系统,如Linux、Unix等。
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
阅读体验不太好,感觉写的略有些混乱,我倾向于在分析图表的时候,文字应该不要离图太远,我看的时候,明明已经在讲图八了又跳出去讲图六,我自己读起来不太顺畅。在讲述方法时,成本建模的部分和后面成本的分析是分开的,一开始看会不明白:这是一个chiplet assemble的问题,测量的是性能,为什么又考虑到成本(最重要的是几个成本公式,读起来关系有点跳脱),还有后面的分析,越看越糊涂……是我太菜了🆒/(ㄒoㄒ)/~~,里面还是涉及到很多基础知识,比如提到的:BEOL和FEOL等,本菜菜是第一次见,这是百度来的:
- BEOL层是指Back-End-of-Line层,它是指晶圆上的最后一层,它包括金属层和多层互连层。
- 金属层是指晶圆上的金属层,它用于连接晶圆上的元件。
- FEOL层是指Front-End-of-Line层,它是指晶圆上的第一层,它包括晶圆上的掩模层和多层互连层。
还有我觉得最让人迷惑的是几个关键指标,我觉得没有说太清楚,出现的频率又高。EDP/EDAP/DEA2P,都是测试系统性能的指标,没有给出公式,难道是很常见的指标吗?反正我没有百度到。逻辑分析我觉得对新手也不友好,为什么EDP越低,系统数目要越多,workload的设计空间就越小,诸如此类这样的问题有很多,我也没看懂(;′⌒`)
四、Why:为什么看这篇文献 (方便再次搜索)
用于实验设计:
- 了解更多关于Chiplet设计空间探索的相关问题
- 看能否将IntLP算法和毕设联系起来
五、Summary:文献方向归纳 (方便分类管理)
-
Design space exploration
-
整数线性规划
-
cost model














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









