







读懂code\ECformer\model当中的.py文件
包括
ba_ours.py
dstt.py sttn.py fuseformer.py poolformer.py
swin.py focal.py
e2fgvi.py
目录
五. Swin Transformer和Focal Loss
预览对比:
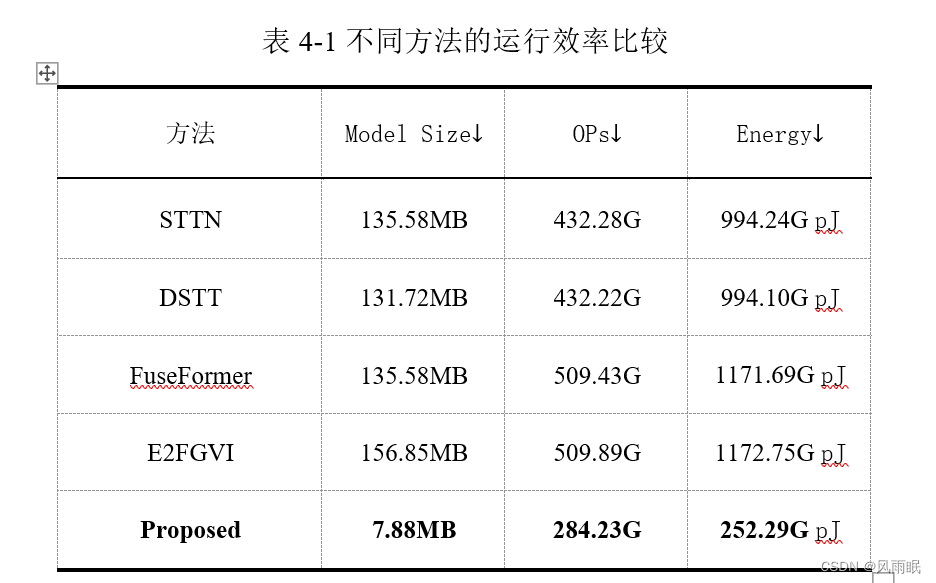
STTN、DSTT、FuseFormer总结(它们改进了什么?)_马鹏森的博客-CSDN博客
一、STTN与FuseFormer
STTN与FuseFormer的Model Size相同,但是OPs(节点数)不同,由此入手进一步了解两个模型不同之处。
STTN中 class InpaintGenerator(BaseNetwork)
padding = (0, 0)
stride = (7, 7)
FuseFormer中 class InpaintGenerator(BaseNetwork)
padding = (3, 3) stride = (3, 3)
1.1主要区别
STTN(Spatio-Temporal Transformer Networks)是一种用于视频分析和处理的模型。它使用Transformer中的自注意力机制来处理时空信息,可以对视频中的对象进行精确定位、跟踪和识别等任务。STTN通过将视频中的每一帧视为一个时间步骤,并在时间和空间上应用Transformer,以捕捉对象之间的关系和运动。
FuseFormer是一种用于自然语言处理的模型,旨在将图像和文本信息融合以进行多模态任务,例如图像标注和视觉问答。FuseFormer结合了Transformer中的编码器和解码器,并使用了注意力机制来对图像和文本信息进行编码和解码。FuseFormer可以自适应地对文本和图像信息进行特征提取和融合,从而实现多模态信息的有效交互。
1.2 代码实现上的主要区别
STTN和FuseFormer在代码实现上最大的区别在于其网络架构和输入数据处理的方式。
STTN的网络架构主要包括时间和空间Transformer编码器,时间和空间Transformer解码器和空间注意力机制。在输入数据处理方面,STTN将视频序列拆分为时间步骤,并将每个时间步骤的特征图与相邻时间步骤的特征图进行堆叠,以建立时空关系。
相比之下,FuseFormer的网络架构主要包括编码器、解码器和融合层。在输入数据处理方面,FuseFormer将图像和文本信息分别输入到编码器中,然后使用融合层将两个编码器的特征进行融合,最后在解码器中生成相应的输出。
二、STTN与DSTT
从代码结构上看有许多的不同:
| STTN包含的类 | DSTT包含的类 |
| class BaseNetwork(nn.Module) | class BaseNetwork(nn.Module): |
| class BinarizedEncoder(nn.Module): | class HierarchyEncoder(nn.Module): |
| class Encoder(nn.Module): | class InpaintGenerator(BaseNetwork): |
| class BinarizedDecoder(nn.Module): | class deconv(nn.Module): |
| class InpaintGenerator(BaseNetwork): | class Attention(nn.Module): |
| class deconv(nn.Module): | class Vec2Patch(nn.Module): |
| class Attention(nn.Module): | class MultiHeadedAttention(nn.Module): |
| class AddPosEmb(nn.Module): | class FeedForward(nn.Module): |
| class SoftSplit(nn.Module): | class TransformerBlock(nn.Module): |
| class SoftComp(nn.Module): | class Discriminator(BaseNetwork): |
| class MultiHeadedAttention(nn.Module): | |
| class BinarizedMultiHeadedAttention(nn.Module): | |
| class FusionFeedForward(nn.Module): | |
| class TransformerBlock(nn.Module): | |
| class Discriminator(BaseNetwork): |
2.1 区别在于网络结构和应用场景
STTN使用Transformer的自注意力机制来处理时空信息,通过将视频序列视为一个时间步长,并在时间和空间上应用Transformer,从而捕捉视频中对象之间的关系和运动。STTN主要应用于视频分析和处理领域,如视频分类、动作识别、对象检测和跟踪等任务。
DSTT也是一种基于Transformer的视频处理模型,但它采用了双流结构,即在空间和时间上分别使用两个独立的Transformer编码器。DSTT使用空间Transformer编码器来提取图像中的空间信息,并使用时间Transformer编码器来提取视频中的时序信息。通过使用两个独立的编码器,DSTT可以在空间和时间上同时学习到不同层次的特征,从而提高视频处理的效果。
与STTN相比,DSTT更加适用于需要同时考虑空间和时间信息的视频处理任务,如视频分割、行为识别、事件检测等。
因此,STTN和DSTT都是基于Transformer的视频处理模型,但它们的网络结构和应用场景有所不同。STTN主要用于视频分类、对象检测和跟踪等任务,而DSTT则适用于需要同时考虑空间和时间信息的视频处理任务。
2.2 代码实现上的主要区别
STTN(Spatio-Temporal Transformer Networks)和DSTT(Dual Spatio-Temporal Transformer)在代码实现上的主要区别在于它们的网络结构和输入数据的处理方式。
STTN的网络结构包括时间Transformer编码器、空间Transformer编码器、时间Transformer解码器、空间Transformer解码器和空间注意力机制。在输入数据处理方面,STTN将视频序列分解为时间步骤,并将每个时间步骤的特征图与相邻时间步骤的特征图进行堆叠,以建立时空关系。
DSTT的网络结构包括时间Transformer编码器、空间Transformer编码器、时间Transformer解码器和空间Transformer解码器。在输入数据处理方面,DSTT分别使用空间和时间Transformer编码器对视频中的每个帧进行特征提取,并将两个编码器的特征进行融合以生成相应的输出。
因此,尽管STTN和DSTT都是基于Transformer架构的视频处理模型,但它们的网络结构和输入数据处理方式有所不同。
三、STTN与E2FGVI
3.1 主要差别
STTN(Spatio-Temporal Transformer Networks)和E2FGVI(Enhanced Two-Stream Fused Graph Video Inference)都是应用于视频处理领域的深度学习模型,但它们之间的区别在于网络结构和应用场景。
STTN主要是通过使用Transformer架构的自注意力机制来处理时空信息,从而捕捉视频中对象之间的关系和运动。STTN可以用于视频分类、动作识别、对象检测和跟踪等任务。
E2FGVI则使用图卷积神经网络(GCN)和两个流(空间流和时间流)的结构来对视频进行建模。它通过建立空间和时间流之间的图结构,利用图卷积神经网络来融合两个流中的特征,从而捕捉视频中的上下文信息。E2FGVI主要应用于视频分割、人物重识别和行为识别等任务。
在网络结构方面,STTN使用Transformer编码器和解码器以及空间注意力机制,而E2FGVI使用图卷积神经网络和两个流的结构。在输入数据处理方面,STTN将视频序列分解为时间步骤,并将每个时间步骤的特征图与相邻时间步骤的特征图进行堆叠,以建立时空关系。而E2FGVI则将空间流和时间流的特征提取结果通过图卷积神经网络进行融合。因此,STTN和E2FGVI在网络结构和应用场景上存在不同。
3.2代码实现上的差别
STTN和E2FGVI的代码实现上的主要区别在于它们的网络结构和数据处理方式。
在网络结构方面,STTN主要包括时间Transformer编码器、空间Transformer编码器、时间Transformer解码器、空间Transformer解码器和空间注意力机制。在代码实现上,这些组件被实现为不同的神经网络层或模块,并按照一定的顺序进行堆叠和连接。例如,STTN中的时间Transformer编码器可以通过堆叠多个自注意力层和前馈网络层来实现。
而E2FGVI则使用了两个流的结构,其中每个流都包括空间和时间编码器、图卷积神经网络和解码器。在代码实现上,每个流可以被实现为独立的神经网络,其中空间和时间编码器可以由卷积神经网络或其他类型的神经网络层组成,而图卷积神经网络通常是由多层图卷积层和池化层组成的。
在数据处理方面,STTN将视频序列分解为时间步骤,并将每个时间步骤的特征图与相邻时间步骤的特征图进行堆叠,以建立时空关系。这种处理方式可以通过在代码中使用循环神经网络(RNN)或卷积神经网络(CNN)来实现。
而E2FGVI则将空间流和时间流的特征提取结果通过图卷积神经网络进行融合。在代码实现上,可以使用一些图卷积神经网络库(如PyTorch Geometric)来构建图卷积层和池化层,并将它们与空间和时间流的特征进行融合。STTN和E2FGVI在代码实现上的区别主要在于它们的网络结构和数据处理方式。
四. PoolFormer和FuseFormer
PoolFormer和FuseFormer都是最近提出的基于Transformer的深度学习模型,用于对图像进行处理和编码。它们之间的区别主要在于网络结构和编码方式。
PoolFormer是一种基于自注意力机制的图像编码器,它使用了Transformer编码器的结构来对图像进行编码。具体地,PoolFormer将输入的图像通过一个普通的卷积神经网络编码为特征图,并将特征图拆分为多个块。然后,PoolFormer将这些块分别作为自注意力机制的输入,以捕获它们之间的关系和重要性。最后,PoolFormer将所有注意力机制的输出合并,并通过多层感知机对其进行汇总,生成最终的编码表示。
FuseFormer是在PoolFormer的基础上提出的一种改进模型,它将两个图像的特征向量进行融合,以生成更精确的编码表示。与PoolFormer不同,FuseFormer将两个图像的特征向量通过注意力机制进行融合。具体地,FuseFormer将两个特征向量分别作为注意力机制的输入,以捕获它们之间的关系和重要性。然后,FuseFormer将注意力机制的输出与两个特征向量的加权和相加,并通过多层感知机对其进行汇总,生成最终的编码表示。
因此,PoolFormer和FuseFormer的主要区别在于它们的编码方式和融合方式。PoolFormer仅对单个图像进行编码,而FuseFormer则通过融合两个图像的特征向量来生成更精确的编码表示。在代码实现上,这些模型也有所不同,但它们都基于Transformer的结构,并使用PyTorch等深度学习框架实现。
五. Swin Transformer和Focal Loss
-
Swin Transformer是一种新型的Transformer模型,其与传统的Transformer模型相比,引入了基于窗口的局部自注意力机制,从而可以处理更大的图像。Swin Transformer还引入了层次式的特征表示,使得模型可以学习到更具有层次性的图像特征,从而取得更好的效果。
-
Focal Loss是一种用于解决分类问题中类别不平衡的损失函数。与传统的交叉熵损失函数相比,Focal Loss可以将更多的关注点放在难以分类的样本上,从而提高这些样本的权重,减少易分类样本的权重,从而提高模型的性能。
在代码实现上,Swin Transformer和Focal Loss都可以在主流的深度学习框架中实现,如PyTorch等。Swin Transformer的代码实现需要对窗口化自注意力机制进行实现,并将其应用于Transformer结构中。而Focal Loss的代码实现则需要在交叉熵损失函数的基础上,添加额外的参数用于调节易分类样本的权重,以实现类别不平衡问题的处理。
总之,Swin Transformer和Focal Loss都是目前深度学习领域中非常重要的模型和技术,在不同的任务和场景中都可以取得很好的效果。它们的主要区别在于模型结构和损失函数的设计。
六. STTN与ba_ours
| STTN包含的类 | ba_ours包含的类 |
| class BaseNetwork(nn.Module): | class BaseNetwork(nn.Module): |
| class BinarizedEncoder(nn.Module): | class Encoder(nn.Module): |
| class Encoder(nn.Module): | class InpaintGenerator(BaseNetwork): |
| class BinarizedDecoder(nn.Module): | class deconv(nn.Module): |
| class InpaintGenerator(BaseNetwork): | class Attention(nn.Module): |
| class deconv(nn.Module): | class AddPosEmb(nn.Module): |
| class Attention(nn.Module): | class SoftSplit(nn.Module): |
| class AddPosEmb(nn.Module): | class SoftComp(nn.Module): |
| class SoftSplit(nn.Module): | class MultiHeadedAttention(nn.Module): |
| class SoftComp(nn.Module): | class FeedForward(nn.Module): |
| class MultiHeadedAttention(nn.Module): | class FusionFeedForward(nn.Module): |
| class BinarizedMultiHeadedAttention(nn.Module): | class ChannelAttention(nn.Module): |
| class FusionFeedForward(nn.Module): | class kNNAttention(nn.Module): |
| class TransformerBlock(nn.Module): | class TransformerBlock(nn.Module): |
| class Discriminator(BaseNetwork): | class Discriminator(BaseNetwork): |
class PositionalEncoding(nn.Module): |














 4135
4135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









