






芯片及类脑芯片内容的学习记录)
仅个人学习记录,有错误还希望被指出
本来只是想了解芯片中矩阵相乘的具体操作过程,看了一堆资料和讯息,就将了解到的记录下来了
一些混淆概念的介绍
推荐视频和链接:
1、芯片的介绍
2、硬件知识cpu/gpu/tpu/npu相关知识
3、简单的聊聊 NPU ,Tensor core
- CPU的主要计算单元是标量运算,当然后面出来的SSD,AVX指令不包含在里面
- GPU的主要计算单元是矢量运算,现在一般都是SIMD,然后多个SIMD组成MIMD
- NPU的主要计算单元是矩阵运算. 矩阵运算器就是tensor core.
- TPU英文全称Tensor Processing Unit,中文全称为张量处理单元,是深度学习算法的专用芯片。
- 一般情况下,npu和tpu就是ai芯片的核心,cpu和gpu就是简单处理一些计算。但这只是一般情况。
普通芯片
1、普通的芯片是遵循冯·诺依曼计算架构的。
2、cpu和并行加速运算的GPU都是属于普通芯片。
3、GPU在早期是为了处理图形数据。gpu相当于是10000个加法题找很多的幼儿园学生去做。效率也就高了很多。
4、cpu/gpu支持矩阵相乘的库:cpu(OpenBLAS、Intel MKL)、gpu(cuBLAS、cuDNN)
cpu中的矩阵计算
推荐链接:cpu中的矩阵计算
主要的计算过程就像下面写的代码一样:
for (unsigned int i = 0; i < hA; ++i){
for (unsigned int j = 0; j < wB; ++j) {
float C[i][j] = 0;
for (unsigned int k = 0; k < wA; ++k) {
C[i][j] += A[i][k] * B[k][j];
}
C[i][j] = Cij ;
}
}
就是按照最原始的线性代数的方式,不断的从内存中获取值并计算。下图采用的是行优先存储,也就是按照先一行行的存储再进行下一列的,正好符合上述代码。

具体计算过程见上述链接,本文只叙述大概的过程。
gpu中的矩阵计算
推荐链接:gpu中的矩阵运算、更详细的不同gpu计算方法
gpu中为了实现并行运算,主要的思想还是将矩阵分为多个子矩阵,然后同时计算他们的乘积。
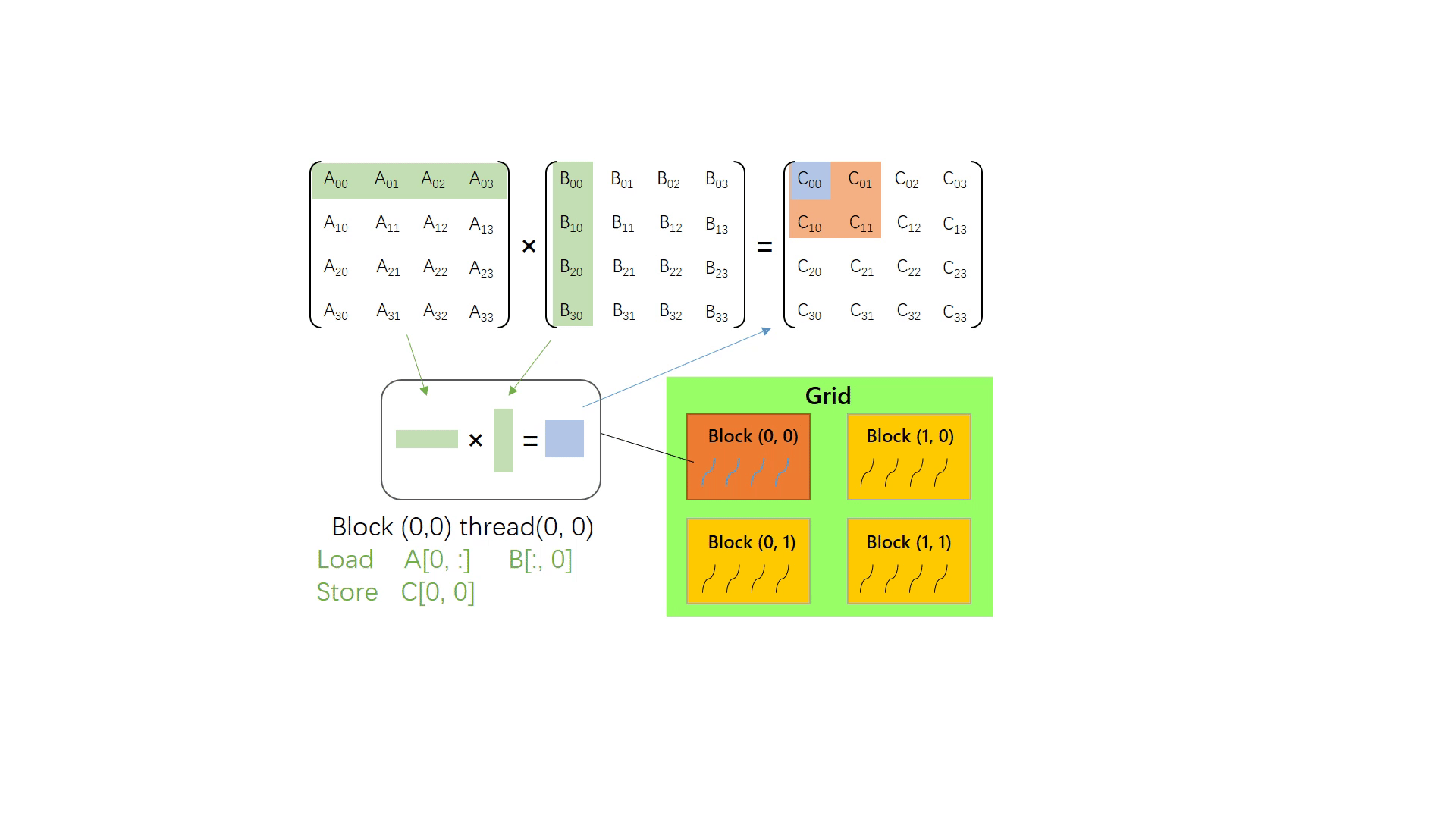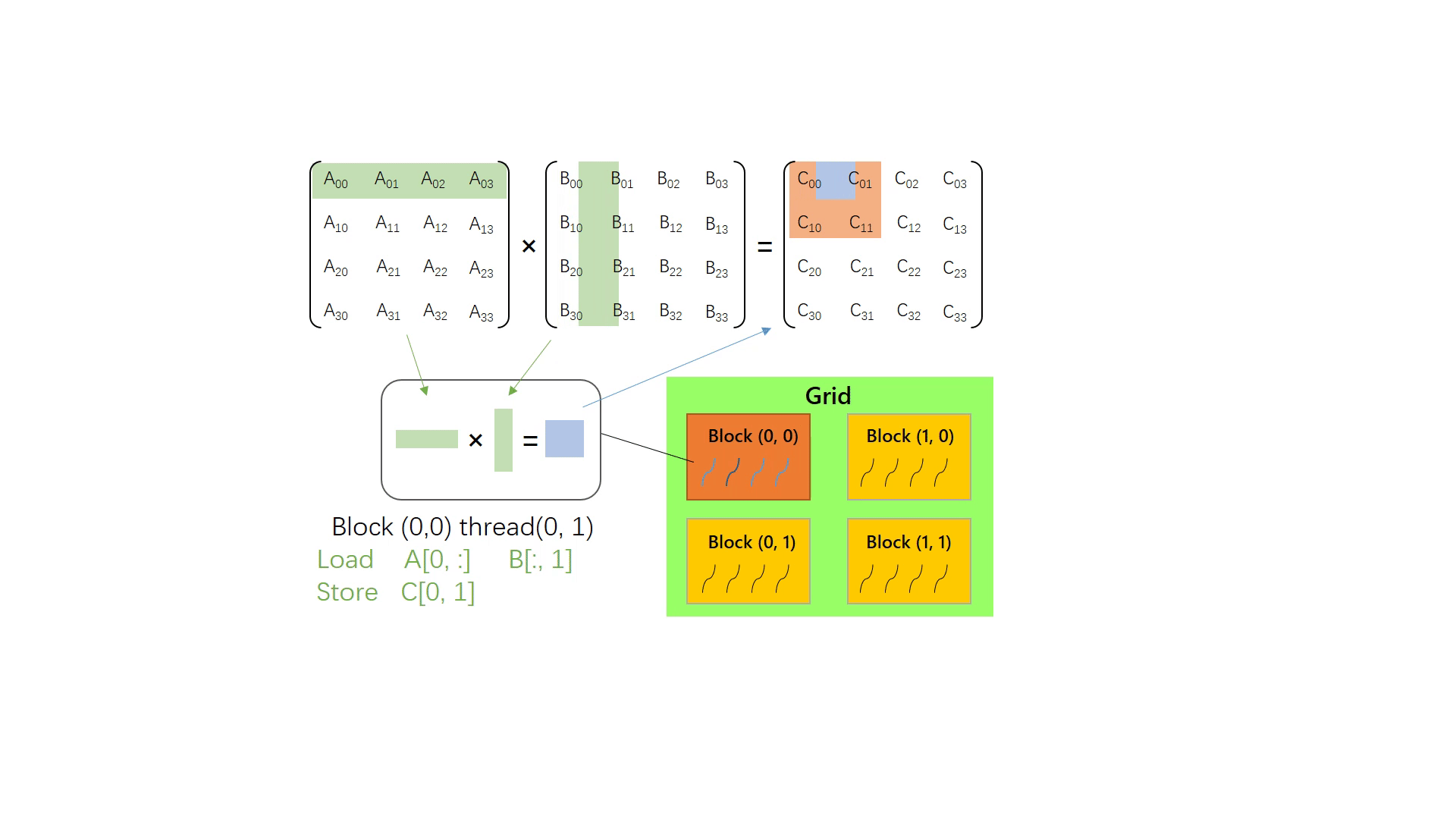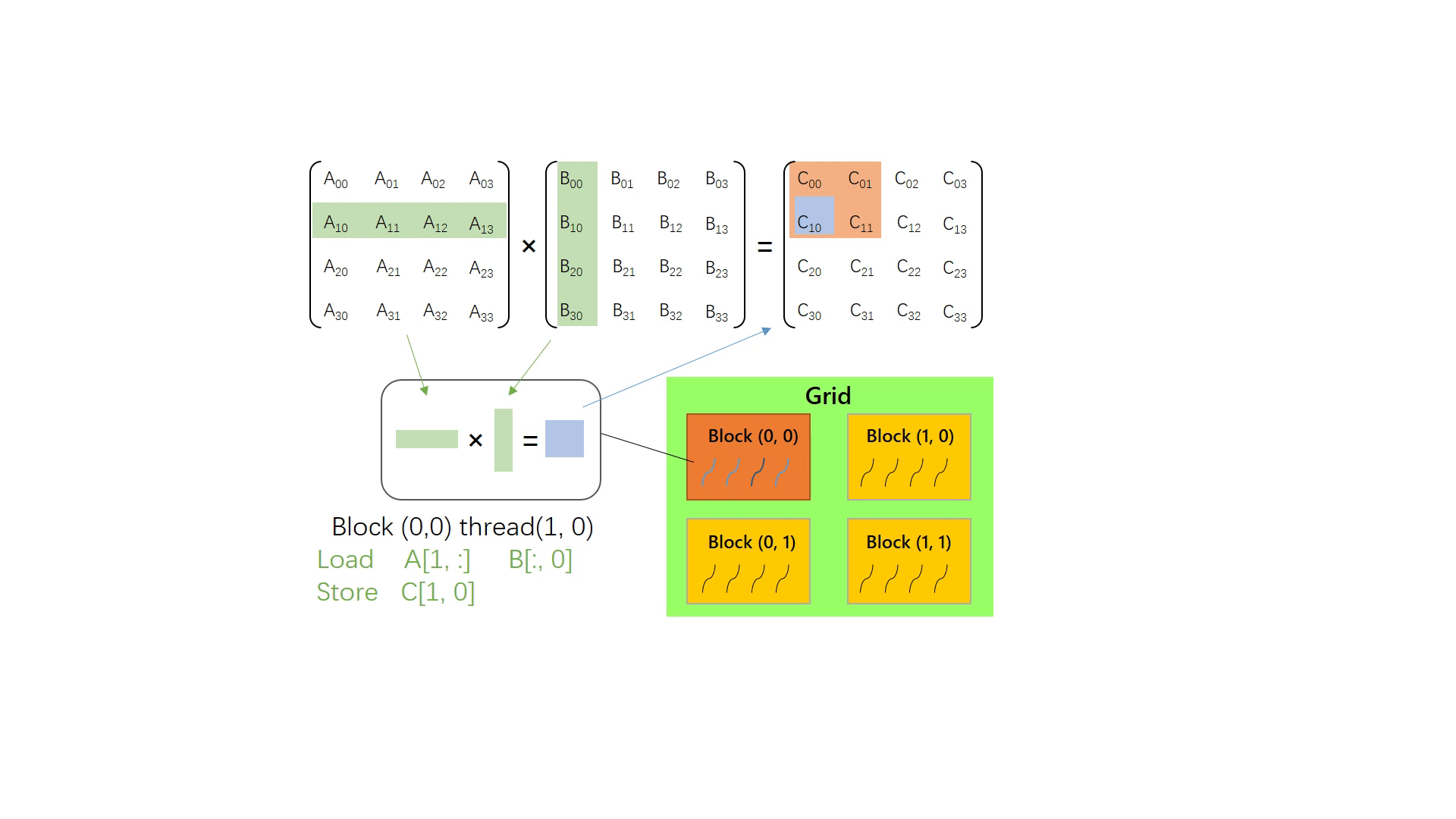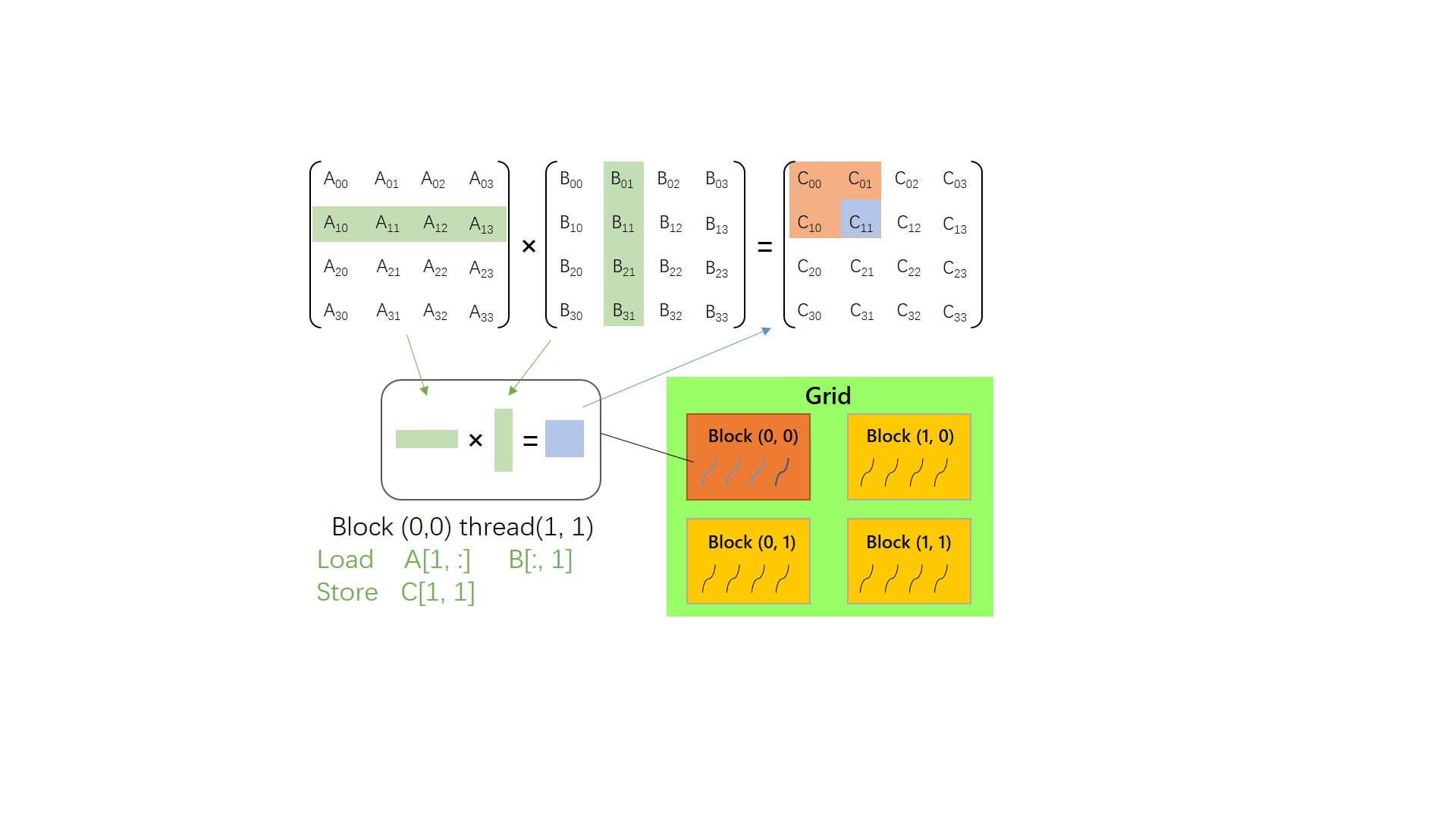
具体计算过程见上述链接,本文只叙述大概的过程。
ai芯片
1、ai芯片也是遵循冯·诺依曼架构的
2、ai芯片主要用于处理深度学习,专门用于机器学习的芯片。(例如:Google TPU系列、NPU)
3、ai芯片的指标:
1)OPS(Operations Per Second);
2)MACs(Multiply-Accumulate Operations);
3)FLOPs(Floationg Point Operations);
4)MAC(Memory Access Cost)
卷积变矩阵相乘
在研究ai芯片矩阵相乘的过程中,要知道卷积变为矩阵相乘也是一个小内容。
例如:下图中为卷积变矩阵相乘的过程,但是途中的1234为位置编号,非数值。
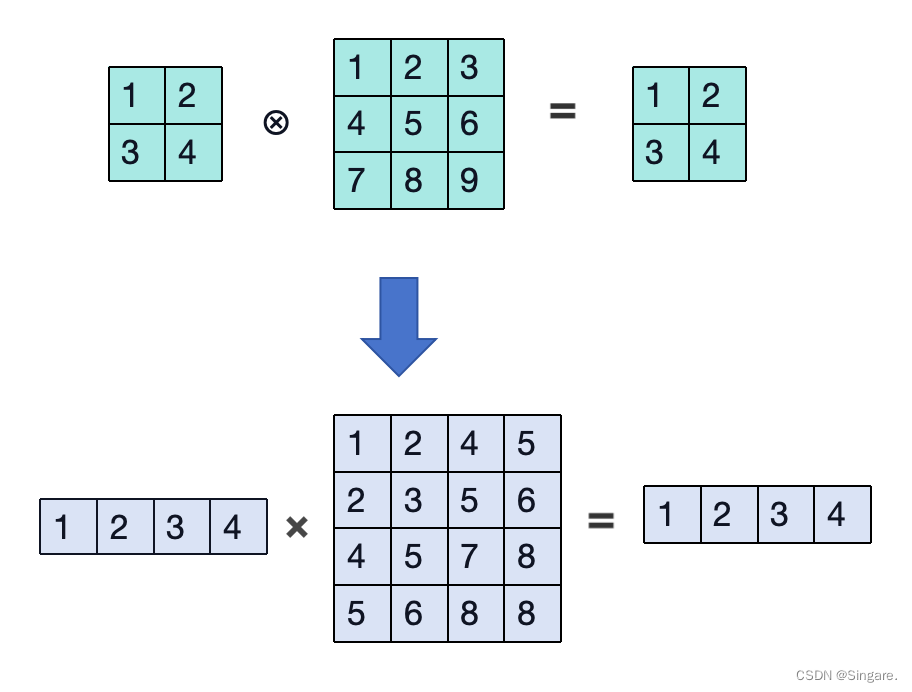
ai芯片中的矩阵相乘
推荐链接:AI芯片:高性能卷积计算中的数据复用、芯片原理:NPU矩阵乘法加速详解
Nvidia TensorCore矩阵相乘过程
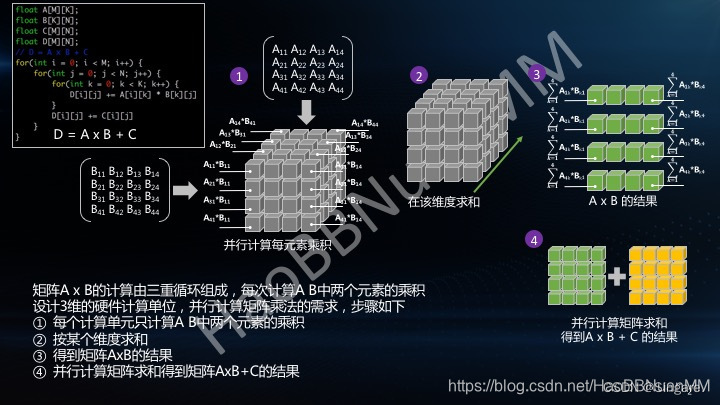
简单来说,就是在矩阵相乘的过程中矩阵a和矩阵b中需要相乘的每一个过程都分别计算出来。
第一步就是先分别计算需要的相乘部分;第二步就是按照矩阵相乘的要求,再进行相乘部分的相加。
下图是博主HaoBBNuanMM
给出的一个解释,很形象。
图中解释的是A*B+C的过程,1-3步解释的是A*B,第四步是相加。图中不好理解的时候可以倒着推一下过程,A*B的结果矩阵中(i,j)位置上的数是怎么得来的,再去看第2步和第1步。
上图只是针对4*4的矩阵过程,如果是8*8。此时并行就需要把大的矩阵转化为小矩阵进行操作计算。如图
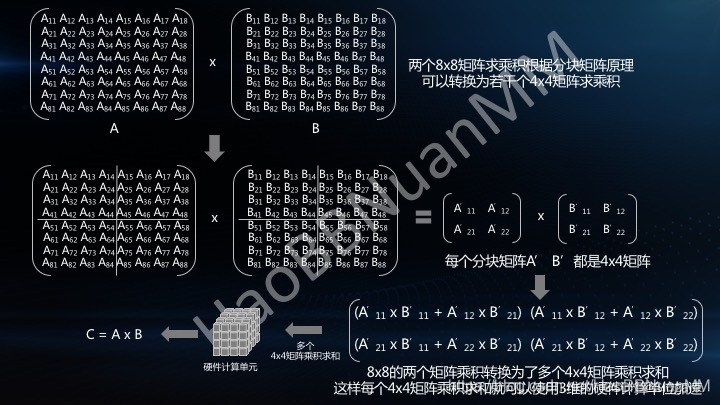
总结:简单来说此时的计算就是需要拆分计算过程,优先乘法,再加法。需要添加一个3维的硬件计算单元。(这也是为什么nv要求用户模型中的矩阵大小最好是4的倍数)
Google TPU矩阵相乘过程
官网介绍:张量处理单元 (TPU) 是 Google 定制开发的应用专用集成电路 (ASIC),用于加速机器学习工作负载。如需详细了解 TPU 硬件,请参阅系统架构。Cloud TPU 是一项网络服务,可让 TPU 作为 Google Cloud 上的可伸缩计算资源使用。
TPU 使用专为执行机器学习算法中常见的大型矩阵运算而设计的硬件,更高效地训练模型。TPU 具有芯片上高带宽内存 (HBM),让您可以使用较大的模型和批量大小。TPU 可以组成 Pod 组,这样无需更改代码即可纵向扩容工作负载。
博主HaoBBNuanMM给出的一个计算过程解释,感觉比官网形象。
就是两个矩阵按照特定的方式进入MAC计算阵列,边相乘边相加。

类脑芯片
1、类脑芯片是不遵循冯·诺依曼架构,采用的是存算一体的方式进行计算和处理数据。
2、现在的类脑芯片研究主要是进行人工智能边缘计算,突破冯·诺依曼架构,提供一种新的创新发展路径。
3、现如今发展的类脑芯片有:
- TrueNorth芯片(IBM-2014年)
- 英特尔Loihi芯片(英特尔-2018)
- 天机Tianjic芯片(清华大学-2019nature)
- 达尔文Darwin芯片(浙江大学和之江实验室-2020年)
- 英特尔Loihi2芯片(英特尔-2021年)
- 苏轼SHSHI芯片(中科院-2023年)
4、忆阻器也会处理double类型的数据。
5、即使现在有很多框架可以让snn跑在ai芯片上(例如:spikingjelly),但是实际结果并不具备压倒性的优势。
忆阻器
忆阻器是一种存算一体电子突触。忆阻器是一种具有记忆功能的非线性电阻。具体构造解说见:忆阻器芯片介绍
简单来说就是一种电阻,受流过的电荷影响而变化的元件。
说明:
- 忆阻器的电阻值通电结束后是不变的,需要重新输入权重的话,再来个电压给电阻值重新刷新即可
- 忆阻器阵列,其实是一种利用物理规律完成的模拟计算。
举例说明忆阻器的应用过程:
现在有一个矩阵和一个向量相乘:
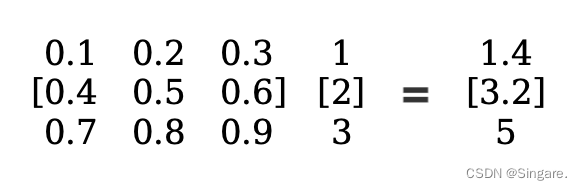
然后如下图所示,小圆圈部分是忆阻器元件,我们可以通过在1,2,3号竖线上加电压,分别表示向量中的三个值。让9个小圆圈(忆阻器)的电导和矩阵中的数值对应起来。电流=电导*电压。那么此时横向方向上在电线位置测量一下总电流就是矩阵的结果。
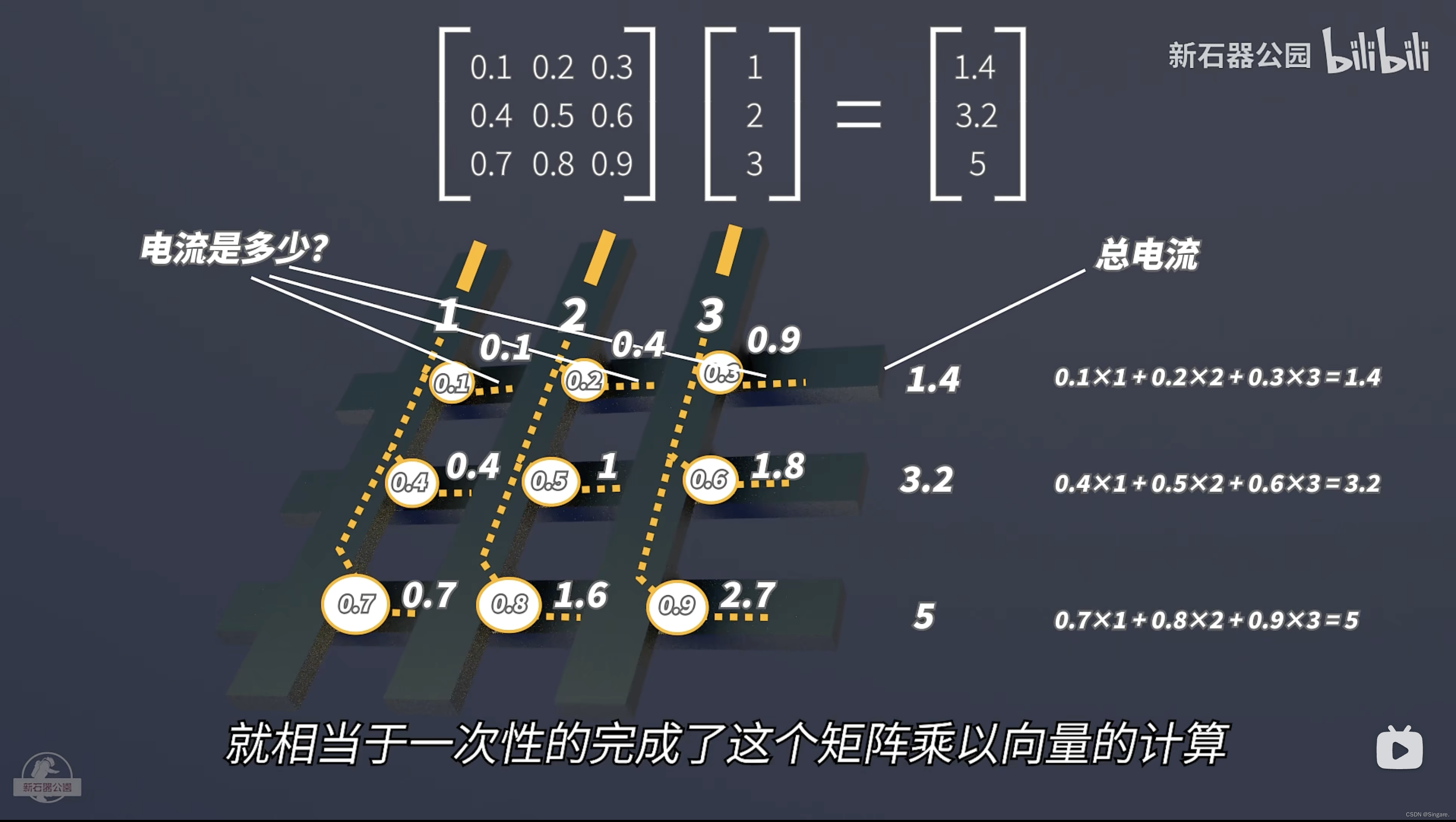
应用:
1、2015年,IBM用一个12*12的阵列实现了三个字母的识别
2、2017年,清华大学吴华强团队用128*8的阵列实现了人脸识别等等
模拟计算中,计算精度是一个很大的考验。毕竟以二进制为代表的数字计算只需要管有电和没电,所有的状态都转化为0101数字再进行数学运算,对物理精度完全不关心。但是模拟计算中,电压电流就代表数值,每一点微小的变化就会带来计算数字的变化。
那么由此可见,提高模拟计算的精度就变成了一个新的问题。清华大学吴华强团队(研究出全球首个多阵列忆阻器存算一体芯片)的一些改进:
1、阻值变化不稳定问题
- 使用千层饼结构,导电层和不导电层交替叠加,使其成为了一个千层饼结构,并且在千层饼之上又增加了一个热导率低的热交换层。
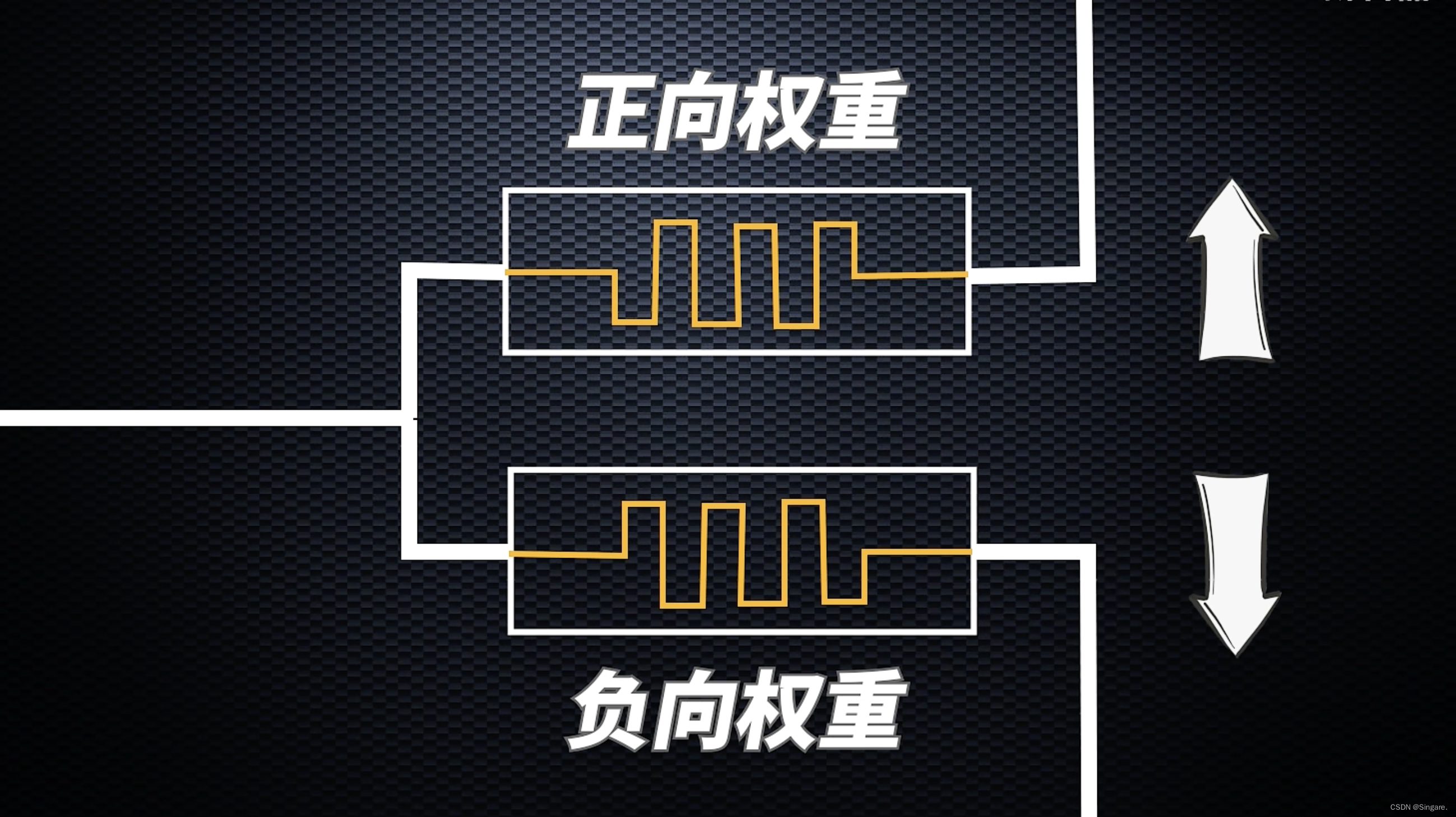
2、电流的不稳定
- 增加限流电路
- 把忆阻器分为正向权重和负向权重。相同电压下,一个电阻值增加,一个电阻值降低。增加权重,更新正向。减少权重,更新负向。
3、算法
- 误差模型。通过压力训练,让AI自己寻找误差规律。
TureNorth
推荐视频:truenorth
1M的神经元,每个神经元256个轴突输入。
计算过程如下图:
横向的线是轴突,用于接受上一层神经元信息。
纵向的是树突,用于每个下层神经元接收信息。
横向和纵向的交叉点就是突触,每个突触会有不同的权重
过程:来自上层神经元的信息通过轴突再通过突触最后汇聚到下方的神经元。通过激活函数的处理,产生新的脉冲再传递到更下一层的神经元。
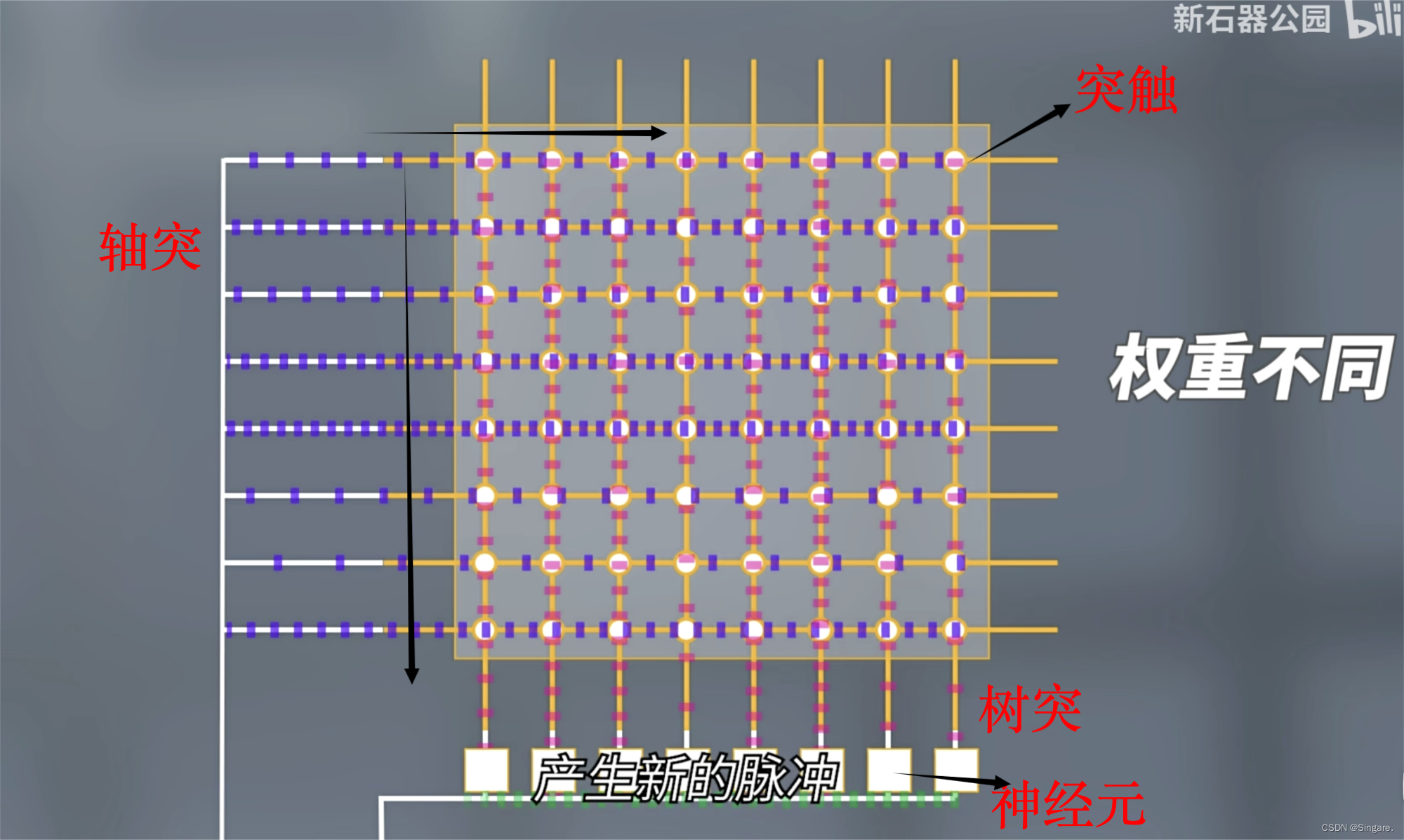
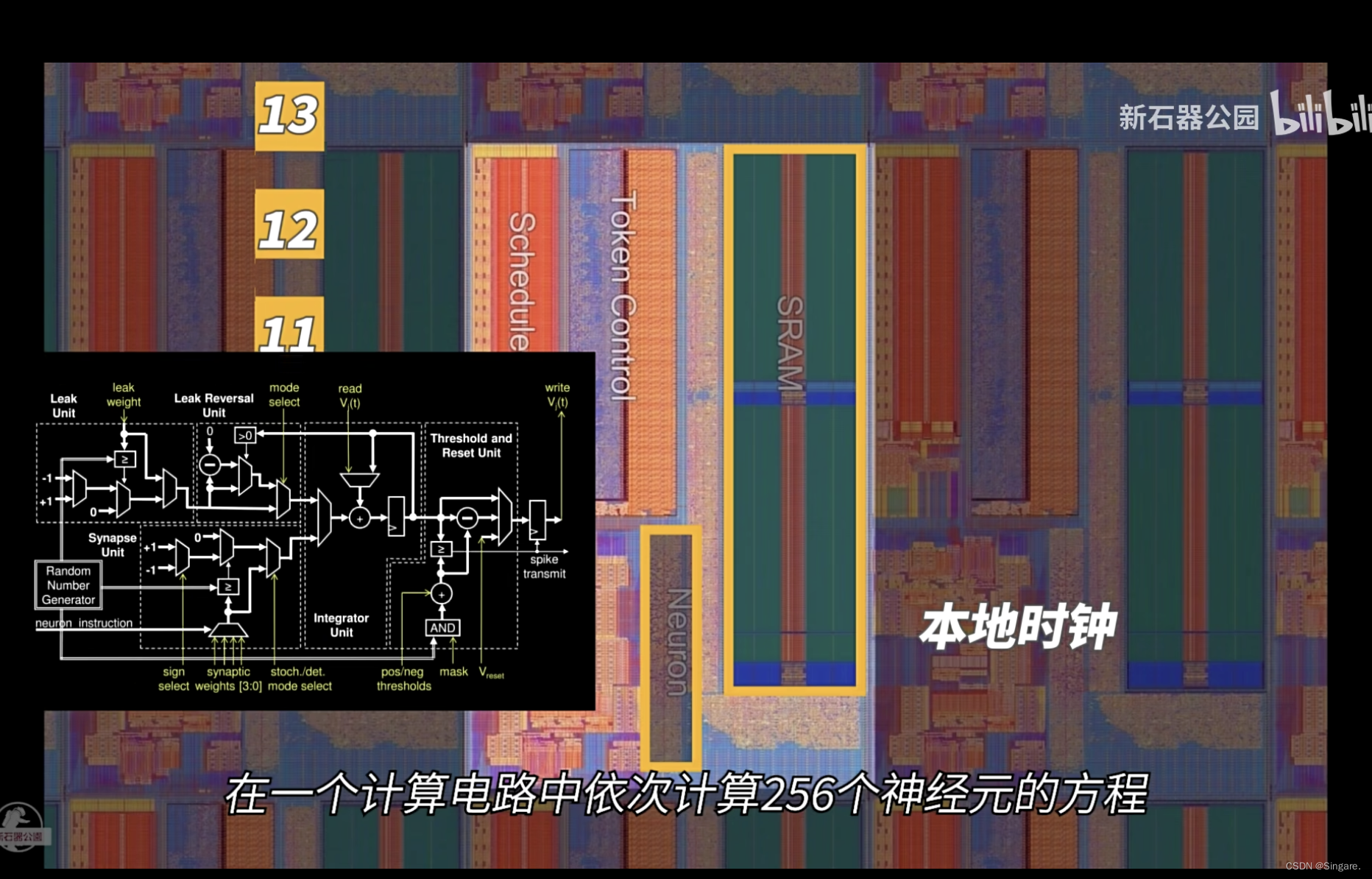
整个芯片没有全局的时钟,靠脉冲驱动。也就是说脉冲来了就计算,没有脉冲就休息。但是芯片还是基于CMOS架构。实际采用的还是传统的计算。物理结构如下图。
数据存储到SRAM中,再采用一个本地时钟进行同步。物理的神经元只有一个,它把时间分成小块,在一个计算电路中依次计算256个神经元的方程,此处没有并行运算。就和传统的cpu一样挨个计算。
Loihi芯片
218个神经内核和三个嵌入式x86处理器,每个内核有1024个尖峰神经单元。神经元突触的密度比TrueNorth高了三倍。
天机Tianjic芯片
速度比TrueNorth提高了10倍,带宽提高了至少100倍。最关键的是把ANN和SNN的计算逻辑合并到了一个计算单元中。通过巧妙的打开和关闭乘法运算单元,同时兼容ANN和SNN。
苏轼SUSHI芯片(中科院-2023年)

推荐视频:sushi超导神经形态芯片
1、采用超导神经形态芯片。需要极低的超导温度。
2、RSFQ:快速单通量量子
3、Josephson junctions约瑟夫森结
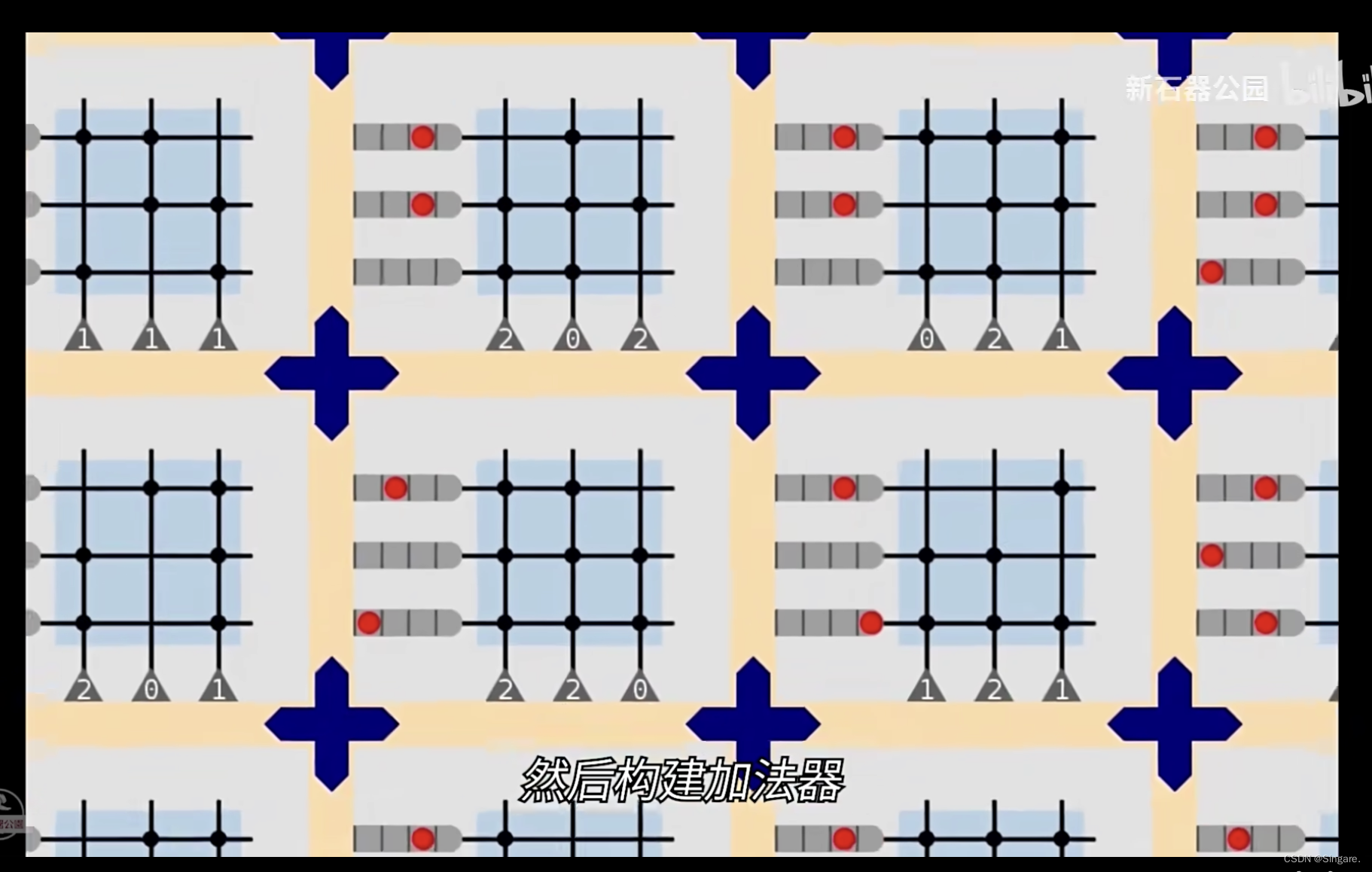
4、半导体中实现snn:硬件模拟出神经元,然后构建加法器,把脉冲权重累加一下做一个判断,超过阈值就输出一个1,然后发送给下一级的神经元。(TrueNorth就是这样实现的)
01脉冲通过晶体管的通断来维持,线路打开,电流通了就是1,关闭就是0。会有一个全局时钟来控制。
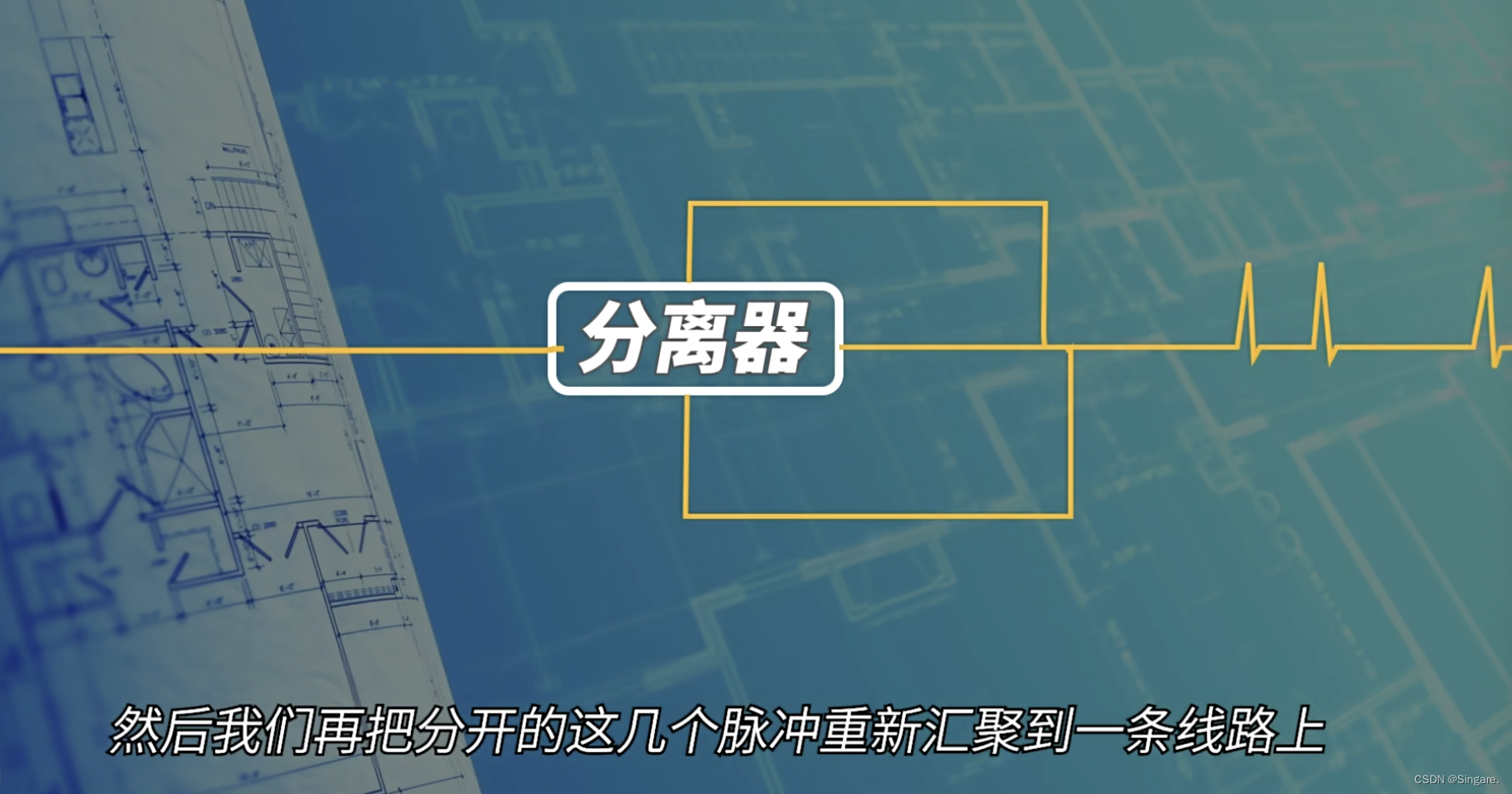
5、分离器可以复制脉冲
超导中会遇见的问题——————————————————————
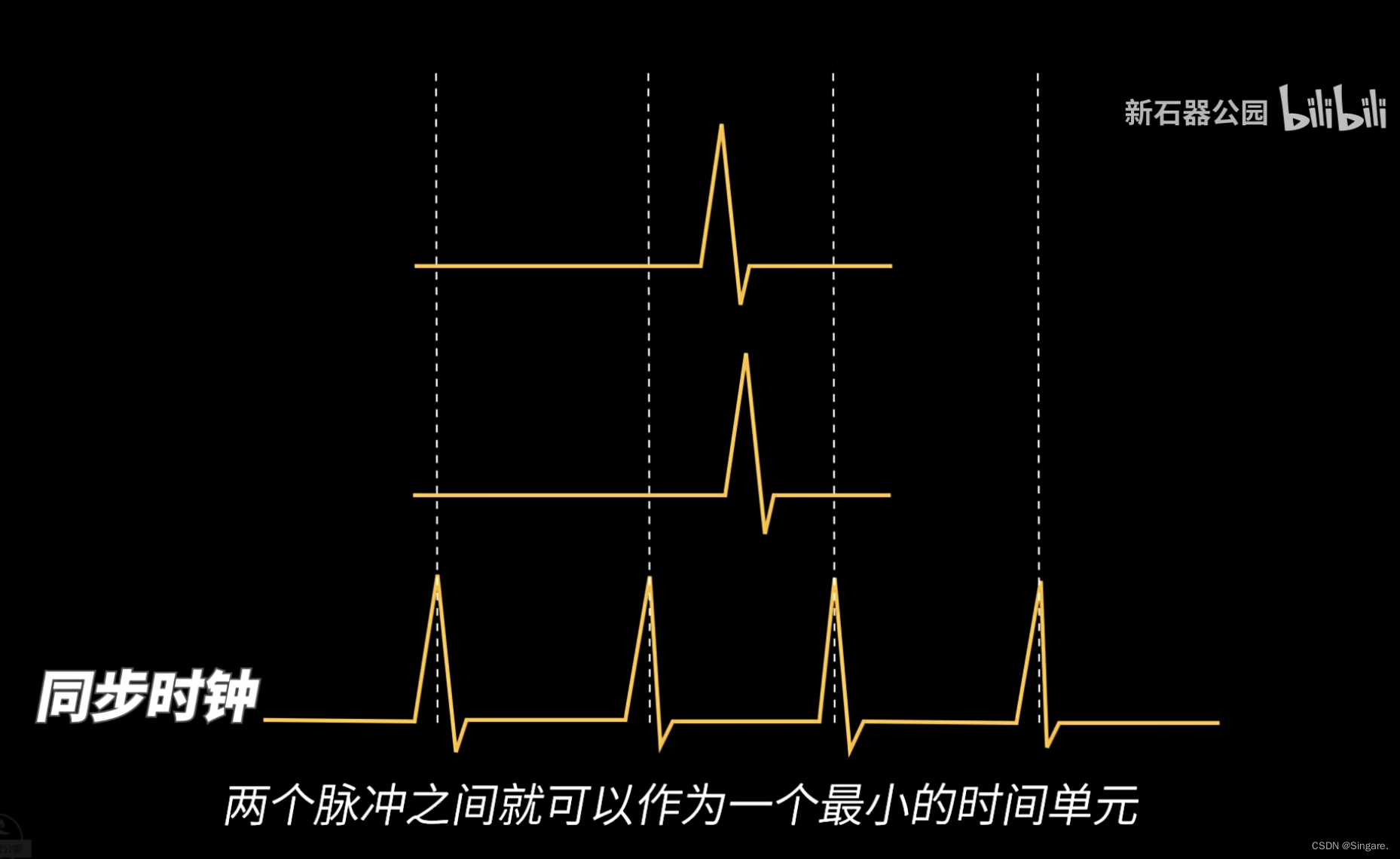
同步时钟:超导中RSFQ就不可能像半导体一样,脉冲是随机产生的,所以需要一个同步时钟。
存储器拖后腿:无法满足快速计算的要求
芯片集成度不够:很难形成大规模
中科院的创新SUSHI——————————————————————
状态控制器:完成数据的存储;状态的翻转,会在脉冲来了的情况下触发四种状态:1)当前是0,不翻转;2)当前是0,翻转;3)当前是1,不翻转;4)当前是1,翻转;
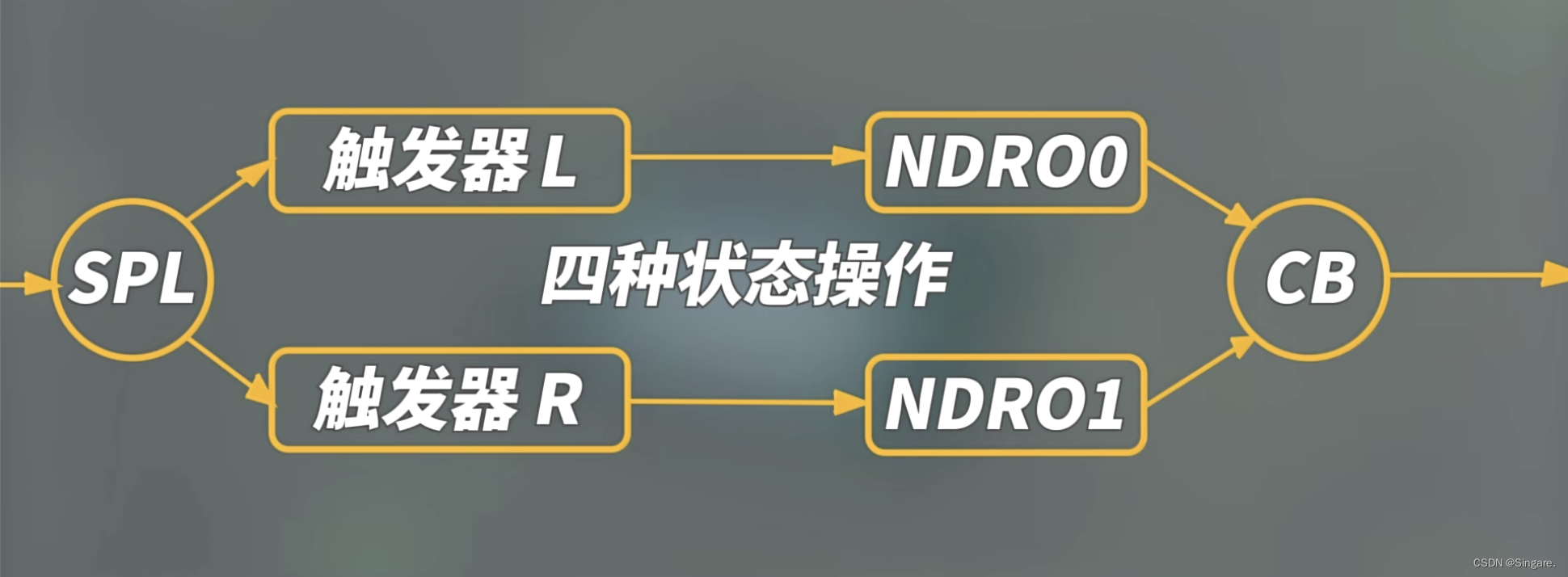
状态控制器完成了激活函数的计算。将状态进行单位统一,便于定量分析。例如:500个状态就可以记录整个神经元的放电过程的所有状态,只需要用状态控制器表示这500个状态就可以,就相当于用计数器在记录倒水的次数。
那不同的状态怎么变为这统一定量下的标准呢?这就采用了超导脉冲神经网络(Superconductuing SNN,SSNN),绕开了传统的权重计算过程。
传统计算如下,第一个权重是0.3,第二个权重是0.5。
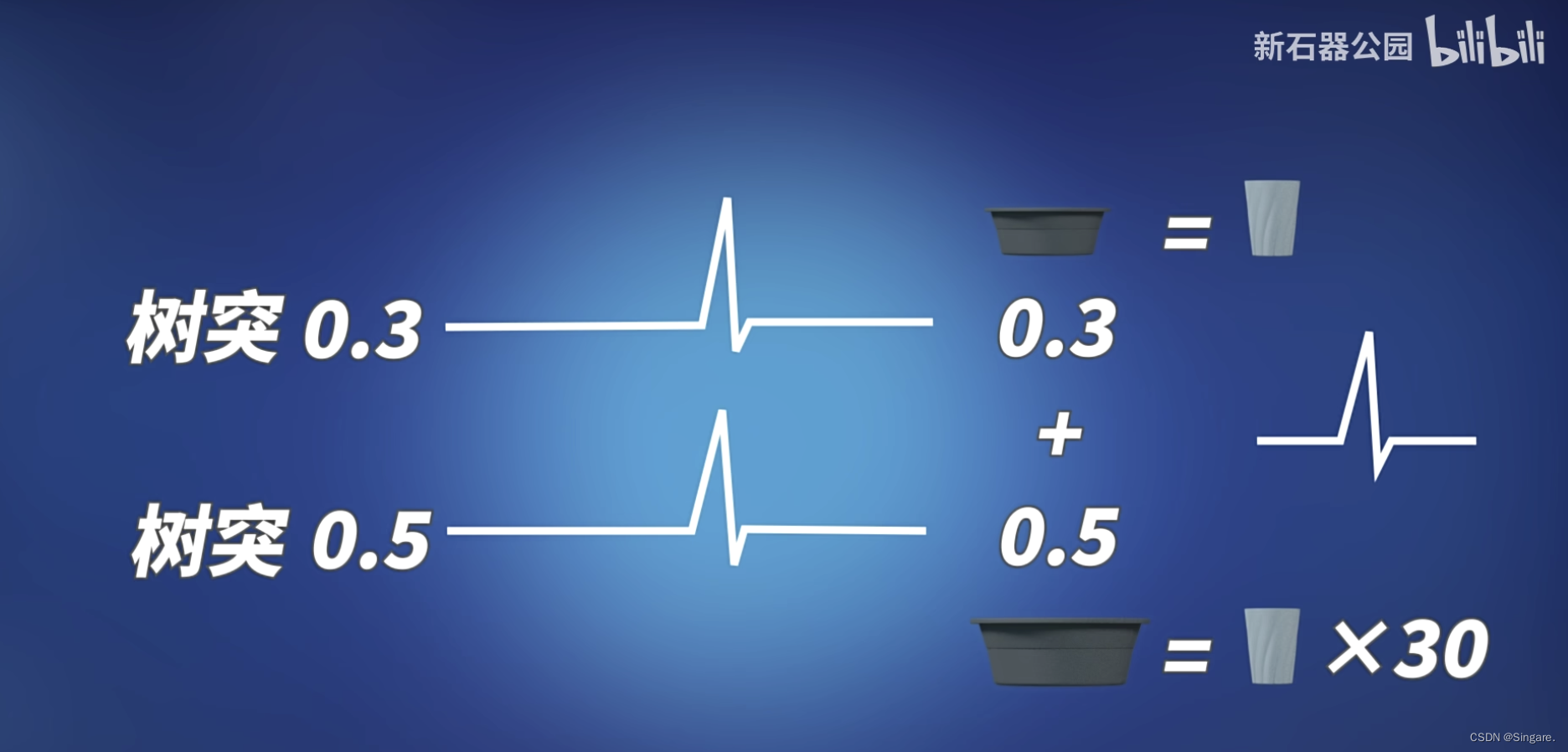
改进就是统一单位,数数量。本来是按照权重计算大小,现在只需要数脉冲个数了。使用分离器将脉冲进行复制。
网络框架
横向是轴突,纵向是树突。树突的末尾是神经元。横向和纵向交叉的地方就是突触。
权重的逻辑,就是统一单位定量的地方就在这里。每个突触上设计了一个开关,可以决定更新脉冲到达的时候要不要更新权重。这样就可以并行更新所有需要更新的权重了。
计算过程就是脉冲沿上一级神经元的轴突横向传过来,在每一个突触上根据权重被复制出不同的份数,然后这些脉冲再沿着树突传播,汇聚到神经元上。根据累计的状态来决定是否需要发射一个新脉冲到下一个神经元。

位片处理切片
为了在较小的规模下运行很大规模的网络,还采用了一种位片处理的方法把网络进行切片。按照神经网络的层分为很多片。这样就可以重复利用计算核心,以时间换空间。
相关问题
1、我还是不太清楚,类脑计算中的数值在权重计算时,还是以double类型存在吗?
2、类脑芯片中处理的数据是ann还是snn(spike neural network)还是都有呢?
3、类脑芯片的核心是存算一体还是说脉冲计算呢?

















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









