









前面部分很多只是笔者学习知识记录的部分并且会随着学习的深入不段增加知识,没有什么参考价值,实战部分或许更有借鉴意义。
0 知识学习
1 官方文档学习
1.1 相关问题
学习到的知识及需要学习的知识:
- 异步训练
- 支持keras高阶API和自定义训练(实验需要,目前只学习keras)
jobs和tasks两个概念需要明确- 集群中的三个角色的分工需要了解:
chief、worker、ps portpicker是什么?为什么需要这个东西?multiprocessing是什么?为什么需要这个东西?sidecar评估如何实现?- 官方示例需要创建2个ps服务器和3个worker服务器
- 每个worker上支持调用多个GPU但需要保证所有worker上的GPU数目是一致的。
- 通常需要将多个步骤打包到一个函数中以实现最佳性能。
1.2 问题解答
异步训练相对于同步训练的优点?
- 训练速度快,效率高
- 模型的泛化能力好
- 能够减少机器的短板效应
cluster、job、task之间的关系
包含关系:一个cluster(集群)包含多个job(作业),每个job又可能包括一个或多个task(任务)。
portpicker是干啥用的?
可能和集群间网络通信有关,是一个用于选择独特可用网络端口的库。
官方文档中使用portpicker来进行配置In-process集群,用于本地测试,并不是真实生产环境。因此,我们并不需要用到。
multiprocessing是干啥用的?
用于支持多线程执行任务
每个worker和ps都需要运行一个server,什么是
tf.distribute.Server?
一个进程内(in-process)服务
tf.distribute.Server(
server_or_cluster_def, # (协议缓冲?)用于描述server的创建或者集群中的成员
job_name=None, # 可选,指定job的名称
task_index=None, # 可选,指定task的索引
protocol=None, # 可选,指定使用的协议,包括 "grpc", "grpc+verbs"
config=None, # 可选,tf1.x 的默认配置
start=True # 可选,布尔型,指示是否在创建这个server之后启动它
)
coordinator实例的作用是啥?
- 创建故障容错资源并调度函数到远程worker上。
- 协调集群,在ps上定义变量,并在worker上进行计算。
- 好像说将不会以一个孤立的样式被支持,目前只在实验性策略中可以工作
tf.distribute.experimental.ParameterServerStrategy?
coordinator的task的作用有哪些?
创建资源、调度训练任务、编写检查点、处理任务失败
worker、ps、coordinator之间如何联系?
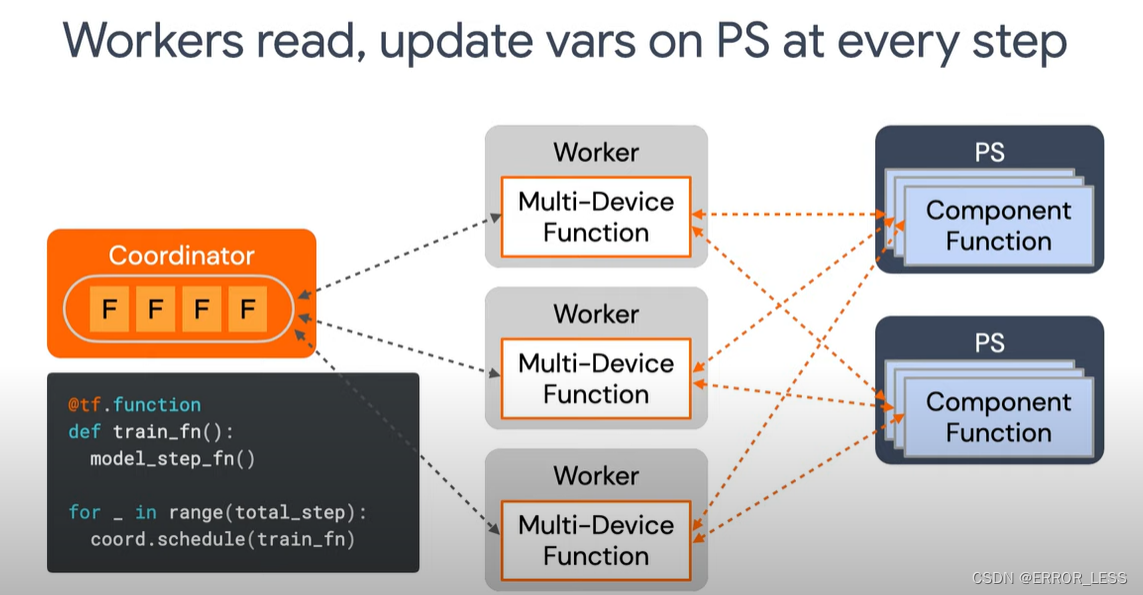
coordinator调度tf.function在远程worker上执行,worker通过从coordinator那获得的请求读取并处理从ps那传过来的变量并更新后传到ps上。每台worker只处理来自coordinator的请求并且只和ps进行通信,不和集群中的其他worker通信。
coordinator实例的使用场景
- 自定义训练时,必须创建coordinator实例
- 而使用
Model.fit时,输入部分只支持tf.keras.utils.experimental.DatasetCreator
节点coordinator的创建流程
- 自定义训练
# Prepare a strategy to use with the cluster and variable partitioning info.
# 准备ps策略来使用集群和变量分片信息
strategy = tf.distribute.experimental.ParameterServerStrategy(
cluster_resolver=..., # 集群解析器
variable_partitioner=...) # 变量分片器
#创建coordinator实例
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(
strategy=strategy)
# Prepare a distribute dataset that will place datasets on the workers.
# 准备一个将布置到workers中的分布式数据集
distributed_dataset = coordinator.create_per_worker_dataset(dataset_fn=...)
with strategy.scope():
model = ...
optimizer, metrics = ... # Keras optimizer/metrics are great choices
checkpoint = tf.train.Checkpoint(model=model, optimizer=optimizer)
checkpoint_manager = tf.train.CheckpointManager(
checkpoint, checkpoint_dir, max_to_keep=2)
# `load_checkpoint` infers initial epoch from `optimizer.iterations`.
initial_epoch = load_checkpoint(checkpoint_manager) or 0
@tf.function
def worker_fn(iterator):
def replica_fn(inputs):
batch_data, labels = inputs
# calculate gradient, applying gradient, metrics update etc.
strategy.run(replica_fn, args=(next(iterator),))
for epoch in range(initial_epoch, num_epoch):
distributed_iterator = iter(distributed_dataset) # Reset iterator state.
for step in range(steps_per_epoch):
# Asynchronously schedule the `worker_fn` to be executed on an arbitrary
# worker. This call returns immediately.
coordinator.schedule(worker_fn, args=(distributed_iterator,))
# `join` blocks until all scheduled `worker_fn`s finish execution. Once it
# returns, we can read the metrics and save checkpoints as needed.
coordinator.join()
logging.info('Metric result: %r', metrics.result())
train_accuracy.reset_states()
checkpoint_manager.save()
- model.fit
# Prepare a strategy to use with the cluster and variable partitioning info.
# 注意无须创建coordinator实例
strategy = tf.distribute.experimental.ParameterServerStrategy(
cluster_resolver=...,
variable_partitioner=...)
# A dataset function takes a `input_context` and returns a `Dataset`
# 后面的DatasetCreator API需要用到
def dataset_fn(input_context):
dataset = tf.data.Dataset.from_tensors(...)
return dataset.repeat().shard(...).batch(...).prefetch(...)
# With `Model.fit`, a `DatasetCreator` needs to be used.
# 只能用这个API
input = tf.keras.utils.experimental.DatasetCreator(dataset_fn=...)
with strategy.scope():
model = ... # Make sure the `Model` is created within scope.
model.compile(optimizer="rmsprop", loss="mse", steps_per_execution=..., ...)
# Optional callbacks to checkpoint the model, back up the progress, etc.
callbacks = [tf.keras.callbacks.ModelCheckpoint(...), ...]
# `steps_per_epoch` is required with `ParameterServerStrategy`.
# `steps_per_epoch`这个参数是必须的
model.fit(input, epochs=..., steps_per_epoch=..., callbacks=callbacks)
使用keras的高阶API
Model.fit进行训练的注意事项
- 输入数据可以有3中形式:
tf.data.Dataset、tf.distribute.DistributedDataset、tf.keras.utils.experimental.DatasetCreator(推荐)。 - 如果将数据集转换为
tf.data.Dataset输入,则需要使用Dataset.shuffle,Dataset.repeat进行处理Dataset.shuffle是用来打乱数据集的,以确保每个worker可以更均匀地进行迭代训练Dataset.repeat是在没有参数调用时无限重复数据集。因为worker训练不同步,他们可能会在不同的时间完成数据集的处理。
- 回调与检查点
tf.keras.callbacks.ModelCheckpoint:以特定频率保存模型tf.keras.callbacks.BackupAndRestore:当某个节点中断后,保存备份当前模型和训练轮数,以便后续继续训练。tf.keras.callbacks.TensorBoard:在TensorBoard可视化插件中查看模型的日志信息。
需要注意的是:ps策略不能保存batch level的检查点,应修改为epoch level的检查点,并且把参数steps_per_epoch的值调整到一个合适的值。
- 即使使用了
Model.fitAPI也可以考虑初始化一个ClusterCoordinator实例来调度其他函数在workers上执行。
tf.keras.utils.experimental.DatasetCreator是什么?
调用此API可以返回生成的一个数据集,经常是使用CPU进行计算。
在Model.fit 中的参数steps_per_epoch是必须的
evaluator是干啥用的?
可选择用或者不用。evaluator是独立于集群之外,在旁边(side)进行评估的一个模型,可以周期性地读取coordinator保存的检查点并再次运行进行评估。
evaluator不需要知道训练集群的设置,即使知道也不能尝试去链接到训练集群。
创建变量分布的范围
在strategy.scope()中创建的变量将会自动部署到ps上,否则在此之外创建的变量会被部署到coordinator上。
变量分片相关
推荐使用tf.distribute.experimental.partitioners.MinSizePartitionerAPI,是一个用于设置每个分片最小的size的分片器。
tf.distribute.experimental.partitioners.MinSizePartitioner(
min_shard_bytes=(256 << 10), # 每个分片最小的字节数,默认为256k
max_shards=1, # 分片数量的上界
bytes_per_string=16 # 若分片的数据是string类型,则评估一下这个字符串有多长
)
下面是应用:
# Partition the embedding layer into 2 shards.
# 将(1024, 1024)分片为两个(512, 1024)
variable_partitioner = (
tf.distribute.experimental.partitioners.MinSizePartitioner(
min_shard_bytes=(256 << 10),
max_shards = 2))# 分片的数量为2
strategy = tf.distribute.experimental.ParameterServerStrategy(
cluster_resolver=...,
variable_partitioner = variable_partitioner)
with strategy.scope():
embedding = tf.keras.layers.Embedding(input_dim=1024, output_dim=1024)
assert len(embedding.variables) == 2
assert isinstance(embedding.variables[0], tf.Variable)
assert isinstance(embedding.variables[1], tf.Variable)
assert embedding.variables[0].shape == (512, 1024)
assert embedding.variables[1].shape == (512, 1024)
数据准备相关
def dataset_fn():
filenames = ...
dataset = tf.data.Dataset.from_tensor_slices(filenames)
# Dataset is recommended to be shuffled, and repeated.
# 推荐被打乱和重复
return dataset.shuffle(buffer_size=...).repeat().batch(batch_size=...)
coordinator =
tf.distribute.experimental.coordinator.ClusterCoordinator(strategy=...)
distributed_dataset = coordinator.create_per_worker_dataset(dataset_fn)
注意:当使用 Model.fit, tf.distribute.experimental.ParameterServerStrategy 时,必须指定 tf.keras.utils.experimental.DatasetCreator,和参数 steps_per_epoch。
fit(
x=None, # 输入的数据。一般来说支持数组、张量等,但当使用了ps策略后,就只支持DatasetCreator了
y=None, # 目标数据。当x指定后,y无须指定
batch_size=None, # 默认32
epochs=1, # 模型训练的轮数
verbose='auto', # auto在使用ps策略时默认为2=one line per epoch
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
设置模型参数以供训练
compile(
optimizer='rmsprop', # 优化器,常见的有Adam、SGD等
loss=None, # 损失函数值。常见的有二元交叉熵(BinaryCrossentropy),绝对交叉熵(CategoricalCrossentropy),稀疏分类交叉熵(SparseCategoricalCrossentropy)等
metrics=None, # 典型的是metrics=['accuracy']
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None, # 指定每一次训练所使用的批次数
jit_compile=None,
**kwargs
)
ParameterStrategy策略存在的局限
os.environment["grpc_fail_fast"]="use_caller"在worker、ps和coordinator上都应该设置,以达到合适的故障容错效果。- 同步训练在ps策略中是不支持的
- 经常需要把很多steps打包成一个函数来实现最佳效果(ctl)
- 不重启coordinator task的haul,集群不会从ps的错误中恢复过来
- 变量创建等应放在
Strategy.scope中,否则会在coordinator上创建。
2 视频初了解
2.1 知识获取
视频链接在此
out-of-the-box:开箱即用,无须另外配置
什么时候需要使用ParameterServerStrategy?
- 异步训练
- 大数据集输入
- 工作节点经常被其他线程所占用,可调用的资源不多。
tf2自定义训练支持的API:coordinator.schedule()和coordinator.join()方法。

2.2 代码修改
原始代码:Model.fit+MirroredStrategy

第一步:替换分布式策略为PS

3 官方视频教程
- 在TF1中,都是采用
Multi-Client Setup,造成多个worker之间很难协调,造成混乱;TF2中采用Single-Client Setup,只需要从Coordinator中获取变量。


- 测试起来非常方便,因为可以在一台机器上进行测试。
- 需要定义一个
coordinator,具体作用暂未知。—>client - 数据并行,矩阵串联计算

workers:ps最好为2:1,或接近- in runtime
1 项目实践
1.1 项目1
参考GitHub项目
出错:

1.2 项目2
参考github项目
貌似需要多台机器,像视频里边那样开多个桌面,连接网段相同最后一段不同的局域网,不知道怎么操作,暂时搁浅一段时间吧。
具体实战见下篇文章















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









