






设需要编码的字符集为{d1,d2,..., dn}它们出现的频率为{w1,w2,...,wn},应用哈夫曼树构造最短的不等长编码方案。
实验目的
(1)了解前缀编码的概念,理解数据压缩的基本方法
(2) 掌握最优子结构性质的证明方法
(3) 掌握贪心法的设计思想并能熟练运用
3.实验要求
(1) 证明哈夫曼树满足最优子结构性质;
(2) 设计贪心算法求解哈夫曼编码方案
(3) 设计测试数据,写出程序文档。
实验项目——哈夫曼编码
题目复述:
设需要编码的字符集为{d1,d,2..., dn}它们出现的频率为{w1,w2,...,wn},应用哈夫曼树构造最短的不等长编码方案。
- 证明哈夫曼树满足最优子结构性质
首先,对于哈夫曼树的定义和性质:
1.夫曼树是一种具有最小带权路径长度的树。
2.哈夫曼树是一种最优前缀编码树,即字符出现频率越高的字符离根节点越近,从而可以用较短的编码表示高频字符,实现数据的压缩。
假设存在一个子树S不是哈夫曼树。考虑S的叶子节点集合P(P为S的所有叶子节点)和叶子节点集合Q(Q为整个哈夫曼树的所有叶子节点)。根据哈夫曼树的性质,P中的节点离根节点的路径长度必定小于等于Q中的节点离根节点的路径长度。如果将S替换为Q中路径长度最长的子树,记为S'。但由于P中的节点离根节点的路径长度小于等于Q中的节点离根节点的路径长度,所以S'的路径长度必定大于S。
然而,由于哈夫曼树是一种具有最小带权路径长度的树,S'作为哈夫曼树的子树必须满足最小带权路径长度的条件。这意味着S'的路径长度必定小于等于S。所以假设导致了矛盾,因此任意一个子树也是哈夫曼树,即哈夫曼树满足最优子结构性质,证明完毕。
- 设计贪心算法求解哈夫曼编码方案
- 树结构的定义
class Node:
#树结构定义
def __init__(self, char, weight):
self.char = char # 字符
self.weight = weight # 权重
self.left = None # 左子节点
self.right = None # 右子节点
2.构建哈夫曼树
给定节点名称和节点权重(在编码中可理解为信号频率),通过贪心算法(每次找到当前环境中最小的两个点)构建哈夫曼树并返回。
def begain(chars,weights):
#根据贪心思想,返回哈夫曼树
# chars = ['d1', 'd2', 'd3', 'd4']
# weights = [2, 6, 8, 4]
nodes = []
for i in range(len(chars)):
nodes.append(Node(chars[i], weights[i]))
while len(nodes) > 1:
# 按权重排序
nodes = sorted(nodes, key=lambda x: x.weight)
# 取最小的两个节点
left_node = nodes.pop(0)
right_node = nodes.pop(0)
# 创建新节点作为它们的父节点
parent_node = Node(None, left_node.weight + right_node.weight)
parent_node.left = left_node
parent_node.right = right_node
# 将新节点加入节点列表
nodes.append(parent_node)
root = nodes[0] # 哈夫曼树的根节点
return root
3.根据哈夫曼树得到哈夫曼编码
code_table = {}
def generate_huffman_code(node, code):
#根据哈夫曼树得到哈夫曼编码
if node.char is not None:
code_table[node.char] = code
else:
generate_huffman_code(node.left, code + '0')
generate_huffman_code(node.right, code + '1')
4.简单测试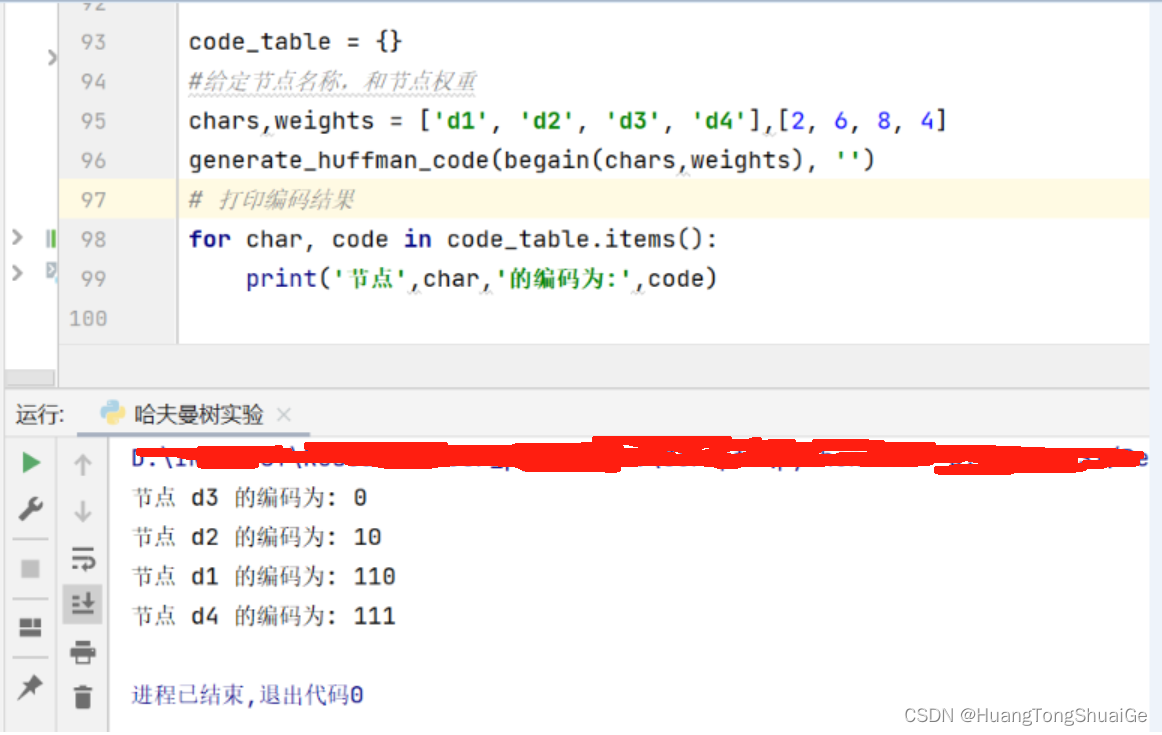
- 设计测试数据,写出程序文档。
- 设计一个函数返回随机选的点和对应权重。这里我设置了最多12个叶子简单的选择。随机选择1-100的权重,同时有百分之20的几率会使得两个点的权重相同。具体如下:
def retruninstant():
import numpy as np
nodes_name = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'M']
chose_nodes = np.random.choice(nodes_name,size=np.random.choice([5,len(nodes_name)],size=1),replace=False)
chose_nodes_weight=[]
for i in chose_nodes:
#为每一个点初始化一个权重
if np.random.choice(range(1,11),size=1) in [1,2]:#百分之30的几率选一个重复的权重
if len(chose_nodes_weight)!=0:
chose_nodes_weight.append(np.random.choice(chose_nodes_weight,size=1)[0])
else:
chose_nodes_weight.append(np.random.choice(range(1,101),size=1)[0])
else:
chose_nodes_weight.append(np.random.choice(range(1, 101), size=1)[0])
print(chose_nodes,chose_nodes_weight)
return chose_nodes,chose_nodes_weight
返回类型为:
![]()
2.测试案例使用上述程序生成的10个测试案例:
tests=[]
for i in range(10):
test_node,tests_weight=retruninstant()
tests.append([test_node,tests_weight])
得到测试集合为:

3.使用测试集,结合上述程序,得到结果:
for j in tests:
code_table = {}
#给定节点名称,和节点权重
chars,weights = j[0],j[1]
generate_huffman_code(begain(chars,weights), '')
# 打印编码结果
print(code_table)
结果:
{'C': '00', 'B': '01', 'D': '10000', 'M': '10001', 'G': '1001', 'H': '101', 'I': '110', 'J': '1110', 'K': '11110', 'A': '111110', 'E': '1111110', 'F': '1111111'}
{'E': '00', 'H': '01', 'I': '10', 'M': '110', 'C': '111'}
{'K': '00', 'M': '01', 'C': '10', 'B': '110', 'H': '111'}
{'D': '000', 'M': '001', 'F': '0100', 'B': '0101', 'A': '011', 'K': '100', 'I': '101', 'J': '110', 'H': '111000', 'E': '111001', 'C': '11101', 'G': '1111'}
{'A': '000', 'K': '001', 'D': '010', 'H': '011', 'I': '100', 'J': '1010', 'F': '1011', 'M': '1100', 'C': '1101', 'E': '1110', 'G': '11110', 'B': '11111'}
{'K': '000', 'G': '0010', 'H': '0011', 'D': '01', 'B': '1'}
{'J': '00', 'C': '010', 'H': '011', 'K': '10', 'I': '11'}
{'H': '000', 'J': '001', 'C': '010', 'K': '011', 'B': '100', 'E': '10100', 'I': '10101', 'M': '1011', 'G': '1100', 'A': '1101', 'D': '1110', 'F': '1111'}
{'H': '000', 'E': '001', 'J': '010', 'D': '011', 'F': '100', 'B': '10100', 'M': '10101', 'A': '1011', 'I': '1100', 'K': '1101', 'G': '1110', 'C': '1111'}
{'F': '000', 'E': '001', 'C': '010', 'A': '0110000', 'M': '0110001', 'G': '011001', 'J': '011010', 'H': '011011', 'D': '0111', 'K': '10', 'I': '110', 'B': '111'}
完整代码:
class Node:
#树结构定义
def __init__(self, char, weight):
self.char = char # 字符
self.weight = weight # 权重
self.left = None # 左子节点
self.right = None # 右子节点
def generate_huffman_code(node, code):
#根据哈夫曼树得到哈夫曼编码
if node.char is not None:
code_table[node.char] = code
else:
generate_huffman_code(node.left, code + '0')
generate_huffman_code(node.right, code + '1')
def begain(chars,weights):
#根据贪心思想,返回哈夫曼树
# chars = ['d1', 'd2', 'd3', 'd4']
# weights = [2, 6, 8, 4]
nodes = []
for i in range(len(chars)):
nodes.append(Node(chars[i], weights[i]))
while len(nodes) > 1:
# 按权重排序
nodes = sorted(nodes, key=lambda x: x.weight)
# 取最小的两个节点
left_node = nodes.pop(0)
right_node = nodes.pop(0)
# 创建新节点作为它们的父节点
parent_node = Node(None, left_node.weight + right_node.weight)
parent_node.left = left_node
parent_node.right = right_node
# 将新节点加入节点列表
nodes.append(parent_node)
root = nodes[0] # 哈夫曼树的根节点
return root
def retruninstant():
import numpy as np
nodes_name = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'M']
chose_nodes = np.random.choice(nodes_name,size=np.random.choice([5,len(nodes_name)],size=1),replace=False)
chose_nodes_weight=[]
for i in chose_nodes:
#为每一个点初始化一个权重
if np.random.choice(range(1,11),size=1) in [1,2]:#百分之30的几率选一个重复的权重
if len(chose_nodes_weight)!=0:
chose_nodes_weight.append(np.random.choice(chose_nodes_weight,size=1)[0])
else:
chose_nodes_weight.append(np.random.choice(range(1,101),size=1)[0])
else:
chose_nodes_weight.append(np.random.choice(range(1, 101), size=1)[0])
print(chose_nodes,chose_nodes_weight)
return chose_nodes,chose_nodes_weight
tests=[]
for i in range(10):
test_node,tests_weight=retruninstant()
tests.append([test_node,tests_weight])
for j in tests:
code_table = {}
#给定节点名称,和节点权重
chars,weights = j[0],j[1]
generate_huffman_code(begain(chars,weights), '')
# 打印编码结果
print(code_table)














 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









