






前言:
整个活,本人平时喜欢听歌,但奈何每月十元大洋的会员顶我一餐饭,我觉得不值,所以啊,就要稍微去弄点歌来听听,具体咋弄,我们来聊聊!
ps:楼上三首歌算我请大家的

流程分析:
* 简单来讲会涉及一个资源平台,然后在上面获取音频,需要有歌曲网址接口,音频接口和音频id这几个重要内容。
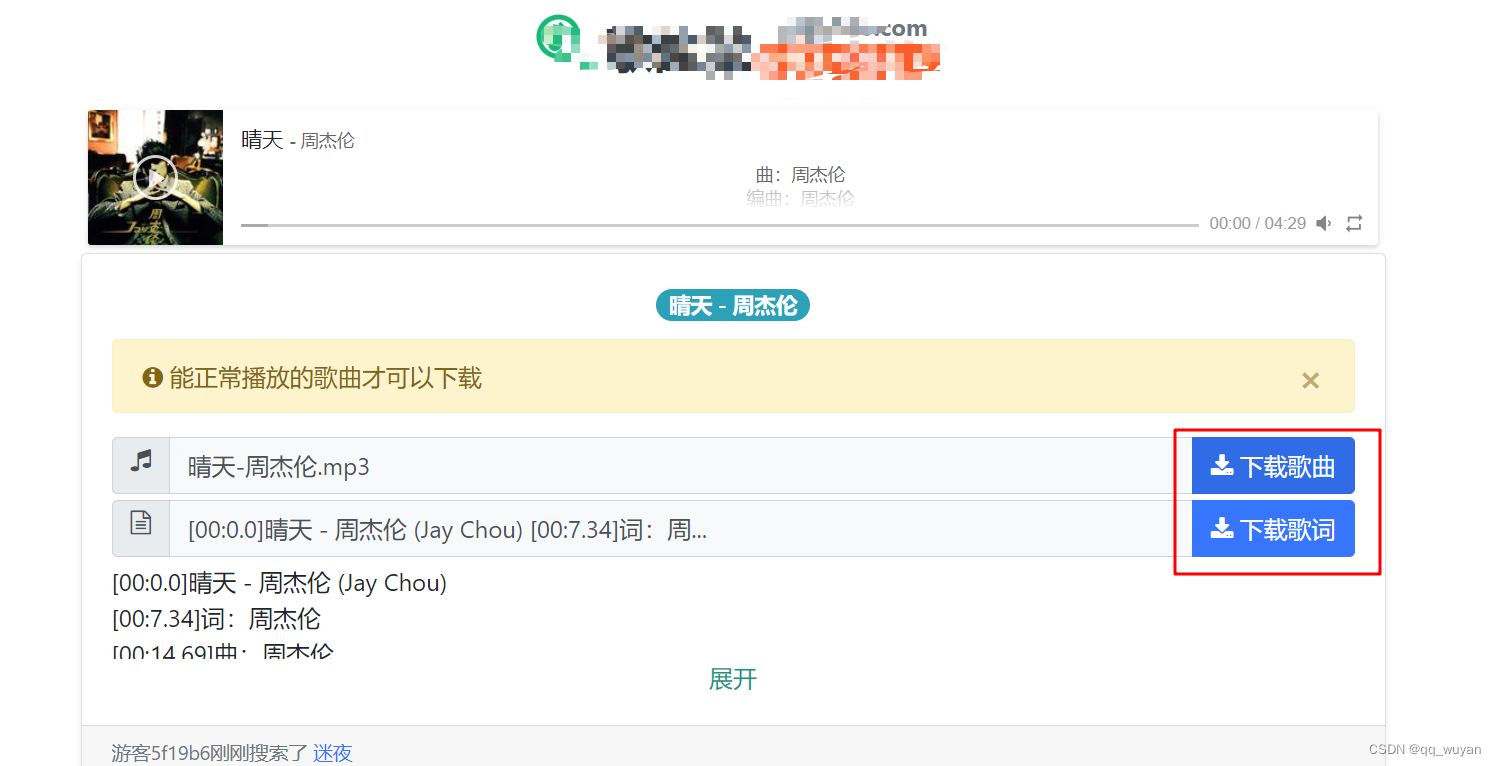
爬虫基本流程:
一、明确需求
1.请求网址:https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6
2.请求目标:歌曲mp4音频链接
二、抓包分析
1.发送请求:模拟浏览器向网址url地址进行请求访问
- url:https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6
2.获取数据:得到数据响应内容
3.解析数据:提取歌曲名称/歌手/id
4.发送请求:模拟浏览器向歌曲url地址进行请求访问
- url:https://www.gequbao.com/api/play_url?id=402856&json=1
5.获取数据:得到数据响应内容
6.解析数据:提取歌曲链接
7.保存数据:保存到本地
代码编写:
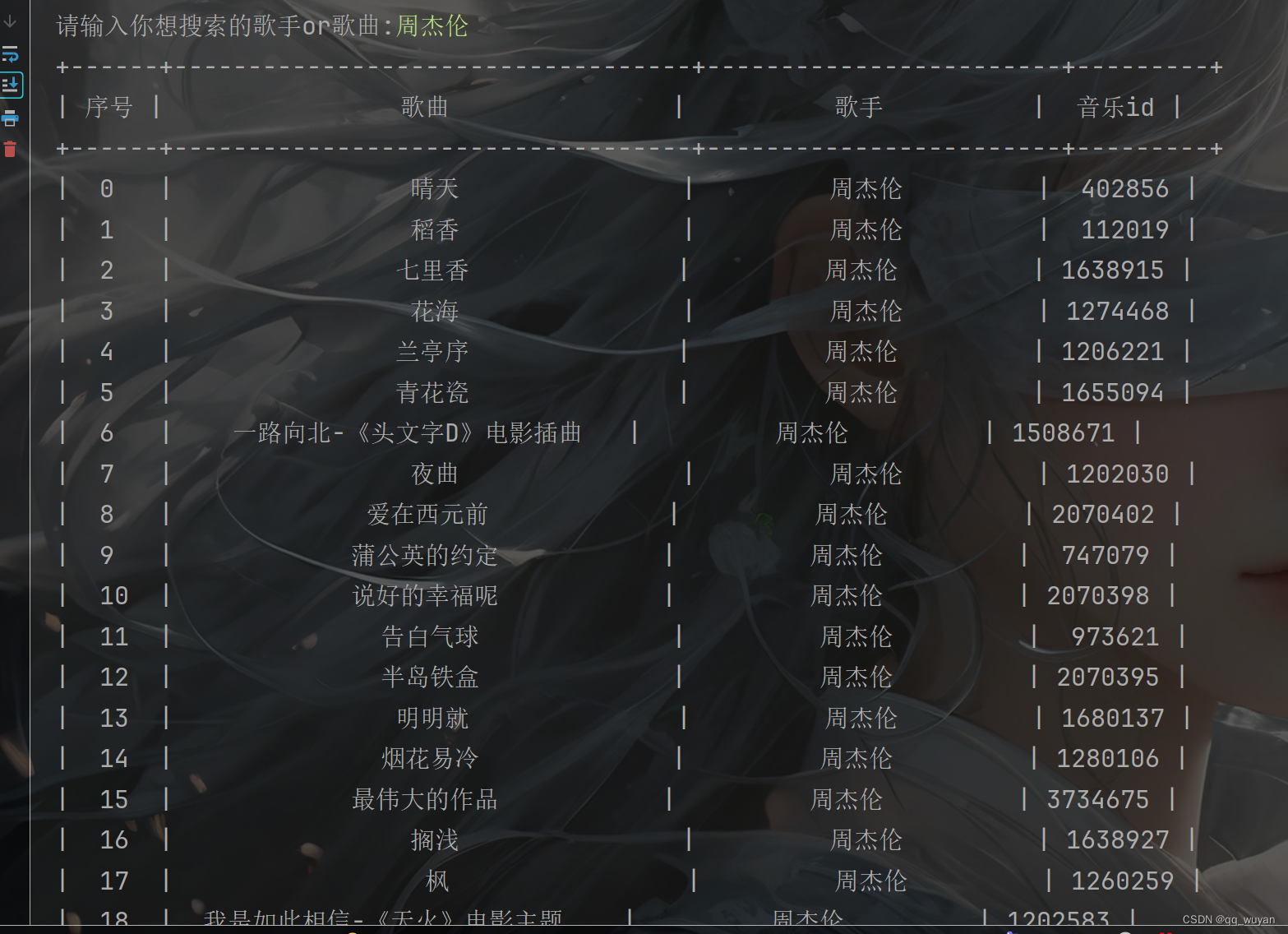
①歌曲网址接口,提取歌曲id和歌曲名称
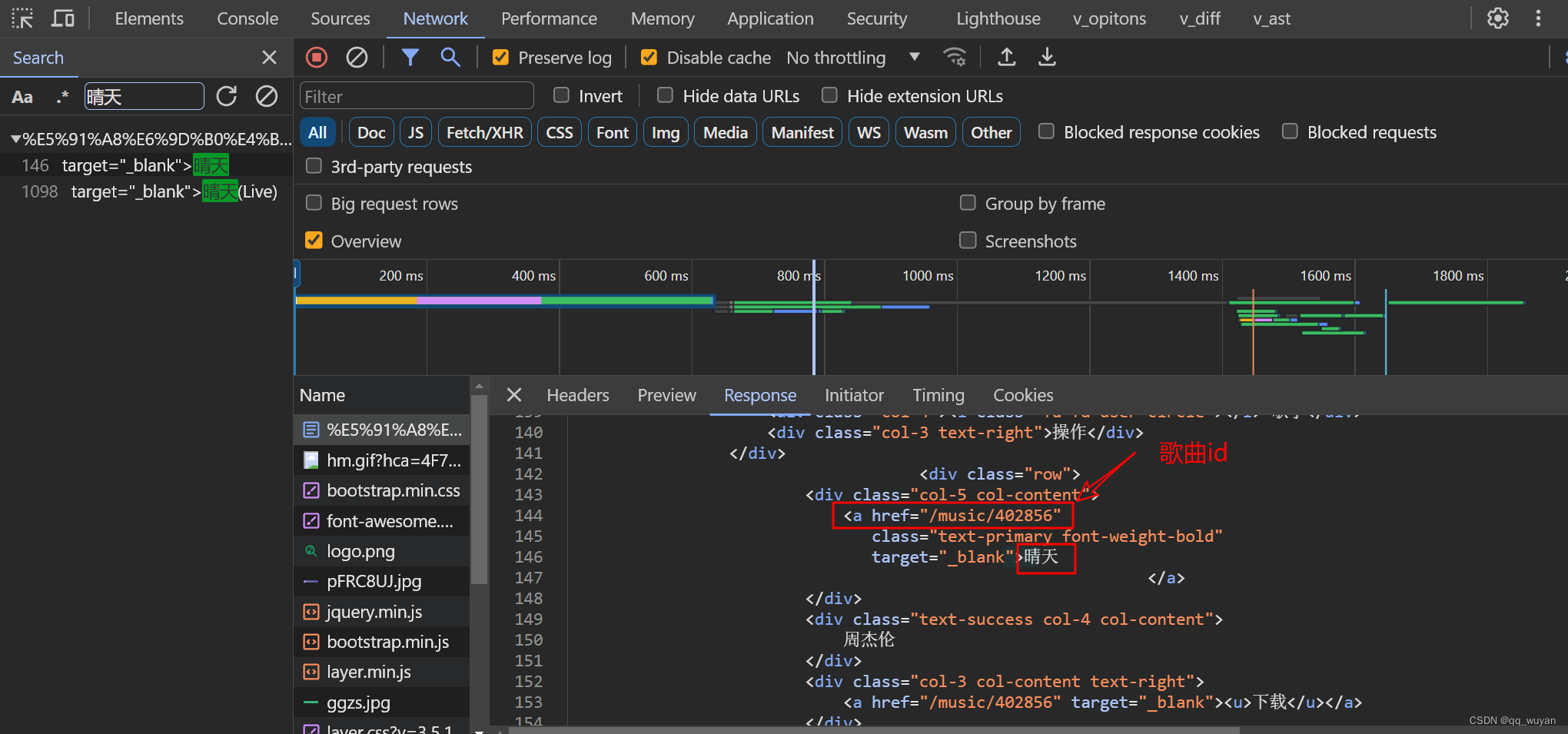
构建一个基本请求做提取,将拿到的内容进行数据清洗去重
import requests
from parsel import Selector
headers = {}
cookies = {}
url = "https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6"
response = requests.get(url, headers=headers, cookies=cookies)
print(response)
selector = Selector(response.text)
rows = selector.css('.card-text .row')[1:]
for row in rows:
title = row.css('.text-primary::text').get().strip()
name = row.css('.text-success::text').get().strip()
music_id = row.css('.col-5 a::attr(href)').get().split('/')[-1]
print(title, name, music_id)②提取歌曲链接,拼接网址
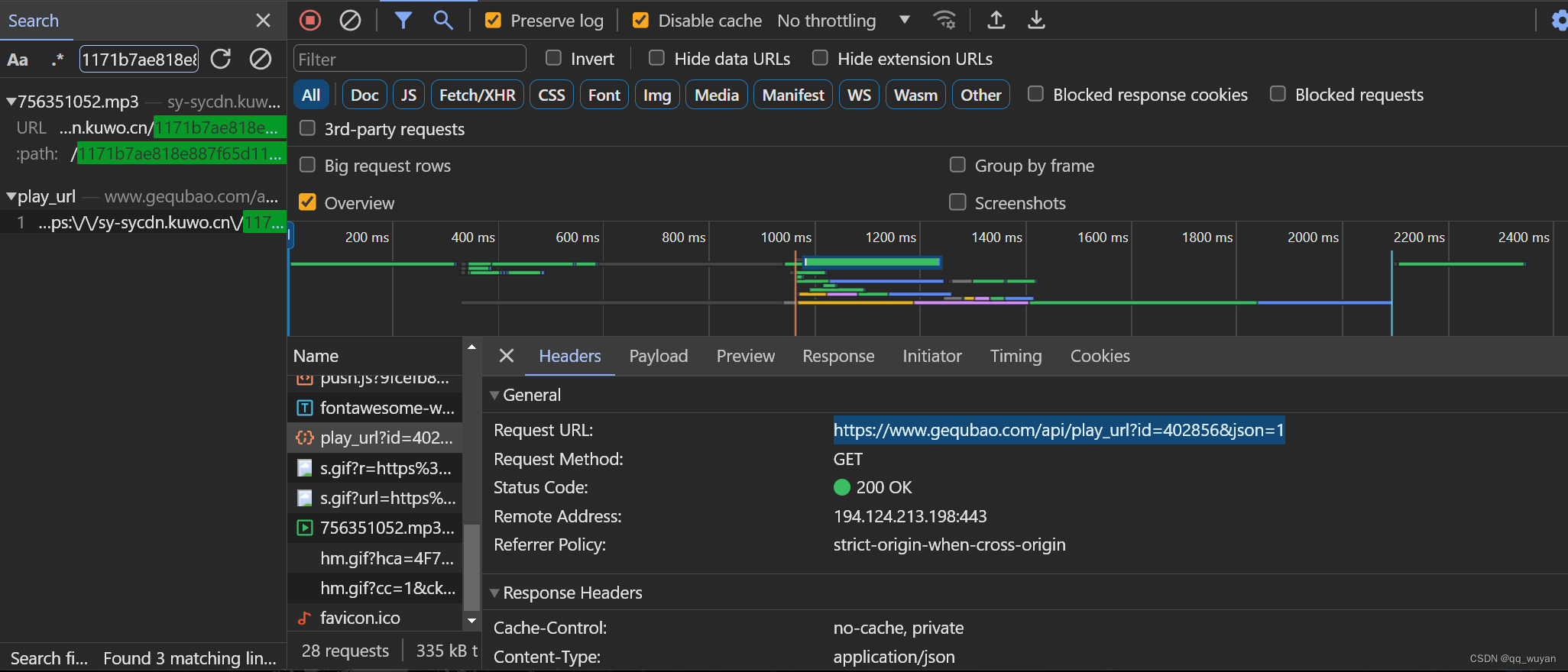
直接就完美搞定啦!!
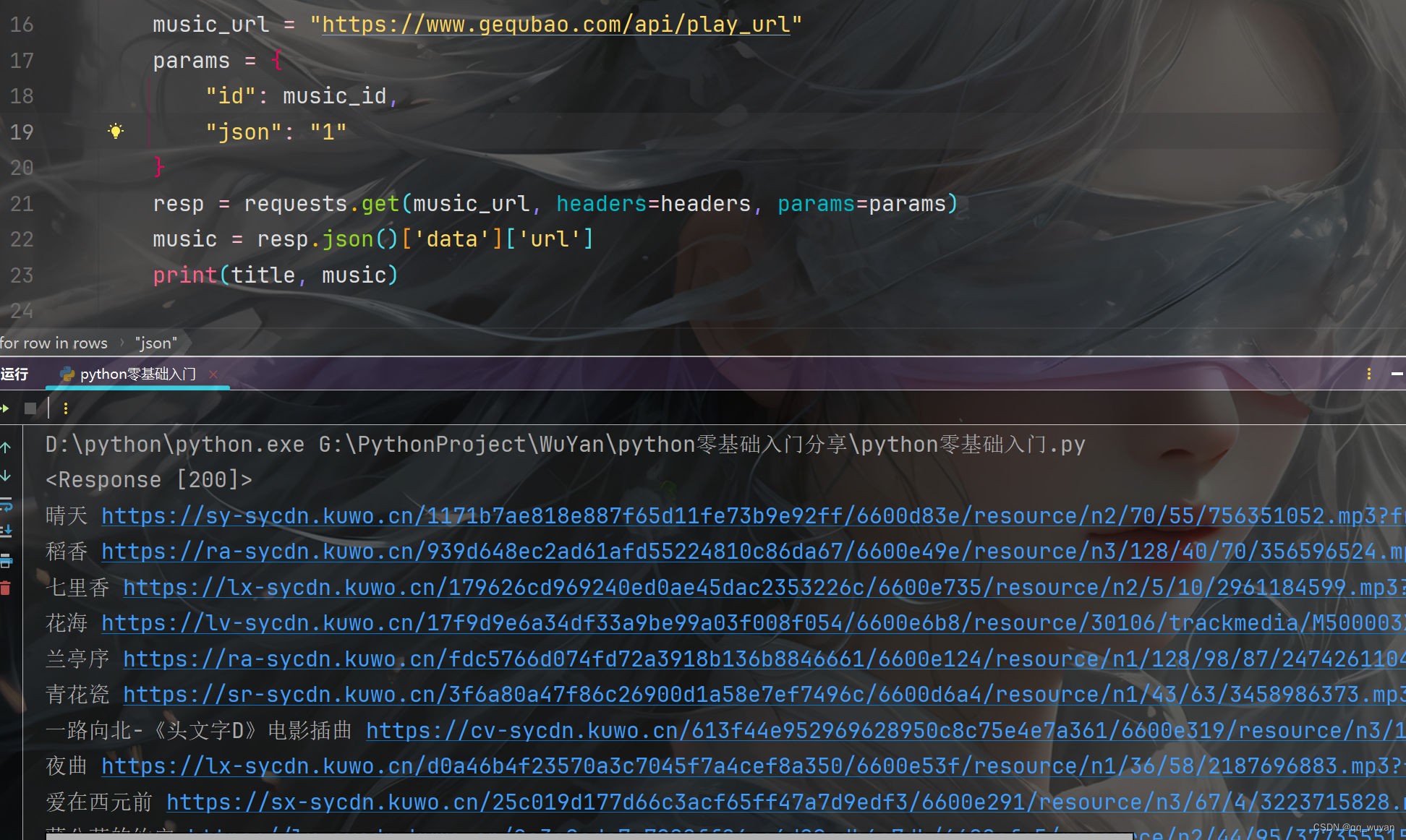
总结:
适合新手入门的小案例,感兴趣的朋友可以一试!后面给他做了个小升级,完整的程序可以私信


















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









