






原子操作
在前面的学习中我们知道gpu中有多种存储单元,每个线程对于不同的存储单元具备不同的权限,当对于我们而言,有时需要不同线程对同一个变量进行操作,由此我们引出了原子操作。
原子操作就是对存在于global memory或者shared memory进行”读取-修改-写入“的一个最小单位的执行过程。在一个线程对共享变量进行原子操作时,其他并行线程是不能进行读取-写入操作的,继而实现了多线程的互斥和变量保护,保证了原子操作的正确性。
原子操作function
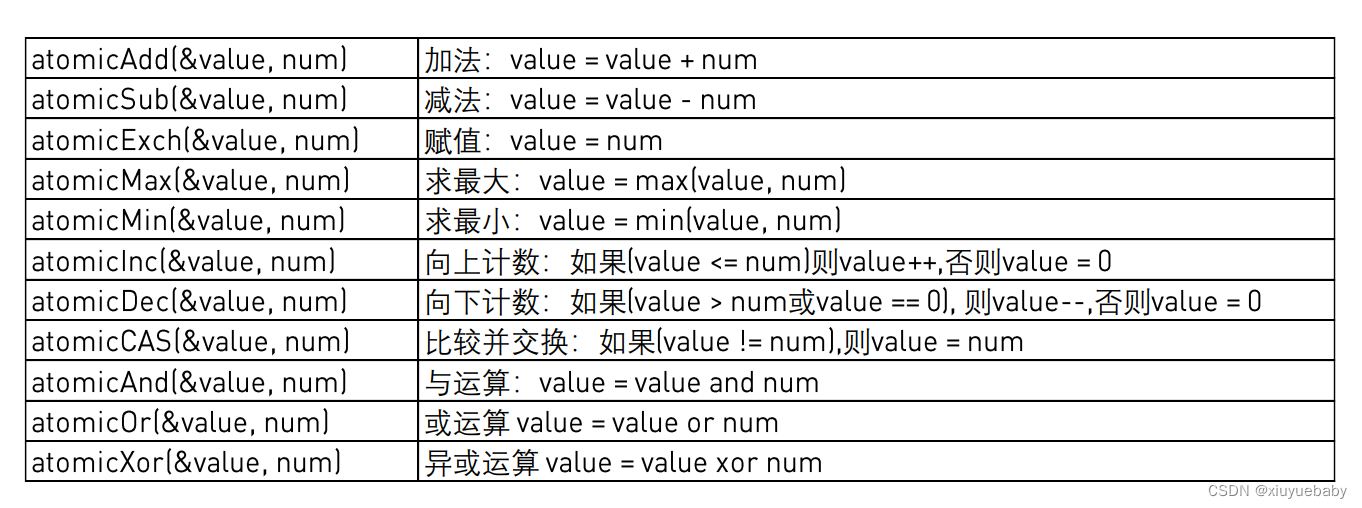
对于函数的详细讲解可以参考樊老师的文章:cuda原子操作详解
实验示例
我们基于jetson nano平台,使用一个求和的示例来学习原子操作:
首先我们申请32个block,每个block中有256个核心,以此来取得运行速度和效率的平衡:
int main()
{
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
//Now we are going to kick start your kernel.
cudaDeviceSynchronize(); //steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
_sum_gpu<<<BLOCKS, BLOCK_SIZE>>>(source, N, final_result);
CHECK(cudaGetLastError()); //checking for launch failures
CHECK(cudaDeviceSynchronize()); //checking for run-time failurs
double t1 = get_time();
int A = final_result[0];
fprintf(stderr, "GPU sum: %u\n", A);
//**********************************
//Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int B = _sum_cpu(source, N);
double t3 = get_time();
fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
if (A == B)
{
fprintf(stderr, "Test Passed!\n");
}
else
{
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}
按照以往cpu的办法,我们直接串行累加即可完成
int _sum_cpu(int *ptr, int count)
{
int sum = 0;
for (int i = 0; i < count; i++)
{
sum += ptr[i];
}
return sum;
}而在gpu中,我们对其的并行相加采用的思路是:
- 对于超大的数组,我们采用前面学习中类似滑动窗口的思路,在每个线程中向进行一次相加,确保进入并行计算的第一轮的总数据量不大于我们所申请的总线程数,即保证不超出share memory大小,也能够将所有数据存储到share memeory中,降低访问数据的时间。
- 每次循环都将share memory中input_num[x]于input_num[x+blockDimx.x/(2^n)](n为第多少轮),直到相加到所需要计算的长度为1时将其输出到位于share memory或global memory的output中。
- 使用原子操作atomicAdd(&num,output[blockIdx.x],对output数组中的数据进行求和,这里我自己认为原子操作本质上面还是串行的,前面加法的过程时部分并行。
__global__ void _sum_gpu(int *input, int count, int *output)
{
__shared__ int sum_per_block[BLOCK_SIZE];
int temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x
)
{
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp; //the per-thread partial sum is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int double_kill = -1;
if (threadIdx.x < length)
{
double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
sum_per_block[threadIdx.x] = double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
if (threadIdx.x == 0) atomicAdd(output, sum_per_block[0]);
}
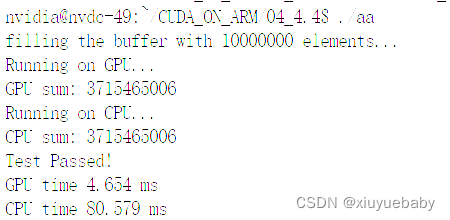
}由此我们完成了使用gpu并行的对数据进行求和,通过实验结果可以看到大大提高的运算速度:
完整代码
#include<stdio.h>
#include<stdint.h>
#include<time.h> //for time()
#include<stdlib.h> //for srand()/rand()
#include<sys/time.h> //for gettimeofday()/struct timeval
#include"error.cuh"
#define N 10000000
#define BLOCK_SIZE 256
#define BLOCKS 32
__managed__ int source[N]; //input data
__managed__ int final_result[1] = {0}; //scalar output
__global__ void _sum_gpu(int *input, int count, int *output)
{
__shared__ int sum_per_block[BLOCK_SIZE];
int temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x
)
{
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp; //the per-thread partial sum is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int double_kill = -1;
if (threadIdx.x < length)
{
double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
sum_per_block[threadIdx.x] = double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
if (threadIdx.x == 0) atomicAdd(output, sum_per_block[0]);
}
}
int _sum_cpu(int *ptr, int count)
{
int sum = 0;
for (int i = 0; i < count; i++)
{
sum += ptr[i];
}
return sum;
}
void _init(int *ptr, int count)
{
uint32_t seed = (uint32_t)time(NULL); //make huan happy
srand(seed); //reseeding the random generator
//filling the buffer with random data
for (int i = 0; i < count; i++) ptr[i] = rand();
}
double get_time()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);
}
int main()
{
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
//Now we are going to kick start your kernel.
cudaDeviceSynchronize(); //steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
_sum_gpu<<<BLOCKS, BLOCK_SIZE>>>(source, N, final_result);
CHECK(cudaGetLastError()); //checking for launch failures
CHECK(cudaDeviceSynchronize()); //checking for run-time failurs
double t1 = get_time();
int A = final_result[0];
fprintf(stderr, "GPU sum: %u\n", A);
//**********************************
//Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int B = _sum_cpu(source, N);
double t3 = get_time();
fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
if (A == B)
{
fprintf(stderr, "Test Passed!\n");
}
else
{
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}
总结
原子操作为我们多线程操作同一个变量给出了解决方案,也在保证每个线程相互独立的前提下,让每个线程间数据交互有了更快捷的路径,实验示例中求和的优化思路,对于我来说也是一种新颖的尝试,拓宽了今后优化的代码的思路。















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









