







基于地域和热度的推荐算法
下面以新闻为例说明热度算法的基本原理。
在一则新闻录入数据库后, 初始化一个热度分(S0), 此时该新闻就进入了新闻推荐的候选池。
(1) 随着新闻不断被用户点击 (click) 、转发 (share) 、关注 (follow) 、评论 (comment) 、 点赞 (up) 等, 对应的和用户交互维度的热度 (S1) 不断增加。
**(2)**另外, 新闻要求具有时效性, 因此在新闻发布后, 热度(S2)会随着时间衰减。随着时间的后移,新闻的热度不断发生变化,对应的推荐抽选池排序也在不断地发生变化.
最终新闻热度对应的计算公式为:
S=S0+S1-S2
实际情况下, 需要考虑的因素还有很多, 但这里遵循的原则是: 正向的因素做加法, 负向的因素做减法。
但这里有三个问题:
1. 新闻的初始热度应该不一致
在上式中, 为每一条入库的新闻赋予了相同的初始化热度, 但这并不符合实际情况,因为:
(1) 不同类别的新闻本身的社会传播度不同, 如娱乐类的新闻更容易被大众所接受。
(2) 不同时期, 人们对新闻的需求程度也不同。 例如, 在新的 iPhone 发布时, 和 iPhone相关的新闻热度就比较大;在奥运会期间, 和体育相关的新闻热度就比较大。
因此, 在初始化新闻的初始热度时需要考虑以下两点:
(1)不同类别的新闻初始热度权重应该不同。 至于每种类别的新闻的权重应该是多少, 可以对历史数据进行统计, 进而得出相应的比例。 最终的结果应该类似下图所示的权重分布 (图中比例仅做举例使用)。
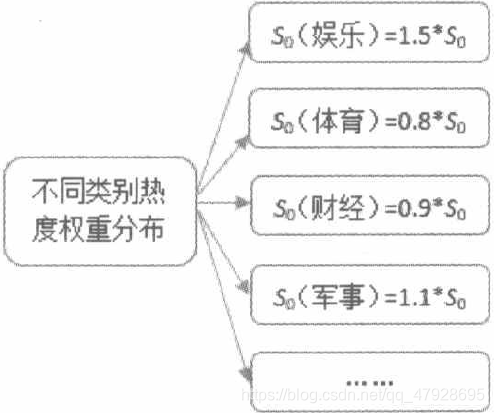
不同类别新闻对应的权重分布
(2)不同时间段的热门新闻应该有不同的初始权重。 在新闻进入推荐候选池时, 进行人工审核, 如果是热点新闻则赋予较大的权重。 另外一种做法是一维护一个热点词库: 当新发表新闻时, 与热点词库进行匹配, 匹配度越高则初始化的热度值就越大。
2. 用户的行为规则应该发生变化
用户与新闻的交互是导致新闻热度增加的最主要因素, 常见交互行为有点击(click)、转发(share)、关注(follow)、评论(comment)、 点赞(up)。这里认为所 列出的5种行为均对提高新闻的热度值具有正向作用。 如果给它们都赋予相同的权重, 则S2的表达式为:
S2 = 0.2 × click + 0.2 × share + 0.2 × follow + 0.2 × comment + 0.2 × up
但在实际情况中, 不同行为所表达的用户对新闻的偏好程度并不一致。 直观地理解, 它们的占比大小是:
评论>转发>关注>点赞>点击 。
按照比例给不同的交互行为赋予不同的权重, 改进的S2计算公式如下:
S2 = 0.05 × click + 0.3 × share + 0.15 × follow + 0.4 × comment + 0.
I × up
3.热度随时间衰减的趋势非线性
新闻具有实效性, 已经发布的新闻的热度会随着时间的流逝而衰减, 并且趋势是衰减得越来越快, 直到热度趋于0。 由此可以想到, 如果一条新闻要持续出现在推荐列表靠前的位置,则必须有越来越多的用户进行交互。
结合牛顿冷却定律, 新闻热度随时间的衰减是一个类似千指数增长的过程,公式如下式中,:
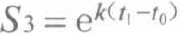
t0为新闻的发布时间, t1 为当前计算排序时的时间。
但考虑到新闻的热度最终是趋于0的, 所以将上式改为:
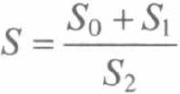
--------------------------------------------进入正题---------------------------------------
创建一个基于地域和热度的酒店推荐系统
在基于地域和热度的酒店推荐中,并不对用户的偏好进行区分,而是根据用户的位置信息, 结合不同的排序方式, 将用户位置附近的酒店推荐给用户。

北京部分酒店数据(注意数据形式)
这里选择的是某网站上北京的部分酒店数据, 数据获取方式为爬虫爬取。 酒店信息包含: 酒店名字、 所在地区、 具体地址、 评论数目、 评分、 电话号码、 装修时间、 开业时间、 最低价格。
基于地域和热度的酒店推荐系统实现思路如下:
(1) 加载并筛选出用户所在地区的数据;
(2) 根据指定的排序规则对数据进行排序;
(3) 将结果返回给用户。
主要实现酒店推荐, 根据用户所在的地区和所选择的排序方式返回相应的前k个酒 店数据。
- 数据集都取所在地址是北京的, 包含朝阳区、 丰台区、 东城区、 西城区、 海淀区、 顺义 区、 石景山区、 延庆区、 房山区、 通州区。
- 支持排序的字段有:评论数目、装修时间、开业时间、评分、最低价格,以及综合排序。
- 程序中通过type字段进行赋值。
- 排序方式分为升序和降序。
第一种:自定义排序,用户根据可选择的排序字段,返回前k个或者后k个值的排序,返回酒店名字和查看的字段排序后的k个值。
第二种:综合排序
“综合排序” 是对其余排序字段的线性整合。这里简单地定义了各个排序字段的权重,通过线性相加的方式计算出最后的总得分, 然后根据这个得分对酒店进行排序。
- 对“装修时间” 和 “开业时间” 做了差值处理。这里认为装修时间越久, 对最终的排 序越起到负向作用, 所以, 使用装修时间减去 2018 得到一个负值。 同理, 认为开业时间越久对 最终的排序越起到正向作用, 所以使用 2018 减去开业时间得到一个正值。
- 对参与计算的各个字段做归一化处理, 采用的是 min-max 归一化。
- 得到最终的 “ 综合排序” 的计算公式为:
Score= 1× 评分+2×评论数目+ 3× 装修时间+ 4× 开业时间+ 5× 最低价格
#代码思路:
import pandas
class RecomendHotel:
def __init__(self,path=None,address=None, type=['score'],k=10,sort=False):
self.path = path
self.address = address
self.type = type
self.k= k
self.sort = sort
self.data = self.hotel_mess()
def hotel_mess(self):
data =pd.read_csv(self.path,header=0,sep=",",encoding='GBK')
return data[data["addr"]==self.address]
def recomend(self):
data = self.data[['name',"score","comment_num","lowest_price","decoration_time","open_time"]] #取出需要的字段
if self.type in data.columns.tolist(): #判断用户需要查看的指标判断酒店
data = data.sort_values([self.type,"lowest_price"],ascending=self.sort)[:self.k] #根据用户输入的判断字段可以进行排序
return dict(data.filter(items=["name",self.type]).values) #返回酒店名字和排序后的字段
else:
if self.type=='combine': #用户选择综合评分
#过滤使用的信息
data = self.data.filter(items=["name","score","comment_num","decoration_time","open_time","lowest_price"])
#对装修时间做处理
data['decoration_time'] = data['decoration_time'].apply(lambda x: int(x)-2021)
#对开店时间做处理
data['open_time'] = data['open_time'].apply(lambda x: 2021 - int(x))
#数据归一化
for col in data.columns.tolist():
if col != 'name':
data[col] = (data[col] - data[col].min()) / (data[col].max() - data[col].min())
# 给予:评分的权重为1,评论数目权重为2,装修和开业时间权重为0.5,最低价权重为1.5
#给予不同的字段的权重,并将分数赋给combine综合字段
data[self.type]=1 * data["score"] + 2 * data["comment_num"] + \
3 * data["decoration_time"] + 4 * data["open_time"] + 5 * data["lowest_price"]
data = data.sort_values(by=self.type, ascending=self.sort)[:self.k]
return dict(data.filter(items=['name',self.type]).values) #返回综合评分的酒店名字和排序
if __name__ == '__main__':
recomendhotel = RecomendHotel(path = 'hotel-mess.csv',address='东城区',type = 'combine',k=10)
print(recomendhotel.recomend())
{'北京保利大厦': 8.928710269200643, '北京新侨诺富特饭店': 7.794049593059157, '北京航招宾馆(原中航第一招待所)': 7.061409778511543, '北京华侨大厦': 6.959724357099342, '北京励骏酒店': 6.866169144869108, '国瑞百捷酒店(北京站崇文门店)': 6.628174603174602, '北京黄河京都大酒店': 6.270450726817961, '如家精选酒店(北京朝阳门地铁站店)': 6.0280423280423285, '鑫海锦江大酒店': 6.006402414685075, '北京贝尔特酒店': 5.8860641874390485}
``

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









