







一、开篇总览
1. bulk操作最好请求体数据大小在5m-15m

2.由于要给文件系统缓存留下足够空间,es的jvm堆大小不要超过服务器可用内存空间的一半。

二、聚合
1.在聚合时,missing字段可以给没有该字段的文档以默认值
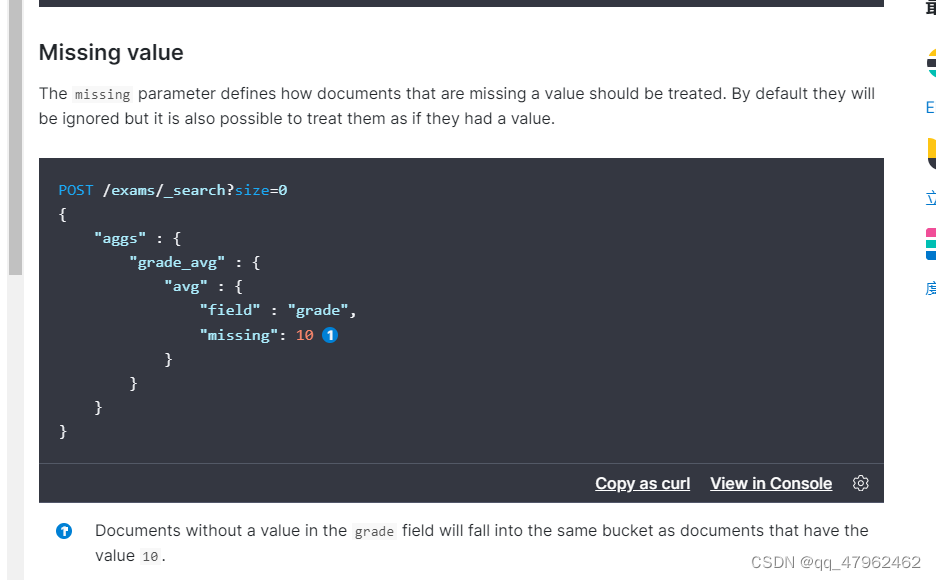
2.带权重的计算平均值,文档如果没有weight字段,值默认为1.

3.基数统计(cardinality ) 基于hyperlog算法,相比hashset节约大量内存。如果聚合的字段是高基数字符串,那么可以在保存到es前先计算出hash值保存到文档中,最后计算的时候可以直接计算hash字段即可。

4.term聚合在数据分布式存储到多节点时是可能不准确的,默认是返回每个节点的前size个符合条件的数据然后聚合起来,不能保证精确性。可以选择加大size或者索引自定义路由解决问题。

5.聚合时大多时候应把外层的size设置为0,加快查询效率。
6.range聚合是左闭右开。
三、query dsl
1.must_not和filter都是一样的,不参加算分,属于filter上下文。
2.disjuction max(dis_max)复合查询,默认情况下会返回匹配度最高的那条查询语句所得的算分,如果两个文档同时符合匹配度最高的那条查询语句,他们的算分会相同,这时候可以使用tie_breaker参数,使得dis_max查询所得最后得分再加上Σ(其他条件所得的分数*tie_breaker)。

3.可以使用function score复合查询实现自定义算分规则。

4. match查询会对查询条件里面得文本进行分词,然后对分词后的结果进行查询,默认是满足分词的一个即可,也可设置operator参数使其为and全部满足。

5.Multi_match query可以使一个查询对多个字段有效,类似于bool中的or,默认使用dis_max查询,即取得当中的最佳匹配条件作为分数。还可以对字段进行模糊匹配以及提高字段所得分比重,如下所示。

6.exist query
(1)exist query的存在的意思是该字段是否为空或者该字段是否能被索引。

7.prefix query可以开启index_prefixes参数使其指定范围内的字段进行索引加快前缀查询速度,典型的空间换时间。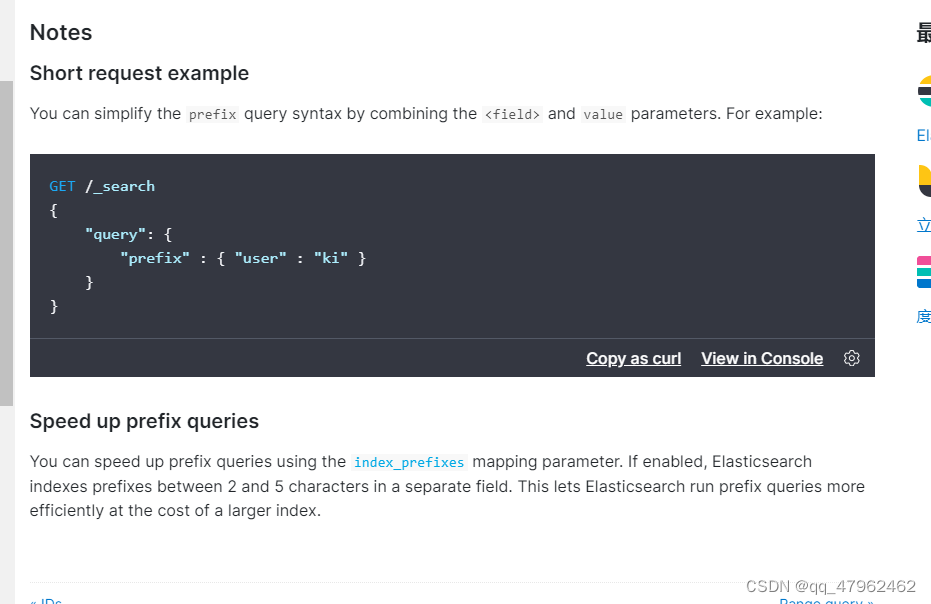
8.match_phrase查询的流程:首先将输入的查询语句分词,然后去索引中查具有查询语句所有分词的文档,同时文档中的该字段分词必须按照查询语句的顺序进行。可以通过调整查询语句的slop,调整分词在文档中出现的顺序。

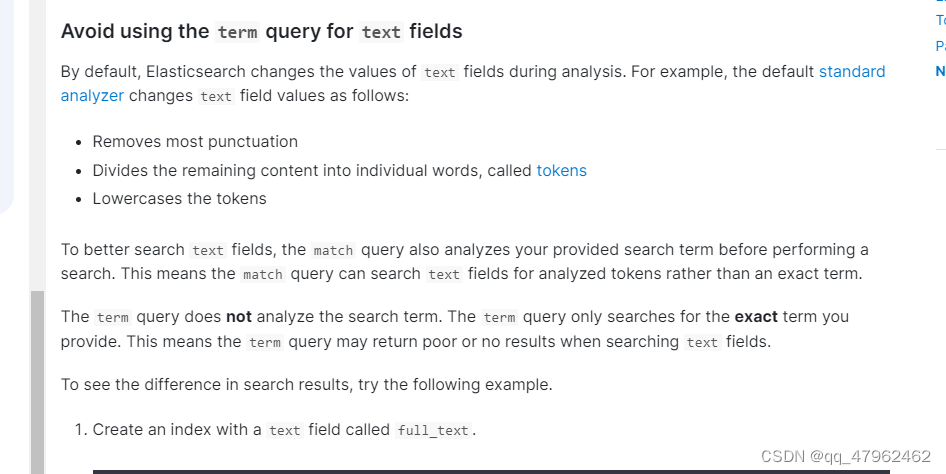
9.term query不会对搜索条件分词,别用term query查询text类型字段。
10.terms query可以对一个字段进行多个值查询,他们的关系是or,如果查询的值来源是文档本身。可以使用term lookup 语法:

11.可以使用terms_set对符合条件的查询语句数量进行限制,只返回满足特定匹配条件数量的结果才会返回。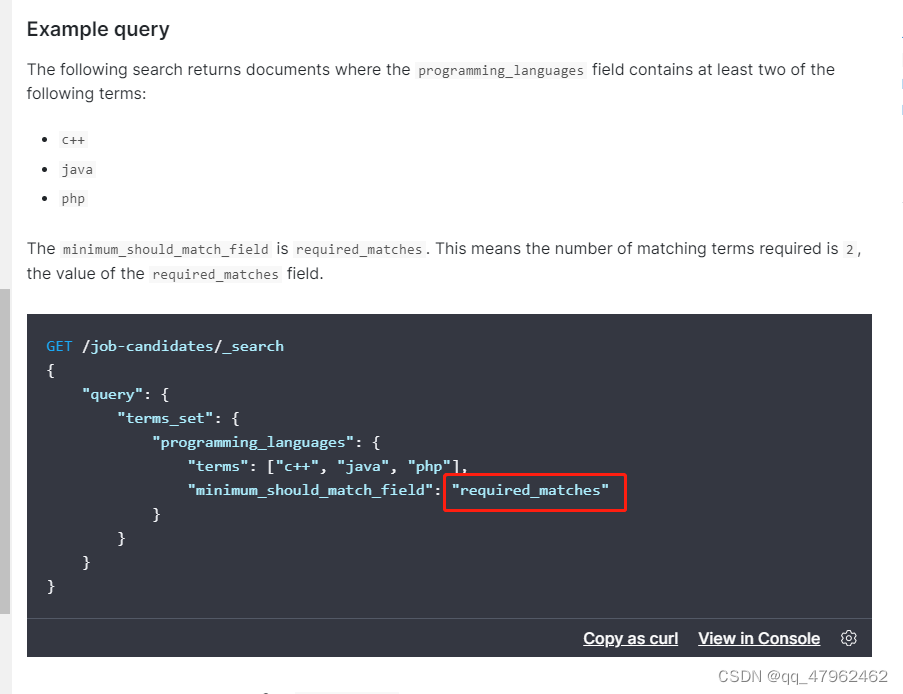
12.可以使用script_score 进行简单的算分,例如使用文档的某个字段进行算分排序。
四、script
1.使用脚本时source内需要注入的参数必须写在外面的params字段,这样可以让脚本只编译一次,大大提高工作效率。

2.脚本可以先存储到集群中,使用的时候指定脚本名称即可,减少网络带宽消耗。

五、mapping


1.nested类型可以将数组内的对象每个都视作单独的对象,而不是object类型这样的会将数组内相同字段打平聚集在一起。
2.浮点类型最好使用scaled_float,其内部以long类型存储,因为压缩的原因可以更节约磁盘空间
3.自定义routing可以在查询时不必将搜索请求分散到索引中的所有分片,而是可以将请求仅发送到与特定路由值匹配的分片,同时为了防止将大索引全都放在一个分片导致数据倾斜,可以弄一个所有分片的子集作为索引的分片选择上,加快搜索性能提升。

4.定义数据结构时可以使用ignore_above这个参数限制字符串长度,当插入的字符超过这个参数大小,文档不能使用这个字段索引出来。
5.ignore_malformed参数可以忽略类型的不匹配,例如定义字段为integer,可以提交字符串类型,但是json类型是不能提交过来的,会忽略这个配置抛出异常,此外开启这个配置的字段是不能被索引的。
6.null_value可以使空值有一个默认值使其按照默认值被检索出来。
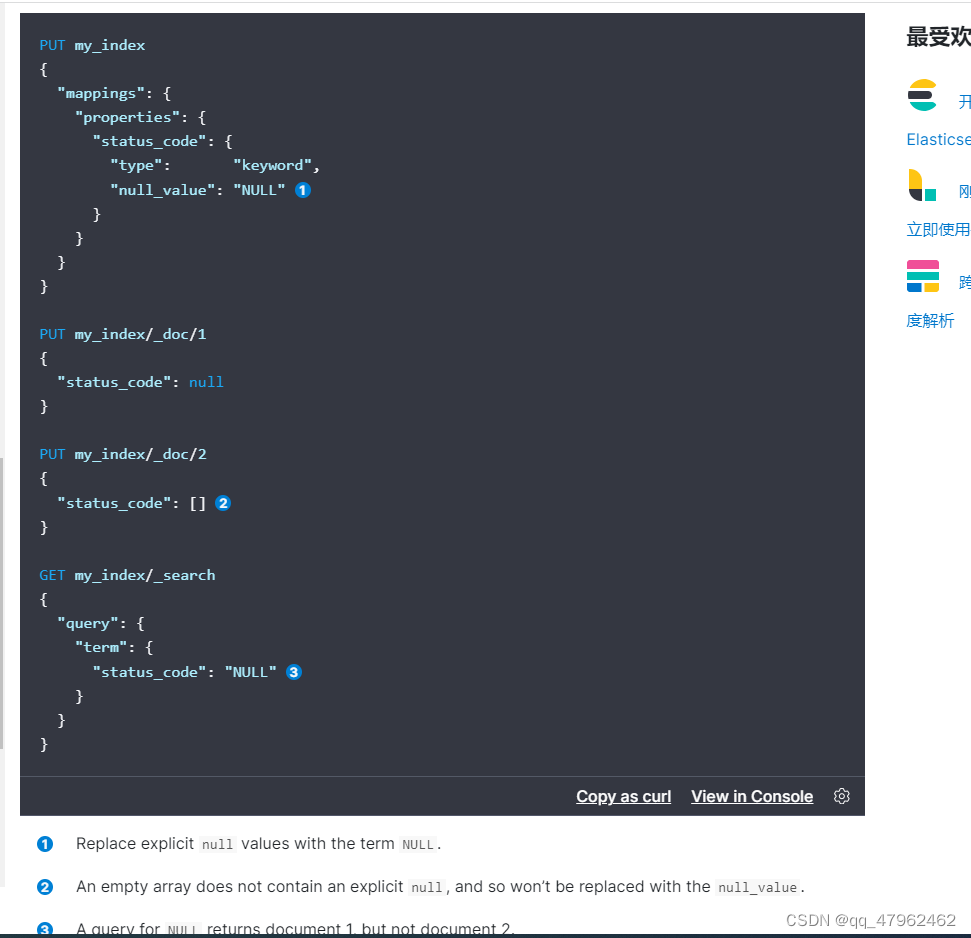
7._source可以指定哪些字段不保存到原始的json文档中,但是可以被索引,不过使用后有如下图片弊端,建议为了节省磁盘空间加大压缩等级。如果实在想让返回值没有某个字段,直接查询时进行source filter即可。

8.copy_to参数可以让某个字段的值复制到另外一个字段,source并不会改变

9.doc_value是专门存储用于在脚本等其他地方查询并且用于排序,聚合使用,如果某个字段没有这个需求可以使其关闭节省空间。

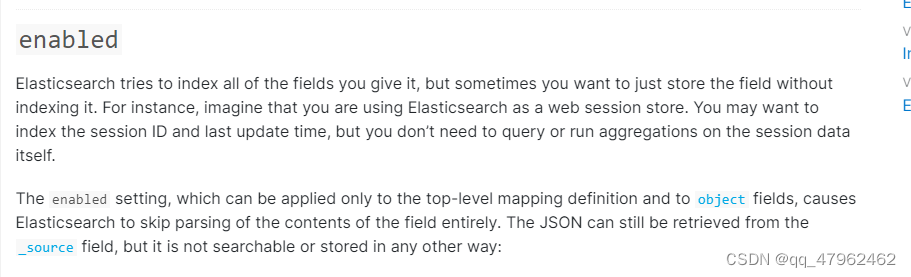
10.enbled只能用于obj对象,为false时对该字段插入不会有任何检查,该字段也不能进行任何索引。
六、模块
1.shard request cache
(1)默认只对size=0的结果有效,并且会缓存聚合结果和hits.total等信息。缓存会在节点refresh后失效,前提是真的有数据变更。
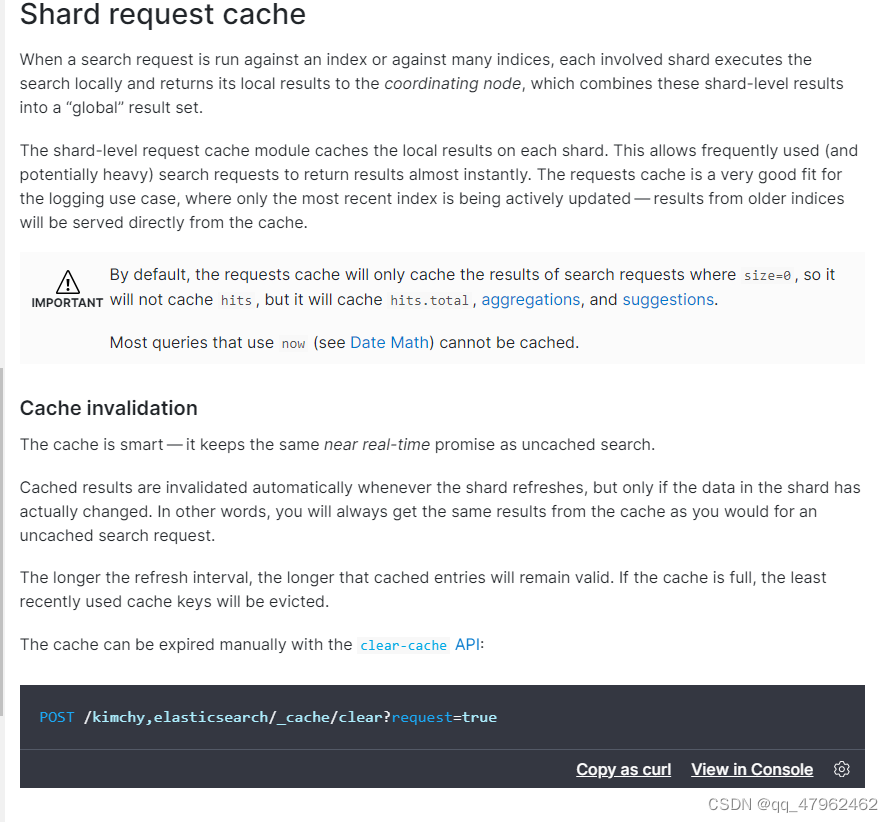
(2)如果请求中使用了脚本并含有随机数类似的参数,应该在url后面加上参数手动关闭本次请求缓存。缓存的key是请求体。

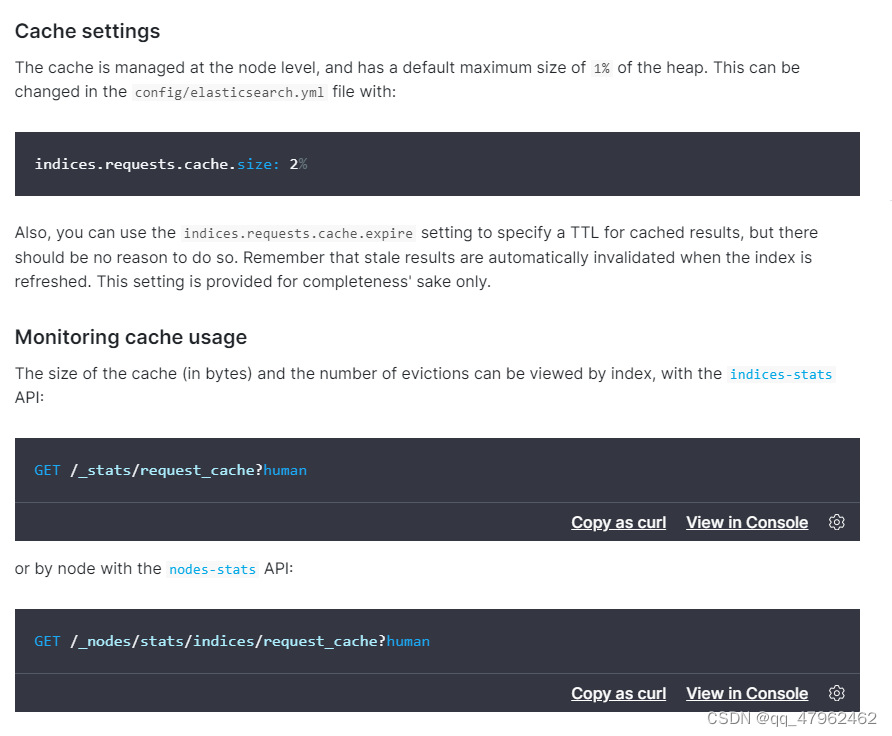
(3)缓存可以设置缓存大小以及缓存过期时间(通常是无意义的,因为索引refresh就会自动删除缓存)
2.node节点缓存仅仅缓存filter上下文的query语句。

七、通用推荐
1.在大索引中应该使用scroll或者search_after分页
(1)scroll:如果对结果没有排序要求只是简单的返回可以使用_doc排序,这样速度会更快,另外,scroll查询中如果有聚合,只会在第一次scroll查询返回,后续不会返回。弊端是不实时。当scroll到最后一页后,应该使用clear_scroll及时删除保存的快照。
(2)search after:需要在第一次查询时根据某个唯一字段(该字段是后续插入比前须大,这样保证了实时性)升序排列,然后根据排列后的升序字段最大值作为search after入参,这样就可以在分页时保证从各个节点返回的数据最大也只会有分页的size大小。弊端是不支持随机翻页。如果一定要随机翻页还是要使用from + size,可以在业务上规避翻页大小。
2.多使用bulk api来进行索引存取,这样有利于减少网络io,提高性能。当然对某个索引的bulk数量需要压测获取。不要超过几十mb。

3.使用多线程并发存取索引也是一个不错的方式去提高性能,这样有利于减少刷盘的性能损耗。

4.在业务允许的情况下,使用系统自动生成的id,这样可以少去集群查询一次id是否存在,提高了索引的插入速度。

5.index_buffer是用来暂存插入索引的文档的,最多给与512mb即可,超过这个大小对插入文档性能没有什么提升了。

6.尽量避免join,nested,parent_child,这个对索引检索的性能损耗很大。

7.索引的时候尽量查询更少的字段,可以用copy to代替multi_match这样的多字段查询。

8.如果范围聚合的范围查询都是固定的话,可以新增字段自己标识所属范围,用terms aggregation代替range aggragation加快查询速度。

9.有些字段虽然是数字但是仍然可以定义为keyword,取决于其是否常用作范围聚合或者term聚合。

10. 日期相关搜索尽量不要使用now,这样会无法利用缓存,建议可以四舍五入到分钟,这样在一分钟内的查询都是有缓存的,同时如果间隔越大,缓存越久,但是用户的体验就会有问题。

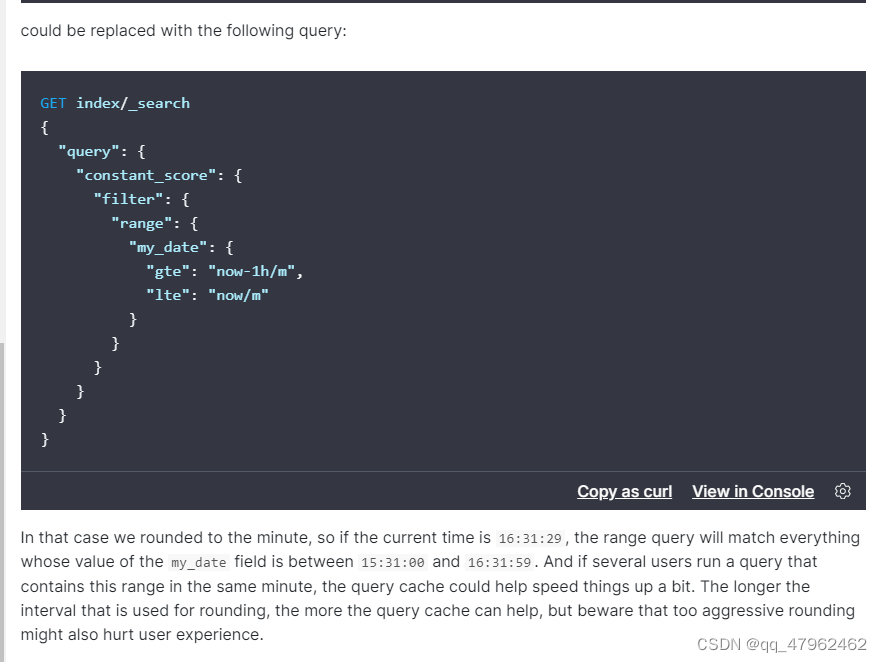
11.在多节点多副本情况下,可以使用preference指定分片顺序让缓存更好的利用起来。

12. 可以使用kibana的search profiler对查询进行多维指标观测。















 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









