







一、文献信息
发表信息:The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20),来自罗彻斯特大学。
作者信息:Tianlang Chen, Jiebo Luo
Department of Computer Science
University of Rochester
{tchen45, jluo}@cs.rochester.edu
二、论文详解
(一)背景
现有的ITM方法通常通过捕获和聚焦文本与图像的每个独立对象之间的相关性来推断Image-Text Similarity。But! 他们忽略了语义相关的对象之间的连接,而这些对象可以共同确定某一个图像是否对应于文本。
eg:绿色框中的每个对象都与文本中的“people”高度匹配,然而这却是一个预测错误的图文匹配(显然整张图片与文本中“Two people riding...”不符合)。因此,只有联合建模对象,模型才能预测图像与文本的不对应,才能使模型做出更准确的预测。

(二)主要内容
本文提出了一种双路径递归神经网络(DP-RNN),该网络通过递归神经网络对称地处理图像和句子,构成双路RNN。特别是,给定一个输入Image-Text pair,作者提出的模型能够根据 Image object 在Text 中最相关的单词的位置对图像对象重新排序,并由RNN编码。提出了一种配对早期选择策略,使递归视觉嵌入易于处理。此外,集成了一个多注意力交叉匹配模型,以根据重复的视觉和文本特征计算图像-文本的相似性。最后,进行了有关实验,证明了模型的有效性。
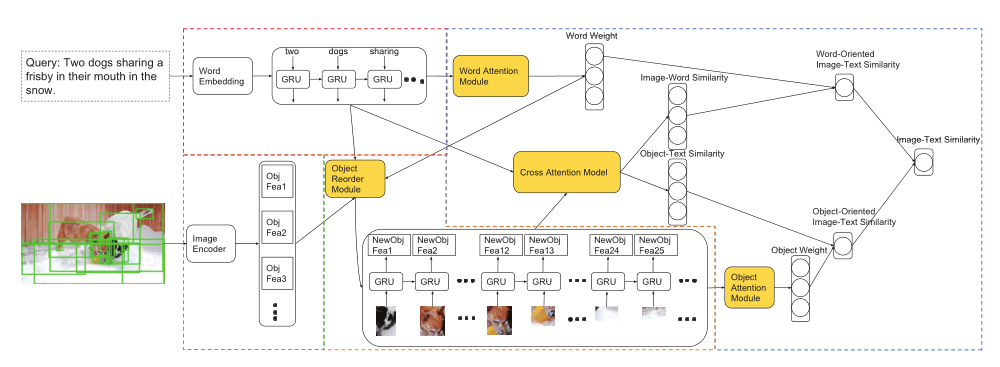
(三)具体方法
(1)Cross Matching with Multi-attention(多注意力交叉匹配)
提出了一种多注意力交叉匹配模型来计算相似度,以进一步提高图像文本匹配性能。
Image :用Faster R-CNN来提出显著区域,将每个突出区域视为一个对象,对于图像I,我们提取一组对象{O1,O2,…,Ok},其中k=36,具有相应的对象特征{f1, f2, ..., fk} ,k=36。
......额外将对象位置信息也输入到模型中,最后得到图像对象的最终特征
Text :对于单词集{W1, W2, ..., Wn},将其放入text encoder(包括word-embedding module and bi-directional GRU)。对于每个Wi,首先被嵌入为一个q维的单词表示xj。之后,双向GRU正向和反向读取单词集。

我们的模型以对称的方式预测(I,T)的相似性!!!
输入:一组对象和单词的特征
输出:S(i,T),文本T与每个对象之间的相似性
S(I,j),图像I与每个单词之间的相似性
以S(i,T)为例:
Step1:计算图像对象Oi对单词Wj的亲和力Ai,j
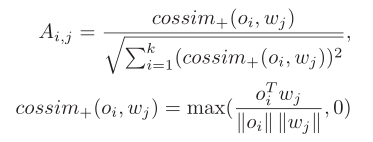
Step2:跨模态引导的注意力机制, αi,j(注意力权重),ti(第i个图像区域对整个句子的注意力系数)
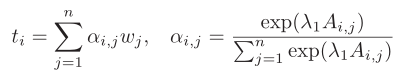
Step3:用余弦相似性计算该区域与整个文本的相似性
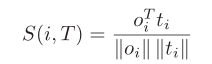
Step4: 文章结合了单词注意力模块和对象注意力模块来计算单词和对象的自我注意力权重。
对象Oi的自注意力权重: 单词Wj的自注意力权重:
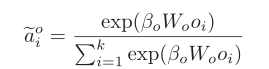
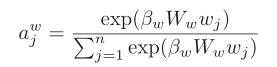
Step5:最后,用self-attention后的权重系数加权cross-modal的相似度分数矩阵,得到word-oriented and object-oriented 相似性
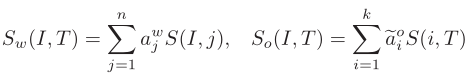
(2)三元rank loss
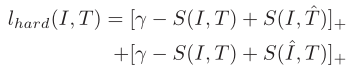
(3)Recurrent Visual Embedding(递归视觉嵌入)
本质上,该模型旨在使两个对象在输入文本环境中语义相关时彼此接近!!
将递归视觉嵌入模块并入DP-RNN。DP-RNN首先通过text encoder and image encoder 提取单词特征和原始图像特征,之后,在对图像的对象重新排序后,我们将对象特征以与单词特征相同的方式馈送到另一个双向GRU层,提取新的对象特征。最后,该模型将单词特征和新的对象特征馈送到多注意力交互匹配模型中,计算对(I,T)的相似度。
(4)Pair Early-selection(配对早期选择)
为了减少模型的时间复杂度,作者提出了一种早期选择策略,以过滤掉那些没法成为hardest negatives 的 image-text对。
计算每个 Text 和每个 Image 之间的早期匹配分数,计算公式如下:
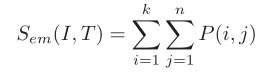
![]()
根据早期选择策略,只保留top-d个分数最高的不匹配图文对,硬负样本将从这里产生。
(四)Experiments
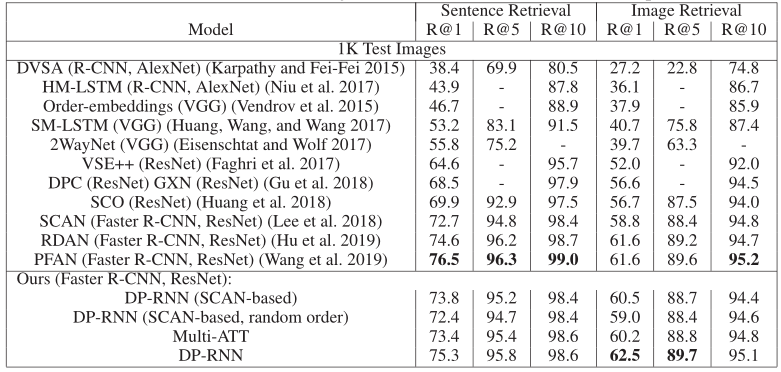
大量实验证明,我们的模型能够有效地从语义相关的对象中捕获联合信息,并将信息与文本中的相应单词相匹配。
(五)创新点
1、提出了一种用于 Image-Text Matching 的双路径递归神经网络(DP-RNN)
2、采用 RNN 处理图像特征,使得图像区域仿佛也有上下文
3、提出了一种对早期选择策略,使得递归视觉嵌入易于处理,减少了模型的时间复杂度
3、整合了一个多注意力交叉匹配模型来计算(I,T)相似度
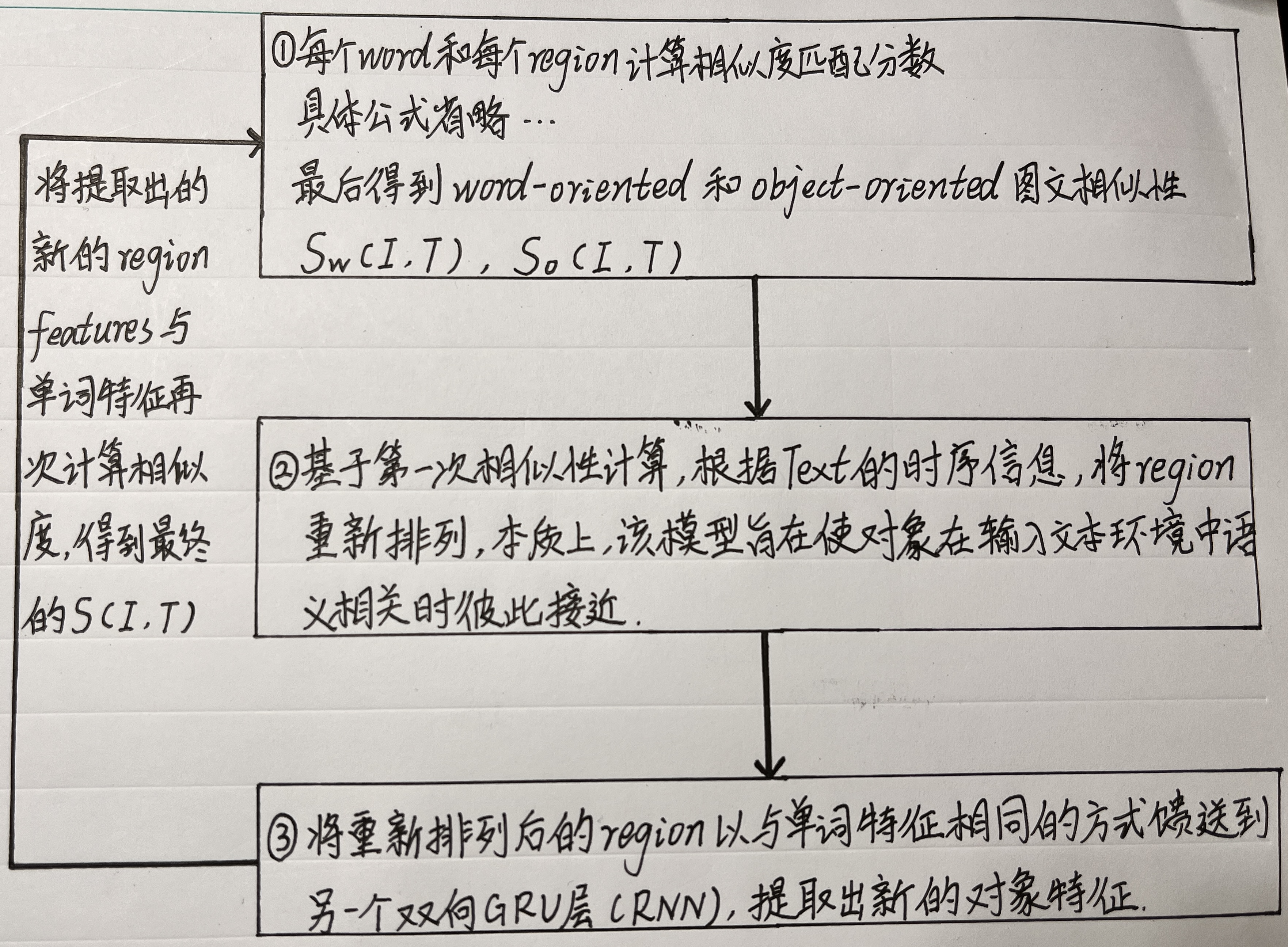
(补充:该论文提出的方法的具体过程)















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









