






文章目录
原文标题:Let’s code a Neural Network in plain NumPy
原文作者:Piotr Skalski
原文链接: https://medium.com/towards-data-science/lets-code-a-neural-network-in-plain-numpy-ae7e74410795
使用像Keras、TensorFlow或PyTorch这样的高级框架允许我们快速构建非常复杂的模型。 然而,花点时间看看内部情况并理解底层概念是值得的。 不久前,我发表了一篇文章,用一种简单的方式解释了神经网络是如何工作的。然而,这是一个高度理论性的职位,主要致力于数学,这是神经网络超级力量的来源。 从一开始我就打算以一种更实际的方式来跟进这个话题。这一次,我们将尝试利用我们的知识,仅使用NumPy构建一个完全可操作的神经网络。最后,我们也将测试我们的模型-解决简单的分类问题,并将其性能与Keras建立的神经网络进行比较。

Figure 1. Example of dense neural network architecture
First things first
我们开始编程之前,让我们停下来准备一个基本的路线图。 我们的目标是创建一个程序,能够创建一个密集连接的神经网络与指定的架构(层的数量和大小和适当的激活函数)。 上图给出了这样一个网络的示例。 最重要的是,我们必须能够训练我们的网络并使用它进行预测。

Figure 2. Neural network blueprint
上图显示了在我们的NN训练过程中需要执行哪些操作。 它还显示了在单个迭代的不同阶段我们需要更新和读取多少参数。 构建正确的数据结构并巧妙地管理其状态是我们任务中最困难的部分之一。 由于时间限制,我将不详细描述图中每个参数的作用。 我建议所有感兴趣的人阅读本系列的第一篇文章,我希望您能在其中找到困扰您的所有问题的答案。

Figure 3. Dimensions of weight matrix W and bias vector b for layer l.
Initiation of neural network layers
首先为每一层初始化权矩阵W和偏置向量b。 在上图中,我准备了一个小备考表,它将帮助我们为这些系数分配适当的维度。 上标[l]表示当前层的索引(从1开始计数),n表示给定层的单元数。 我假设描述NN架构的信息将以列表的形式交付给我们的程序,类似于代码片段1中展示的列表。 列表中的每一项都是一个描述单个网络层基本参数的字典:input_dim—作为该层的输入提供的信号向量的大小,output_dim—在该层的输出处获得的激活向量的大小,而activation—将在该层内部使用的激活函数。
nn_architecture = [
{"input_dim": 2, "output_dim": 4, "activation": "relu"},
{"input_dim": 4, "output_dim": 6, "activation": "relu"},
{"input_dim": 6, "output_dim": 6, "activation": "relu"},
{"input_dim": 6, "output_dim": 4, "activation": "relu"},
{"input_dim": 4, "output_dim": 1, "activation": "sigmoid"},
]
Snippet 1. A list containing parameters describing a particular neural network. This list corresponds to the NN shown in Figure 1.
如果你对这个话题很熟悉,你可能已经听到一个声音在你的脑海中焦虑地说:“嘿,嘿! 东西是错的! 有些字段是不必要的……” 是啊,你内心的声音这次说对了。 从一层出来的向量也是下一层的输入,所以事实上,只知道其中一个向量的大小就足够了。 然而,我故意决定使用以下符号来保持所有层的对象一致,并使代码更容易让第一次遇到这些内容的人理解。
def init_layers(nn_architecture, seed = 99):
np.random.seed(seed)
number_of_layers = len(nn_architecture)
params_values = {}
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
layer_input_size = layer["input_dim"]
layer_output_size = layer["output_dim"]
params_values['W' + str(layer_idx)] = np.random.randn(
layer_output_size, layer_input_size) * 0.1
params_values['b' + str(layer_idx)] = np.random.randn(
layer_output_size, 1) * 0.1
return params_values
Snippet 2. The function that initiates the values of the weight matrices and bias vectors.
让我们最后关注在这一部分中必须完成的主要任务—层参数的初始化。 那些已经看过代码片段2并对NumPy有一定经验的人已经注意到矩阵W和向量b被填充成小的、随机的数字。 这种做法并非偶然。 权重值不能用相同的数字初始化,因为这会导致打破对称性的问题。 基本上,如果所有的权重都是相同的,那么无论输入X是什么,隐藏层中的所有神经元也将是相同的。 在某种程度上,我们陷入了最初的状态,没有任何逃脱的希望,无论我们要训练我们的模型多久,我们的网络有多深。 线性代数不能原谅。
在第一次迭代中,使用小值可以提高算法的效率。 看一下sigmoid函数的图,如图4所示,我们可以看到,对于大的值,它几乎是平坦的,这对我们的NN的学习速度有显著的影响。 总之,使用小随机数初始化参数是一种简单的方法,但它保证了我们的算法有足够好的起点。 准备好的参数值存储在python字典中,其键值唯一标识它们的父层。 字典在函数结束时返回,因此我们将在算法的下一阶段访问它的内容。
Activation functions
我们将使用的所有函数,有一些非常简单但强大的。 激活函数可以在一行代码中编写,但它们为神经网络提供了所需的非线性和表现力。 “没有它们,我们的神经网络就会变成线性函数的组合,所以它本身就只是一个线性函数。” 有许多激活函数,但在这个项目中,我决定提供使用其中两个的可能性- sigmoid和ReLU。 为了能够绕一圈并同时进行正向和反向传播,我们还需要准备它们的导数。
def sigmoid(Z):
return 1/(1+np.exp(-Z))
def relu(Z):
return np.maximum(0,Z)
def sigmoid_backward(dA, Z):
sig = sigmoid(Z)
return dA * sig * (1 - sig)
def relu_backward(dA, Z):
dZ = np.array(dA, copy = True)
dZ[Z <= 0] = 0;
return dZ;
Snippet 3. ReLU and Sigmoid activation functions and their derivatives.
Forward propagation
所设计的神经网络具有简单的结构。 信息以一个方向流动——它以X矩阵的形式传递,然后通过隐藏层的神经元,产生Y_hat预测向量。 为了便于阅读,我将前向传播分为两个单独的函数——对单个层进行前向传播,对整个NN进行前向传播。
def single_layer_forward_propagation(A_prev, W_curr, b_curr, activation="relu"):
Z_curr = np.dot(W_curr, A_prev) + b_curr
if activation is "relu":
activation_func = relu
elif activation is "sigmoid":
activation_func = sigmoid
else:
raise Exception('Non-supported activation function')
return activation_func(Z_curr), Z_curr
Snippet 4. Single layer forward propagation step
这部分代码可能是最简单易懂的。 给定前一层的输入信号,我们计算仿射变换Z,然后应用选定的激活函数。 通过使用NumPy,我们可以利用向量化——对整个层和整批示例执行矩阵操作。 这消除了迭代,大大加快了我们的计算速度。 除了计算出的矩阵A,我们的函数还返回一个中间值z。 答案如图2所示, 在 backward的过程中我们需要Z。

Figure 5. Dimensions of individual matrices used in a forward step.
使用一个预先准备好的一层前向函数,我们现在可以轻松地构建一个完整的前向传播步骤。 这是一个稍微复杂一些的函数,它的作用不仅是执行预测,而且还组织中间值的集合。 它返回Python字典,其中包含为特定层计算的A和Z值。
def full_forward_propagation(X, params_values, nn_architecture):
memory = {}
A_curr = X
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
A_prev = A_curr
activ_function_curr = layer["activation"]
W_curr = params_values["W" + str(layer_idx)]
b_curr = params_values["b" + str(layer_idx)]
A_curr, Z_curr = single_layer_forward_propagation(A_prev, W_curr, b_curr, activ_function_curr)
memory["A" + str(idx)] = A_prev
memory["Z" + str(layer_idx)] = Z_curr
return A_curr, memory
Snippet 5. Full forward propagation step
Loss function
为了监测我们的进展并确保我们在正确的方向上前进,我们应该定期计算损失函数的值。 “一般来说,损失函数的设计是为了显示我们离‘理想’解决方案还有多远。” 它是根据我们计划解决的问题来选择的,像Keras这样的框架有很多选择。 因为我打算测试我们的NN对两个类之间的点进行分类,所以我决定使用二分类交叉熵,它由以下公式定义。 为了获得更多关于学习过程的信息,我还决定实现一个计算精度的函数。

def get_cost_value(Y_hat, Y):
m = Y_hat.shape[1]
cost = -1 / m * (np.dot(Y, np.log(Y_hat).T) + np.dot(1 - Y, np.log(1 - Y_hat).T))
return np.squeeze(cost)
def get_accuracy_value(Y_hat, Y):
Y_hat_ = convert_prob_into_class(Y_hat)
return (Y_hat_ == Y).all(axis=0).mean()
Snippet 6. Calculating the value of the cost function and accuracy
Backward propagation
反向传播被许多缺乏经验的深度学习爱好者认为是一种令人生畏且难以理解的算法。 微分学和线性代数的结合常常使没有受过扎实数学训练的人却步。 所以如果你不能马上理解所有的内容,也不要太担心。 相信我,我们都经历过。
def single_layer_backward_propagation(dA_curr, W_curr, b_curr, Z_curr, A_prev, activation="relu"):
m = A_prev.shape[1]
if activation is "relu":
backward_activation_func = relu_backward
elif activation is "sigmoid":
backward_activation_func = sigmoid_backward
else:
raise Exception('Non-supported activation function')
dZ_curr = backward_activation_func(dA_curr, Z_curr)
dW_curr = np.dot(dZ_curr, A_prev.T) / m
db_curr = np.sum(dZ_curr, axis=1, keepdims=True) / m
dA_prev = np.dot(W_curr.T, dZ_curr)
return dA_prev, dW_curr, db_curr
人们经常混淆反向传播和梯度下降,但事实上这是两个独立的问题。 第一种方法的目的是有效地计算梯度,而第二种方法是利用计算的梯度进行优化。 在神经网络中,我们计算损失函数(前面讨论过)关于参数的梯度,但反向传播可以用于计算任何函数的导数。这个算法的本质是递归使用一个从微分学中知道的链式法则——计算由组合其他函数创建的函数的导数,这些函数的导数我们已经知道。 对于一个网络层,这个过程可以用以下公式来描述。 不幸的是,由于本文主要关注实际实现,所以省略了推导过程。 看看这些公式,我们决定记住中间层的A和Z矩阵值的原因就变得很明显了。


Figure 6. Forward and backward propagation for a single layer.
就像前向传播的情况一样,我决定将计算分成两个单独的函数。 第一个代码片段(如代码片段7所示)主要关注单个层,并将其归结为在NumPy中重写上述公式。 第二个表示完全向后传播,主要处理在三个字典中读取和更新参数值。 我们首先计算损失函数对预测向量的导数——正向传播的结果。 这是很简单的,因为它只包含重写下面的公式。 然后从头到尾遍历网络各层,按图6所示对各参数求导数。 最终,函数返回一个python字典,其中包含我们正在寻找的梯度。

def full_backward_propagation(Y_hat, Y, memory, params_values, nn_architecture):
grads_values = {}
m = Y.shape[1]
Y = Y.reshape(Y_hat.shape)
dA_prev = - (np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat));
for layer_idx_prev, layer in reversed(list(enumerate(nn_architecture))):
layer_idx_curr = layer_idx_prev + 1
activ_function_curr = layer["activation"]
dA_curr = dA_prev
A_prev = memory["A" + str(layer_idx_prev)]
Z_curr = memory["Z" + str(layer_idx_curr)]
W_curr = params_values["W" + str(layer_idx_curr)]
b_curr = params_values["b" + str(layer_idx_curr)]
dA_prev, dW_curr, db_curr = single_layer_backward_propagation(
dA_curr, W_curr, b_curr, Z_curr, A_prev, activ_function_curr)
grads_values["dW" + str(layer_idx_curr)] = dW_curr
grads_values["db" + str(layer_idx_curr)] = db_curr
return grads_values
Snippet 8. Full backward propagation step
Updating parameters values
该方法的目标是利用梯度优化更新网络参数。 通过这种方式,我们试图使我们的目标函数更接近最小值。 为了完成这项任务,我们将使用提供函数参数的两个字典:params_values,它存储参数的当前值,以及grads_values,它存储根据这些参数计算出的损失函数的导数。 现在你只需要对每一层应用下面的方程。 这是一个非常简单的优化算法,但我决定使用它,因为它是更高级优化器的一个很好的起点,这可能是我下一篇文章的主题。

def update(params_values, grads_values, nn_architecture, learning_rate):
for layer_idx, layer in enumerate(nn_architecture):
params_values["W" + str(layer_idx)] -= learning_rate * grads_values["dW" + str(layer_idx)]
params_values["b" + str(layer_idx)] -= learning_rate * grads_values["db" + str(layer_idx)]
return params_values;
Snippet 9. Updating parameters values using gradient descent
Putting things together
这项任务最困难的部分已经过去了——我们已经准备好了所有必要的功能,现在我们只需要把它们按正确的顺序放在一起。 为了更好地理解操作的顺序,有必要再次查看图2中的图表。 该函数返回训练的结果以及训练期间指标的历史变化所获得的优化权重。 为了进行预测,您只需要使用接收到的权重矩阵和一组测试数据运行一个完整的前向传播。
def train(X, Y, nn_architecture, epochs, learning_rate):
params_values = init_layers(nn_architecture, 2)
cost_history = []
accuracy_history = []
for i in range(epochs):
Y_hat, cashe = full_forward_propagation(X, params_values, nn_architecture)
cost = get_cost_value(Y_hat, Y)
cost_history.append(cost)
accuracy = get_accuracy_value(Y_hat, Y)
accuracy_history.append(accuracy)
grads_values = full_backward_propagation(Y_hat, Y, cashe, params_values, nn_architecture)
params_values = update(params_values, grads_values, nn_architecture, learning_rate)
return params_values, cost_history, accuracy_history
Snippet 10. Training a model
David vs Goliath
是时候看看我们的模型能否解决一个简单的分类问题了。 我生成了一个由属于两个类的点组成的数据集,如图7所示。 让我们试着教我们的模型对属于这个分布的点进行分类。 为了进行比较,我还准备了一个高级框架模型——Keras。 这两个模型具有相同的架构和学习率。 不过,这确实是一场不均衡的战斗,因为我们准备的实现可能是最简单的实现。 最终,NumPy和Keras模型在测试集中都达到了相似的95%的准确率。 然而,我们的模型花费了几十倍的时间才达到这样的结果。 在我看来,这种状态主要是由于缺乏适当的优化造成的。

Figure 7. Test dataset
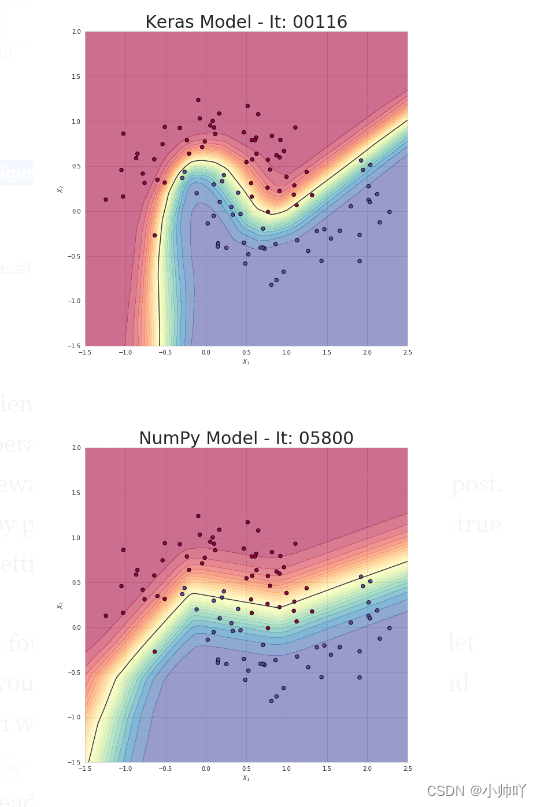
Figure 8. Visualisation of the classification boundaries achieved with both models















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









