




引言:之前写过一篇《PPO算法逐行代码详解》的博客,在这篇博客中在介绍PPO算法理论的同时,基于《动手学强化学习》书中PPO算法的代码实现进行了逐行详解。但是这个实现我认为过于demo,实用性并不是很强,所以又学习魔改了cleanrl中的PPO算法的实现,在这篇文章中总结一下修改后的代码。
文章目录
cleanrl代码仓库: https://github.com/vwxyzjn/cleanrl
修改后的实现:https://github.com/acezsq/rlCode/blob/main/ppo_new.py
1. 修改的主要内容
修改的主要内容:
(1)更改cleanrl中多个环境并行采集数据的实现为单环境采集(为了适配我自己的gym任务环境)
(2)将gymnasium改为的gym(我自己的环境之前是基于gym实现的)
(3)去除部分我认为暂时没必要的配置项
(4)增加少量控制台打印训练进度信息展示
修改后实现的优点:
(1)最大的优点就是更加适配自定义的gym环境
为了验证修改后代码的正确性,这里先展示一下修改后的代码跑CartPole-v1和cleanrl原版代码跑CartPole-v1的效果对比:
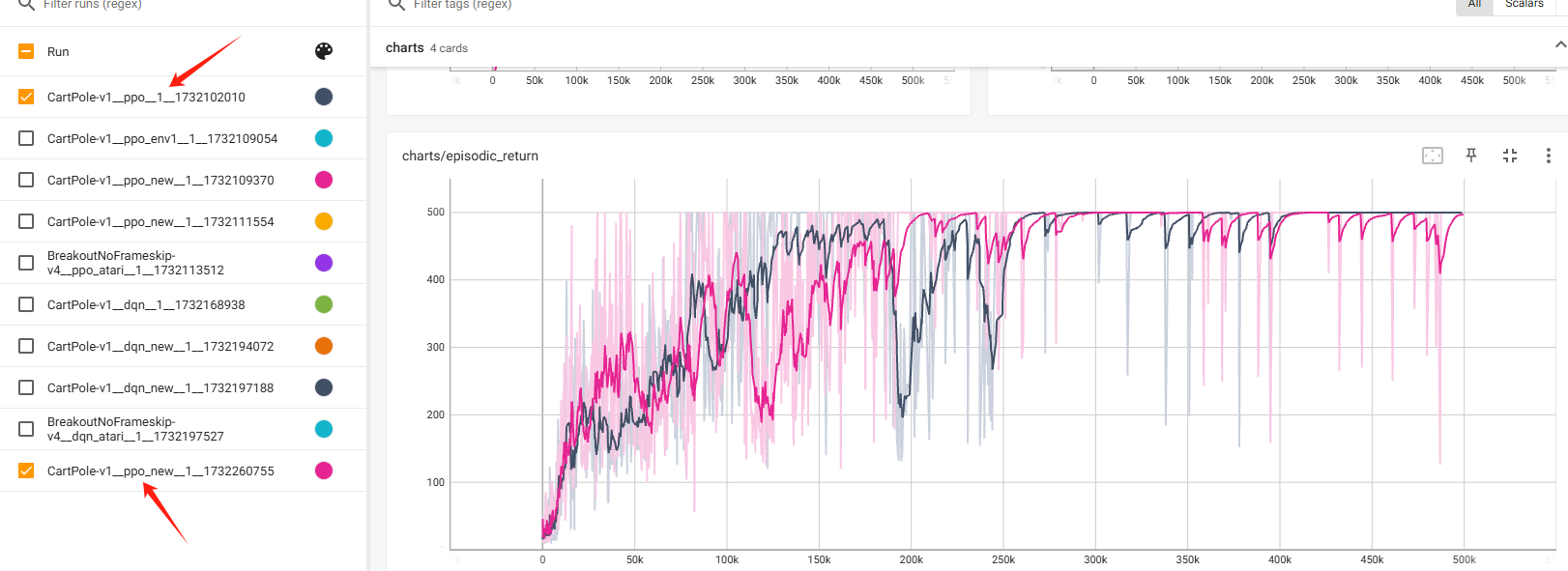
整体上是跟原来的实现大差不多,后期偶有不稳定的现象,这是可接受的。
2. 训练流程
在正式围绕代码实现分析之前,我觉得有必要先就PPO算法的训练流程有个大体的理解。
首先所有的drl算法的训练大逻辑都是agent和环境交互采集数据并存储到某个数据结构中,之后利用数据进行网络参数的更新。对于PPO算法,它是一个on-policy算法,需要采集一定量数据之后结合重要性采样,重复利用多次这批数据进行参数更新,之后清空重新采集。
在本次分析的代码实现中,训练的配置如下:
total_timesteps = 500000
batch_size = 512
minibatch_size = 128
num_iterations = 500000 // 512 = 976
update_epochs = 4
上面的配置就是一共训练500000个step,最外层的大循环一共执行976次,每次与agent与环境交互采集一个batch 512个step的数据,然后循环利用这一个batch的数据4次,每次将512个step的数据随机打乱,分为4个minibatch,每次通过一个minibatch计算损失函数进行参数更新。
3. 网络结构
网络结构:
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)
return layer
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.observation_space.shape[0]).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor = nn.Sequential(
layer_init(nn.Linear(np.array(envs.observation_space.shape[0]).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, envs.action_space.n), std=0.01),
)
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
logits = self.actor(x)
probs = Categorical(logits=logits)
if action is None:
action = probs.sample()
return action, probs.log_prob(action), probs.entropy(), self.critic(x)
get_value函数返回状态价值;
get_action_and_value函数使用actor获取动作的分布,采样一个动作,返回动作、logΠ(a|s)、动作分布的熵、状态价值。
4. 训练整体流程
我觉得整体流程可以分为以下几部分:
(1)相关参数定义、env环境初始化、存储数据结构定义。
(2)agent与环境交互产生训练用数据并存储。
(3)利用产生的数据进行多次网络参数更新。
4.1 相关参数定义、env环境初始化、存储数据结构定义
下面是主函数,首先是一些关于训练的参数定义和存储数据的数据结构的定义等内容。
if __name__ == "__main__":
args = tyro.cli(Args)
args.batch_size = int(args.num_envs * args.num_steps) # 1 * 512
args.minibatch_size = int(args.batch_size // args.num_minibatches) # 512 // 4 = 128
args.num_iterations = args.total_timesteps // args.batch_size # 500000 // 512 = 976
run_name = f"{
args.env_id}__{
args.exp_name}__{
args.seed}__{
int(time.time())}"
writer = SummaryWriter(f"runs/{
run_name}")
writer.add_text(
"hyperparameters",
"|param|value|\n|-|-|\n%s" % ("\n".join([f"|{
key}|{
value}|" for key, value in vars(args).items()])),
)
random.seed(args.seed)
np.random.seed(args 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









