







深度学习一(PyTorch物体检测实战)
文章目录
文章来源: <深度学习之PyTorch物体检测实战> 编著: 董洪义
书籍下载: www.hzbook.com
1、浅谈物体检测与PyTorch
在2012年的ImageNet图像识别竞赛中,Hinton率领的团队利用卷积神经网络构建的AlexNet一举夺得了冠军,从此点燃了学术界、工业界等对于深度学习、卷积网络的热情。短短六七年的时间,在图像分类、 物体检测、图像分割、人体姿态估计等一系列计算机视觉领域,深度学习都收获了极大的成功。
本章将专注于介绍物体检测的基础知识、发展历史,以及为什么选择PyTorch作为深度学习的框架。
1.1、深度学习与计算机视觉
近年来,人工智能、机器学习、深度学习、物体检测这样的名词经常会出现在大家的眼前,但大家对这些技术之间的区别与联系却经常混淆。基于此,本节将会介绍每一个技术的基本概念与发展历史。
1.1.1 发展历史
当前的计算机无论是处理多复杂的计算任务,其基本逻辑始终是0与1的位运算,凭借其每秒亿万的计算次数,计算机可以快速完成复杂的数学运算,这是人类无法比拟的。然而,涉及高语义的理解、判断,甚至是情感、意识(如判断一张图像中有几个儿童)这种对于人类轻而易举的任务,对计算机而言却很难处理,因为这种问题无法建立明确的数学规则。
为了赋予计算机以人类的理解能力与逻辑思维,诞生了人工智能(Artificial Intelligence,AI)这一学科。在实现人工智能的众多算法中,机器学习是发展较为快速的一支。机器学习的思想是让机器自动地从大量的数据中学习出规律,并利用该规律对未知的数据做出预测。在机器学习的算法中,深度学习是特指利用深度神经网络的结构完成训练和预测的算法。
人工智能、机器学习、深度学习这三者的关系如图1.1所示。可以看出,机器学习是实现人工智能的途径之一,而深度学习则是机器学习的算法之一。如果把人工智能比喻成人类的大脑,机器学习则是人类通过大量数据来认知学习的过程,而深度学习则是学习过程中非常高效的一种算法。

下面详细介绍这三者的发展历程
1、人工智能
人工智能的概念最早来自于1956年的计算机达特茅斯会议,其本质是希望机器能够像人类的大脑一样思考,并作出反应。由于极具难度与吸引力,人工智能从诞生至今,吸引了无数的科学家与爱好者投入研究。搭载人工智能的载体可以是近年来火热的机器人、自动驾驶车辆,甚至是一个部署在云端的智能大脑。
根据人工智能实现的水平,我们可以进一步分为3种人工智能,如图1.2所示。

弱人工智能(Artificial Narrow Intelligence,ANI):擅长某个特定任务的智能。例如语言处理领域的谷歌翻译,让该系统去判断一张图片中是猫还是狗,就无能无力了。再比如垃圾邮件的自动分类、自动驾驶车辆、手机上的人脸识别等,当前的人工智能大多是弱人工智能。
强人工智能:在人工智能概念诞生之初,人们期望能够通过打造复杂的计算机,实现与人一样的复杂智能,这被称做强人工智能,也可以称之为通用人工智能(Artificial General Intelligence,AGI)。这种智能要求机器像人一样,听、说、读、写样样精通。目前的发展技术尚未达到通用人工智能的水平,但已经有众多研究机构展开了研究。
超人工智能(Artificial Super Intelligence,ASI):在强人工智能之上,是超人工智能,其定义是在几乎所有领域都比人类大脑聪明的智能,包括创新、社交、思维等。人工智能科学家Aaron Saenz曾有一个有趣的比喻,现在的弱人工智能就好比地球早期的氨基酸,可能突然之间就会产生生命。超人工智能不会永远停留在想象之中。
人类追求人工智能的脚步永不会停止,例如鼎鼎有名的智能围棋学习系统AlphaGo,由谷歌大脑团队开发,在2016年3月15日以4∶1的总比分战胜了韩国围棋选手李世石,引发了全世界巨大的反响。谷歌在时隔一年后推出了AlphaGo Zero,可以在不使用人类棋谱经验的前提下成为一个围棋高手,具有划时代的意义。我们也有理由相信,实现更高级的人工智能指日可待。
2、机器学习
机器学习是实现人工智能的重要途径,也是最早发展起来的人工智能算法。与传统的基于规则设计的算法不同,机器学习的关键在于从大量的数据中找出规律,自动地学习出算法所需的参数
机器学习最早可见于1783年的贝叶斯定理中。贝叶斯定理是机器学习的一种,根据类似事件的历史数据得出发生的可能性。在1997年,IBM开发的深蓝(Deep Blue)象棋电脑程序击败了世界冠军。当然,最令人振奋的成就还当属2016年打败李世石的AlphaGo。
机器学习算法中最重要的就是数据,根据使用的数据形式,可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)与强化学习(Reinforcement Learning),如图1.3所示。
· 监督学习:通常包括训练与预测阶段。在训练时利用带有人工标注标签的数据对模型进行训练,在预测时则根据训练好的模型对输入进行预测。监督学习是相对成熟的机器学习算法。监督学习通常分为类与回归两个问题,常见算法有决策树(Decision Tree,DT)、支持向量机(Support Vector Machine,SVM)和神经网络等。
· 无监督学习:输入的数据没有标签信息,也就无法对模型进行明确的惩罚。无监督学习常见的思路是采用某种形式的回报来激励模型做出一定的决策,常见的算法有K-Means聚类与主成分分析(PrincipalComponent Analysis,PCA)。
· 强化学习:让模型在一定的环境中学习,每次行动会有对应的奖励,目标是使奖励最大化,被认为是走向通用人工智能的学习方法。常见的强化学习有基于价值、策略与模型3种方法。

机器学习涉及概率、统计、凸优化等多个学科,目前已在数据挖掘、计算机视觉、自然语言处理、医学诊断等多个领域有了相当成熟的应用。
3、深度学习
深度学习是机器学习的技术分支之一,主要是通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据通常较为复杂、规模大、维度高。深度学习可以说是机器学习问世以来最大的突破之一。
深度学习的发展经历了一番波折,具体历程如图1.4所示。

最早的神经网络可以追溯到1943年的MCP(McCulloch and Pitts)人工神经元网络,希望使用简单的加权求和与激活函数来模拟人类的神经元过程。在此基础上,1958年的感知器(Perception)模型使用了梯度下降算法来学习多维的训练数据,成功地实现了二分类问题,也掀起了深度学习的第一次热潮。图1.5代表了一个最简单的单层感知器,输入有3个量,通过简单的权重相加,再作用于一个激活函数,最后得到了输出y。

然而,1969年,Minsky证明了感知器仅仅是一种线性模型,对简单的亦或判断都无能为力,而生活中的大部分问题都是非线性的,这直接让学者研究神经网络的热情难以持续,造成了深度学习长达20年的停滞不前。
1986年,深度学习领域“三驾马车”之一的Geoffrey Hinton创造性地将非线性的Sigmoid函数应用到了多层感知器中,并利用反向传播(Backpropagation)算法进行模型学习,使得模型能够有效地处理非线性问题。1998年,“三驾马车”中的卷积神经网络之父Yann LeCun发明了卷积神经网络LeNet模型,可有效解决图像数字识别问题,被认为是卷积神经网络的鼻祖。
然而在此之后的多年时间里,深度学习并没有代表性的算法问世,并且神经网络存在两个致命问题:一是Sigmoid在函数两端具有饱和效应,会带来梯度消失问题;另一个是随着神经网络的加深,训练时参数容易陷入局部最优解。这两个弊端导致深度学习陷入了第二次低谷。在这段时间内,反倒是传统的机器学习算法,如支持向量机、随机森林等算法获得了快速的发展。
2006年,Hinton提出了利用无监督的初始化与有监督的微调缓解了局部最优解问题,再次挽救了深度学习,这一年也被称为深度学习元年。2011年诞生的ReLU激活函数有效地缓解了梯度消失现象。
真正让深度学习迎来爆发式发展的当属2012年的AlexNet网络,其在ImageNet图像分类任务中以“碾压”第二名算法的姿态取得了冠军。深度学习从此一发不可收拾,VGGNet、ResNet等优秀的网络接连问世,并且在分类、物体检测、图像分割等领域渐渐地展现出深度学习的实力,大大超过了传统算法的水平。
当然,深度学习的发展离不开大数据、GPU及模型这3个因素,如图1.6所示。
· 大数据:当前大部分的深度学习模型是有监督学习,依赖于数据的有效标注。例如,要做一个高性能的物体检测模型,通常需要使用上万甚至是几十万的标注数据。数据的积累也是一个公司深度学习能力雄厚的标志之一,没有数据,再优秀的模型也会面对无米之炊的尴尬。
· GPU:当前深度学习如此“火热”的一个很重要的原因就是硬件的发展,尤其是GPU为深度学习模型的快速训练提供了可能。深度学习模型通常有数以千万计的参数,存在大规模的并行计算,传统的以逻辑运算能力著称的CPU面对这种并行计算会异常缓慢,GPU以及CUDA计算库专注于数据的并行计算,为模型训练提供了强有力的工具。
· 模型:在大数据与GPU的强有力支撑下,无数研究学者的奇思妙想,催生出了VGGNet、ResNet和FPN等一系列优秀的深度学习模型,并且在学习任务的精度、速度等指标上取得了显著的进步。

根据网络结构的不同,深度学习模型可以分为卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(RecurrentNeural Network,RNN)及生成式对抗网络(Generative AdviserialNetwork,GAN)。
1.2.2 计算机视觉
视觉是人类最为重要的感知系统,大脑皮层中近一半的神经元与视觉有关系。计算机视觉则是研究如何使机器学会“看”的学科,最早起源于20世纪50年代,当时主要专注于光学字符识别、航空图片的分析等特定任务。在20世纪90年代,计算机视觉在多视几何、三维重建、相机标定等多个领域取得了众多成果,也走向了繁荣发展的阶段。
然而在很长的一段时间里,计算机视觉的发展都是基于规则与人工设定的模板,很难有鲁棒的高语义理解。真正将计算机视觉的发展推向高峰的,当属深度学习的爆发。由于视觉图像丰富的语义性与图像的结构性,计算机视觉也是当前人工智能发展最为迅速的领域之一
进入深度学习发展阶段后,计算机视觉在多个领域都取得了令人瞩目的成就,如图1.7所示。
· 图像成像:成像是计算机视觉较为底层的技术,深度学习在此发挥的空间更多的是成像后的应用,如修复图像的DCGAN网络,图像风格迁移的CycleGAN,这些任务中GAN有着广阔的发挥空间。此外,在医学成像、卫星成像等领域中,超分辨率也至关重要,例如SRCNN(Super-Resolution CNN)。
· 2.5D空间:我们通常将涉及2D运动或者视差的任务定义为2.5D空间问题,因为其任务跳出了单纯的2D图像,但又缺乏3D空间的信息。这里包含的任务有光流的估计、单目的深度估计及双目的深度估计。
· 3D空间:3D空间的任务通常应用于机器人或者自动驾驶领域,将2D图像检测与3D空间进行结合。这其中,主要任务有相机标定(Camera Calibration)、视觉里程计(Visual Odometry,VO)及SLAM(Simultaneous Localization and Mapping)等。
· 环境的高语义理解是深度学习在计算机视觉中的主战场,相比传统算法其优势更为明显。主要任务有图像分类(Classification)、物体检测(Object Detection)、图像分割(Segmentation)、物体跟踪(Tracking)及关键点检测。其中,图像分割又可以细分为语义分割(Semantic Segmentation)与实例分割(Instance Segmentation)。

1.2、物体检测技术
在计算机视觉众多的技术领域中,物体检测是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于物体检测。此外,由于每张图像中物体的数量、大小及姿态各不相同,也就是非结构化的输出,这是与图像分类非常不同的一点,并且物体时常会有遮挡截断,物体检测技术也极富挑战性,从诞生以来始终是研究学者最为关注的焦点领域之一。
物体检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类别。对于图1.8中的人,我们要求检测器输出5个量:物体类别、 xmin、ymin、xmax与ymax。当然,对于一个边框,检测器也可以输出中心点与宽高的形式,这两者是等价的。

在计算机视觉中,图像分类、物体检测与图像分割是最基础、也是目前发展最为迅速的3个领域。图1.9列出了这3个任务之间的区别。

·图像分类:输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
·物体检测:输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。
·图像分割:输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
1.2.1、发展历程
在利用深度学习做物体检测之前,传统算法对于物体的检测通常分为区域选取、特征提取与特征分类这3个阶段,如图1.10所示。
·区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。
·特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。
·特征分类:最后,对上一步得到的特征进行分类,通常使用如SVM、AdaBoost的分类器。
深度学习时代的物体检测发展过程如图1.11所示。深度神经网络大量的参数可以提取出鲁棒性和语义性更好的特征,并且分类器性能也更优越。2014年的RCNN(Regions with CNN features)算是使用深度学习 实现物体检测的经典之作,从此拉开了深度学习做物体检测的序幕。
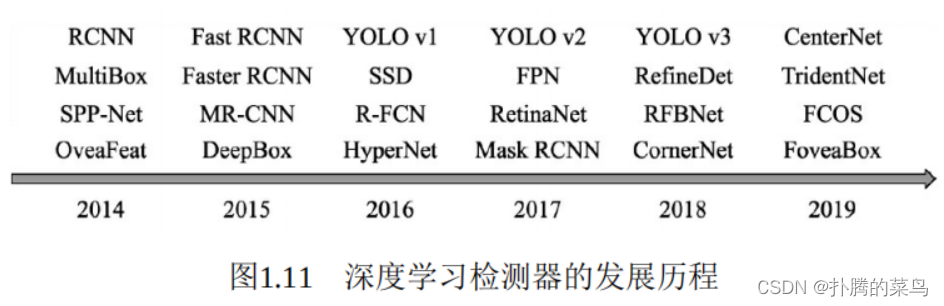
在RCNN基础上,2015年的Fast RCNN实现了端到端的检测与卷积共享,Faster RCNN提出了锚框(Anchor)这一划时代的思想,将物体检测推向了第一个高峰。在2016年,YOLO v1实现了无锚框(Anchor- Free)的一阶检测,SSD实现了多特征图的一阶检测,这两种算法对随 后的物体检测也产生了深远的影响。
在2017年,FPN利用特征金字塔实现了更优秀的特征提取网络, Mask RCNN则在实现了实例分割的同时,也提升了物体检测的性能。 进入2018年后,物体检测的算法更为多样,如使用角点做检测的 CornerNet、使用多个感受野分支的TridentNet、使用中心点做检测的CenterNet等。
在物体检测算法中,物体边框从无到有,边框变化的过程在一定程度上体现了检测是一阶的还是两阶的。
·两阶:两阶的算法通常在第一阶段专注于找出物体出现的位置,得到建议框,保证足够的准召率,然后在第二个阶段专注于对建议框进行分类,寻找更精确的位置,典型算法如Faster RCNN。两阶的算法通常精准度更高,但速度较慢。当然,还存在例如Cascade RCNN这样更多阶的算法。
·一阶:一阶的算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测,方法通常更为简单,依赖于特征融合、Focal Loss等优秀的网络经验,速度一般比两阶网络更快,但精度会有所损失,典型算法如SSD、YOLO系列等。
Anchor是一个划时代的思想,最早出现在Faster RCNN中,其本质上是一系列大小宽高不等的先验框,均匀地分布在特征图上,利用特征去预测这些Anchors的类别,以及与真实物体边框存在的偏移。Anchor相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有地预测物体,精度往往较高,常见算法有Faster RCNN和SSD等。
当然,还有一部分无锚框的算法,思路更为多样,有直接通过特征预测边框位置的方法,如YOLO v1等。最近也出现了众多依靠关键点来检测物体的算法,如CornerNet和CenterNet等。
1.2.2、技术应用领域
由于检测性能的迅速提升,物体检测也是深度学习在工业界取得大规模应用的领域之一。以下列举了5个广泛应用的领域。
·安防:受深度学习的影响,安防领域近年来取得了快速的发展与落地。例如广为人知的人脸识别技术,在交通卡口、车站等已有了成熟的应用。此外,在智慧城市的安防中,行人与车辆的检测也是尤为重要的一环。在安防领域中,有很大的趋势是将检测技术融入到摄像头中, 形成智能摄像头,以海康威视、地平线等多家公司最为知名。
·自动驾驶:自动驾驶的感知任务中,行人、车辆等障碍物的检测尤为重要。由于涉及驾驶的安全性,自动驾驶对于检测器的性能要求极高,尤其是召回率这个指标,自动驾驶也堪称人工智能应用的“珠穆朗玛峰”。此外,由于车辆需要获取障碍物相对于其自身的三维位置,因此通常在检测器后还需要增加很多的后处理感知模块。
·机器人:工业机器人自动分拣中,系统需要识别出要分拣的各种部件,这是极为典型的机器人应用领域。此外,移动智能机器人需要时刻检测出环境中的各种障碍物,以实现安全的避障与导航。从广泛意义来看,自动驾驶车辆也可以看做是机器人的一种形式。
·搜索推荐:在互联网公司的各大应用平台中,物体检测无处不在。例如,对于包含特定物体的图像过滤、筛选、推荐和水印处理等, 在人脸、行人检测的基础上增加更加丰富的应用,如抖音等产品。
·医疗诊断:基于人工智能与大数据,医疗诊断也迎来了新的春天,利用物体检测技术,我们可以更准确、迅速地对CT、MR等医疗图像中特定的关节和病症进行诊断。
1.2.3、评价指标
对于一个检测器,我们需要制定一定的规则来评价其好坏,从而选择需要的检测器。对于图像分类任务来讲,由于其输出是很简单的图像类别,因此很容易通过判断分类正确的图像数量来进行衡量。
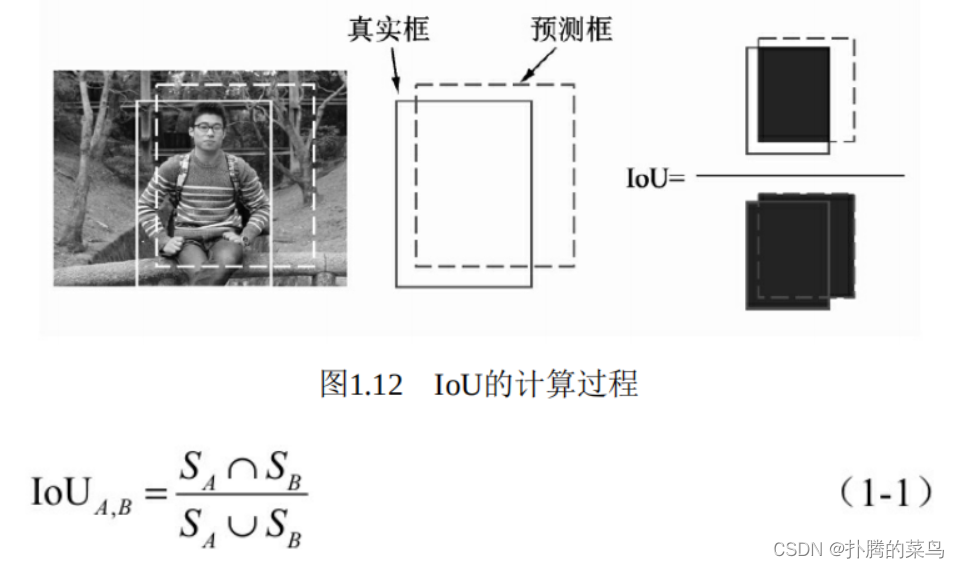
物体检测模型的输出是非结构化的,事先并无法得知输出物体的数量、位置、大小等,因此物体检测的评价算法就稍微复杂一些。对于具体的某个物体来讲,我们可以从预测框与真实框的贴合程度来判断检测的质量,通常使用IoU(Intersection of Union)来量化贴合程度。
IoU的计算方式如图1.12所示,使用两个边框的交集与并集的比值,就可以得到IoU,公式如式(1-1)所示。显而易见,IoU的取值区 间是[0,1],IoU值越大,表明两个框重合越好。
利用Python可以很方便地实现IoU的计算,代码如下:
# boxA | boxB = [xmin, ymin, xmax, ymax]
def iou(boxA, boxB):
# 计算重合部分的上、下、左、右4个边的值,注意最大最小函数的使用
left_max = max(boxA[0], boxB[0])
top_max = max(boxA[1], boxB[1])
right_min = min(boxA[2], boxB[2])
bottom_min = min(boxA[3], boxB[3])
# 计算重合部分的面积
inter =max(0,(right_min-left_max))* max(0,(bottom_min-top_max)
Sa = (boxA[2]-boxA[0])*(boxA[3]-boxA[1])
Sb = (boxB[2]-boxB[0])*(boxB[3]-boxB[1])
# 计算所有区域的面积并计算iou,如果是Python 2,则要增加浮点化操作
union = Sa+Sb-inter
iou = inter/union
return iou
对于IoU而言,我们通常会选取一个阈值,如0.5,来确定预测框是正确的还是错误的。当两个框的IoU大于0.5时,我们认为是一个有效的检测,否则属于无效的匹配。如图1.13中有两个杯子的标签,模型产生了两个预测框。
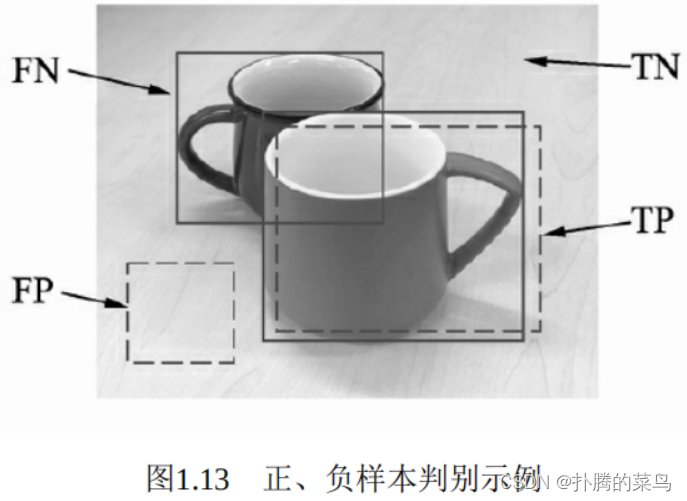
由于图像中存在背景与物体两种标签,预测框也分为正确与错误,因此在评测时会产生以下4种样本。
·正确检测框TP(True Positive):预测框正确地与标签框匹配了,两者间的IoU大于0.5,如图1.13中右下方的检测框。
·误检框FP(False Positive):将背景预测成了物体,如图1.13中左下方的检测框,通常这种框与图中所有标签的IoU都不会超过0.5。
·漏检框FN(False Negative):本来需要模型检测出的物体,模型没有检测出,如图1.13中左上方的杯子。
·正确背景(True Negative):本身是背景,模型也没有检测出来,这种情况在物体检测中通常不需要考虑。
有了上述基础知识,我们就可以开始进行检测模型的评测。对于一个检测器,通常使用mAP(mean Average Precision)这一指标来评价一 个模型的好坏,这里的AP指的是一个类别的检测精度,mAP则是多个类别的平均精度。评测需要每张图片的预测值与标签值,对于某一个实例,二者包含的内容分别如下:
·预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分。
·标签值(GTs):物体类别、边框位置的4个真值。
在预测值与标签值的基础上,AP的具体计算过程如图1.14所示。我们首先将所有的预测框按照得分从高到低进行排序(因为得分越高的边框其对于真实物体的概率往往越大),然后从高到低遍历预测框。
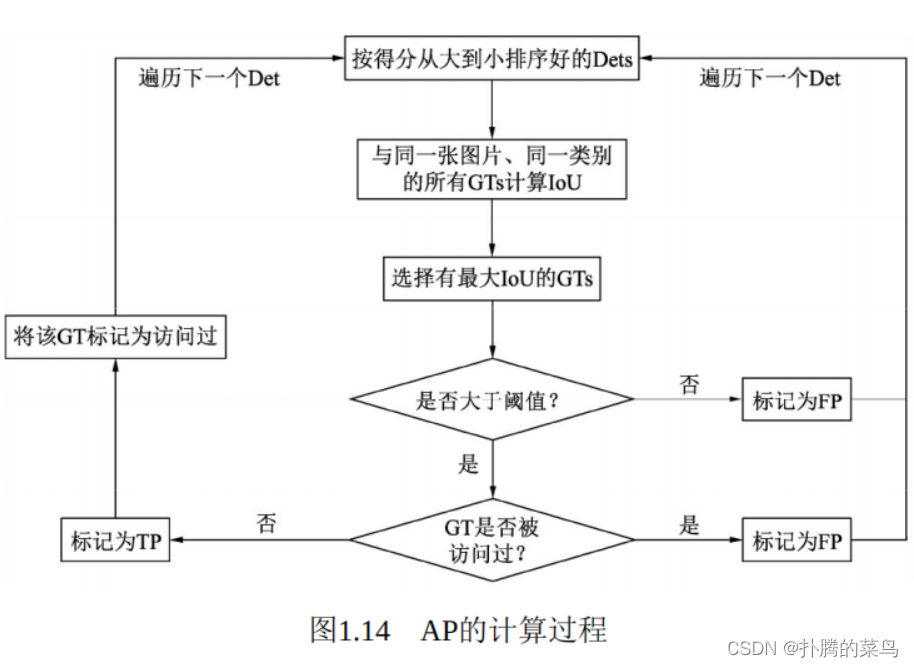
对于遍历中的某一个预测框,计算其与该图中同一类别的所有标签框GTs的IoU,并选取拥有最大IoU的GT作为当前预测框的匹配对象。如果该IoU小于阈值,则将当前的预测框标记为误检框FP。
如果该IoU大于阈值,还要看对应的标签框GT是否被访问过。如果前面已经有得分更高的预测框与该标签框对应了,即使现在的IoU大 阈值,也会被标记为FP。如果没有被访问过,则将当前预测框Det标记为正确检测框TP,并将该GT标记为访问过,以防止后面还有预测框与其对应。
在遍历完所有的预测框后,我们会得到每一个预测框的属性,即TP或FP。在遍历的过程中,我们可以通过当前TP的数量来计算模型的召回率(Recall,R),即当前一共检测出的标签框与所有标签框的比值,如式(1-2)所示。

除了召回率,还有一个重要指标是准确率(Precision,P),即当前遍历过的预测框中,属于正确预测边框的比值,如式(1-3)所示。

遍历到每一个预测框时,都可以生成一个对应的P与R,这两个值可以组成一个点(R,P),将所有的点绘制成曲线,即形成了P-R曲线,如图1.15所示。
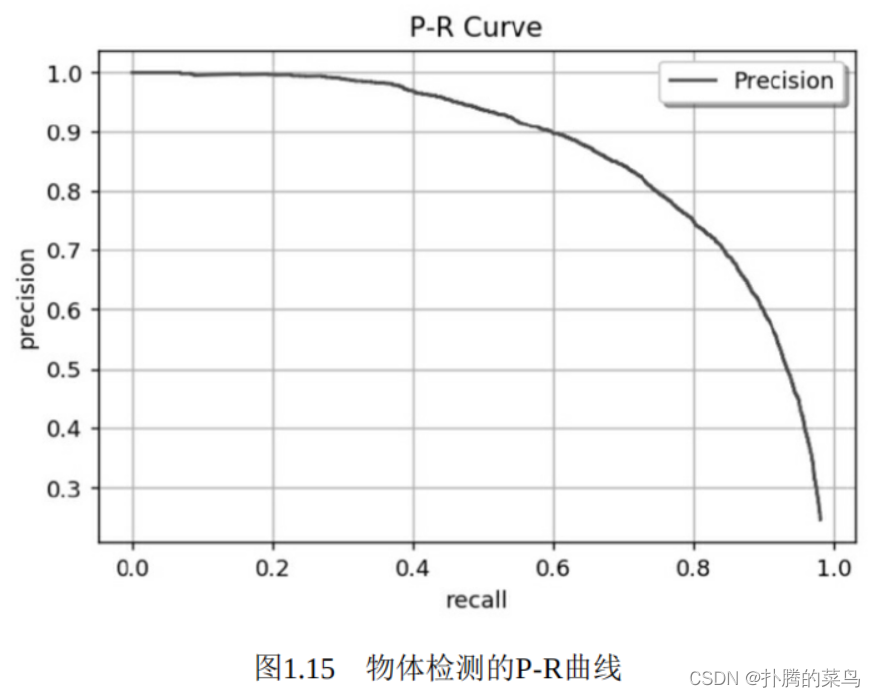
然而,即使有了P-R曲线,评价模型仍然不直观,如果直接取曲线上的点,在哪里选取都不合适,因为召回率高的时候准确率会很低,准确率高的时候往往召回率很低。这时,AP就派上用场了,计算公式如式(1-4)所示。

从公式中可以看出,AP代表了曲线的面积,综合考量了不同召回率下的准确率,不会对P与R有任何偏好。每个类别的AP是相互独立的,将每个类别的AP进行平均,即可得到mAP。严格意义上讲,还需 要对曲线进行一定的修正,再进行AP计算。除了求面积的方式,还可以使用11个不同召回率对应的准确率求平均的方式求AP。
下面从代码层面详细讲述AP求解过程。假设当前经过标签数据与 预测数据的加载,我们得到了下面两个变量:
·det_boxes:包含全部图像中所有类别的预测框,其中一个边框包含了[left,top,right,bottom,score,NameofImage]。
·gt_boxes:包含了全部图像中所有类别的标签,其中一个标签的内容为[left,top,right,bottom,0]。需要注意的是,最后一位0代表该标签有没有被匹配过,如果匹配过则会置为1,其他预测框再去匹配则为误检框。
下面是所有类别的评测过程。
for c in classes:
# 通过类别作为关键字,得到每个类别的预测、标签及总标签数
dects = det_boxes[c] # dects[0] = [left,top,right,bottom,score,NameofImage]
gt_class = gt_boxes[c] # gt_class[0][0] = [left,top,right,bottom,0]
npos = num_pos[c] # 指定类别的总标签数
# 利用得分作为关键字,对预测框按照得分从高到低排序
dects = sorted(dects, key=lambda conf: conf[4], reverse=True)
# 设置两个与预测边框长度相同的列表,标记是True Positive还是False Positive
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
# 对某一个类别的预测框进行遍历
for d in range(len(dects)):
# 将IoU默认置为最低
iouMax = sys.float_info.min
# 遍历与预测框同一图像中的同一类别的标签,计算IoU
if dects[d][-1] in gt_class:
for j in range(len(gt_class[dects[d][-1]])):
iou = Evaluator.iou(dects[d][:4], gt_class[dects[d][-1]][j][:4]
if iou > iouMax:
iouMax = iou
# 记录与预测有最大IoU的标签
jmax = j
# 如果最大IoU大于阈值,并且没有被匹配过,则赋予TP
if iouMax >= cfg['iouThreshold']:
if gt_class[dects[d][-1]][jmax][4] == 0:
TP[d] = 1
# 标记为匹配过
gt_class[dects[d][-1]][jmax][4] = 1
# 如果被匹配过,赋予FP
else:
FP[d] = 1
# 如果最大IoU没有超过阈值,赋予FP
else:
FP[d] = 1
# 如果对应图像中没有该类别的标签,赋予FP
else:
FP[d] = 1
# 利用NumPy的cumsum()函数,计算累计的FP与TP
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
# 得到每个点的Recall
rec = acc_TP / npos
# 得到每个点的Precision
prec = np.divide(acc_TP, (acc_FP + acc_TP))
# 利用Recall与Precision进一步计算得到AP
[ap, mpre, mrec, ii] = Evaluator.CalculateAveragePrecision(rec, prec)
3、PyTorch简介
工欲善其事,必先利其器。对于物体检测的学习,选择一个优秀的框架是一件十分重要的事情。
本节将会介绍PyTorch框架的诞生与发展历程,以及为什么选择PyTorch,最后将介绍多种安装PyTorch的方法。
1.3.1、诞生于特点
2017年的1月,来自于Facebook的研究人员在GitHub上推出了 PyTorch,并凭借其简洁易用的特性,迅速在人工智能的各大应用领域流行起来,一时间成为最炙手可热的深度学习框架。
PyTorch的前身是诞生于2002年的Torch框架。Torch使用了小众化的Lua作为编程接口,虽然对于深度神经网络的实现比较高效,但由于Lua使用人数不多,Torch并没有受到广泛的关注。而在计算科学领域, Python由于其简单易用与完整的生态,优势渐渐体现了出来。在此基础 上,2017年Facebook的团队对Torch张量之上的所有模块进行了重构, 并增加了自动求导这一先进的理念,实现了一个高效的动态图框架 PyTorch。
在2018年NeurIPS大会上,Facebook推出了PyTorch 1.0版本,该版本吸收了Caffe 2和ONNX模块化及面向生产的特点,使得算法可以从研究原型快速无缝衔接到生产部署中。这意味着,PyTorch的生态将更加完备,在进行算法原型研究、移动部署时将更加便利。
1.3.2、各大深度学习框架对比
为了更好地支持深度学习算法的研究与落地,各大公司和研究机构陆续推出了多种深度学习框架,除了PyTorch之外,还有几种知名的框架,如TensorFlow、MXNet、Keras、Caffe和Theano等,广泛应用于计算机视觉、自然语言处理、语音识别等领域,如图1.16所示。

不同的深度学习框架通常有不同的设计理念,优势和劣势也各不相同。
1.TensorFlow简介
2015年,谷歌大脑(Google Brain)团队推出了深度学习开源框架 TensorFlow,其前身是谷歌的DistBelief框架。凭借其优越的性能与谷歌在深度学习领域的巨大影响力,TensorFlow一经推出就引起了广泛的关注,逐渐成为用户最多的深度学习框架。
TensorFlow使用数据流图进行网络计算,图中的节点代表具体的数学运算,边则代表了节点之间流动的多维张量Tensor。TensorFlow有 Python与C++两种编程接口,并且随着发展,也渐渐支持Java、Go等语言,并且可以在ARM移动式平台上进行编译与优化,因此,TensorFlow拥有非常完备的生态与生产环境。
TensorFlow的优点很明显,功能完全,对于多GPU的支持更好,有强大且活跃的社区,并且拥有强大的可视化工具TensorBoard。当然, 其缺点在于系统设计较为复杂,接口变动较快,兼容性较差,并且由于其构造的图是静态的,导致图必须先编译再执行,不利于算法的预揽等。
2.MXNet简介
MXNet由DMLC(Distributed Machine Learning Community)组织创建,该组织成员以陈天奇、李沐为代表,大部分都为中国人。MXNet项目于2015年在GitHub上正式开源,于2016年被亚马逊AWS正式选择为其云计算的官方深度学习平台,并在2017年进入Apache软件基金会,正式成为了Apache的孵化器项目。
MXNet的特色是将命令式编程与声明式编程进行结合,在命令式编程上提供了张量计算,在声明式编程上支持符号表达式,用户可以自由地进行选择。此外,MXNet提供了多种语言接口,有超强的分布式支持,对于内存和显存做了大量优化,尤其适用于分布式环境中。
但是,MXNet的推广不够有力,文档的更新没有跟上框架的迭代速度,导致新手上手MXNet较难,因此MXNet也一直没有得到大规模的应 用。目前国内的众多AI创业公司都在使用MXNet框架。
3.Keras简介
Keras是建立在TensorFlow、Theano及CNTK等多个框架之上的神经网络API,对深度学习的底层框架作了进一步封装,提供了更为简洁、易上手的API。Keras使用Python语言,并且可以在CPU与GPU间无缝切换。
Keras的首要设计原则就是用户的使用体验,把神经网络模块化,因此Keras使用相对简单,入门快。但是,Keras构建于第三方框架之上,导致其灵活性不足,调试不方便,用户在使用时也很难学习到神经网络真正的内容。从性能角度看,Keras也是较慢的一个框架。
4.Caffe与Caffe 2简介
Caffe(Convolutional Architecture for Fast Feature Embedding)发布于2013年,作者是贾扬清博士。Caffe的核心语言是C++,支持CPU与GPU两种模式的计算。Caffe的优点是设计清晰、实现高效,尤其是对于C++的支持,使工程师可以方便地在各种工程应用中部署Caffe模型, 曾经占据了神经网络框架的半壁江山。
Caffe的主要缺点是灵活性不足。在Caffe中,实现一个神经网络新层,需要利用C++来完成前向传播与反向传播的代码,并且需要编写CUDA代码实现在GPU端的计算,总体上更偏底层,显然与当前深度学习框架动态图、灵活性的发展趋势不符。
在2017年,Facebook推出了Caffe 2,主要开发者仍然是贾扬清博 士。Caffe 2是一个轻量化与跨平台的深度学习框架,继承了Caffe大量的设计理念,同时为移动端部署做了很多优化,性能极佳。Caffe 2的核心库是C++,但也提供了Python的API,可以方便地在多个平台进行模型训练与部署。
作为Facebook推出的框架,Caffe 2的优点是高性能与跨平台部署。PyTorch的优点是灵活性与原型的快速实现。为了进一步提升开发者的效率,Facebook于2018年宣布将Caffe 2代码全部并入PyTorch。
1.3.3、为什么选择PyTorch
前面介绍的深度学习框架多多少少都有一些缺陷,而PyTorch作为后起之秀,是一个难得的集简洁与高性能于一身的一个框架,笔者在本书中选择PyTorch来实现物体检测算法,主要原因有4点,如图1.17所示。
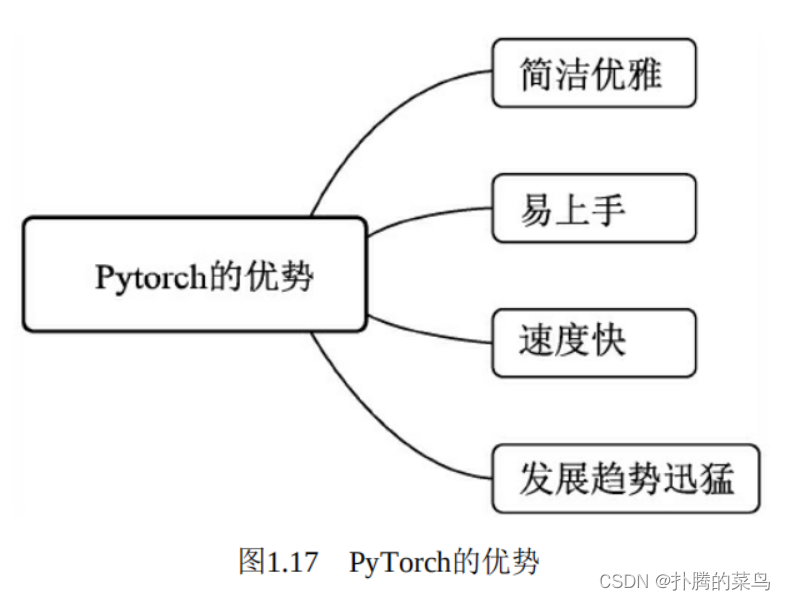
·简洁优雅:PyTorch是一个十分Pythonic的框架,代码风格与普通的Python代码很像,甚至可以看做是带有GPU优化的NumPy模块,这使得使用者很容易理解模型的框架与逻辑。此外,PyTorch是一个动态图框架,拥有自动求导机制,对神经网络有着尽量少的概念抽象,这使得使用者更容易调试、了解模型的每一步到底发生了什么,而不至于是一个黑箱。
·易上手:PyTorch与Python一样,追求用户的使用体验,所有的接口都十分易用,对于使用者极为友好。与Keras不同的是,在接口易用的同时,PyTorch很难得地保留了灵活性,使用者可以利用PyTorch自由地实现自己的算法。另外,PyTorch的文档简洁又精髓,建议初学者可以通读一遍。
·速度快:PyTorch在追求简洁易用的同时,在模型的速度表现上也极为出色,相比TensorFlow等框架,很多模型在PyTorch上的实现可能会更快。这一点也使得学术界有大量PyTorch的忠实用户,因为使用PyTorch既可以快速实现自己的想法,又能够保证优秀的速度性能。
·发展趋势:PyTorch在问世的两年多时间里,发展趋势十分迅猛, fast.ai、NVIDIA等知名公司也选择使用PyTorch作为深度学习框架。 PyTorch背后是Facebook人工智能研究院,有这一顶级AI机构强有力的支持,生态完备,尤其是在Caffe 2并入PyTorch之后,PyTorch未来的发展值得期待。
1.3.4、安装方法
PyTorch目前支持Ubuntu、Mac OS、Windows等多个系统,本书将主要围绕Ubuntu系统进行讲解。PyTorch官网中提供了pip、Conda、源码等多种安装方法,由于源码安装较为复杂,通常情况下使用不到,在此只介绍pip与Conda两种安装方法。
由于本书介绍的物体检测算法模型通常较大,因此我们需要使用带有GPU加速版本的PyTorch。在安装PyTorch之前,你需要有一台带有GPU的机器,并从NVIDIA官网下载安装对应的显卡驱动,在终端中输入以下命令可以证明驱动已装好,并显示GPU的内存、使用情况等信息:
nvidia-smi
在安装完显卡驱动后,我们还需要安装CUDA(Compute Unified Device Architecture)。CUDA是NVIDIA推出的通用并行计算架构,可以使类似于PyTorch之类的深度学习框架调用GPU来解决复杂的计算问题。
为了实现更高效的GPU并行计算,通常我们还需要安装cuDNN库。 cuDNN库是由NVIDIA开发的专用于深度神经网络的GPU加速库。由于CUDA与cuDNN的安装较为简单,在此就不展开了,读者可以参考官网教程进行安装。在完成上述步骤后,即可使用pip或者Conda安装 PyTorch。
1.pip安装
pip是一个通用的Python包管理工具,可以便捷地实现Python包的查找、下载、安装与卸载。使用pip安装PyTorch的方法可以参考官网教程,我们以Python 3.6、CUDA 9.0、PyTorch 0.4.0为例,使用下面的指令即可完成PyTorch安装:
pip3 install torch==0.4.0
安装后,在终端中输入python3,再输入以下指令:
>>> import torch
>>> torch.cuda.is_available() #判断当前GPU是否可用
True
如果没有报错,则表明PyTorch安装成功。
2.Conda安装
Conda是一个开源的软件管理包系统和环境管理系统,可以安装多个版本的软件包,并在其间自由切换。相比于pip,Conda功能更为强大,可以提供多个Python环境,并且解决包依赖的能力更强。我们可以通过安装Anaconda来使用Conda,安装方式可以参考官网教程,在此不再展开介绍。
安装好Conda后,可以使用如下指令安装PyTorch。
conda install pytorch=0.4.0 cuda90 -c pytorch
注意:在使用pip或者Conda安装软件包时,如果下载速度较慢,可以考虑将pip或者Conda的源更换为国内的源,这样速度会更快。
4、基础知识准备
在后续的物体检测学习过程中,我们会涉及数据集的操作,以及模型的设计、优化、训练与评测等,这些内容都需要有一定的Linux基础。此外,PyTorch框架使用了Python作为基本编程语言,因此读者也需要具备一定的Python基础。
因此,本节将会简要地介绍本书所需的Linux与Python基础,并介绍几种笔者认为十分好用的工具,可以极大地方便读者的学习。
1.4.1、Linux基础
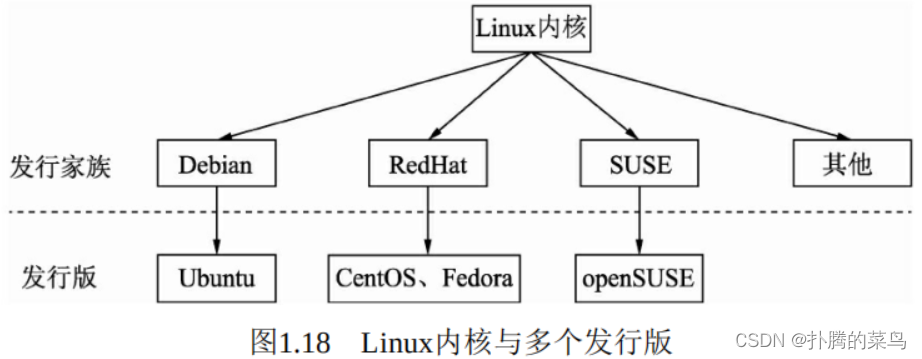
Linux诞生于1991年,是一个免费使用与自由传播的类UNIX操作系统,凭借其稳定的性能与开放的社区,在手机、电脑、超级计算机等各种计算机设备中都能看到Linux的身影。我们现今使用的更多是Linux发 行版系统,即将Linux内核与应用软件做了打包,并进行依赖管理,如 Ubuntu、CentOS和Fedora等。Linux内核与发行版系统的关系如图1.18所示。需要注意的是,Linux内核是独立的程序,每个发行版维护自己修改的内核。
由于Linux系统知识树很大,本节不可能对所有知识点都覆盖到,因此这里将简要介绍基本目录结构和环境变量这两个知识点。
1.基本目录结构
Linux的首要思想是“一切都是文件”,数据与程序都是以文件形式存在,甚至是主机与外围众多设备之间的交互也抽象成对文件的操作, 因此对于Linux系统,我们首先需要了解其目录树结构。为了统一各大Linux发行版对目录文件的定义,FHS结构在1994年对Linux根目录做了统一的规范,必须包含boot、lib、home、usr和opt等文件。下面对几个主要的目录进行说明:
·boot:Linux系统启动时用到的文件,建议单独分区,大小512MB即可。
·lib:系统使用到的函数库目录,协助系统中程序的执行,比较重要的有lib/modules目录,存放着内存文件。
·bin:可执行的文件目录,包含了如ls、mv和cat等常用的命令。
·home:默认的用户目录,包含了所有用户的目录与数据,建议设置较大的磁盘空间。
·usr:应用程序存放的目录,其中,usr/local目录下存放一些软件升级包,如Python、CUDA等,usr/lib目录下存放一些不能直接运行但却是其他程序不可或缺的库文件,usr/share目录下存放一些共享的数据。
·opt:额外安装的软件所在的目录,例如常用的ROS可执行文件, 一般就存放在opt/ros目录下。
2.环境变量
环境变量,通俗讲是指操作系统执行程序时默认设定的参数,如各种可执行文件、库的路径等。在本书中,我们将会用到Python、 PyTorch和CUDA等多个库,具体使用时调用的是哪一个版本的库,需要设定环境变量。
环境变量有系统级与用户级之分。系统级的环境变量是每一个登录到系统的用户都要读取的变量,可通过以下两个文件进行设置:
·/etc/environment:用于为所有进程设置环境变量,是系统登录时读取的第一个文件,与登录用户无关,一般要重启系统才会生效。
·/etc/profile:用于设置针对系统所有用户的环境变量,是系统登录时读取的第二个文件,与登录用户有关。
用户级环境变量是指针对当前登录用户设定的环境变量,也可以通过两个文件进行设置:
·~/.profile:对应当前用户的profile文件,用于设置当前用户的工作环境,默认执行一次。
·~/.bashrc:对应当前用户的bash初始化文件,每打开一个终端,就会被执行一次。
我们可以在终端中使用echo来查看当前的环境变量,例如:
echo $PYTHONPATH
如果想永久性地设置环境变量,可以在上述的多种文件中添加环境变量。例如我们想指定使用的Python路径,可以修改~/.bashrc文件,在最下方添加:
export PYTHONPATH=/home/yourpythonpath:$PYTHONPATH
在终端中执行source ~/.bashrc即可生效。
如果仅仅是临时设置环境变量,可以在终端中使用set或者export命令,这种方式只在当前终端中生效,对其他终端无效。
export PYTHONPATH=/home/yourpythonpath
1.4.2、Python基础
Python是一种面向对象的动态类型语言,得益于其优雅、简单与明确的设计哲学。自20世纪90年代诞生到现在,Python在人工智能、大数据、网页处理等领域取得了大规模的应用,也是当今最炙手可热的语言之一。Python也是PyTorch深度学习框架的第一语言。
本节将用尽量简短的篇幅,介绍Python语言的一些重要特性与使用方法。
1.变量与对象
掌握一门语言,首先要了解其对于变量与对象的定义。在Python中,变量与对象的概念分别如下:
·对象:内存中存储数据的实体,有明确的类型。Python中的一切都是对象,函数也属于对象。
·变量:指向对象的指针,对对象的引用。作为弱类型语言,Python 中的变量是没有类型的。
>>> a = 1 # 这里1为对象,a是指向对象1的变量
>>> a = 'hello' # 变量a可以指向任意的对象,没有类型限制
>>> a
'hello'
Python中的对象还可以进一步分为可变对象与不可变对象,这一点尤其要注意。
·不可变对象:对象对应内存中的值不会变,因此如果指向该对象的变量被改变了,Pyhton则会重新开辟一片内存,变量再指向这个新的内存,包括int、float、str、tuple等。
·可变对象:对象对应内存中的值可以改变,因此变量改变后,该 对象也会改变,即原地修改,如list、dict、set等。
对于不可变对象,所有指向该对象的变量在内存中共用一个地址:
>>> a = 1
>>> b = 1
>>> c = a + 0
# 使用id()函数来查看3个变量的内存地址
>>> id(a) == id(b) and id(a) == id(c)
True
如果修改了不可变对象的变量的值,则原对象的其他变量不变;相比之下,如果修改了可变对象的变量,则相当于可变对象被修改了,其他变量也会发生变化。
>>> a = 1
>>> b = a
>>> b = 2
# 由于a与b指向的1都是不可变对象,因此改变b的值与a没有关系
>>> a
1
>>> c = [1]
>>> d = c
# c与d指向的是相同的可变对象,d的操作是原地修改
>>> d.append(2)
>>> c
[1, 2]
注意:当对象的引用计数为0时,该对象对应的内存会被回收。
Python中的变量也存在深拷贝与浅拷贝的区别,不可变对象无论深/ 浅拷贝,其地址都是一样的,而可变对象则存在3种情况,下面以list为例。
·直接赋值:仅仅拷贝了引用,因此前后变量没有任何隔离,原list改变,拷贝的变量也会发生变化。
·浅拷贝:使用copy()函数,拷贝了list最外围,而list内部的对象仍然是引用。
·深拷贝:使用deepcopy()函数,list内外围均为拷贝,因此前后的变量完全隔离,而非引用。
# 实现拷贝需要首先引入copy模块
>>> import copy
>>> a = [1, 2, [1, 2]]
>>> b = a # 直接赋值,变量前后没有隔离
>>> c = copy.copy(a) # 浅拷贝
>>> d = a[:] # 相当于浅拷贝,与c相同
>>> e = copy.deepcopy(a) # 深拷贝,前后两个变量完全隔离
>>> a.append(3)
>>> a[2].append(3)
>>> a, b
([1, 2, [1, 2, 3], 3], [1, 2, [1, 2, 3], 3])
>>> c
[1, 2, [1, 2, 3]]
>>> d
[1, 2, [1, 2, 3]]
>>> e
[1, 2, [1, 2]]
2.作用域
Python程序在创建、访问、改变一个变量时,都是在一个保存该变量的空间内进行的,这个空间为命名空间,也叫作用域。Python的作用域是静态的,变量被赋值、创建的位置决定了其被访问的范围,即变量的作用域由其所在的位置决定。
a = 1 # a为全局变量
def local(): # local也是全局变量,在全局作用域中
b = 2 # b为局部变量
在Python中,使用一个变量时并不严格要求必须预先声明这个变量,但是在真正使用这个变量之前,它必须被绑定到某个内存对象(被定义、赋值)中。这种变量名的绑定将在当前作用域中引入新的变量,同时屏蔽外层作用域中的同名变量。
a = 1
def local():
a = 2 # 由于Python不需要预先声明,因此在局部作用域引入了新的变量,而没有修改全局
local()
print(a) # 这里a的值仍为1
上述例子中局部变量是无法修改全局变量的。想要实现局部修改全局变量,通常有两种办法,增加globa等关键字,或者使用list和dict等可变对象的内置函数。
a = 1
b = [1]
def local():
global a # 使用global关键字,表明在局部使用的是全局的a变量
a = 2
b.append(2) # 对于可变对象,使用内置函数则会修改全局变量
local()
print(a) # 这里a的值已经被改变为2
print(b) # 这里输出的是[1, 2]
Python的作用域从内而外,可以分为Local(局部)、Enclosed(嵌 套)、Global(全局)及Built-in(内置)4种,如图1.19所示。变量的搜索遵循LEGB原则,如果一直搜索不到则会报错。
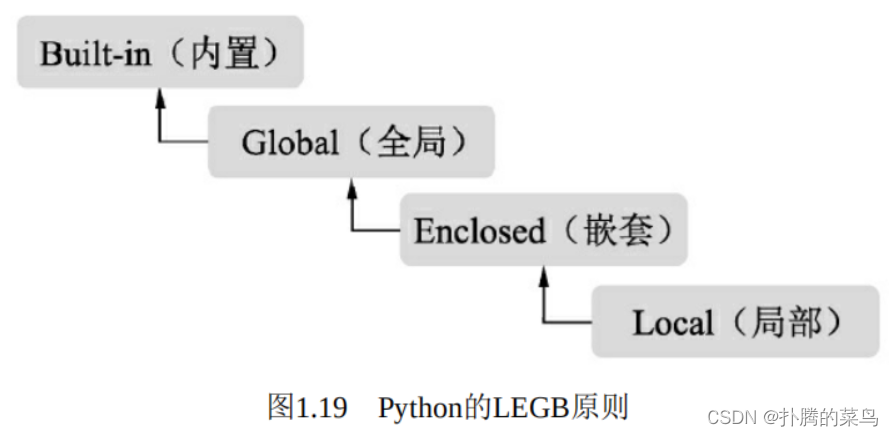
这4种作用域的含义如下:
·局部:在函数与类中,每当调用函数时都会创建一个局部作用域,局部变量域像一个栈,仅仅是暂时存在,依赖于创建该局部作用域的函数是否处于活动的状态。
·嵌套:一般出现在函数中嵌套了一个函数时,在外围函数中的作用域称为嵌套作用域,主要目的是为了实现闭包。
·全局:模型文件顶层声明的变量具有全局作用域,从外部看来,模块的全局变量就是一个模块对象的属性,全局作用域仅限于单个模块的文件中。
·内置:系统内解释器定义的变量。这种变量的作用域是解释器在则在,解释器亡则亡。
3.高阶函数
在编程语言中,高阶函数是指接受函数作为输入或者输出的函数。 对于Python而言,函数是一等对象,即可以赋值给变量、添加到集合中、传参到函数中,也可以作为函数的返回值。下面介绍map()、reduce()、filter()和sorted()这4种常见的高阶函数。
首先,Python中的变量可以指向函数:
>>> f = abs
>>> f(-1) # 这里的f(-1)等同于abs(-1)
1
map()函数可以将一个函数映射作用到可迭代的序列中,并返回函数输出的序列:
>>> def f(x): return x * x
>>> map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) # 将定义的函数f依次作用于列表的各个元素
[1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> map(str, range(4))
['0', '1', '2', '3']
reduce()函数与map()函数不同,其输入的函数需要传入两个参数。 reduce()的过程是先使用输入函数对序列中的前两个元素进行操作,得到的结果再和第三个元素进行运算,直到最后一个元素。
# reduce的计算过程:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
>>> from functools import reduce # 需要从functools引入reduce函数
>>> def f(x, y): return x*10+y
>>> reduce(f, [1, 3, 5, 7, 9])
13579
filter()函数的作用主要是通过输入函数对可迭代序列进行过滤,并返回满足过滤条件的可迭代序列。
>>> def is_odd(n): return n % 2 == 0
>>> filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]) # 对奇偶过滤,保留偶数
[2, 4, 6, 10]
sorted()函数可以完成对可迭代序列的排序。与列表本身自带的sort()函数不同,这里的sorted()函数返回的是一个新的列表。sorted()函数可以传入关键字key来指定排序的标准,参数reverse代表是否反向。
sorted([3, 5, -87, 0, -21], key=abs, reverse=True) # 绝对值排序,并且为反序
[-87, -21, 5, 3, 0]
对于一些简单逻辑函数,可以使用lambda匿名表达式来取代函数的定义,这样可以节省函数名称的定义,以及简化代码的可读性等。
>>> add = lambda x, y : x+y # 使用lamda方便地实现add函数
>>> add(1,2)
3
>>> map(lambda x: x+1, [1, 2, 3, 4, 5, 6, 7, 8, 9]) # lamda实现元素加1的操作
[2, 3, 4, 5, 6, 7, 8, 9, 10]
4.迭代器与生成器
迭代器(Iterator)与生成器(Generator)是Python最强大的功能之一,尤其是在处理大规模数据序列时,会带来诸多便利。在检测模型训练时,图像与标签数据的加载通常就是利用迭代生成器实现的。
迭代器不要求事先准备好整个迭代过程中所有的元素,可以使用next()来访问元素。Python中的容器,如list、dict和set等,都属于可迭代对象,对于这些容器,我们可以使用iter()函数封装成迭代器。
>>> x = [1, 2, 3]
>>> y = iter(x)
>>> z = iter(x)
>>> next(y), next(y), next(z) # 迭代器之间相互独立
(1, 2, 1)
实际上,任何实现了_iter_()和_next_()方法的对象都是迭代器,其中_iter_()方法返回迭代器本身,_next_()方法返回容器中的下一个值。for循环本质上也是一个迭代器的实现,作用于可迭代对象,在遍历时自动调用next()函数来获取下一个元素。
生成器是迭代器的一种,可以控制循环遍历的过程,实现一边循环一边计算,并使用yield来返回函数值,每次调用到yield会暂停。生成器迭代的序列可以不是完整的,从而可以节省出大量的内存空间。
有多种创建迭代器的方法,最简单的是使用生成器表达式,与list很相似,只不过使用()括号。
>>> a = (x for x in range(10)) # 利用()括号实现了一个简单的生成器
>>> next(a), next(a)
(0, 1)
最为常见的是使用yield关键字来创建一个生成器。例如下面代码中,第一次调用f()函数会返回1并保持住,第二次调用f()会继续执行,并返回2。
>>> def f():
... yield 1
... yield 2
... yield 3
>>> f1 = f()
>>> print([next(f1) for i in range(2)])
[1, 2]
使用生成器还可以便捷地实现斐波那契数列的生成,如下:
def fibonacci():
a = [1, 1]
while True:
# 往列表里添加下一个元素
a.append(sum(a))
# 取出第0个元素,并停留在当前执行点
yield a.pop(0)
for x in fibonacci():
print(x)
if x > 50:
# 仅打印小于50的数字
break
执行上述代码,则会生成小于50的斐波那契数列的数字。
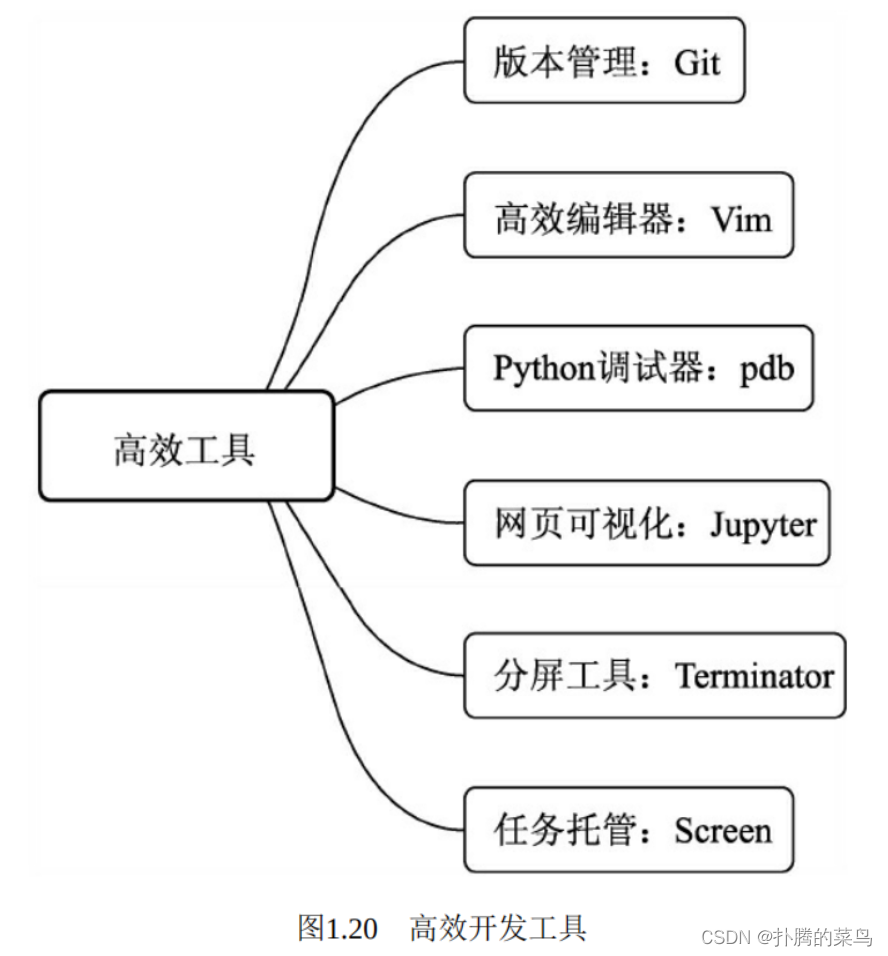
1.4.3、高效开发工具
为了更好地探索深度学习,享受coding的乐趣,笔者在此推荐几种日常使用的工具,可以起到事半功倍的效果,如图1.20所示。
1.版本管理:Git
Git是一个开源的分布式版本控制系统,用于高效敏捷开发工程项目。有了Git,开发人员就不必将不同版本的文件复制成不同的副本, 而是可以通过Git系统的版本控制来完成,尤其是在多人协同开发时,会提供诸多便利。在深度学习领域,大部分的模型与工程都是使用Git 进行维护开发的,包括本书的代码,因此希望每一位读者都能打好Git 的基础,受用终生。
Git目前支持Linux、Mac OS、Windows等系统,在此我们以Ubuntu 系统为例。
利用如下指令即可进行Git的安装。。
sudo apt install git
安装完后,为了使用便捷,可以利用git config指令来配置自己的邮箱与密码信息,具体如下:
git config --global user.name "your name"
git config --global user.email "youremail@youremail.com"
使用git init指令可以初始化一个Git仓库,执行后会在当前目录中生成一个.git目录,其中保存了所有有关Git的数据,但切勿手动更改.git里的文件。
Git根据文件的存在位置,有工作区、暂存区与版本库区3个概念,如图1.21所示。
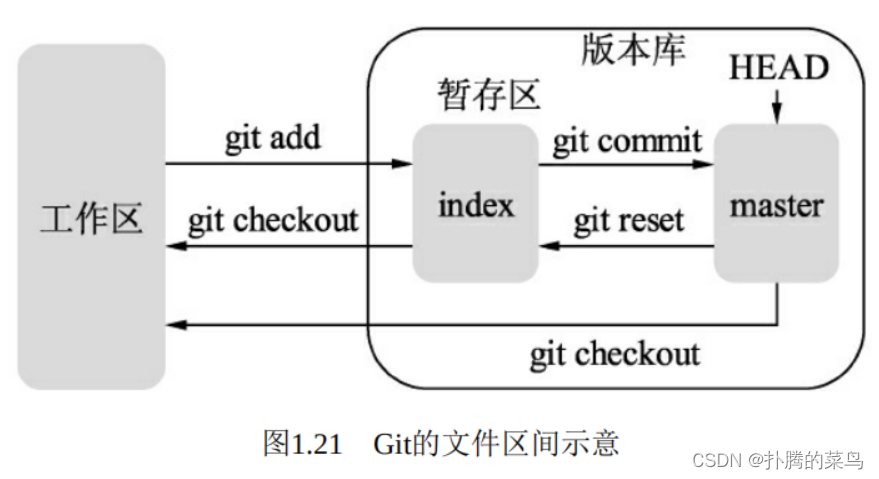
·工作区:计算机里能看到的实际目录。工作区修改后执行git add命令,暂存区的内容会被更新,修改或者新增的文件会被写入git对象区,将对象的ID记录在暂存区的索引中。
·暂存区:有时也叫做索引(index),一般存放在.git目录下的index文件中。当执行git commit操作后,暂存区的目录会被写入版本库中, master会做相应的更新。而当执行git checkout与对应的文件时,暂存区的文件会覆盖工作区的文件,清除工作区中还没有添加到暂存区的改动。
·版本库区:工作区下会存在一个.git目录,称之为版本库区。当执 行git reset指令时,版本库区的目录树会替换暂存区的目录,但是工作区不受影响。当执行git checkout HEAD时,HEAD指向的master分支会覆盖工作区及暂存区的文件,这个指令较为危险,容易把没有提交的文件清除掉。
当多人协同开发或者需要有多个不同的版本时,就需要用到Git的分支管理功能了,这也是Git极为强大与重要的功能之一。版本管理主要有以下4个指令:
git branch branchname # 创建一个名为branchname的分支
git checkout branchname # 切换到branchname的分支,git branch也可以查看当前的Git分支
git checkout -b branchname # 创建一个名为branchname的分支,并切换到该分支,十分常用
git merge # 合并分支
当然,Git还有git log、git status等重要的指令,在此不一一展开。 如果想要使用远程的Git仓库,不依赖于本地计算机,并进行仓库的社交,GitHub就派上用场了。
GitHub是一个基于Git的代码托管平台,是目前最为流行的代码托管服务,已拥有超过400万个项目。如果想要使用GitHub,首先需要在其官网注册一个账号,并使用创建仓库的命令创建名为repository的仓库。
为了能将自己本地的代码提交到GitHub上,还需要添加GitHub账号可以识别的秘钥,具体指令如下:
ssh-keygen -t rsa -C "youremail@youremail.com"
上述邮箱为注册GitHub时使用的邮箱。执行上述指令后,一路按回车键,会在~/.ssh文件夹下生成id_rsa.pub文件,复制里边的秘钥并粘贴到GitHub账号的SSH Keys里,即可实现本地与GitHub仓库的配对。
完成配对后,可以使用git clone命令将远程仓库拉取到本地。
git clone username@host:/path/to/repository
在本地进行代码的开发,并以此执行git add、git commit命令后,使用git push可以实现将本地版本仓库内的代码推到GitHub上。
git push origin master
总之,Git与GitHub的功能很强大,以上也仅仅做了简要的介绍,相信读者在日后的开发中会渐渐掌握更多的Git知识,领悟Git的威力。
2.高效编辑器:Vim
Vim是一个功能强大且可以定制功能的文本编辑器,尤其适用于面向程序开发,提供了代码补全、编译及错误跳转等功能。Vim由Vi发展而来,Vi是Linux与UNIX系统中最基本的文本编辑器,Vim对Vi进行了诸多改良,在2000年赢得了Slashdot Beanie的最佳开放源代码编辑器大奖。
也许有很多读者喜欢使用如Visual Studio、Clion等IDE软件来进行程序开发,但是在深度学习模型开发中,很多时候我们会把模型放到远程服务器中,这时IDE就不适用了。此外,IDE较大,在很多平台中安装并不方便,并且调试开发程序不灵活,开发人员也无法掌握其编译、 配置的精髓。因此,在本书的学习中,Vim编辑器是一个必备的工具。
在Linux终端中,使用vim file命令即可以打开一个Vim环境。Vim有下面3种基本模式。
·命令模式:刚打开Vim时就进入了命令模式,此时敲入任何字母都代表了命令,而不是直接插入到光标处。命令模式下有一些常用的基本命令,可以有效提升开发者的效率。
·输入模式:在命令模式中输入i字符就进入了输入模式,在该模式下可以进行代码的增、删等操作。
·底线命令模式:在命令模式下输入“:”(英文冒号)即进入底线命令模式,这里有更为丰富的命令,如保存、退出和跳转等。
以上3种模式的切换方式如图1.22所示。

下面介绍一些常用的Vim命令。首先是从命令模式到输入模式的切换,为了快速锁定插入代码的位置,会有不同的需求,这里列举了常见的5种切换方式,如表1.1所示

在Vim中,我们经常需要上下移动光标,浏览程序,这时就需要快速跳转的功能。这里列举几种常见的光标移动方式,如表1.2所示。

当然,Vim对于复制、搜索、保存等方式也有方便的处理方法,这里统一放到了表1.3中。限于篇幅,Vim更丰富、有趣的功能,还有待读者自己去发现、探索。

3.Python调试器:pdb
对于开发人员来说,调试可以便于查看程序运行的过程,定位程序运行的错误,是一项十分重要的技能。此外,深度学习算法通常会使用远程服务器的形式进行开发,这时使用类似于Pycharm的IDE进行调试的方法也不适用了。所以,如果你还在继续使用print()函数来调试Python程序的话,你需要了解一个新的工具:pdb。
pdb是Python自带的一个库,可以提供交互式的调试功能,提供了断点设置、单步调试、源码查看、堆栈查看等丰富的功能。pdb类似于C++中的gdb调试工具。通常有两种方式来使用pdb,第一种方式是在命令行中加入pdb模块来启动Python程序,如下:
python3 -m pdb test.py
这种方式会从程序第一行开始就进入交互环境,适用于较小的程序调试。在更大型的工程里,我们更习惯用插入断点的方式进行调试,如下:
import pdb
pdb.set_trace()
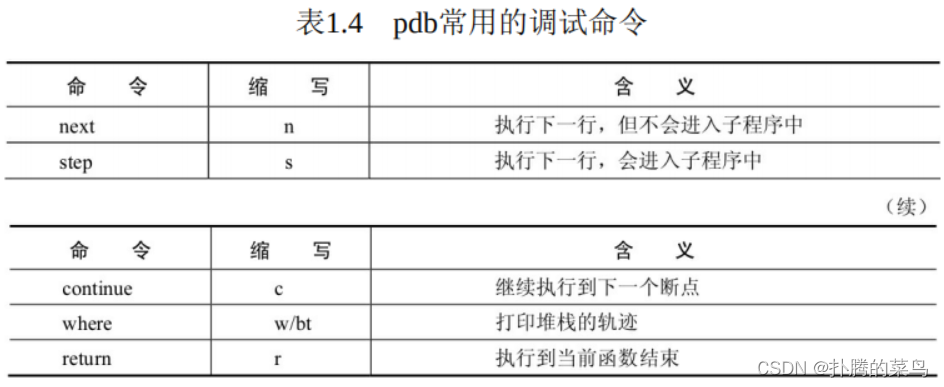
将set_trace()函数放到代码中的任何地方,执行程序时都会在此处产生一个断点,尤其是在使用PyTorch这种极度Python化的框架时,使用极为方便。pdb主要的调试命令如表1.4所示。
4.网页可视化:Jupyter
Jupyter Notebook是一个基于Web应用的交互式笔记本,使用者可以方便地在Web端与Python程序进行交互,以及进行数据的可视化与分析。Jupyter由IPython Notebook发展而来,现已支持40多种编程语言。 在学习深度学习及物体检测算法中,使用Jupyter主要有两点好处。
·数据可视化:Jupyter的交互界面简洁优雅,并且对Python的多种可视化库提供了支持,如Matplotlib、Pillow、Pandas等,这对于训练数据的分析、模型的评测等都提供了极大的帮助。物体检测本身也是视觉任务,可视化是一个至关重要的部分。
·远程访问:为了使用更多的GPU资源,我们通常会将训练任务提交到服务器中,导致无法轻易地访问查看服务器数据。对于Jupyter而 言,只需在服务器中开启Notebook服务,即可在本地的浏览器端进行访问,并且对于系统、环境都没有限制。
使用pip工具可以轻松地安装Jupyter,代码如下:
# Python 2
pip2 install Jupyter
# Python 3
pip3 install Jupyter
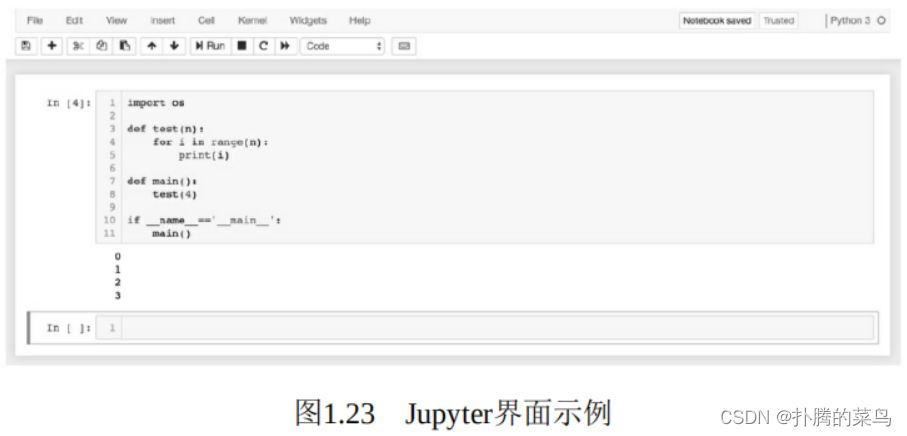
安装成功后,在需要操作的目录下输入jupyter notebook即可开启Jupyter服务。如果是在本地执行的服务,则可以在浏览器中输入http://127.0.0.1:8000,即可打开Jupyter界面,如图1.23所示。
Jupyter默认使用8000端口,如果是在远程服务器开启的服务,则浏览器中的IP也要相应地修改为服务器的IP。
Jupyter也可以设置访问密码,并且支持Markdown语法。Jupyter还有很多丰富有趣的功能,由于篇幅有限,其他功能留给读者自己去探索。
5.分屏工具:Terminator
对于Ubuntu系统的使用者而言,在进行程序的开发、执行时经常需要打开多个终端界面,这时终端分屏的功能可以避免界面的来回切换。 然而Ubuntu自带的终端Terminal并不支持分屏功能,因此推荐一个替代终端:Terminator,可以轻松地实现终端分屏和切换等操作,界面如图 1.24所示。

Terminator的安装极为方便,使用apt或者apt-get即可完成安装,命令如下:
sudo apt install terminator
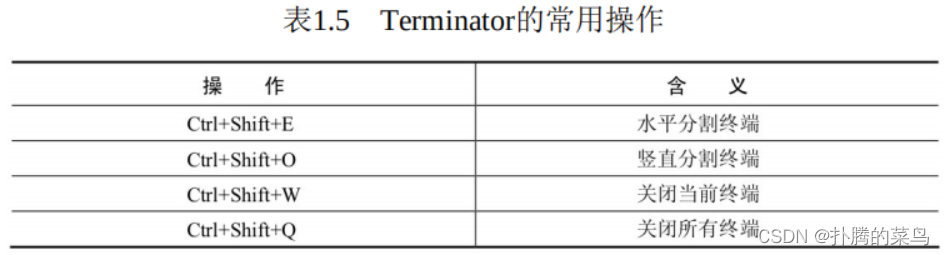
安装完成后,按Ctrl+Shift+T键即可打开Terminator。Terminator常见的操作快捷键如表1.5所示。
6.任务托管:Screen
在远程服务器中,我们通常使用终端的脚本命令来执行模型的训练。训练通常会有几天时间,这时如果网络出现异常,或者有事需要关掉终端时,终端任务也会被杀掉,这显然不是我们想要看到的。因此, 我们需要将任务托管到后台执行,这时Screen就派上用场了。
Screen是一款由GNU开发的软件,可用于多个命令行终端之间的自由切换与管理。即使网络断开,只要Screen本身没有停止,其内部执行的会话将一直保留。Screen软件可通过apt快速进行安装,如下:
sudo apt install screen
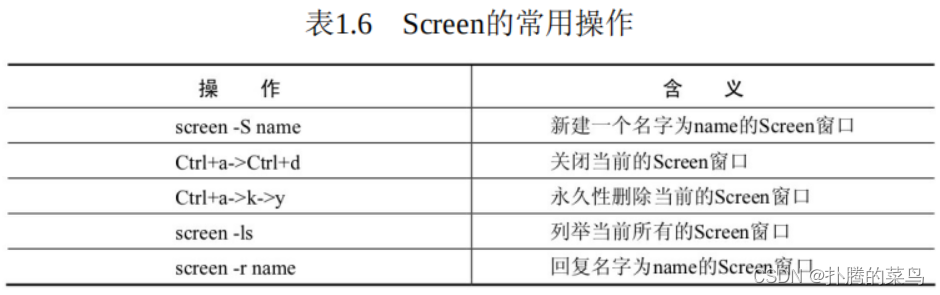
Screen软件的打开、关闭都十分简单,具体操作如表1.6所示。
















 2001
2001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











