






目录
1.安装CV2 (确保已经安装Anconde并配置环境)
pip install opencv-python最好确保numpy也正常安装
pip install numpy
2.读取图片,并显示和保存
在Python的OpenCV库中,读取图片的常用方法有以下几种:
- 使用imread()函数读取图片。
- 使用imshow()函数显示图片。
- 使用waitKey()函数等待用户按下键盘上的任意键后关闭窗口(不加上窗口会一闪而过)
waitKey是 OpenCV 的一个函数,用于等待并获取键盘输入的事件。这个函数的参数是一个整数,表示等待的最长时间(以毫秒为单位)。如果在这段时间内用户按下了键盘上的任意键,函数会立即返回按下的键的 ASCII 值。如果超过指定的时间,函数仍然没有收到键盘输入,那么它将返回 -1。 - 使用destroyAllWindows()函数关闭所有窗口。
- 使用
imwrite('fileName.jpg', img)该函数用于将图像数据保存为名为“saved_example.jpg”的图像文件。第一个参数是文件名,第二个参数是要保存的图像数据
注意:路径不能有中文
import cv2
# 使用imread()函数读取图片,参数是图片文件的路径
image = cv2.imread('path_to_your_image.jpg')
# 使用imshow()函数显示图片,第一个参数是窗口的名称,第二个参数是要显示的图像
cv2.imshow('image', image)
# 使用waitKey()函数等待用户按下键盘上的任意键后关闭窗口,参数是等待的毫秒数
cv2.waitKey(0)
# 使用destroyAllWindows()函数关闭所有窗口
cv2.destroyAllWindows()
cv2.imwrite('saved_example.jpg', image)
积累:
代码使用cv2.imdecode()函数读取文件,如下
import cv2
import numpy as np
filename = "path_to_your_image_file" # 替换为你的图像文件路径
decoded_image = cv2.imdecode(np.fromfile(filename, dtype=np.uint8), cv2.IMREAD_COLOR)
cv2.imshow("Decoded Image", decoded_image)
cv2.waitKey(0)
cv2.destroyAllWindows()展示结果
imdecode()和imread()都是用于读取图像文件的函数,但它们在某些方面存在一些差异。
imread()是OpenCV库中用于读取图像文件的函数,它能够读取各种格式的图像文件,并将其转换为OpenCV的Mat对象。该函数通常用于简单的图像读取任务,并且可以直接在Python中使用。
imdecode()函数则是在读取图像文件后将其解码为图像矩阵,它接受一个包含图像数据的字节流作为输入,并返回解码后的图像矩阵。这个函数通常用于处理从网络传输或文件流中读取的图像数据,因为它可以解码图像而不需要先将其写入磁盘。
总结来说,imread()和imdecode()的主要区别在于:
imread()用于直接读取图像文件,而imdecode()用于解码图像数据流。imread()返回一个OpenCV的Mat对象,而imdecode()返回解码后的图像矩阵。imread()通常用于简单的图像读取任务,而imdecode()适用于处理从网络或文件流中读取的图像数据。
3.图片基本处理
BGR模式转换为RGB模式
在Python的OpenCV库中将图像从BGR模式转换为RGB模式。这是一个常见的操作,因为在许多图像处理和计算机视觉任务中,我们通常使用RGB模式来表示图像
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)提取图片的BGR部分
import cv2
# 读取图像
img = cv2.imread('image.jpg')
# OpenCV默认以BGR(Blue, Green, Red)方式读取图像
# 所以我们需要把BGR转成RGB来处理
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 分离出RGB三个通道,顺序是B、G、R,即蓝绿红与红绿蓝正好相反。
b, g, r = cv2.split(img_rgb)灰度化处理
将彩色图像转换为灰度图像的过程称为灰度化处理。灰度化处理将彩色图像的每个像素转换为一个灰度值,表示像素的亮度。灰度化处理可以减少图像的数据量,并简化图像的分析和处理过程。
# 将彩色图像转换为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)二值化处理
二值化处理,顾名思义就是只留下黑与白,即每个元素不是为0黑,就是最大阈值。是一种常见的图像处理技术,它可以将灰度图像转化为二值图像,使得图像数据量减少,同时凸显出目标的轮廓,更有利于图像的进一步处理。
# 对图像进行二值化处理
ret, thresh = cv2.threshold(src, 阈值, 最大值, type)参数说明:
src:源图像,通常为灰度图像。thresh:阈值,用于确定图像的黑白分界。maxval:当源图像的灰度值高于(或低于)阈值时的最大值。如果是大于阈值的像素,则将其设置为maxval;如果是小于阈值的像素,则将其设置为0。type:二值化类型。这是一个可选参数,默认为cv2.THRESH_BINARY。以下是一些常见的类型:cv2.THRESH_BINARY:这是默认类型,大于阈值的像素被赋值为maxval,否则被赋值为0。cv2.THRESH_BINARY_INV:与cv2.THRESH_BINARY相反,小于阈值的像素被赋值为maxval,否则被赋值为0。cv2.THRESH_TRUNC:大于阈值的像素被赋值为maxval,小于阈值的像素被赋值为0,阈值处的像素被赋值为阈值。cv2.THRESH_TOZERO:大于阈值的像素被赋值为maxval,小于阈值的像素被赋值为0。cv2.THRESH_TOZERO_INV:大于阈值的像素被赋值为0,小于阈值的像素被赋值为maxval。
dst:输出图像,与输入图像大小相同,类型为8位无符号的二进制图像。
shape与reshape的使用
shape使用
在python的OpenCV中图片是使用numpy存储的,是以多维数据矩阵的方式存在,一般维度为height*width*3(height*width代表图片的高和宽,3代表蓝绿红3底色,每个元素取值0-255)。
shape函数如果是彩色图像,则返回(行数,列数,通道数)的数组;如果是灰度图像,则返回(行数,列数)的数组。
# 读取图像
img = cv2.imread('image.jpg')
# 获取图像的形状信息
shape = img.shape
print('Height:', shape[0])
print('Width:', shape[1])
print('Channels:', shape[2])结果:

reshape函数通常是指改变数据结构或矩阵的形状或布局的操作
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 3, 4])
print("原始数组:")
print(arr)
# 将一维数组重塑为二维数组
reshaped_arr = arr.reshape(2, 2)
print("重塑后的二维数组:")
print(reshaped_arr)原始数组:
[1 2 3 4]
重塑后的二维数组:
[[1 2]
[3 4]]图片截取和resize操作
图片裁剪:
# 定义裁剪区域 (x, y, width, height)
crop_img = image[y:y+h, x:x+w] cv2.resize的使用方法
resize函数用于调整图像的尺寸。它接受以下参数:
src:输入图像。这可以是一个彩色或灰度图像。dst:输出图像。这是调整尺寸后的图像大小,一般设置为(height,width)。fx:沿着水平轴的比例因子。如果为负数,则函数会将图像翻转。fy:沿着垂直轴的比例因子。如果为负数,则函数会将图像翻转。如果fx和fy都是0,函数会根据新的图像大小自动计算它们。interpolation:插值方法。这是决定如何调整图像尺寸的方法。常见的选项包括cv2.INTER_LINEAR(线性插值,这是默认值),cv2.INTER_NEAREST(最近邻插值),cv2.INTER_AREA(像素区域相关插值,适合用于缩小图像)等。
import cv2
# 加载图像
image = cv2.imread('01.jpg')
cv2.imshow("image",image)
print("shape:",image.shape)
h,w,_=image.shape
# 定义裁剪区域 (x, y, width, height)
crop_img = image[200:520, 100:520]
cv2.imshow('Cropped Image', crop_img)
#调整图片大小
# 重塑图像为一个高度和宽度都为原来一半的新图像
new_shape = cv2.resize(crop_img,(int(h / 2), int(w / 2)))
cv2.imshow("new_img",new_shape)
cv2.waitKey(0)
cv2.destroyAllWindows()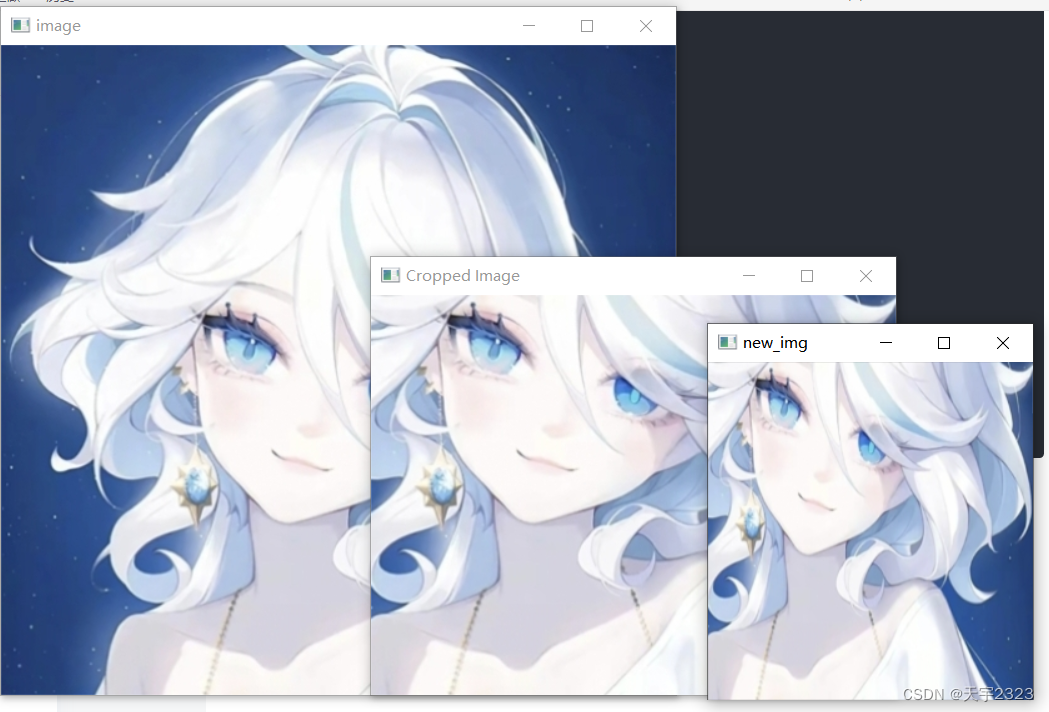
4.画框、画线、画圆
import cv2
import numpy as np
# 创建一个空白的图像
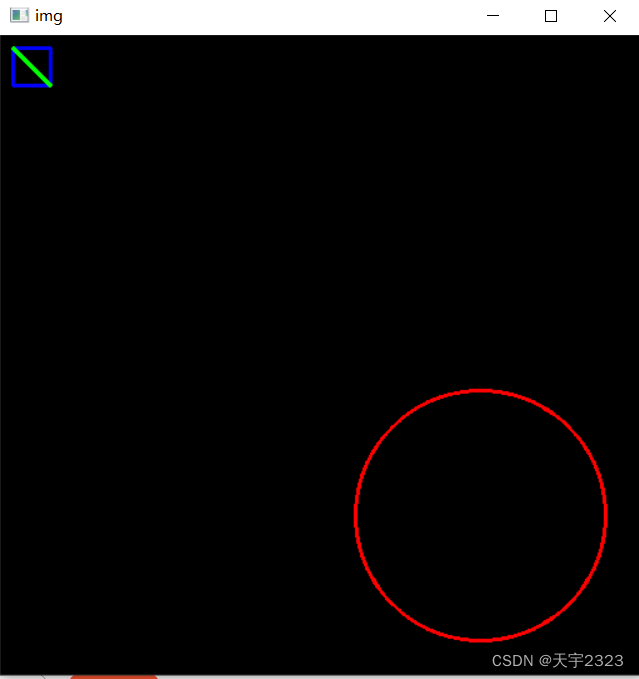
image = np.zeros((512, 512, 3), dtype="uint8")
# 定义矩形的左上角和右下角坐标和颜色蓝,线段粗细2像素点
# 在图像上画一个矩形
cv2.rectangle(image, (10, 10), (40, 40), (255, 0, 0), thickness=2)
# 定义直线的起点坐标和终点坐标,以及颜色绿,线段粗细2像素点
# 在图像上画一条直线
cv2.line(image,(10, 10), (40, 40), (0, 255, 0), thickness=2)
# 定义圆的中心坐标和半径,以及颜色红,线段粗细2像素点
# 在图像上画一个圆
cv2.circle(image, (384, 384), 100, (0, 0, 255),thickness=2)
cv2.imshow("img", image)
cv2.waitKey(0)
cv2.destroyAllWindows()结果演示:
5.插入文字
可以使用Python的内置功能来在图像上绘制文本。
cv2.putText() 函数的参数如下:
image:你想要在其上绘制文本的图像。text:你想要绘制的文本。org:文本的左下角坐标(即文本开始的位置)。font:字体类型。例如,cv2.FONT_HERSHEY_SIMPLEX、cv2.FONT_HERSHEY_PLAIN等。fontScale:字体大小。你可以通过这个参数来缩放字体。color:文本颜色。这个参数是一个BGR元组,例如(255, 255, 255)表示白色。thickness:文本线宽。如果你将这个值设为1,那么文本就会有一条黑色的边框。如果你将这个值设为2,那么文本就会有两条黑色的边框,以此类推。
import cv2
import numpy as np
# 创建一个空白的图像
image = np.zeros((512, 512, 3), dtype="uint8")
# 定义你想要插入的文本
text = "OpenCV"
# 使用OpenCV的putText函数在图像上绘制文本
cv2.putText(image, text, (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
# 显示图像
cv2.imshow("Image with Text", image)
cv2.waitKey(0)
cv2.destroyAllWindows()结果演示:

解决在python中Opencv不给图片中文的问题
- 下载Pillow
pip install Pillow- 使用如下代码
# 创建一个空白的图像
image = np.zeros((512, 512, 3), dtype="uint8")
import cv2
import numpy as np
from PIL import ImageFont, Image, ImageDraw
# 创建一个空白的图像
image = np.zeros((512, 512, 3), dtype="uint8")
def show_chinese(img,text,pos):
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
font = ImageFont.truetype(font='msyh.ttc', size=36)
draw = ImageDraw.Draw(img_pil)
draw.text(pos, text, font=font, fill=(255, 0, 0)) # PIL中RGB=(255,0,0)表示红色
img_cv = np.array(img_pil) # PIL图片转换为numpy
img = cv2.cvtColor(img_cv, cv2.COLOR_RGB2BGR) # PIL格式转换为OpenCV的BGR格式
return img
img = show_chinese(image,"你好",(0,0))
cv2.imshow('p', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果演示

6.平滑处理
在OpenCV中,可以使用多种方法进行噪点过滤。以下是几种常见的方法:
这里只做平滑处理简单介绍,详细原理和具体目的可参考其他博主的文章,推荐如下:
-
均值滤波器:
均值滤波器是一种常见的图像处理技术,可以用于降低图像的噪声。均值滤波器是一种线性滤波器,它对图像进行平滑处理,去除噪声,同时也能去除图像的细节部分,代码示例如下
import cv2
# 加载图像
img = cv2.imread('image.jpg')
# 使用cv2.blur()进行均值滤波,这里使用大小为9*9的滤波核进行均值滤波
dst1 = cv2.blur(img, (9, 9))
# 使用cv2.boxFilter()进行均值滤波
blur = cv2.boxFilter(img, -1, (5, 5), normalize=True)
# 显示原图和处理后的图像
cv2.imshow('Original Image', img)
cv2.imshow('Blur Image', blur)
cv2.waitKey(0)
cv2.destroyAllWindows()参数说明:
dst = cv2.blur(src,ksize,anchor,borderType)
参数说明:
- src:被处理的图像
- ksize:滤波核大小,其格式为(高度,宽度),建议使用如(3,3)、(5,5)等宽高相等的奇数边长。滤波核越大,处理之后的图像就越模糊。
- anchor:可选参数,滤波核的锚点,建议采用默认值,方法可以自动计算锚点。
- boderType:可选参数,边界样式,建议采用默认值。
cv2.boxFilter(src, ddepth, ksize, dst , anchor , normalize , borderType)
参数说明(方括号内表示可加可不加):
- src:输入图像对象矩阵。
- ddepth:数据格式,位深度。通常为
CV_32F或CV_64F。参数为-1时,表示输出图像的深度将与输入图像相同。也就是说,如果输入图像是8位无符号整型的图像,则输出图像也将是8位无符号整型的图像。 - ksize:高斯卷积核的大小,格式为(宽,高)。
- dst:输出图像矩阵,大小和数据类型都与src相同。
- anchor:卷积核锚点,默认-1-1表示卷积核的中心位置。
- normalize:是否归一化(若卷积核3*5,归一化卷积核需要除以15)。
- borderType:填充边界类型。
盒形滤波器是一个领域滤波器,对于领域内像素的平均值进行计算,然后将该值分配给中心像素。盒形滤波器对图像进行滤波处理,与高斯滤波器类似,但是它不需要指定sigmaX和sigmaY参数,因此更加简单和直接。盒形滤波器的卷积核是一个正方形,对应于每个像素的窗口大小可以自由调整。
-
中值滤波:
中值滤波是一种非线性信号处理技术,它对像素值进行排序,并将中间值作为输出。这种方法对于消除随机出现的噪点非常有效。可以使用OpenCV的cv2.medianBlur()函数实现中值滤波,如下所示:
import cv2
# 读取图像
img = cv2.imread('image.jpg')
# 进行中值滤波
filtered_img = cv2.medianBlur(img, 5)
# 显示原图和滤波后的图像
cv2.imshow('Original Image', img)
cv2.imshow('Filtered Image', filtered_img)
cv2.waitKey(0)
cv2.destroyAllWindows()参数说明:
cv2.medianBlur(src,ksize)
函数的具体参数如下1:
- src:源图像,可以是彩色图像或灰度图像。
- ksize:滤波核的边长,必须是正数大于1,且为奇数。
-
高斯滤波:
高斯滤波是一种线性滤波技术,它使用正态分布函数对像素值进行加权平均。这种方法对于消除高斯噪声非常有效。可以使用OpenCV的cv2.GaussianBlur()函数实现高斯滤波,如下所示:
import cv2
# 读取图像
img = cv2.imread('image.jpg')
# 进行高斯滤波
filtered_img = cv2.GaussianBlur(img, (5, 5), 0)
# 显示原图和滤波后的图像
cv2.imshow('Original Image', img)
cv2.imshow('Filtered Image', filtered_img)
cv2.waitKey(0)
cv2.destroyAllWindows()参数说明:
blurred = cv2.GaussianBlur(src,ksize, sigmaX=1.0, sigmaY=1.0, borderType=cv2.BORDER_CONSTANT)
函数的具体参数如下:
- src:源图像,输入图像。
- ksize:高斯核大小。这个参数是一个包含两个整数的元组,表示高斯核的宽和高。例如,(3, 3)表示使用3x3的高斯核。
- sigmaX:X方向上的高斯核标准偏差。这个参数决定了高斯核在X方向上的平滑程度。sigmaX的值越大,图像在X方向上的模糊程度越强。
- sigmaY:Y方向上的高斯核标准偏差。这个参数决定了高斯核在Y方向上的平滑程度。sigmaY的值越大,图像在Y方向上的模糊程度越强。如果不知道如何设计这两个参数值,就直接把这两个参数的值写成0,方法就会根据滤波核的大小自动计算出合适的权重比例。
- borderType:像素外插法。这个参数指定了在进行高斯模糊时,如何处理图像边缘的像素。常见的值有cv2.BORDER_CONSTANT(常数填充)、cv2.BORDER_REPLICATE(复制边缘像素)、cv2.BORDER_REFLECT(镜像反射)等。
-
双边滤波:
双边滤波是一种非线性滤波技术,它考虑了像素的空间信息和灰度信息。这种方法对于保留边缘信息的同时去除噪点非常有效。可以使用OpenCV的cv2.bilateralFilter()函数实现双边滤波,如下所示:
import cv2
# 读取图像
img = cv2.imread('image.jpg')
# 进行双边滤波
filtered_img = cv2.bilateralFilter(img, 9, 75, 75)
# 显示原图和滤波后的图像
cv2.imshow('Original Image', img)
cv2.imshow('Filtered Image', filtered_img)
cv2.waitKey(0)
cv2.destroyAllWindows()参数说明:
filtered = cv2.bilateralFilter(img, 9, sigmaColor=75, sigmaSpace=75)
函数的具体参数如下:
- src:源图像,输入图像。
- d:每个像素的直径,定义了像素的邻域大小。
- sigmaColor:颜色空间的标准偏差。这个参数决定了在颜色空间中的平滑程度。sigmaColor的值越大,颜色平滑程度越强。
- sigmaSpace:空间空间的标准偏差。这个参数决定了在空间域中的平滑程度。sigmaSpace的值越大,空间平滑程度越强。
7.图形轮廓
边缘检测--Canny函数
该函数通过计算图像中每个像素点的梯度值来检测边缘。其基本原理是:先对输入图像进行灰度化处理,然后进行高斯滤波以平滑图像并去除噪声,再使用Sobel算子计算梯度幅值和方向,对梯度幅值进行非极大值抑制以压缩边缘带宽,最后使用滞后阈值进行二值化得到二值化图像,再对二值化图像进行连接操作,将断开的边缘进行连接,得到最终的边缘图像
v2.Canny是OpenCV库中的一个函数,用于在图像中进行边缘检测。其函数语法如下:
cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient]]])参数说明:
- image: 输入图像,可以是灰度图像或彩色图像。
- threshold1: 第一个阈值,用于边缘检测中的滞后阈值,通常建议取值为100。
- threshold2: 第二个阈值,用于边缘检测中的滞后阈值,通常建议取值为200。
- edges:可选参数,用于存储边缘检测的结果。
- apertureSize:可选参数,用于指定Sobel算子的大小,通常建议取值为3。
- L2gradient:可选参数,用于指定是否使用L2 L2梯度计算方式,默认为False。
使用举例:
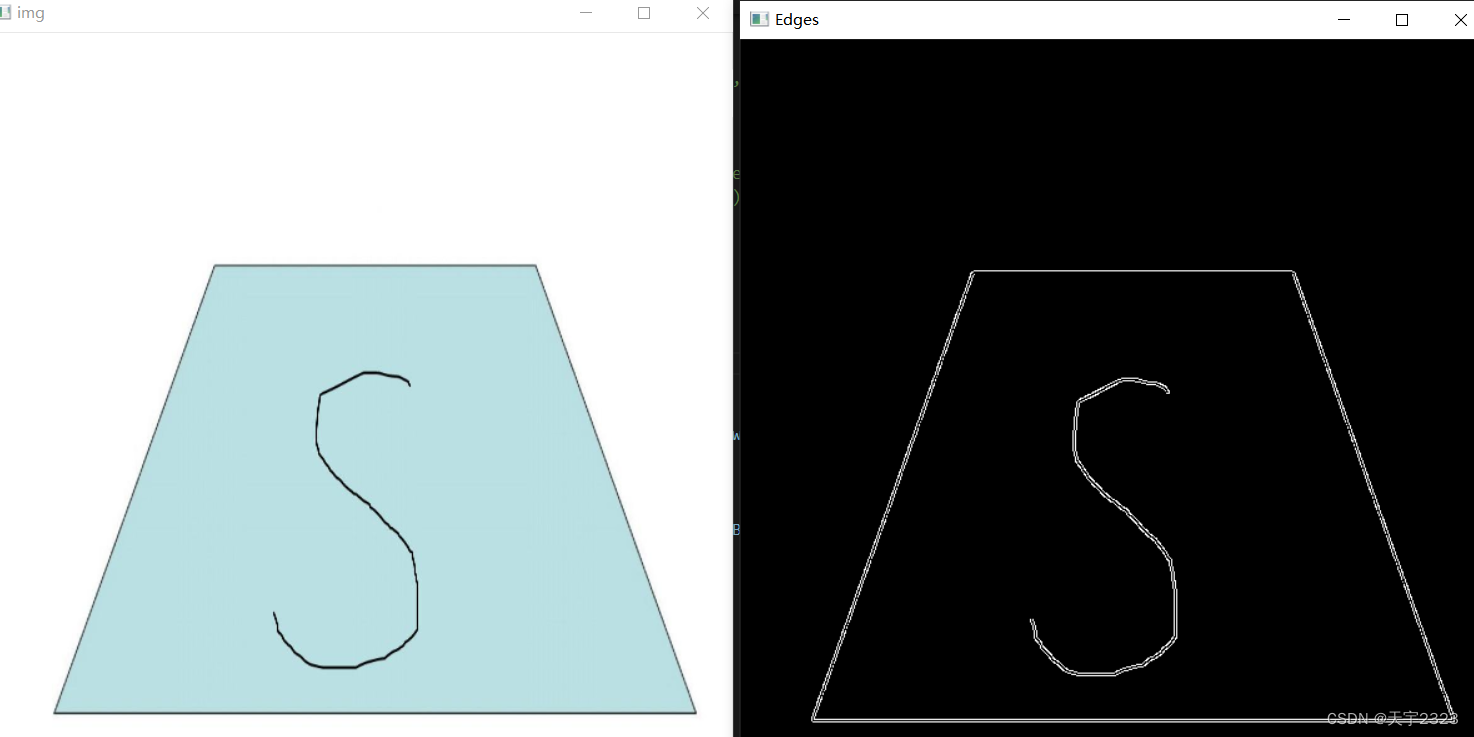
import cv2
# 读取图像
image = cv2.imread('06.jpg')
h,w,_=image.shape
img=cv2.resize(image,(int(w/2),int(w/2)))
# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测算法
edges = cv2.Canny(gray, 100, 200)
# 显示结果图像
cv2.imshow('img', img)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()图片素材 结果展示
查询轮廓--findContours 函数
cv2.findContours 是 OpenCV 库中的一个函数,用于找到图像中的轮廓。
其基本语法如下(方括号内表示可选):cv2.findContours(image, mode, method[, contours[, hierarchy]])
参数解释如下:
image:源图像,应该是灰度图。mode:轮廓检索模式,常用的有cv2.RETR_EXTERNAL(只检索最外面的轮廓)和cv2.RETR_LIST(检索所有轮廓并将其保存到列表中)。method:轮廓近似方法,常用的有cv2.CHAIN_APPROX_SIMPLE(存储轮廓的终点)和cv2.CHAIN_APPROX_TC89_L1(使用Ramer-Douglas-Peucker算法进行近似)。contours:轮廓的输出参数。如果这个参数不为空,那么函数会直接在这个参数中填充找到的轮廓。否则,函数会创建一个新的列表来保存轮廓。hierarchy:这个参数是用来描述轮廓的层次结构的。如果这个参数不为空,那么函数会在这个参数中填充轮廓的层次信息。否则,函数会忽略这个参数。
绘制轮廓--drawContours函数
cv2.
参数如下:
- image:要绘制轮廓的输入图像。可以是彩色图像或灰度图像。
- contours:输入轮廓的数组。轮廓是以向量形式存储的点集。每个轮廓可以由多个连续的点组成。
- contourIdx:要绘制的轮廓的索引值。如果要绘制多个轮廓,则该参数用于指定绘制哪个轮廓。例如,如果要绘制第一个轮廓,可以将contourIdx设置为0,而-1表示绘制所有轮廓。
- color:轮廓的颜色。可以使用RGB或灰度颜色空间表示颜色。
- thickness:轮廓线条的粗细。可以是正整数或负整数。正整数表示使用填充轮廓,负整数表示使用空心轮廓。例如,thickness=2表示绘制填充轮廓,thickness=-1表示绘制空心轮廓。
- lineType:轮廓线条的类型。可以是以下值之一:cv2.LINE_AA(抗锯齿线型)、cv2.LINE_4(4像素线型)、cv2.LINE_8(8像素线型)等。
- hierarchy:轮廓的层次信息。如果不需要层次信息,可以使用默认值noArray()。
- maxLevel:最大轮廓等级。如果需要绘制嵌套的轮廓,可以设置maxLevel的值来控制最大嵌套层级。
- offset:偏移量。可以在绘制轮廓时设置偏移量来调整轮廓的位置。
import numpy as np
# 读取图像
image = cv2.imread('image.png')
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
# 查找轮廓
contours, hierarchy = cv2.findContours(edges.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个空白图像,用于绘制轮廓
draw_image = np.zeros(image.shape, dtype="uint8")
# 绘制轮廓
cv2.drawContours(draw_image, contours, -1, (0,255,0), 3)
# 显示原始图像和轮廓图像
cv2.imshow("Original Image", image)
cv2.imshow("Contours", draw_image)
cv2.waitKey(0)
cv2.destroyAllWindows()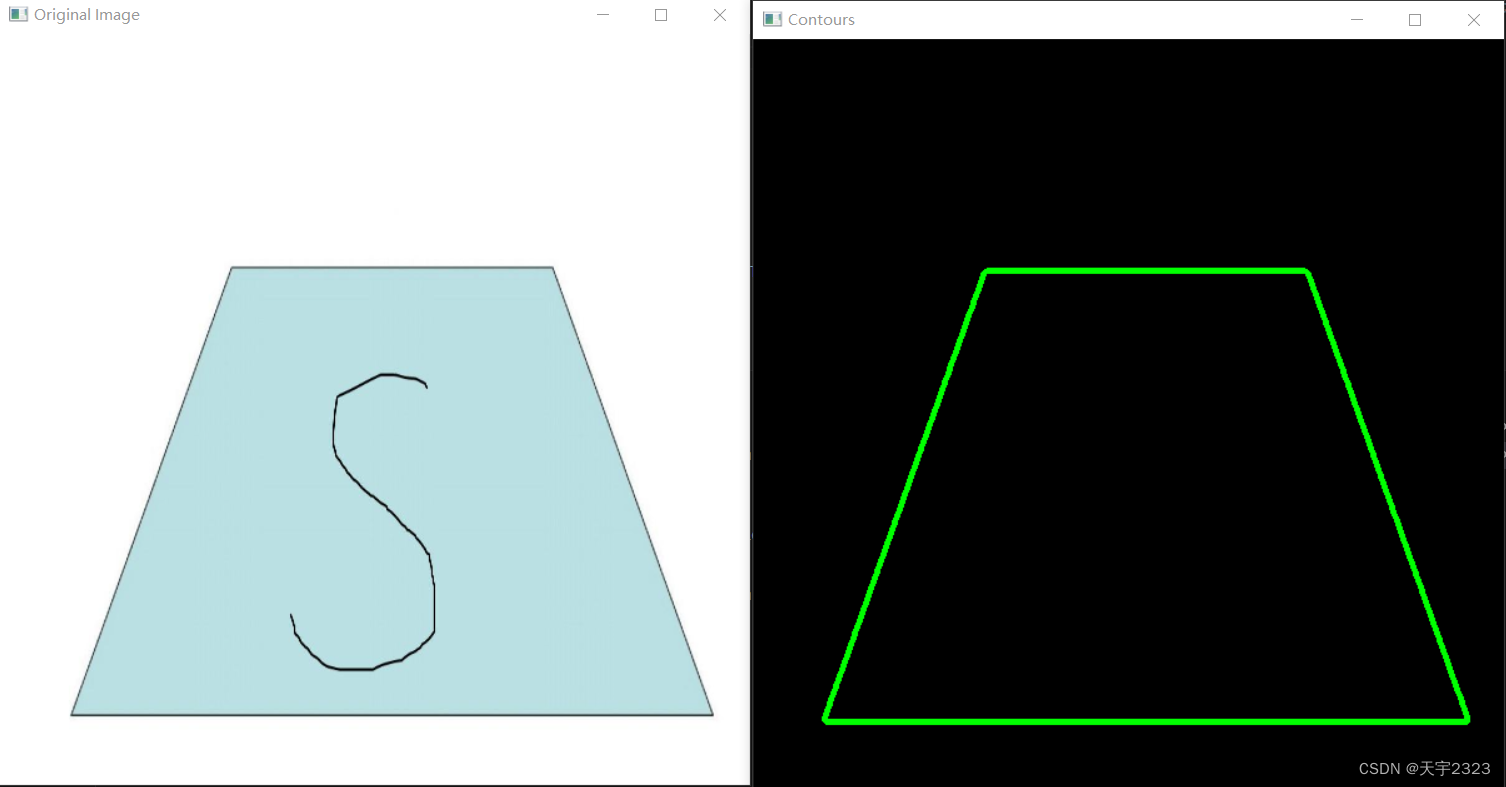
计算轮廓的近似多边形--approxPolyDP函数
cv2.approxPolyDP() 是一个用于在 OpenCV 中近似多边形的函数。这个函数使用 Ramer-Douglas-Peucker 算法来减少多边形顶点的数量,同时尽可能保持多边形的形状。
cv.approxPolyDP(curve, epsilon, closed[, approxCurve=None])
参数说明:
- curve:输入点集,二维点向量的集合
- epsilon:近似精度,原始曲线与近似曲线之间的最大距离。如果epsilon为0,那么函数会返回原始轮廓的顶点集。随着epsilon值的增加,函数返回的近似多边形的顶点数会减少,但与原始轮廓的形状也会越偏离。
- close: 闭合标志,True 表示闭合多边形,False 表示多边形不闭合
- approxCurve:输出点集,表示拟合曲线或多边形,数据与输入参数 curve 一致
cv2.approxPolyDP()函数返回一个列表,其中包含近似多边形的顶点坐标。每个顶点的坐标是一个元组,包含x和y坐标。列表中的顶点按顺序排列,以绘制近似多边形。
近似多边形来寻找图形各个顶点坐标
import numpy as np
import cv2
# 读取图像
image = cv2.imread('06.jpg')
h,w,_=image.shape
image=cv2.resize(image,(int(w/2),int(w/2)))
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
# 查找轮廓
contours, hierarchy = cv2.findContours(edges.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个空白图像,用于绘制轮廓
draw_image = np.zeros(image.shape, dtype="uint8")
# 绘制轮廓
cv2.drawContours(draw_image, contours, -1, (0,255,0), 3)
# 显示原始图像和轮廓图像
cv2.imshow("Original Image", draw_image)
cv2.waitKey()
for contour in contours:
peri=cv2.arcLength(contour,True)
approx=cv2.approxPolyDP(contour,0.02*peri,True)
if len(approx)==4:
screenCnt=approx
break
cv2.drawContours(image,[screenCnt],-1,(0,255,0),2)
screenCnt=screenCnt.reshape(4,2)
for i in screenCnt:
print("--------")
cv2.circle(image,(i[0],i[1]), 3, (0,0,255), -1)
cv2.putText(image,str(i[0])+","+str(i[1]) ,(i[0],i[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (0, 0, 255), 1)
# 显示原始图像和轮廓图像
cv2.imshow("Original Image", image)
cv2.imshow("Contours", draw_image)
cv2.waitKey(0)
cv2.destroyAllWindows()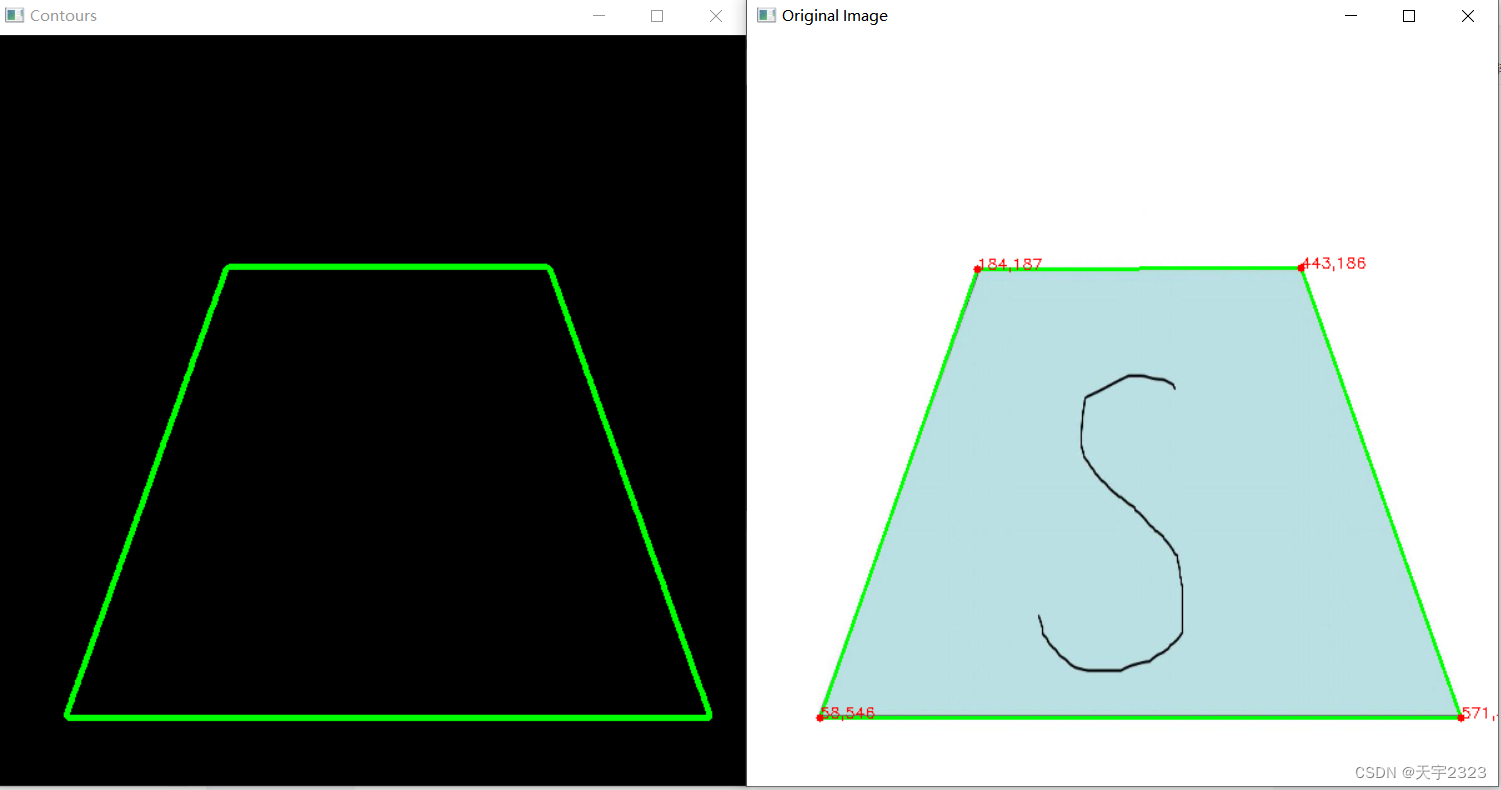
检测车牌
看看就行
该代码出自github项目,这里只有利用轮廓和颜色检测车牌的代码。详细地址如下:
https://github.com/wzh191920/License-Plate-Recognition/tree/master
import cv2
import numpy as np
from numpy.linalg import norm
import sys
import os
import json
SZ = 20 #训练图片长宽
MAX_WIDTH = 1000 #原始图片最大宽度
Min_Area = 2000 #车牌区域允许最大面积
PROVINCE_START = 1000
#读取图片文件
def imreadex(filename):
return cv2.imdecode(np.fromfile(filename, dtype=np.uint8), cv2.IMREAD_COLOR)
def point_limit(point):
if point[0] < 0:
point[0] = 0
if point[1] < 0:
point[1] = 0
#根据找出的波峰,分隔图片,从而得到逐个字符图片
def seperate_card(img, waves):
part_cards = []
for wave in waves:
part_cards.append(img[:, wave[0]:wave[1]])
return part_cards
class CardPredictor:
def __init__(self):
#车牌识别的部分参数保存在js中,便于根据图片分辨率做调整
f = open('config.js')
j = json.load(f)
for c in j["config"]:
if c["open"]:
self.cfg = c.copy()
break
else:
raise RuntimeError('没有设置有效配置参数')
def __del__(self):
self.save_traindata()
def save_traindata(self):
if not os.path.exists("svm.dat"):
self.model.save("svm.dat")
if not os.path.exists("svmchinese.dat"):
self.modelchinese.save("svmchinese.dat")
def accurate_place(self, card_img_hsv, limit1, limit2, color):
row_num, col_num = card_img_hsv.shape[:2]
xl = col_num
xr = 0
yh = 0
yl = row_num
#col_num_limit = self.cfg["col_num_limit"]
row_num_limit = self.cfg["row_num_limit"]
col_num_limit = col_num * 0.8 if color != "green" else col_num * 0.5#绿色有渐变
for i in range(row_num):
count = 0
for j in range(col_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if limit1 < H <= limit2 and 34 < S and 46 < V:
count += 1
if count > col_num_limit:
if yl > i:
yl = i
if yh < i:
yh = i
for j in range(col_num):
count = 0
for i in range(row_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if limit1 < H <= limit2 and 34 < S and 46 < V:
count += 1
if count > row_num - row_num_limit:
if xl > j:
xl = j
if xr < j:
xr = j
return xl, xr, yh, yl
def predict(self, car_pic, resize_rate=1):
if type(car_pic) == type(""):
img = imreadex(car_pic)
else:
img = car_pic
pic_hight, pic_width = img.shape[:2]
if pic_width > MAX_WIDTH:
pic_rate = MAX_WIDTH / pic_width
img = cv2.resize(img, (MAX_WIDTH, int(pic_hight*pic_rate)), interpolation=cv2.INTER_LANCZOS4)
if resize_rate != 1:
img = cv2.resize(img, (int(pic_width*resize_rate), int(pic_hight*resize_rate)), interpolation=cv2.INTER_LANCZOS4)
pic_hight, pic_width = img.shape[:2]
print("h,w:", pic_hight, pic_width)
blur = self.cfg["blur"]
#高斯去噪
if blur > 0:
img = cv2.GaussianBlur(img, (blur, blur), 0)#图片分辨率调整
oldimg = img
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#equ = cv2.equalizeHist(img)
#img = np.hstack((img, equ))
#去掉图像中不会是车牌的区域
kernel = np.ones((20, 20), np.uint8)
img_opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
img_opening = cv2.addWeighted(img, 1, img_opening, -1, 0);
#找到图像边缘
ret, img_thresh = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
img_edge = cv2.Canny(img_thresh, 100, 200)
#使用开运算和闭运算让图像边缘成为一个整体
kernel = np.ones((self.cfg["morphologyr"], self.cfg["morphologyc"]), np.uint8)
img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel)
img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel)
#查找图像边缘整体形成的矩形区域,可能有很多,车牌就在其中一个矩形区域中
try:
contours, hierarchy = cv2.findContours(img_edge2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
except ValueError:
image, contours, hierarchy = cv2.findContours(img_edge2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = [cnt for cnt in contours if cv2.contourArea(cnt) > Min_Area]
print('len(contours)', len(contours))
#一一排除不是车牌的矩形区域
car_contours = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
area_width, area_height = rect[1]
if area_width < area_height:
area_width, area_height = area_height, area_width
wh_ratio = area_width / area_height
#print(wh_ratio)
#要求矩形区域长宽比在2到5.5之间,2到5.5是车牌的长宽比,其余的矩形排除
if wh_ratio > 2 and wh_ratio < 5.5:
car_contours.append(rect)
box = cv2.boxPoints(rect)
box = np.int0(box)
#oldimg = cv2.drawContours(oldimg, [box], 0, (0, 0, 255), 2)
#cv2.imshow("edge4", oldimg)
#cv2.waitKey(0)
print(len(car_contours))
print("精确定位")
card_imgs = []
#矩形区域可能是倾斜的矩形,需要矫正,以便使用颜色定位
for rect in car_contours:
if rect[2] > -1 and rect[2] < 1:#创造角度,使得左、高、右、低拿到正确的值
angle = 1
else:
angle = rect[2]
rect = (rect[0], (rect[1][0]+5, rect[1][1]+5), angle)#扩大范围,避免车牌边缘被排除
box = cv2.boxPoints(rect)
heigth_point = right_point = [0, 0]
left_point = low_point = [pic_width, pic_hight]
for point in box:
if left_point[0] > point[0]:
left_point = point
if low_point[1] > point[1]:
low_point = point
if heigth_point[1] < point[1]:
heigth_point = point
if right_point[0] < point[0]:
right_point = point
if left_point[1] <= right_point[1]:#正角度
new_right_point = [right_point[0], heigth_point[1]]
pts2 = np.float32([left_point, heigth_point, new_right_point])#字符只是高度需要改变
pts1 = np.float32([left_point, heigth_point, right_point])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(oldimg, M, (pic_width, pic_hight))
point_limit(new_right_point)
point_limit(heigth_point)
point_limit(left_point)
card_img = dst[int(left_point[1]):int(heigth_point[1]), int(left_point[0]):int(new_right_point[0])]
card_imgs.append(card_img)
#cv2.imshow("card", card_img)
#cv2.waitKey(0)
elif left_point[1] > right_point[1]:#负角度
new_left_point = [left_point[0], heigth_point[1]]
pts2 = np.float32([new_left_point, heigth_point, right_point])#字符只是高度需要改变
pts1 = np.float32([left_point, heigth_point, right_point])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(oldimg, M, (pic_width, pic_hight))
point_limit(right_point)
point_limit(heigth_point)
point_limit(new_left_point)
card_img = dst[int(right_point[1]):int(heigth_point[1]), int(new_left_point[0]):int(right_point[0])]
card_imgs.append(card_img)
#cv2.imshow("card", card_img)
#cv2.waitKey(0)
#开始使用颜色定位,排除不是车牌的矩形,目前只识别蓝、绿、黄车牌
colors = []
for card_index,card_img in enumerate(card_imgs):
green = yello = blue = black = white = 0
card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)
#有转换失败的可能,原因来自于上面矫正矩形出错
if card_img_hsv is None:
continue
row_num, col_num= card_img_hsv.shape[:2]
card_img_count = row_num * col_num
for i in range(row_num):
for j in range(col_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if 11 < H <= 34 and S > 34:#图片分辨率调整
yello += 1
elif 35 < H <= 99 and S > 34:#图片分辨率调整
green += 1
elif 99 < H <= 124 and S > 34:#图片分辨率调整
blue += 1
if 0 < H <180 and 0 < S < 255 and 0 < V < 46:
black += 1
elif 0 < H <180 and 0 < S < 43 and 221 < V < 225:
white += 1
color = "no"
limit1 = limit2 = 0
if yello*2 >= card_img_count:
color = "yello"
limit1 = 11
limit2 = 34#有的图片有色偏偏绿
elif green*2 >= card_img_count:
color = "green"
limit1 = 35
limit2 = 99
elif blue*2 >= card_img_count:
color = "blue"
limit1 = 100
limit2 = 124#有的图片有色偏偏紫
elif black + white >= card_img_count*0.7:#TODO
color = "bw"
print(color)
colors.append(color)
print(blue, green, yello, black, white, card_img_count)
#cv2.imshow("color", card_img)
#cv2.waitKey(0)
if limit1 == 0:
continue
#以上为确定车牌颜色
#以下为根据车牌颜色再定位,缩小边缘非车牌边界
xl, xr, yh, yl = self.accurate_place(card_img_hsv, limit1, limit2, color)
if yl == yh and xl == xr:
continue
need_accurate = False
if yl >= yh:
yl = 0
yh = row_num
need_accurate = True
if xl >= xr:
xl = 0
xr = col_num
need_accurate = True
card_imgs[card_index] = card_img[yl:yh, xl:xr] if color != "green" or yl < (yh-yl)//4 else card_img[yl-(yh-yl)//4:yh, xl:xr]
if need_accurate:#可能x或y方向未缩小,需要再试一次
card_img = card_imgs[card_index]
card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)
xl, xr, yh, yl = self.accurate_place(card_img_hsv, limit1, limit2, color)
if yl == yh and xl == xr:
continue
if yl >= yh:
yl = 0
yh = row_num
if xl >= xr:
xl = 0
xr = col_num
card_imgs[card_index] = card_img[yl:yh, xl:xr] if color != "green" or yl < (yh-yl)//4 else card_img[yl-(yh-yl)//4:yh, xl:xr]
return card_imgs
if __name__ == '__main__':
c = CardPredictor()
roi= c.predict("Screenshots\\6.jpeg")
for i in roi:
cv2.imshow("img",i)
cv2.waitKey(0)
检测车牌:

展示结果:

有时候你会发现效果并不是很好,利用轮廓检测目标,过于落后,目前目标检测一般会运用深度学习,利用大量的数据来训练模型,目前比较好算法是YOLO,推荐如下文章
8.几何变形
视变换矩阵
cv2.getPerspectiveTransform(srcPoints,dstPoints)
是OpenCV库中的一个函数,用于获取透视变换矩阵。透视变换是一种几何变换,可以模拟图像通过透镜或经过其他透镜形状的物体时的视角效果。
具体参数包括:
srcPoints:输入的源点,它是一个4x2的矩阵,其中4是点的数量。每一行代表一个点的坐标,第一列是x坐标,第二列是y坐标。dstPoints:目标的点,与源点类似,也是一个4x2的矩阵。
这个函数返回一个3x3的变换矩阵,可以用作cv2.warpPerspective函数的变换矩阵M。
M=cv2.getPerspectiveTransform(srcPoints,dstPoints)
cv2.warpPerspective(src, M, (src.shape[1], src.shape[0]))
函数来获取透视变换矩阵。最后,使用cv2.warpPerspective函数来应用这个透视变换到源图像上,并显示原图和转换后的图像。
下面是一个示例代码:
import cv2
import numpy as np
# 源图像
src = cv2.imread('src.jpg')
# 源图像上的四个点(对应于透视变换的四个对应点)
src_pts = np.float32([[10, 10], [100, 10], [10, 100], [100, 100]])
# 目标图像上的对应点
dst_pts = np.float32([[20, 20], [120, 20], [20, 120], [120, 120]])
# 获取透视变换矩阵
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
# 应用透视变换,注意,第二个参数是转换的源图像,第三个参数是输出图像的大小
dst = cv2.warpPerspective(src, M, (src.shape[1], src.shape[0]))
# 显示原图和转换后的图像
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()这段代码首先定义了源图像上的四个点和目标图像上对应的四个点。然后使用
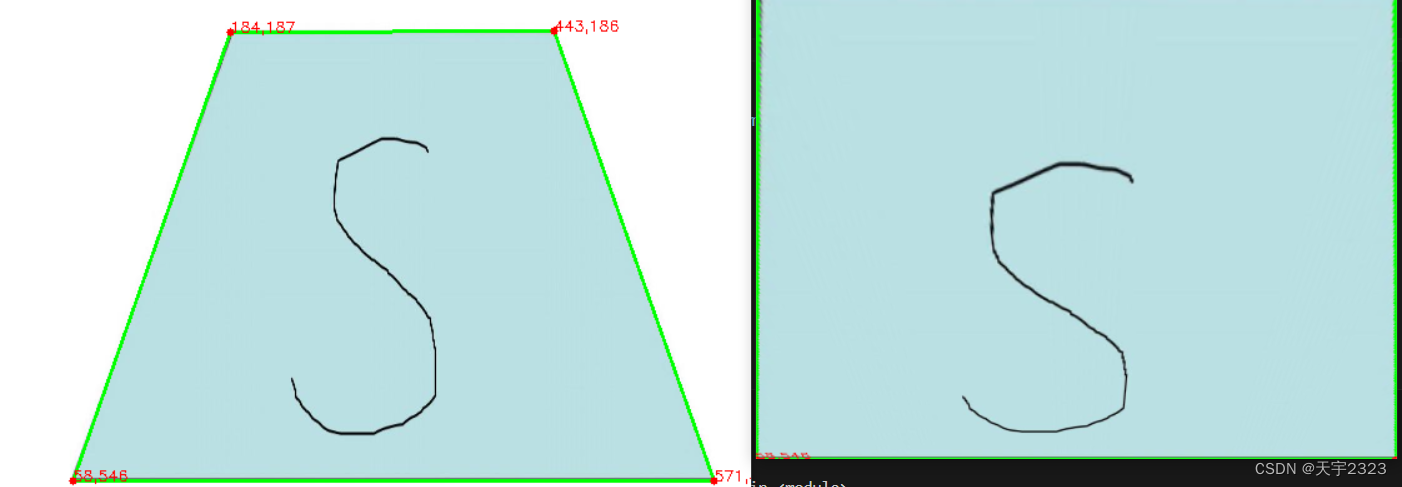
图片矫正
使用举例:
测试使用图片
代码部分
import numpy as np
import cv2
def four_point_transform(img,rect):
# 创建一个NumPy数组
rect = np.array(rect, dtype=np.float32)
(tl,tr,br,bl)=rect
print(tl,tr,br,bl)
#两点距离公式计算最大的高和宽
heightA=np.sqrt(((br[0]-bl[0])**2)+(br[1]-bl[1])**2)
heightB=np.sqrt(((tr[0]-tl[0])**2)+(tr[1]-tl[1])**2)
maxHeight=max(int(heightA),int(heightB))
widthA=np.sqrt((tr[0]-br[0])**2+(tr[1]-br[1])**2)
widthB=np.sqrt((tl[0]-bl[0])**2+(tl[1]-bl[1])**2)
maxWidth=max(int(widthA),int(widthB))
#distinctive point
dst=np.array([[0,0],[0,maxHeight-1],[maxWidth-1,maxHeight-1],[maxWidth-1,0]],dtype="float32")
M=cv2.getPerspectiveTransform(rect,dst)
warped=cv2.warpPerspective(img,M,(maxWidth,maxHeight))
return warped
# 读取图像
image = cv2.imread('06.jpg')
h,w,_=image.shape
image=cv2.resize(image,(int(w/2),int(w/2)))
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
# 查找轮廓
contours, hierarchy = cv2.findContours(edges.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个空白图像,用于绘制轮廓
draw_image = np.zeros(image.shape, dtype="uint8")
# 绘制轮廓
cv2.drawContours(draw_image, contours, -1, (0,255,0), 3)
# 显示原始图像和轮廓图像
cv2.imshow("Original Image", draw_image)
cv2.waitKey()
for contour in contours:
peri=cv2.arcLength(contour,True)
approx=cv2.approxPolyDP(contour,0.02*peri,True)
if len(approx)==4:
screenCnt=approx
break
cv2.drawContours(image,[screenCnt],-1,(0,255,0),2)
screenCnt=screenCnt.reshape(4,2)
for i in screenCnt:
cv2.circle(image,(i[0],i[1]), 3, (0,0,255), -1)
cv2.putText(image,str(i[0])+","+str(i[1]) ,(i[0],i[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (0, 0, 255), 1)
# 显示原始图像和轮廓图像
cv2.imshow("Original Image", image)
cv2.imshow("Contours", draw_image)
warped=four_point_transform(image,screenCnt)
cv2.imshow("warped",warped)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果演示:代码
仿射变换矩阵
cv2.getAffineTransform(srcPoints,dstPoints)
是OpenCV库中的一个函数,用于获取仿射变换矩阵。仿射变换是在几何中常用的一种变换,它保持了图像的“平行性”和“面积不变性”,也就是说,变换后的图像与原图像的平行线段和面积比都是相同的。
具体参数包括:
srcPoints:输入的源点,它是一个3 x 2的矩阵,其中3是点的数量。dstPoints:目标的点,与源点类似,也是一个3 x 2的矩阵,这些点定义了源点对应目标图像上的点。
函数返回一个2x3的变换矩阵,可以用作cv2.warpAffine函数的变换矩阵M。
dst = cv2.warpAffine(src, M, (src.shape[1], src.shape[0]))
下面是一个示例代码:
import cv2
import numpy as np
# 源图像
src = cv2.imread('src.jpg')
# 源图像上的三个点(对应于仿射变换的三个对应点)
src_pts = np.float32([[10, 10], [100, 10], [10, 100]])
# 目标图像上的对应点
dst_pts = np.float32([[20, 20], [120, 20], [20, 120]])
# 获取仿射变换矩阵
M = cv2.getAffineTransform(src_pts, dst_pts)
# 应用仿射变换,注意,第二个参数是转换的源图像,第三个参数是输出图像的大小
dst = cv2.warpAffine(src, M, (src.shape[1], src.shape[0]))
# 显示原图和转换后的图像
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()这段代码首先定义了源图像上的三个点和目标图像上对应的三个点。然后使用cv2.getAffineTransform函数来获取仿射变换矩阵。最后,使用cv2.warpAffine函数来应用这个仿射变换到源图像上,并显示原图和转换后的图像
仿射变换矩阵getAffineTransform和透视变换矩阵getPerspectiveTransform区别
区别如下:
- 应用场景不同:仿射变换通常用于旋转、缩放、倾斜等变换,而透视变换通常用于模拟人眼视角的视觉效果。
- 变换矩阵不同:仿射变换矩阵是一个2x3的矩阵,而透视变换矩阵是一个3x3的矩阵。
- 保持特性不同:仿射变换保持了平行性、共线性和发生率,而透视变换不保持平行性、长度以及角度。
9.加载摄像或视频文件
cv2.VideoCapture()
VideoCapture() 函数是OpenCV库中的一个类,用于捕获视频。它可以放两种参数,分别是视频文件路径或摄像头编号。
参数说明:
filename: 视频文件路径。例如:"test.mp4"。如果这个参数为空,函数会创建一个VideoCapture对象,但不会打开任何文件或设备。camId: 摄像头编号,从0开始。如果这个参数为-1,函数会创建一个VideoCapture对象,但不会打开任何文件或设备。camId可以是一个整数(0表示默认摄像头)或一个文件名(以打开视频文件)
使用说明:
cv2.VideoCapture()创建一个VideoCapture对象。cap.read()从视频中读取一帧。如果帧存在,则返回True。否则返回False。cap.get(propId)返回指定的帧的属性。propId可以是0到18之间的任何整数(取决于所支持的属性)。例如,帧的宽度和高度可以通过cap.get(3)和cap.get(4)获得。cap.set(propId, value)设置帧的属性。propId可以是0到18之间的任何整数(取决于所支持的属性)。例如,可以设置帧的宽度和高度为640x480。cap.release()释放VideoCapture对象并关闭视频文件或摄像头。
获取摄像头画面并保存为视频文件
import cv2
# 创建VideoCapture对象并打开视频文件
cap = cv2.VideoCapture(0)
# 获取视频的当前帧率
fps = cap.get(cv2.CAP_PROP_FPS)
# 创建VideoWriter对象,指定输出视频路径、帧率、分辨率等参数
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 选择视频编码器
out = cv2.VideoWriter('output.mp4', fourcc, 30.0, (640, 480)) # 30帧每秒,640x480分辨率
while cap.isOpened():
ret, frame = cap.read() # 读取一帧
if not ret:
break
#显示
cv2.imshow("Frame", frame)
# 将处理后的帧写入输出视频文件
out.write(frame)
# 等待按键按下,控制帧率
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放VideoCapture对象和VideoWriter对象,并关闭窗口
cap.release()
out.release()
cv2.destroyAllWindows()效果展示
读取视频文件,并显示
import cv2
# 创建VideoCapture对象并打开视频文件
cap = cv2.VideoCapture('D:\\file\\ocr\\OCR\\test\\label\\04.mp4')
fps=cap.get(cv2.CAP_PROP_FPS)
frame_rate=int(fps)
print(frame_rate)
# 循环读取视频帧并显示
while cap.isOpened():
ret, frame = cap.read()
frame=cv2.resize(frame,(640,480))
cv2.imshow('Video', frame)
if cv2.waitKey(frame_rate) == ord('q'): # 按q键退出播放
break
# 释放资源并关闭窗口
cap.release()
cv2.destroyAllWindows()














 2554
2554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









