







说明
本次实验案例是基于pytorch框架下,用yolov5模型实现牛和马的目标检测,数据集是自己制作的,具体制作方法参考我另外一篇博客Labelme制作数据集,为了方便大家也可以直接下载我的数据集进行模型复现,网盘链接如下:数据集链接:提取码:xss6。
1、环境安装
(此步可以跳过,与本文内容无太大关系,就单纯想水文字)
(1)、打开anaconda的Anaconda Prompt工具:
(2)、执行如下操作进行conda环境安装:
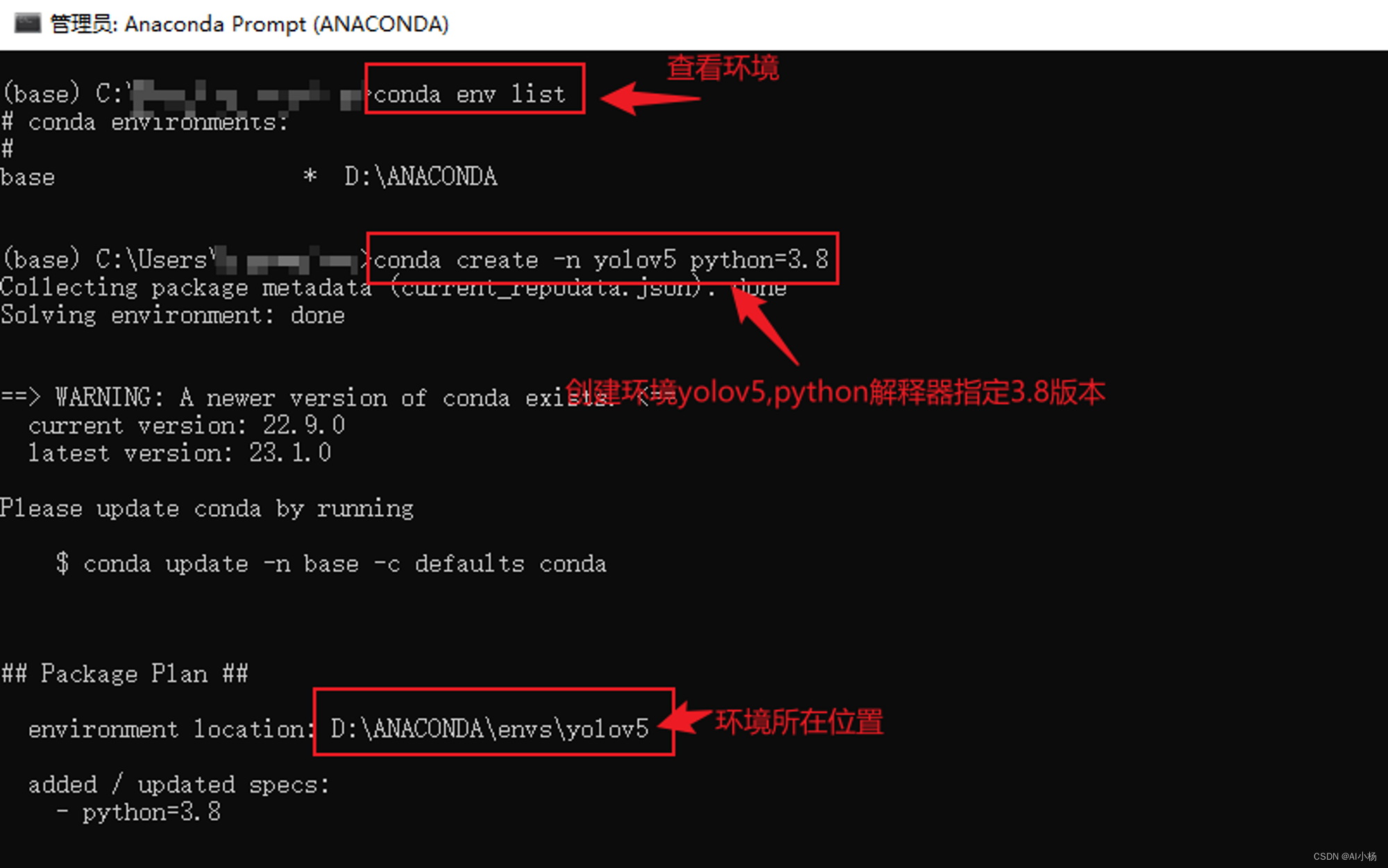
conda env list#查看conda环境
conda create -n yolov5 python=3.8#创建conda环境命名为yolov5,python解释器版本指定3.8版本
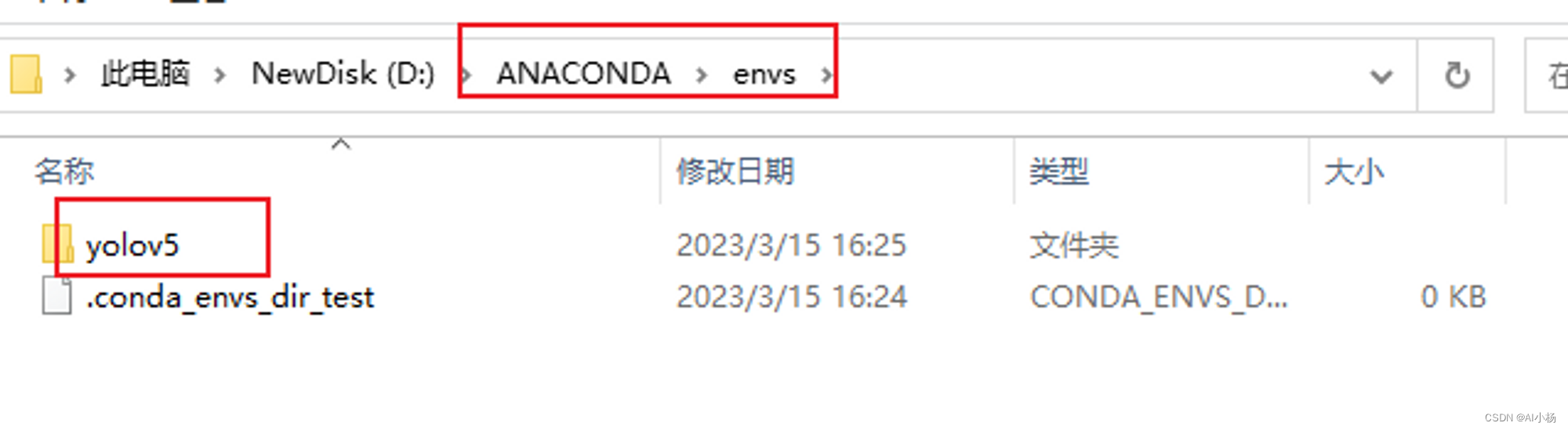
创建过程中刚创建的环境会显示在过程中,如上图红框处环境所在位置,接下来去电脑中的该位置可以找到创建的环境,如下图:
(3)接下来打开pycharm工具进行如下操作
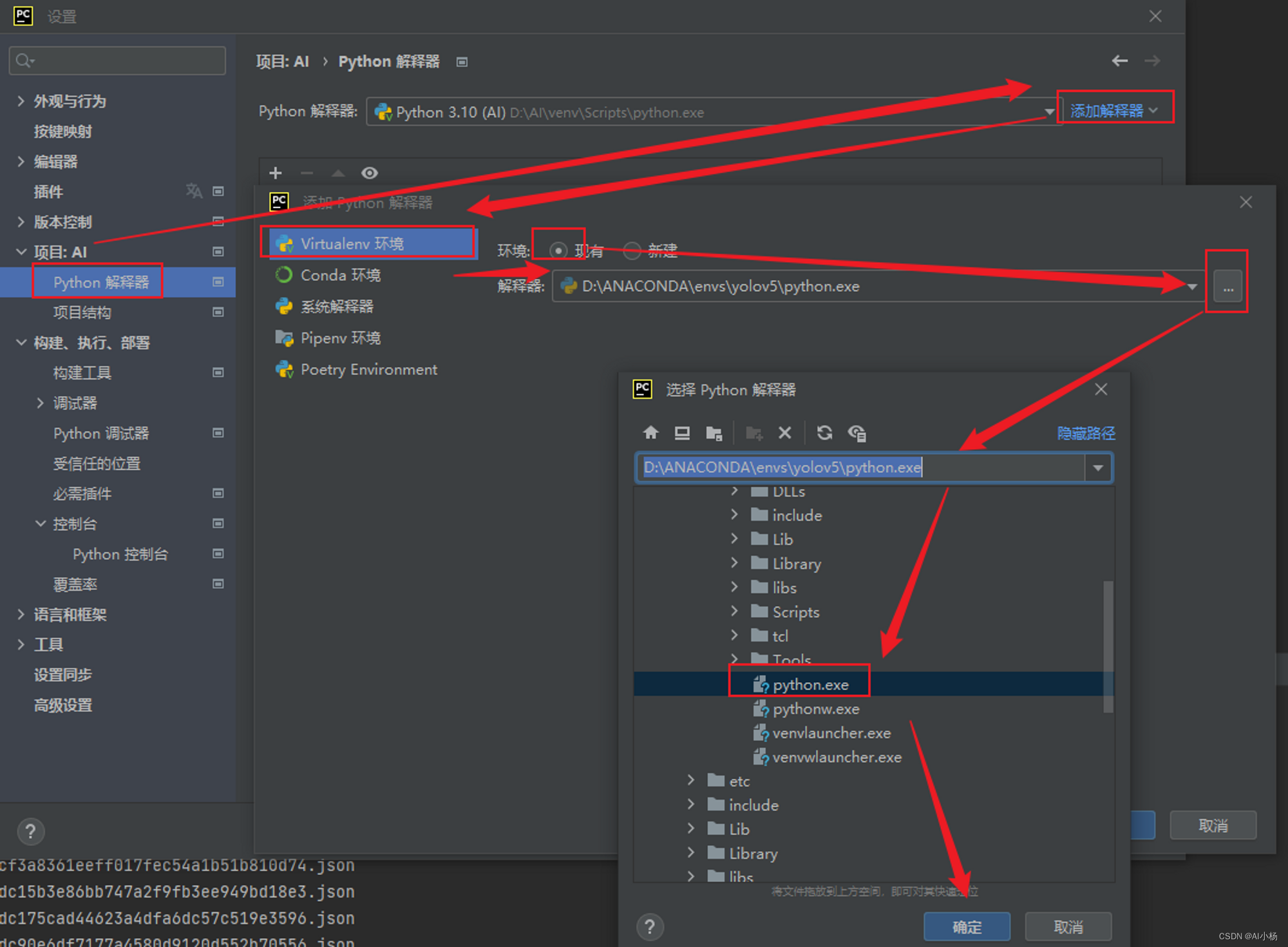
至此创建的解释器添加完成
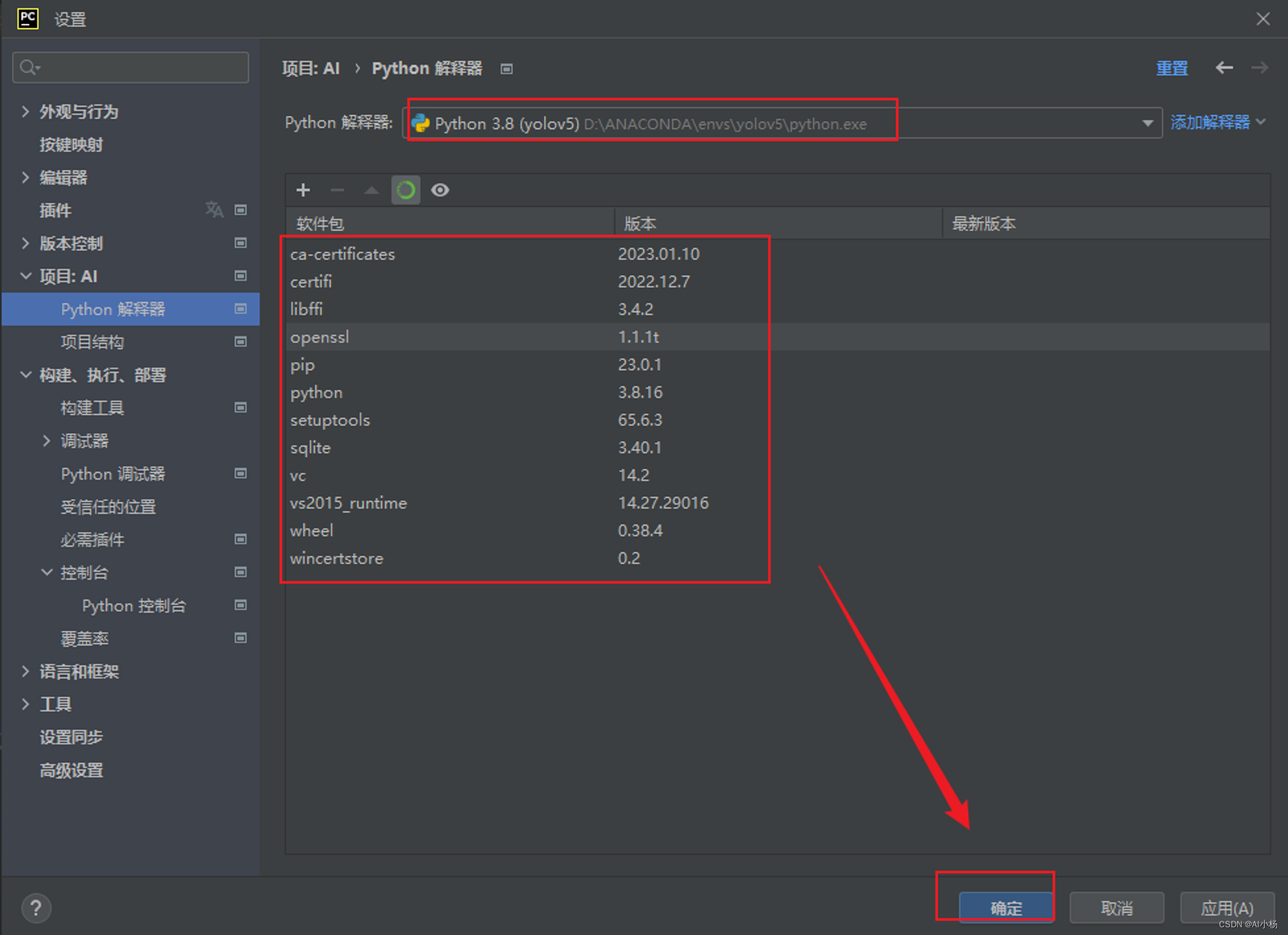
注意:我的pycharm是汉化后的中文版,pycharm安装汉化教程请参考我另外一篇博客pycharm安装和汉化
至此conda环境搭建完成。
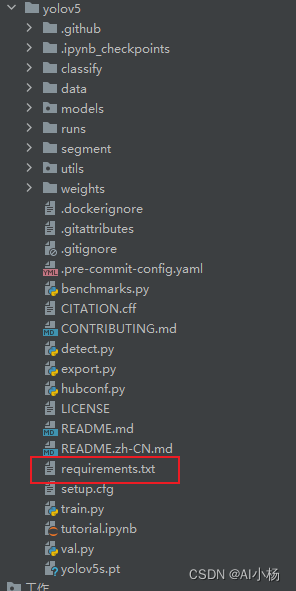
2、安装依赖包
打开yolov5模型可以看到requirement.txt文件,文件里面是yolov5模型需要安装的包:
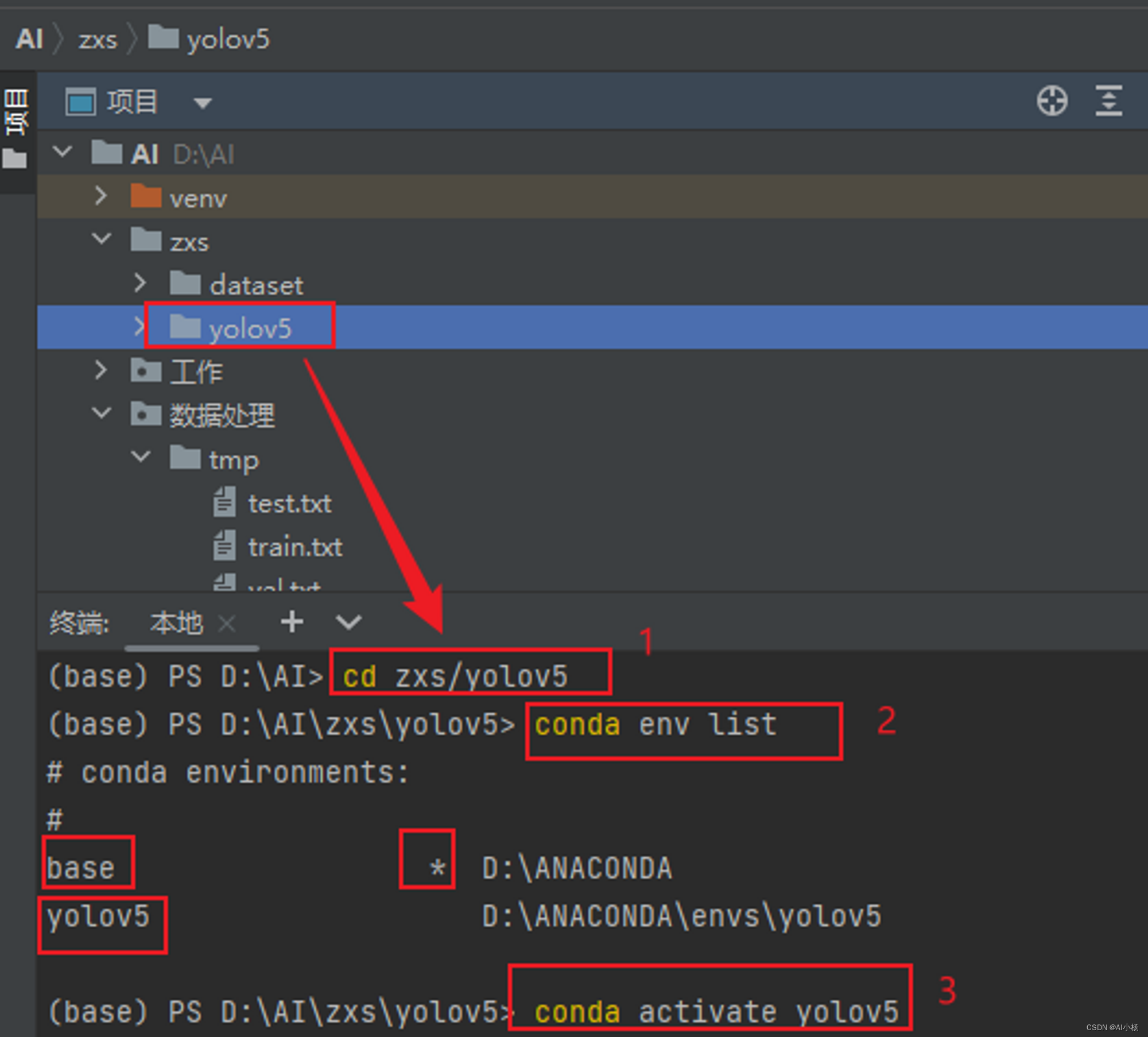
(1)、进入pycharm的终端
(2)、进入环境
步骤如下图:1是终端路径进入yolov5模型里面,2 是查看当前的conda环境,“*”表示当前所处的conda环境,3是切换到yolov5的conda环境里面。
(3)、安装依赖包
pip install -r requirements.txt
3、测试依赖是否安装成功
找到此文件运行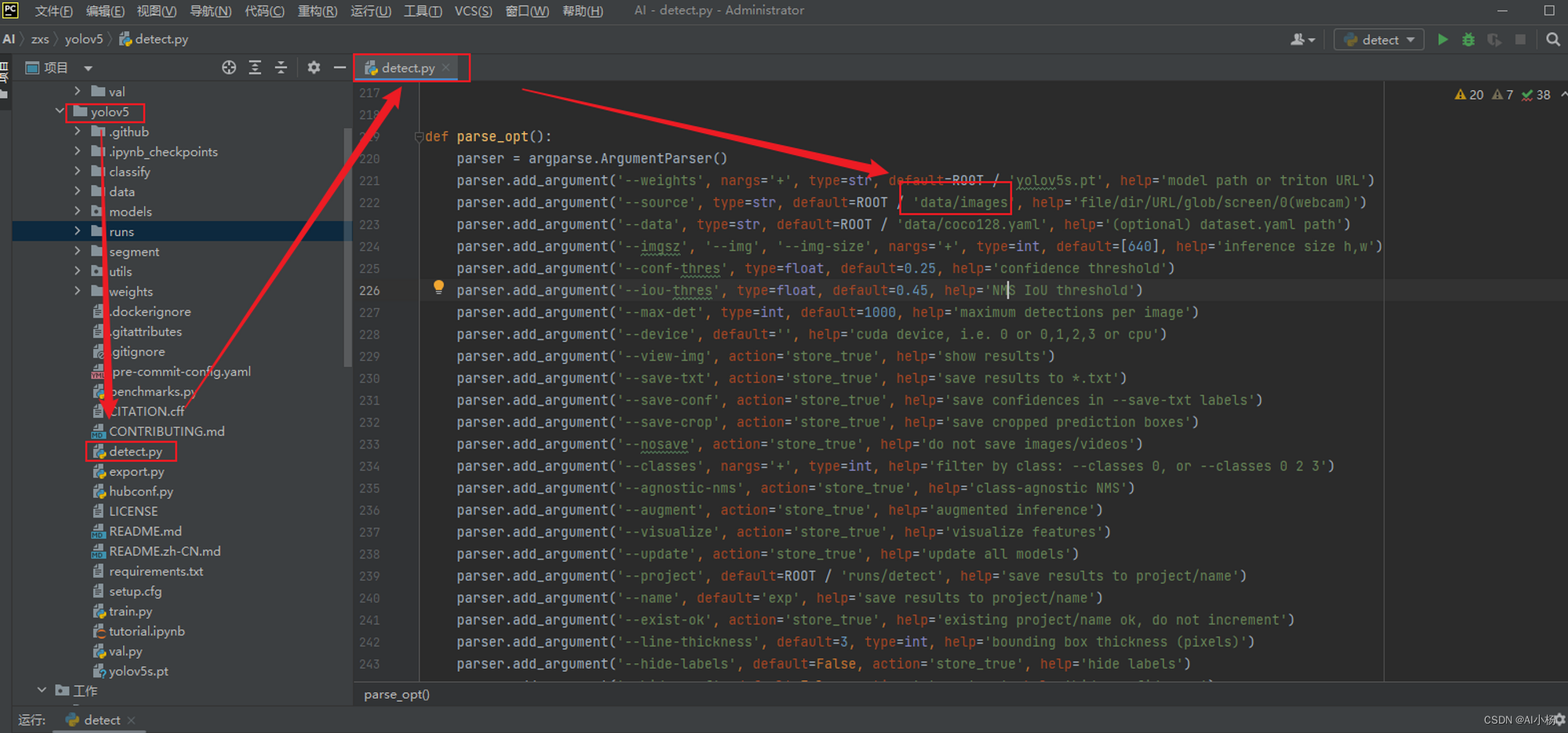
可以发现测试模型的图片放在当前目录下的data/images下:

运行detect.py文件,最后一行反馈出测试结果保存路径,如下图:
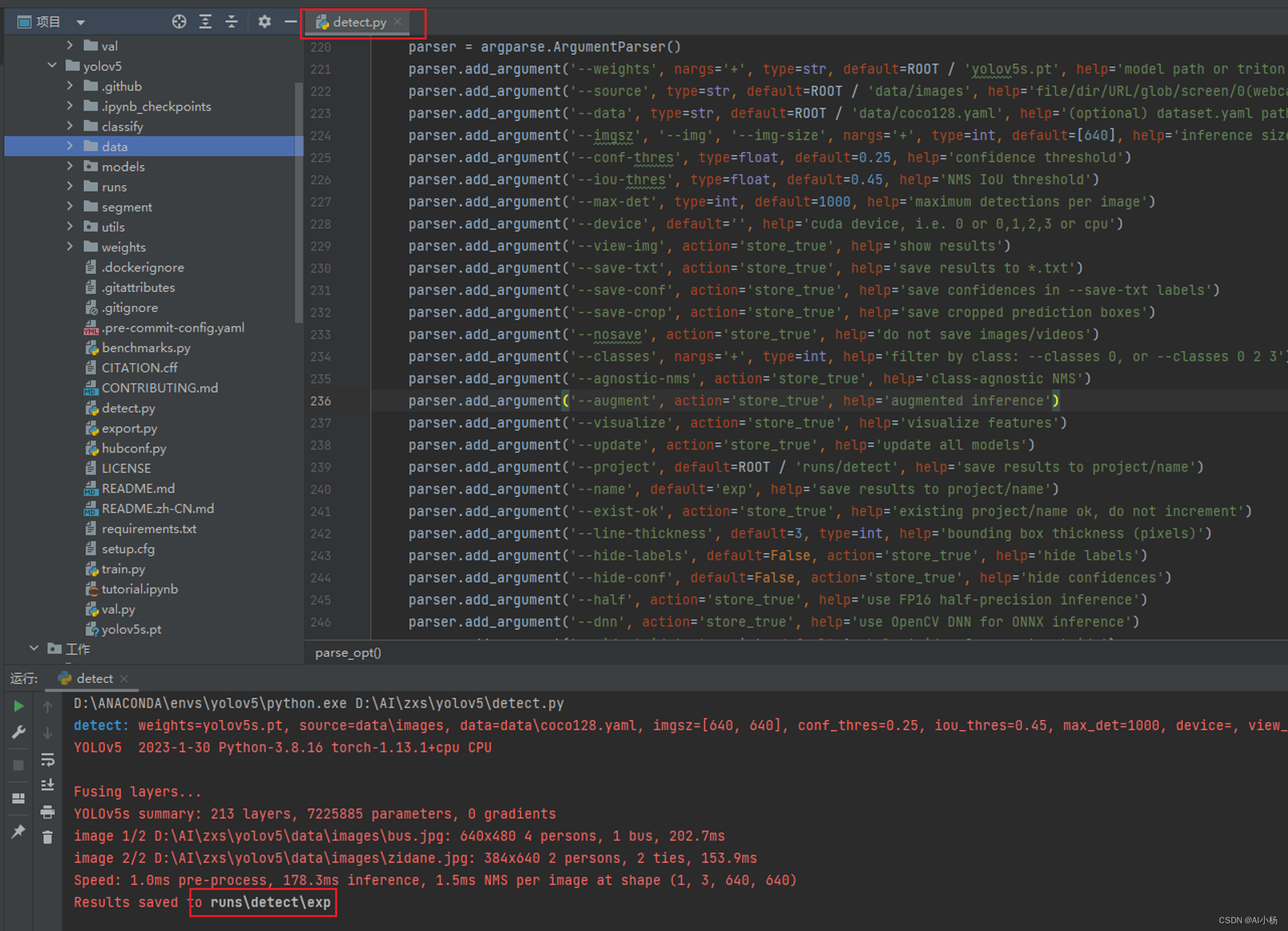
点击进入runs/detect/exp目录,可以发现测试结果:
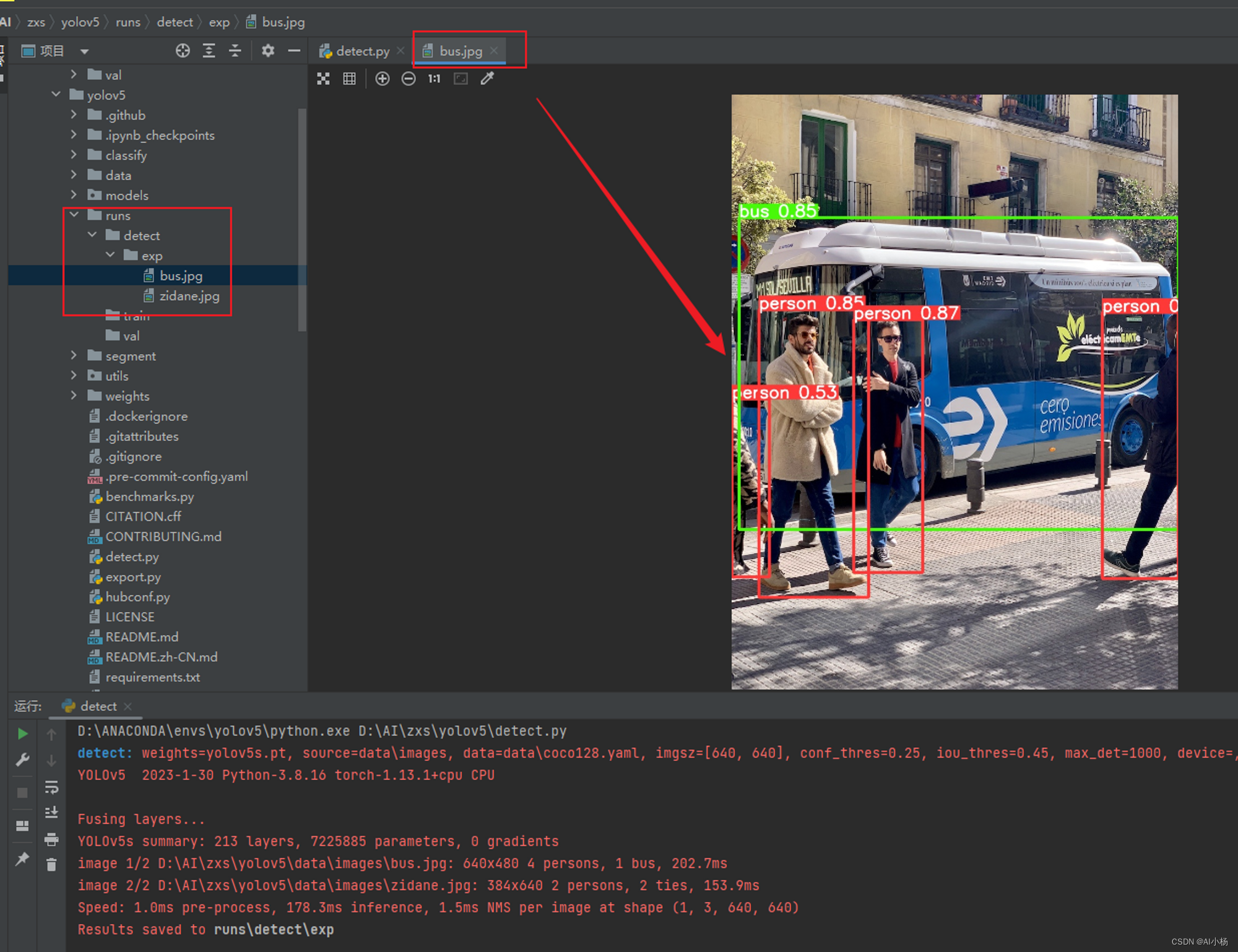
测试成功,表示环境安装成功。
4、文件配置
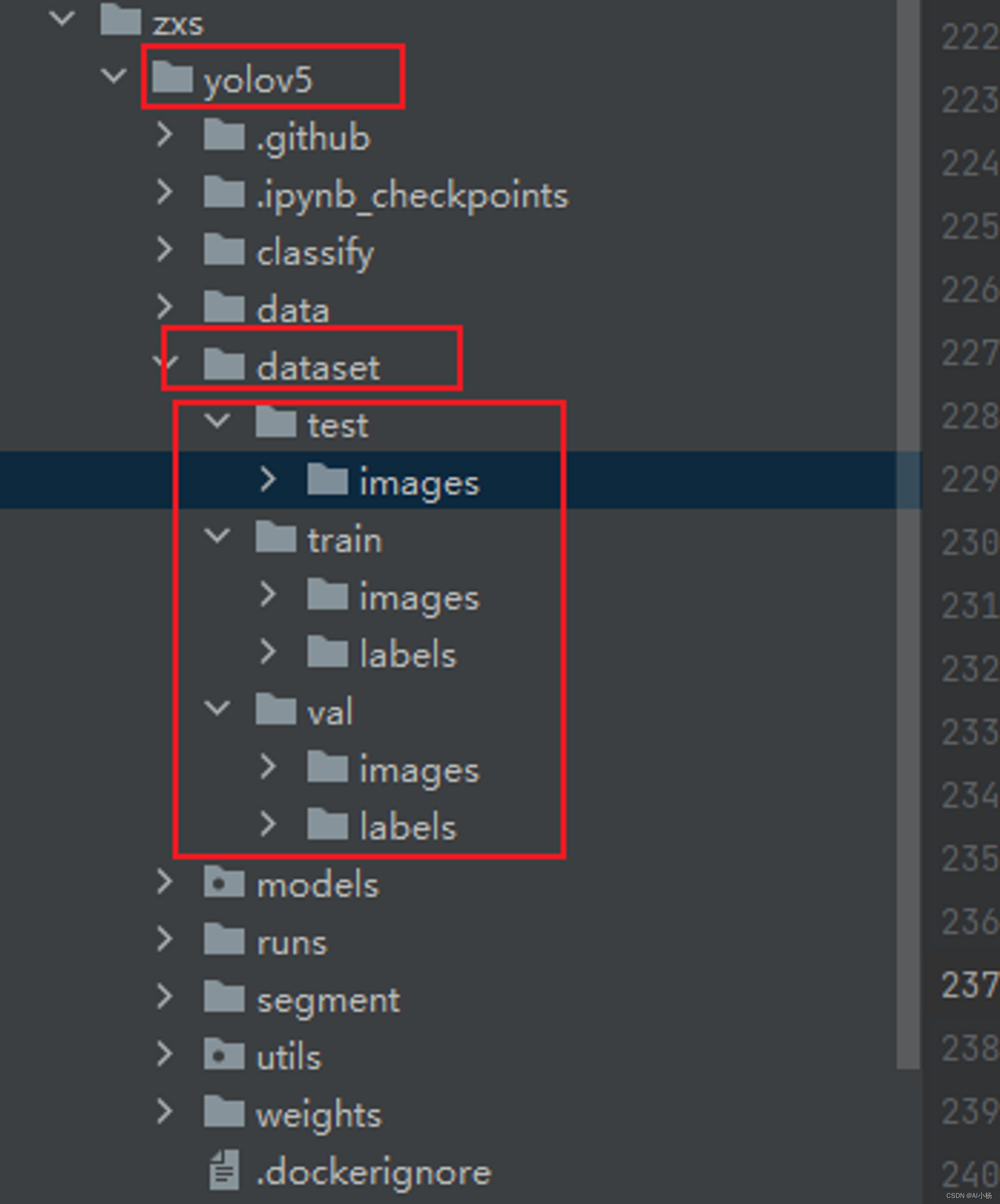
(1)、放入准备好的数据集
注意数据集制作过程参考:yolov5数据集制作
或者可以用标注好的数据集(在文章开头):
(2)、创建.yaml文件
我命名为horse.yaml(无强制要求,看个人需求随意命名):
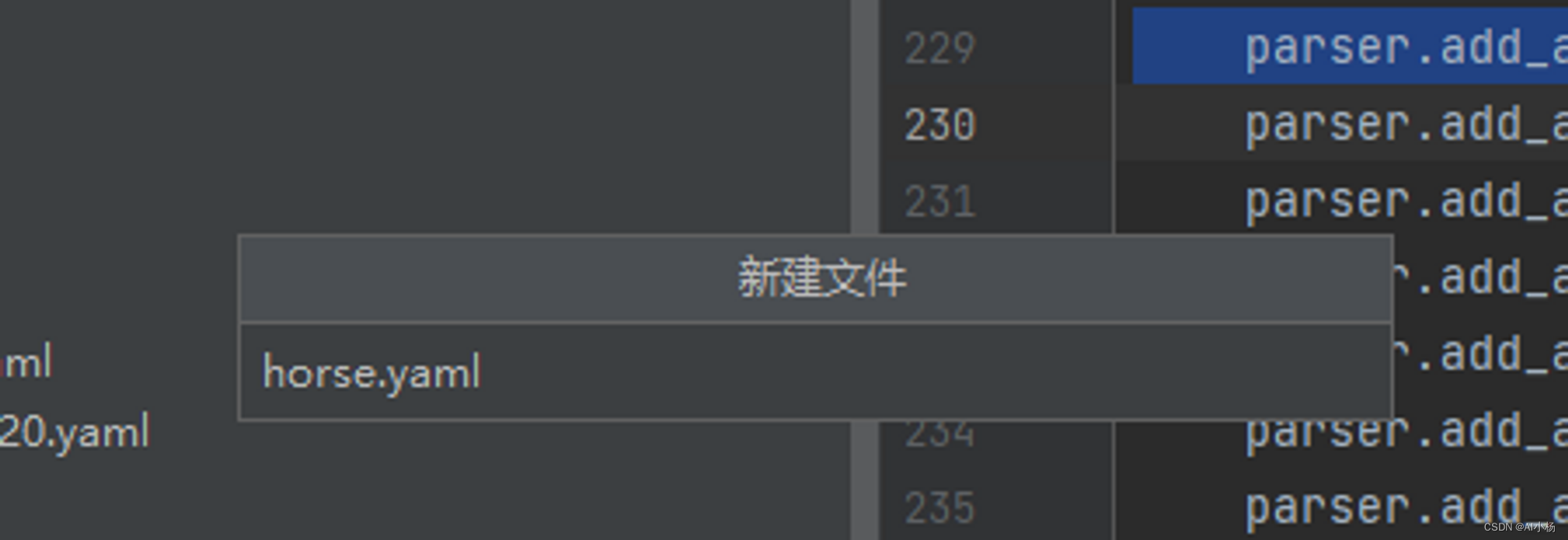
根据数据集的路径进行如下编写,一个是数据集的路径,一个是目标检测的类别标签0和1.
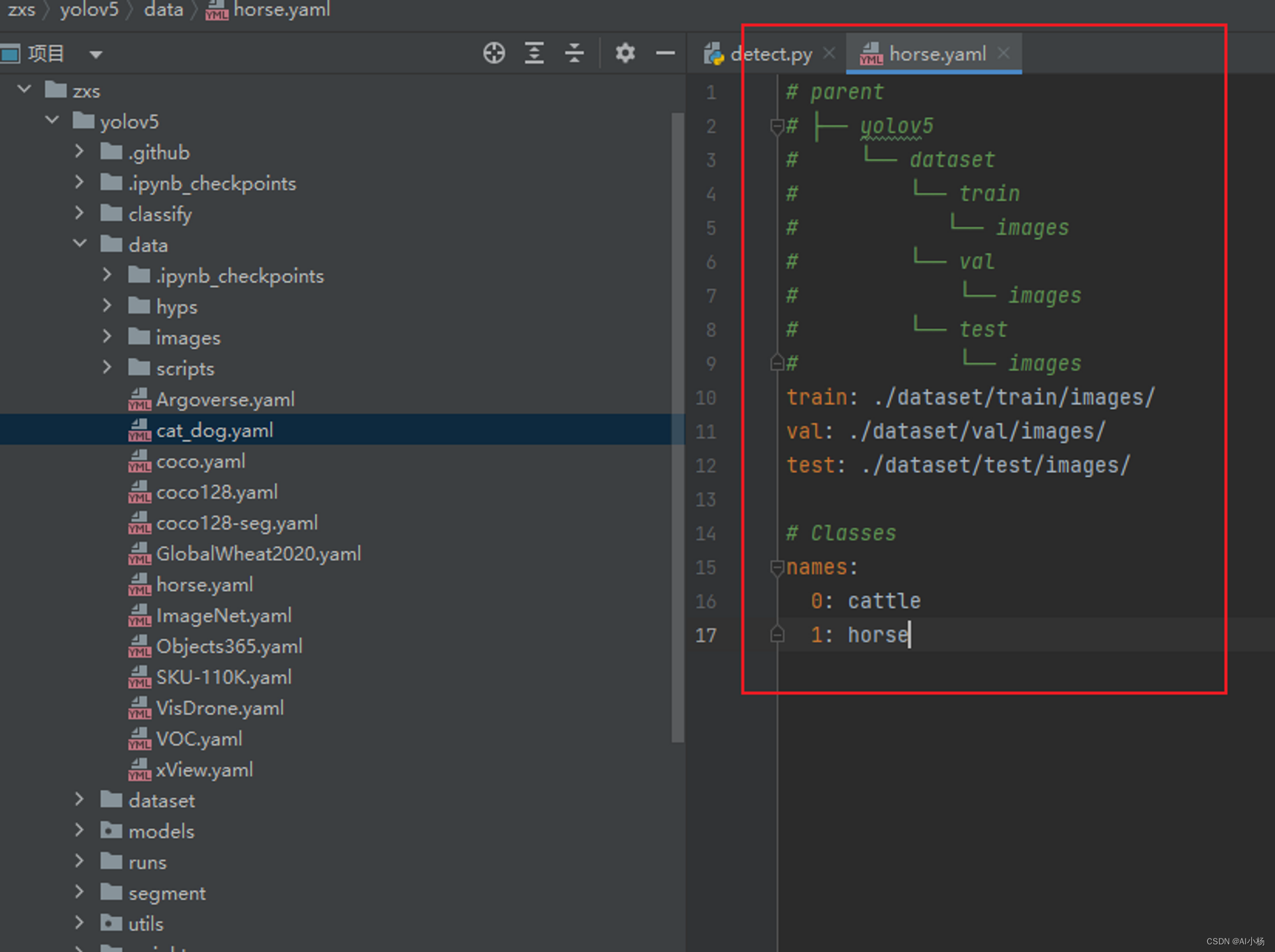
# parent
# ├── yolov5
# └── dataset
# └── train
# └── images
# └── val
# └── images
# └── test
# └── images
train: ../dataset/train/images/
val: ../dataset/val/images/
test: ../dataset/test/images/
# Classes
names:
0: cattle
1: horse
(3)修改目标检测的类别
本次实验是对牛和马两个类别进行检测识别,所有把类别修改为2
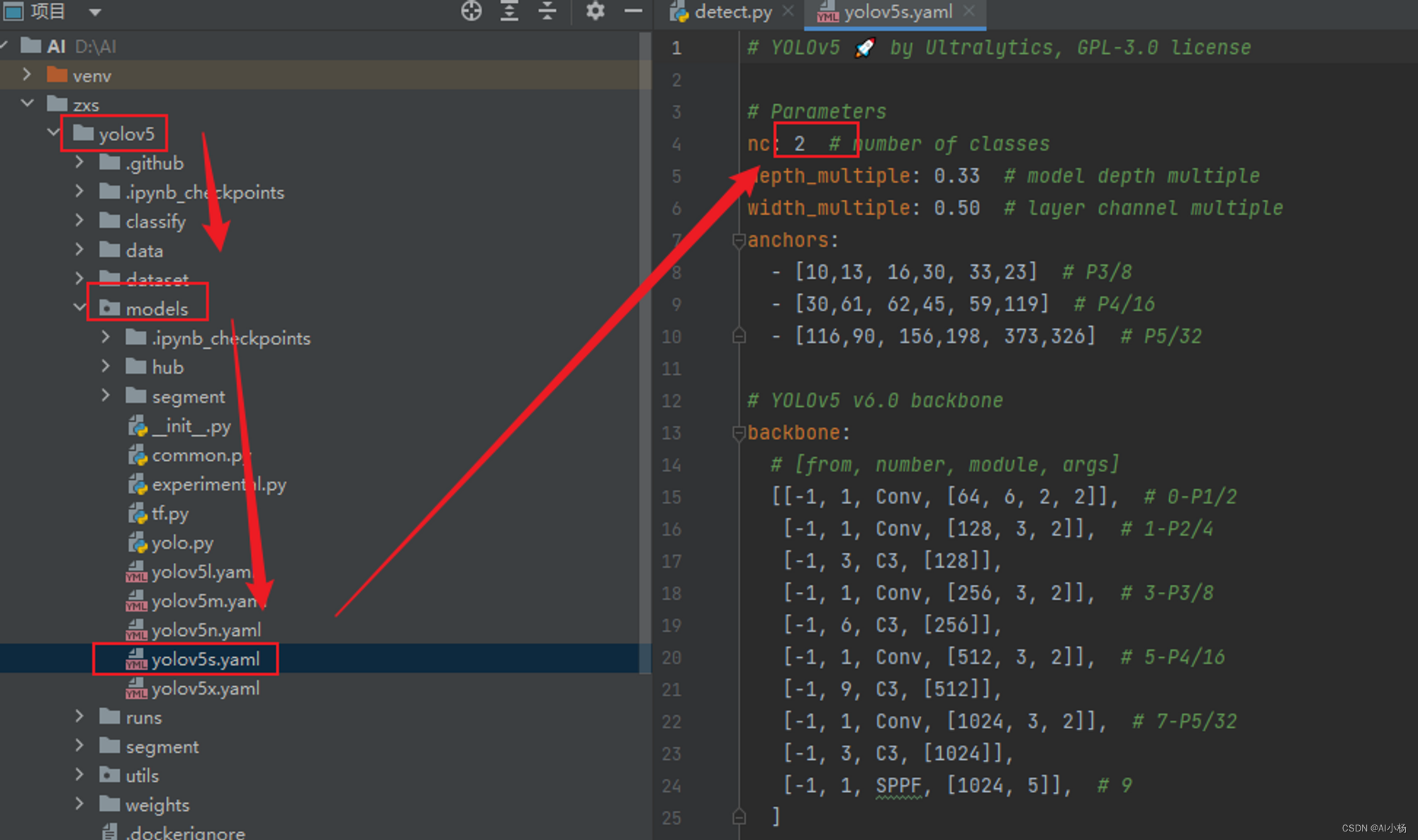
配置准备就绪。
5、模型训练
在终端输入如下代码:
python train.py --img 640 --batch 32 --epoch 100 --data data/horse.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt
–img:输入图片尺寸(640)
–batch:批次文件数量(32)
–epoch:训练轮次(100)
–data:数据集配置文件yaml文件的路径(data/horse.yaml)
–cfg:模型yaml文件的路径地址(models/yolov5s.yaml)
–weights:初始化的权重文件的路径地址(weights/yolov5s.pt)
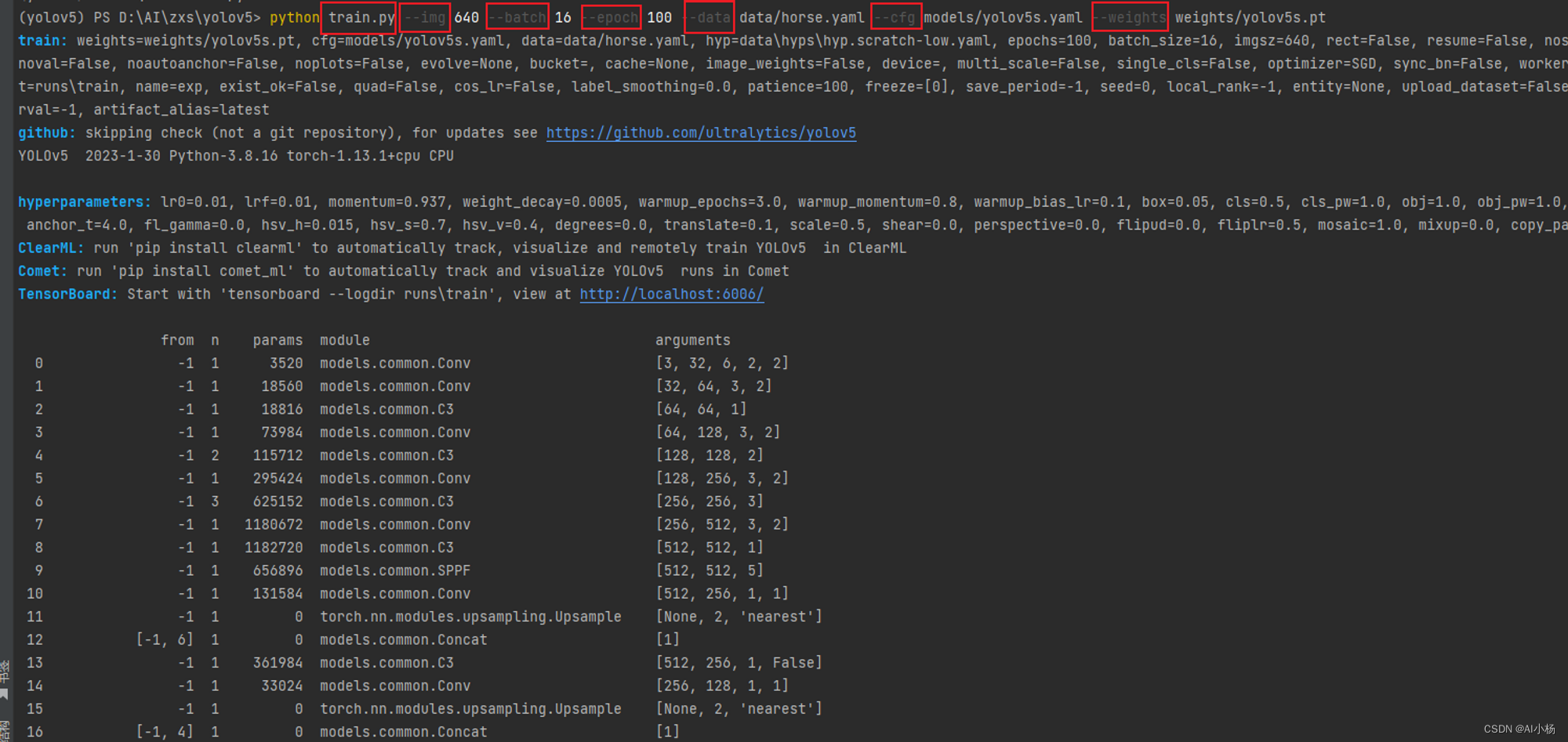
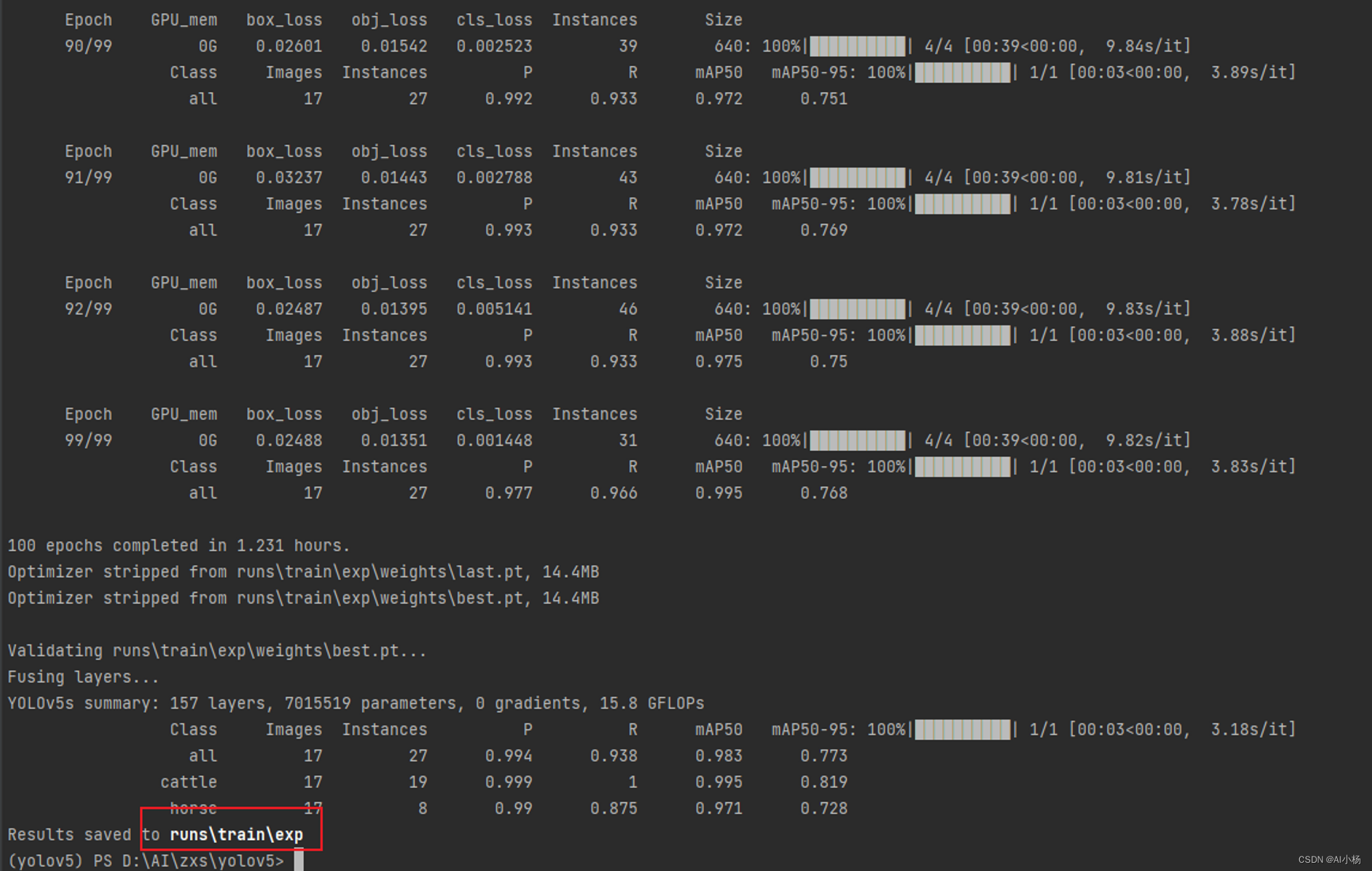
如上图,可以看出,模型训练完100轮后,结果保存在runs/train/exp路径下,进入该路径可以看到模型训练的一些结果:
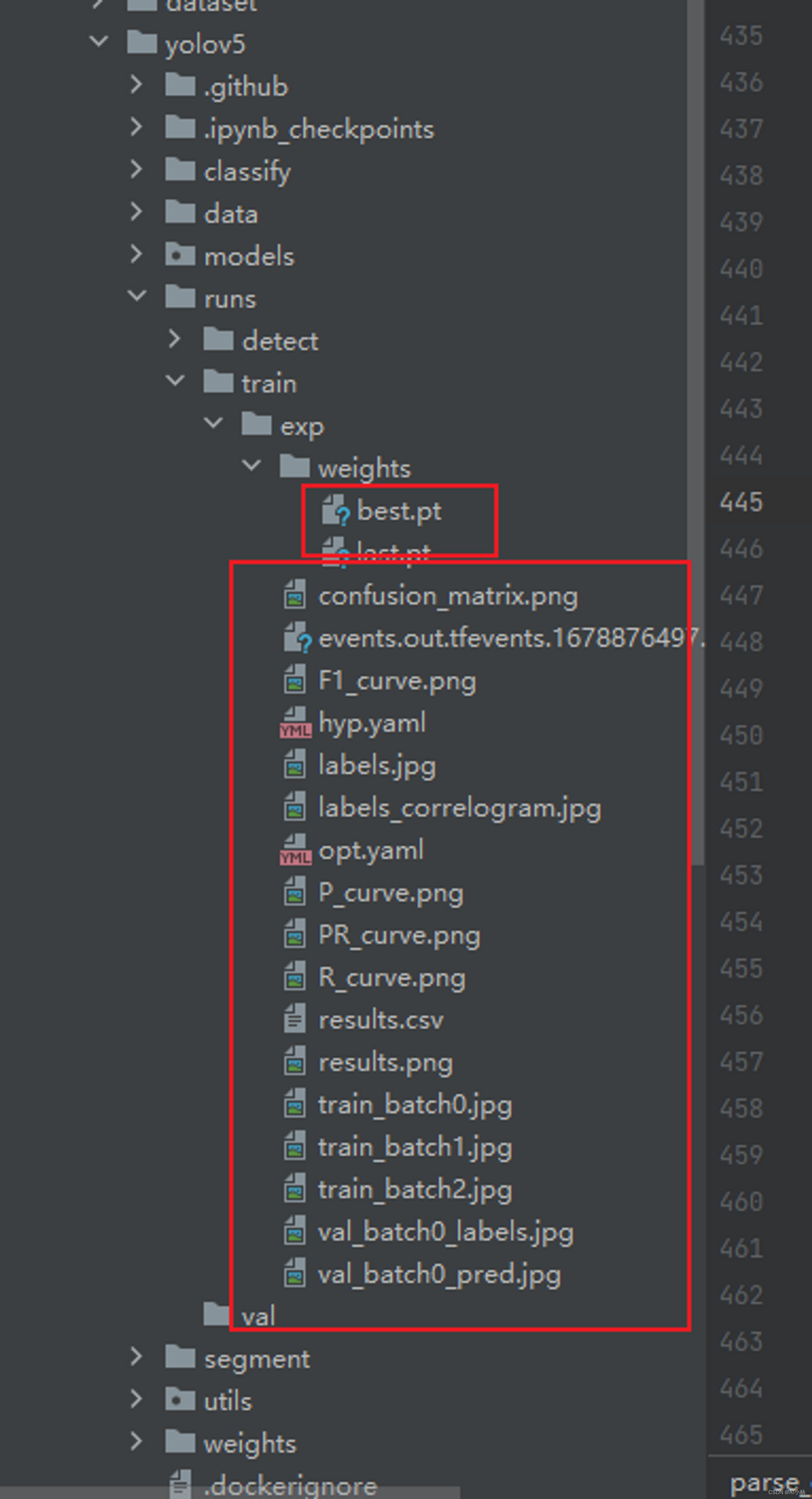
- 随便展示几张结果图:
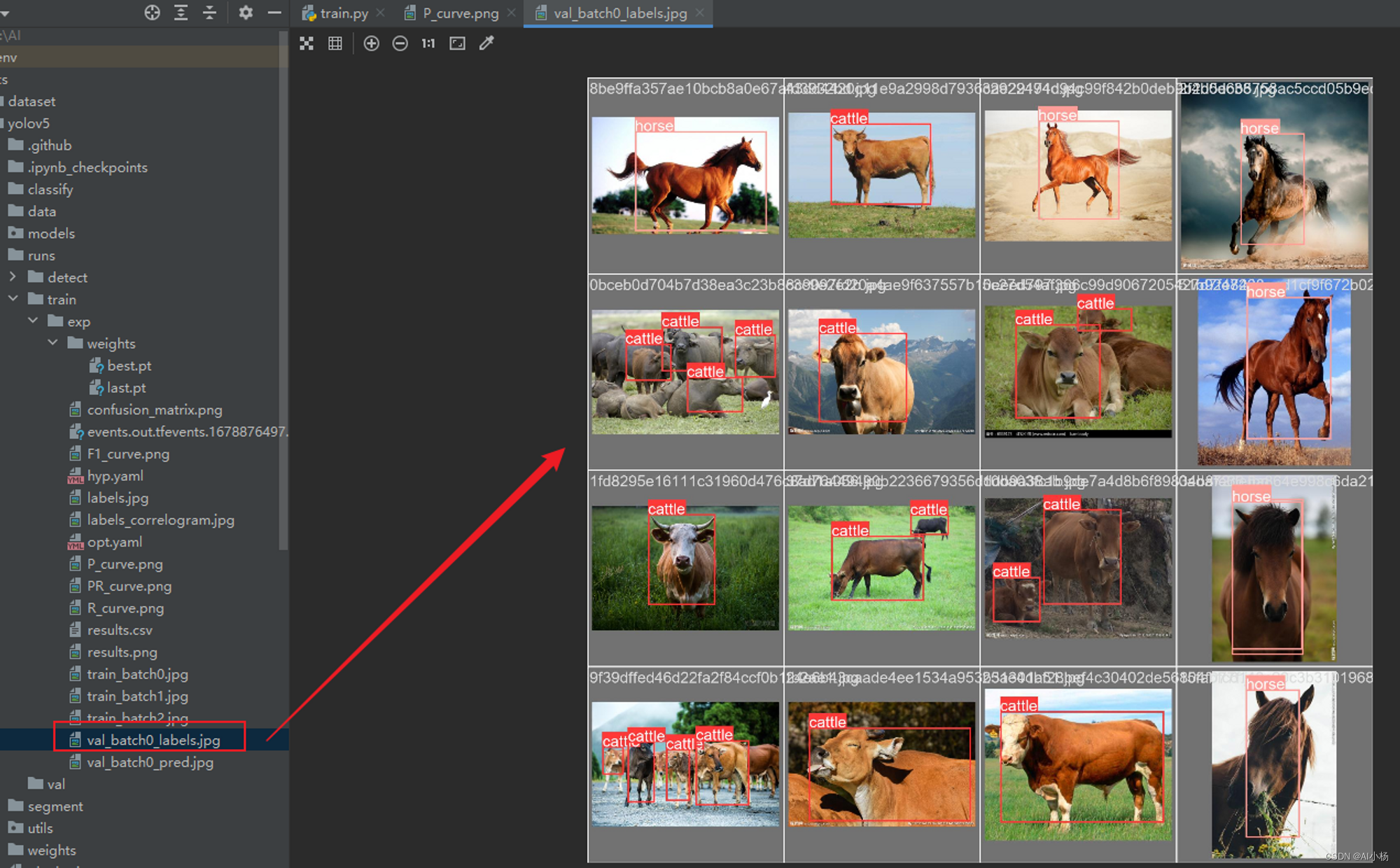
6、模型评估
对模型进行评估推理预测,代码如下:
python val.py --weights runs/train/exp/weights/best.pt --data ./data/horse.yaml --img 640
–weights:训练后的模型路径(runs/train/exp/weights/best.pt,exp后的数字应 与训练结果输出的路径一致)
–data:数据集配置文件yaml文件的路径(data/horse.yaml)
–img:输入图片尺寸(640)
- 运行截图:
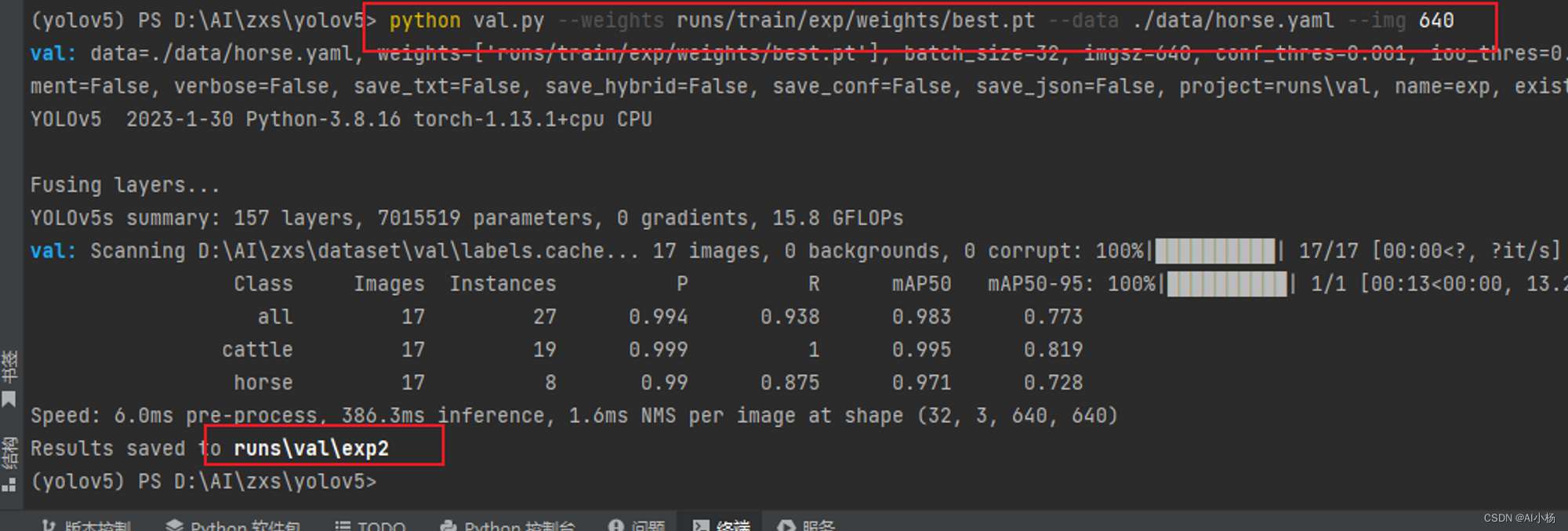
可以发现模型评估结果保存到runs/val/exp2路径下,进入此文件夹内:
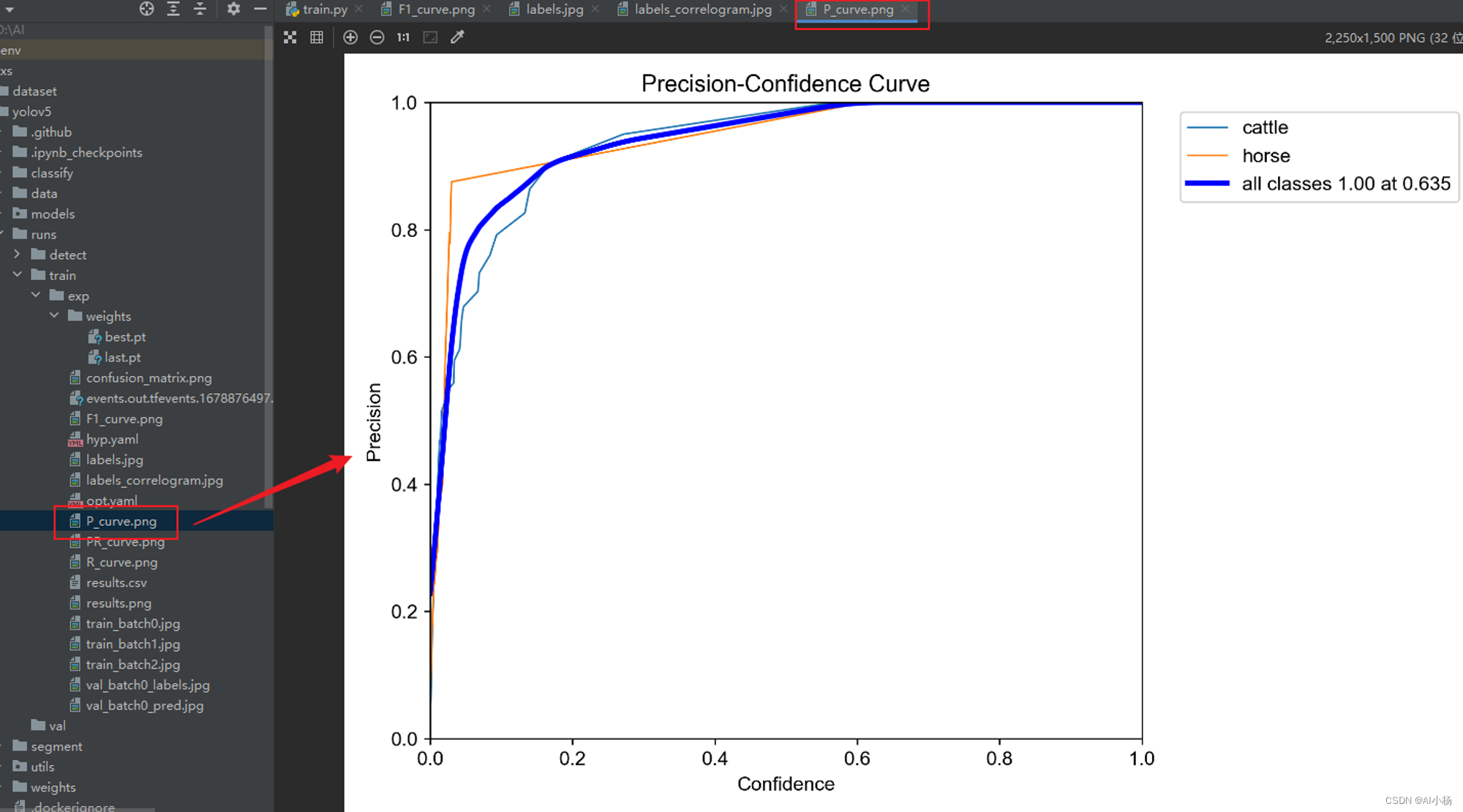
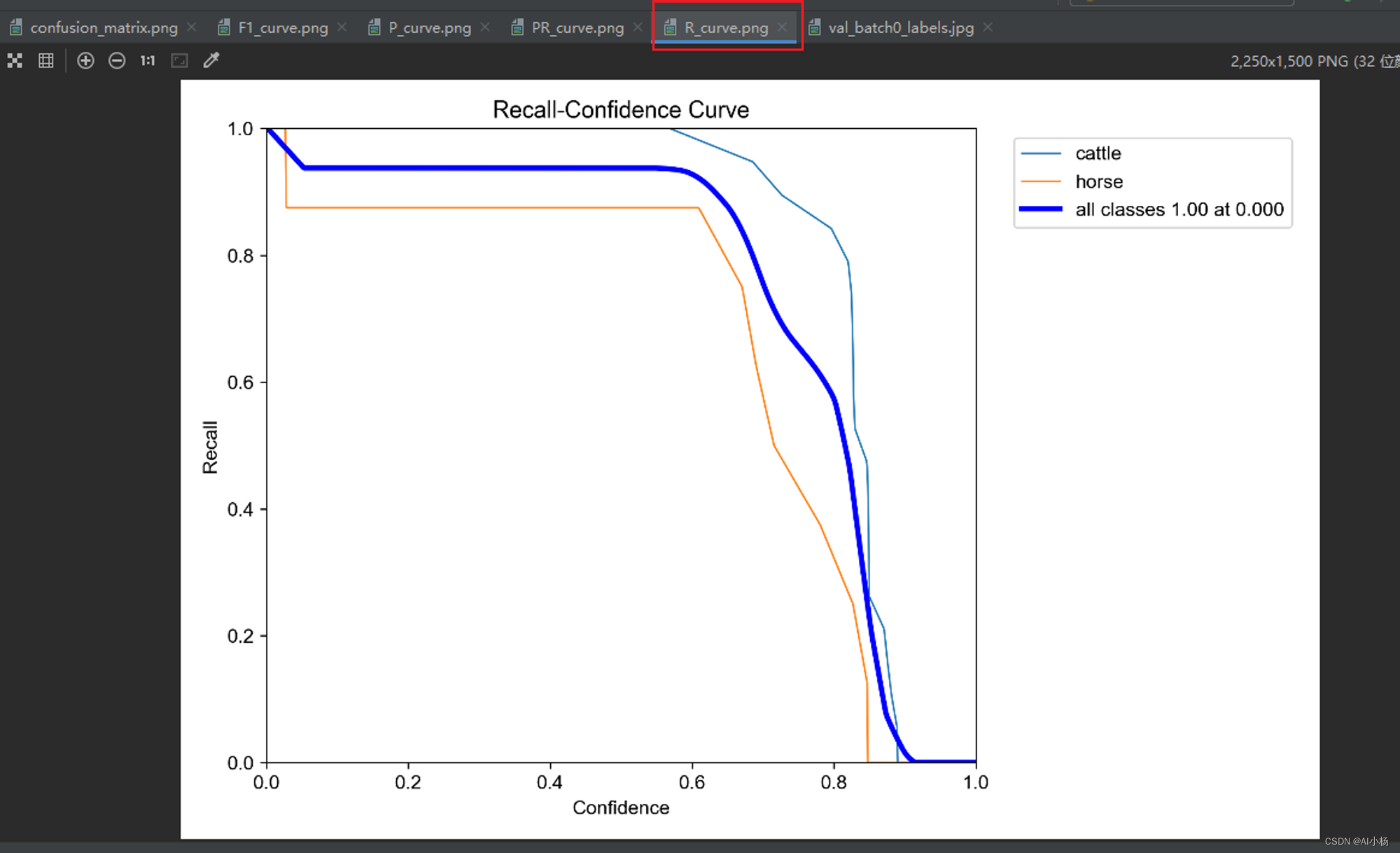
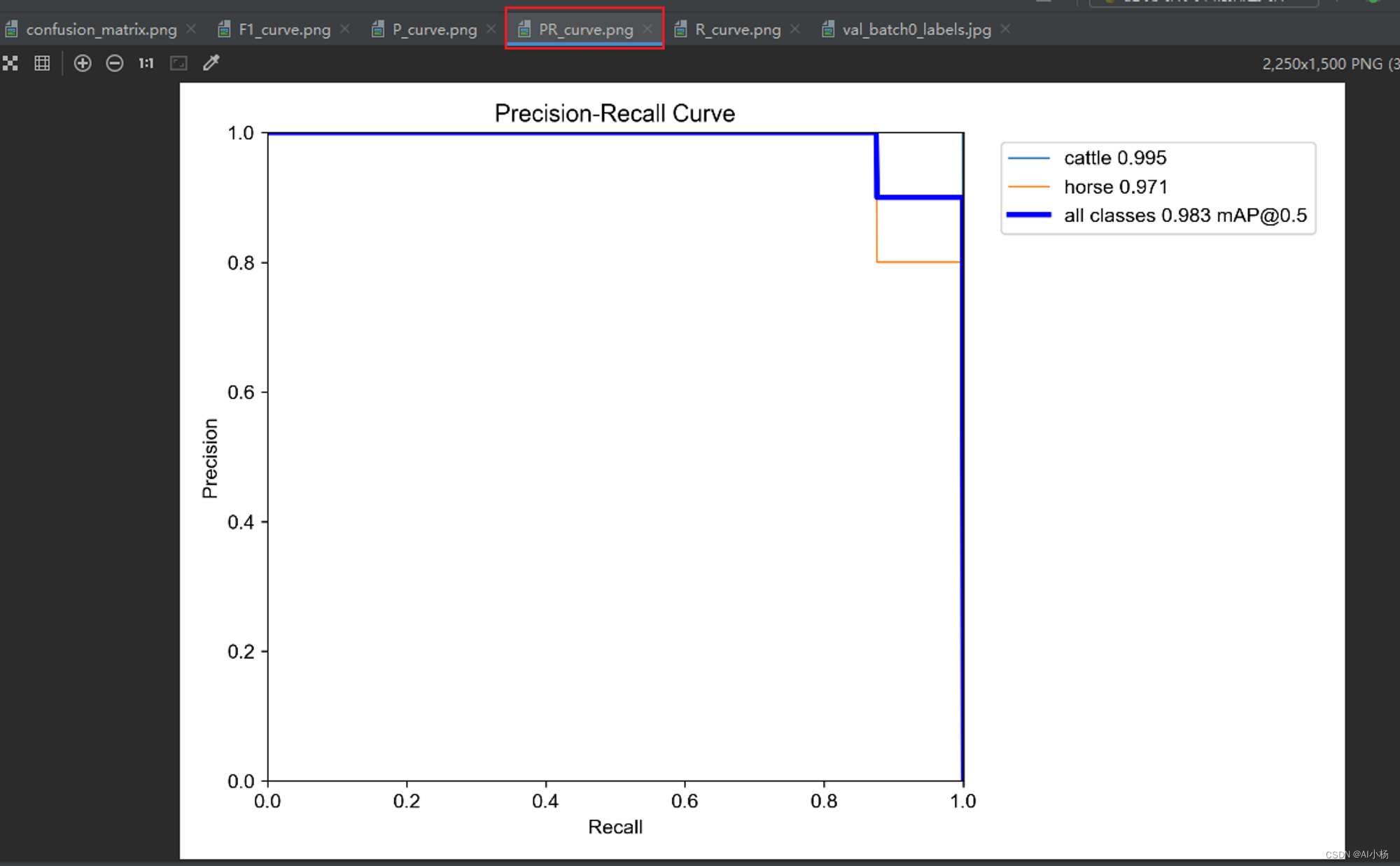
下面的图片展示了模型在训练过程中不同指标的变化情况
●召回率(R_curve.png)
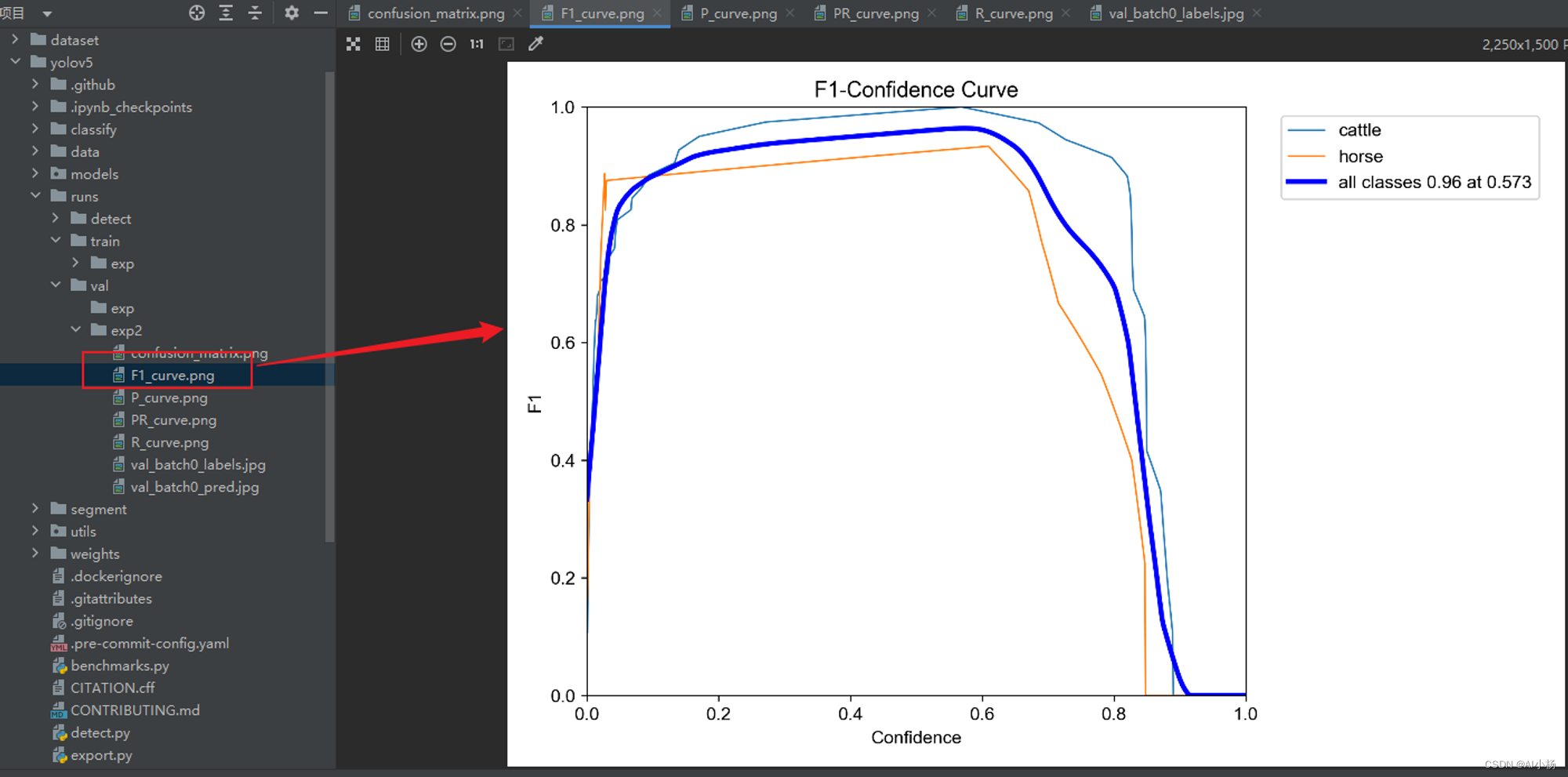
●F1-Score(F1_curve.png)
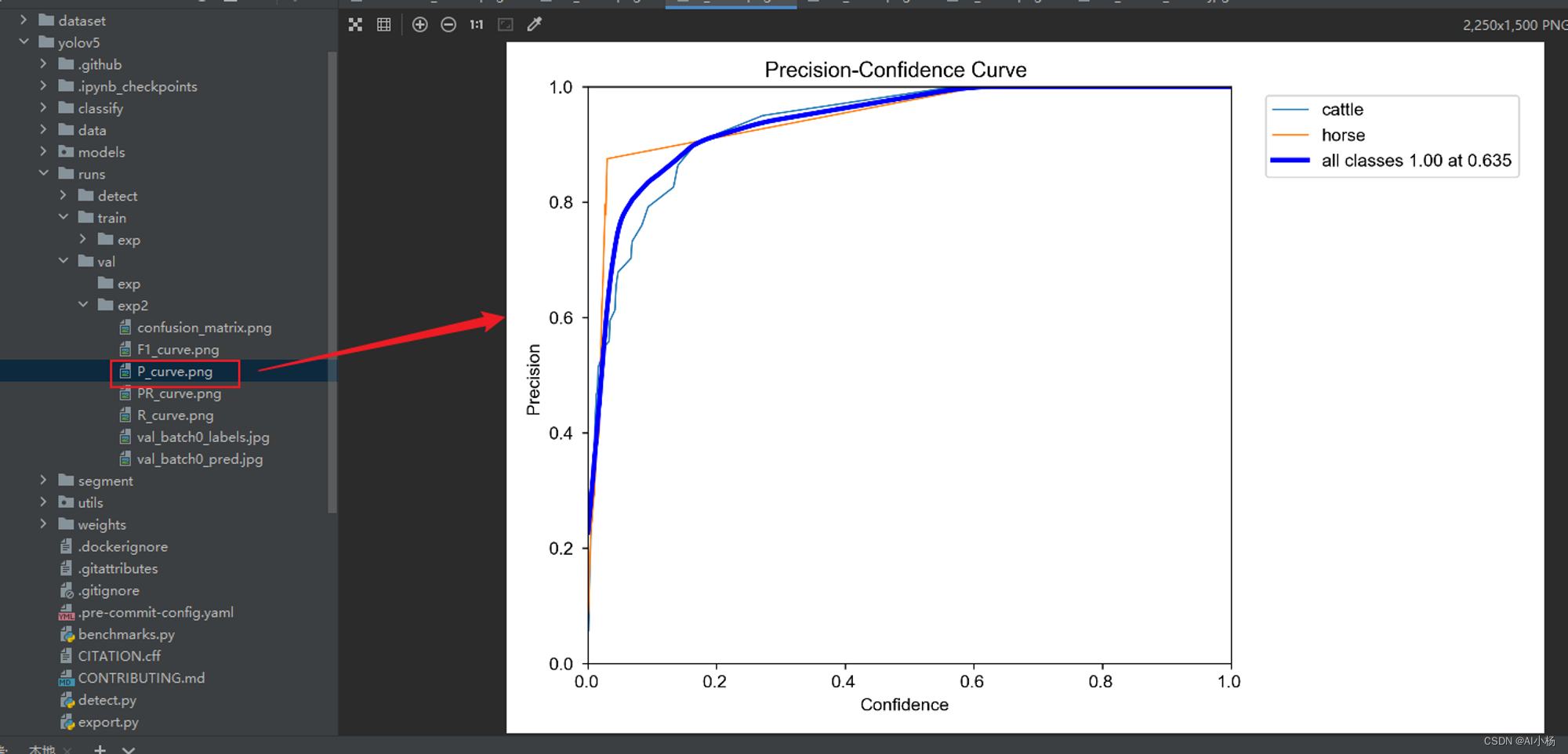
●准确率(P_curve.png)
●PR曲线(PR_curve.png)
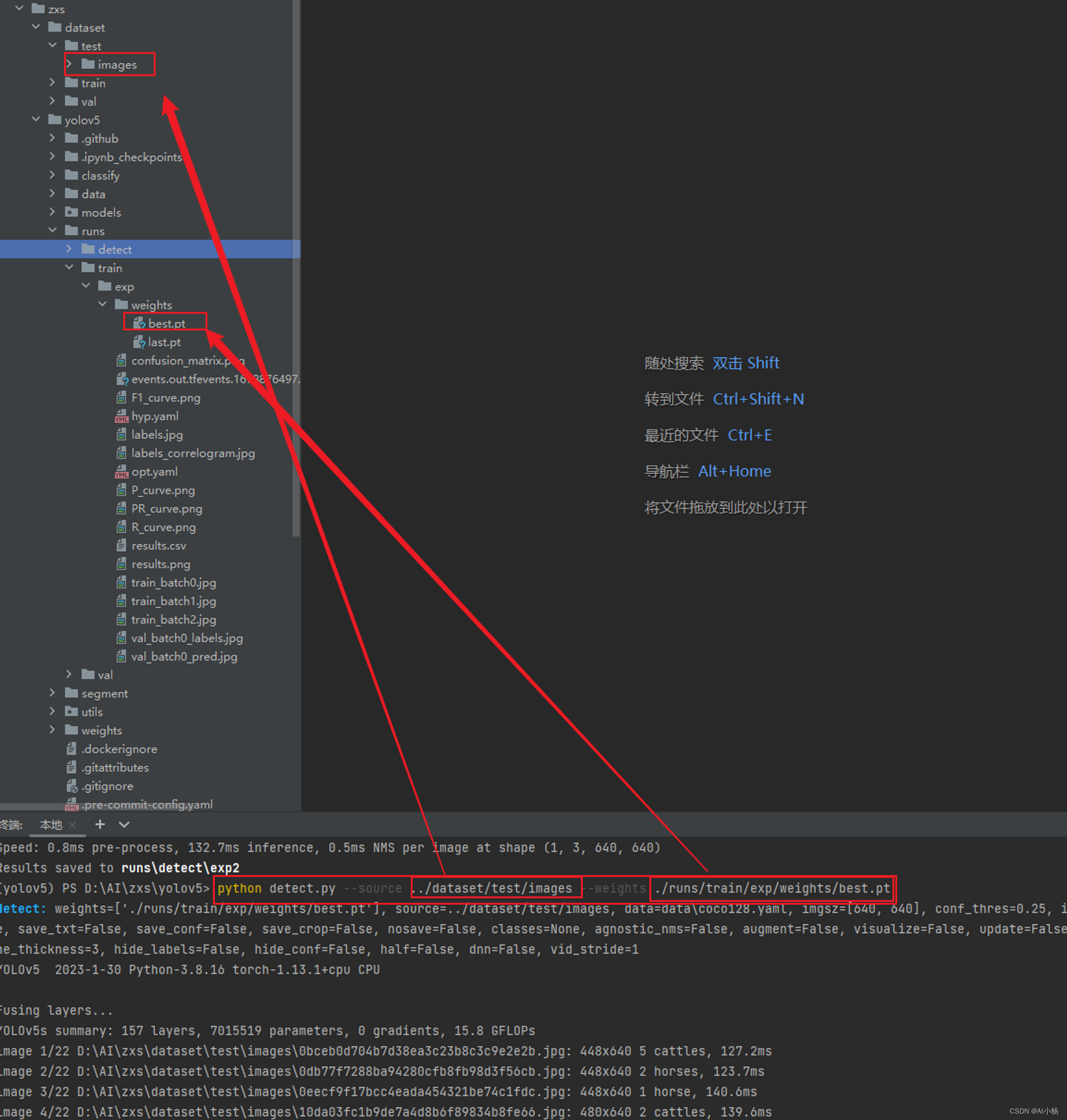
7、模型推理
python detect.py --source ../dataset/test/images --weights ./runs/train/exp/weights/best.pt
–weights:训练后的模型路径(runs/train/exp/weights/best.pt,与模型评估中的路 径一致)
–source:测试集的路径(…/dataset/test/images)
- 运行截图:
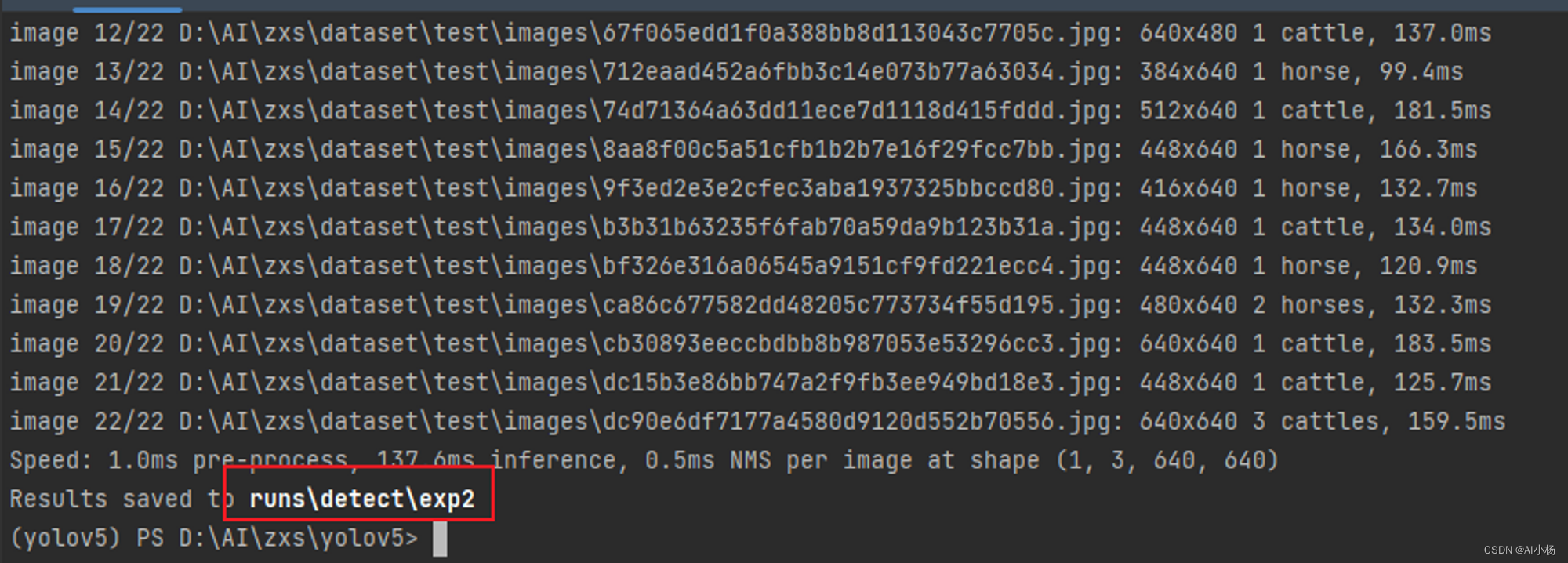
- 推理结果展示:
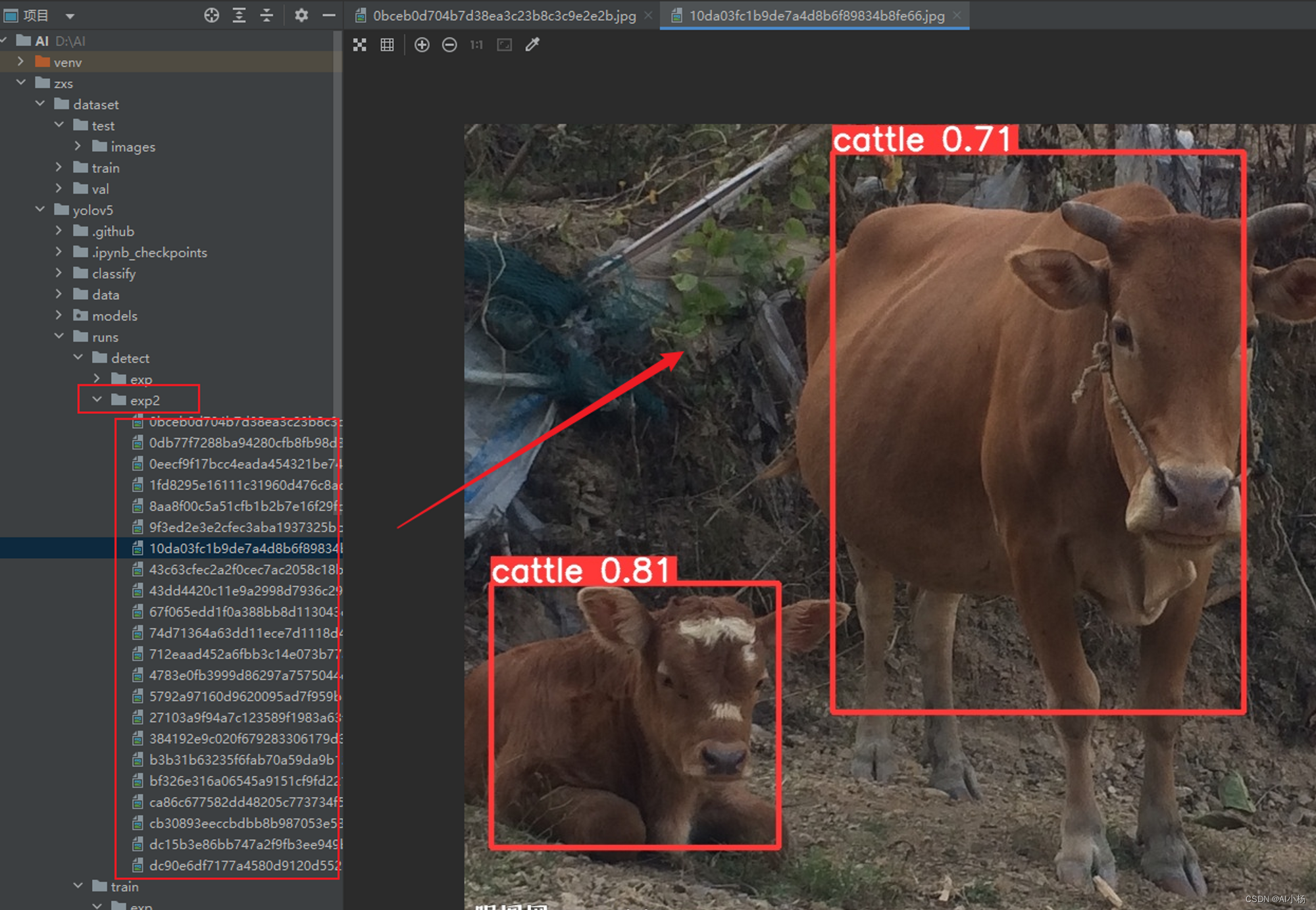
















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











