










论文信息
Subjects: Computation and Language (cs.CL)
(1)题目:A Survey on Deep Learning for Named Entity Recognition (命名实体识别的深度学习研究综述)
(2)文章下载地址:https://doi.org/10.48550/arXiv.1812.09449
Cite as: arXiv:1812.09449 [cs.CL]
(or arXiv:1812.09449v3 [cs.CL] for this version)
(3)相关代码:No official code found
(4)作者信息:Jing Li
————————————————
目录
Abstract
Named entity recognition (NER) is the task to identify mentions of rigid designators from text belonging to predefined semantic types such as person, location, organization etc. NER always serves as the foundation for many natural language applications such as question answering, text summarization, and machine translation. Early NER systems got a huge success in achieving good performance with the cost of human engineering in designing domain-specific features and rules. In recent years, deep learning, empowered by continuous real-valued vector representations and semantic composition through nonlinear processing, has been employed in NER systems, yielding stat-of-the-art performance. In this paper, we provide a comprehensive review on existing deep learning techniques for NER. We first introduce NER resources, including tagged NER corpora and off-the-shelf NER tools. Then, we systematically categorize existing works based on a taxonomy along three axes: distributed representations for input, context encoder, and tag decoder. Next, we survey the most representative methods for recent applied techniques of deep learning in new NER problem settings and applications. Finally, we present readers with the challenges faced by NER systems and outline future directions in this area.
命名实体识别(NER)是从属于预定义语义类型(如人、位置、组织等)的文本中识别刚性指示符的任务。早期的NER系统在设计特定领域的特征和规则时,以人力工程的成本获得了巨大的成功。近年来,由连续实值向量表示和通过非线性处理的语义合成所支持的深度学习已被应用于NER系统,产生了最先进的性能。在本文中,我们全面回顾了现有的NER深度学习技术。 我们首先介绍NER资源,包括标记的NER语料库和现成的NER工具。然后,我们沿着三个轴基于分类法对现有作品进行系统分类:输入的分布式表示、上下文编码器和标记解码器。接下来,我们调查了在新的NER问题设置和应用中最具代表性的深度学习应用技术方法。最后,我们向读者介绍了NER系统面临的挑战,并概述了该领域的未来方向。
introduction
NER:命名实体识别(Named Entity Recognition,NER)是NLP中一项非常基础的任务。 NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。.命名实体识别的准确度,决定了下游任务的效果,是NLP中非常重要的一个基础问题。
AMED实体识别(NER)旨在识别属于预定义语义类型(如人、位置、组织等)的文本中对刚性指示符的提及[1]。NER不仅作为信息提取(IE)的独立工具,而且在各种自然语言处理(NLP)应用中发挥着重要作用,如文本理解[2]、[3]、信息检索[4]、[5]、自动文本摘要[6]、问题解答[7]、机器翻译[8]和知识库构建[9]等。
我们通常将NEs分为两类:一般NEs(例如,人和地点)和域特定NEs(如,蛋白质、酶和基因)。
关于NER中应用的技术,有四个主流:
- 基于规则的方法,它们不需要注释数据,因为它们依赖手工编制的规则;
- 无监督学习方法,其依赖于无监督算法,无需手动标记训练示例;
- 基于特征的监督学习方法,其依赖于具有仔细特征工程的监督学习算法;
- 基于深度学习的方法,以端到端的方式自动从原始输入中发现分类和/或检测所需的表示。
我们简要介绍1)、2)和3),并详细回顾4)
background
我们首先给出了NER问题的正式表述。然后,我们介绍了广泛使用的NER数据集和工具。接下来,我们详细介绍了评估指标,并总结了NER的传统方法。
1. What is NER?
命名实体是一个单词或短语,它从一组具有相似属性的其他项目中明确标识一个项目。NER 是将文本中的命名实体定位并分类为预定义实体类别的过程。
形式上,given a sequence of tokens s = <w1, w2, …, wn >, NER is to output a list of tuples <Is, Ie, t>,如下图所示,其中每一个都是s中提到的命名实体Is∈ [1,N]和Ie∈ [1,N]是命名实体提及的开始和结束索引;t是预定义类别集合中的实体类型。

图1显示了一个NER系统从给定句子中识别三个命名实体的示例。注意,该任务集中于一小组粗略实体类型和每个命名实体一个类型。我们将这类NER任务称为粗粒度NER。
NER是各种下游应用程序(如信息检索、问题解答、机器翻译等)的重要预处理步骤。 以语义搜索为例来说明NER在支持各种应用程序中的重要性。语义搜索 是指一系列技术,这些技术使搜索引擎能够理解用户查询背后的概念、含义和意图[34]。根据[4],大约71%的搜索查询包含至少一个命名实体。在搜索查询中识别命名实体将帮助我们更好地理解用户意图,从而提供更好的搜索结果。
为了将命名实体纳入搜索中,Raviv等人[35]提出了基于实体的语言模型 [34],该模型考虑了单个术语以及注释为实体的术语序列(在文档和查询中)。也有研究利用命名实体来增强用户体验 ,例如查询推荐[36]、查询自动完成[37]、[38]和实体卡[39]、[40]。
2. NER Resources: Datasets and Tools
标记语料库是包含一个或多个实体类型注释的文档集合。表1列出了一些广泛使用的数据集及其数据源和实体类型(也称为标记类型)的数量。表1总结了2005年之前,数据集主要通过注释具有少量实体类型的新闻文章来开发,适用于粗粒度NER任务。之后,在各种文本源上开发了更多的数据集,包括维基百科文章、对话和用户生成的文本(例如,推文和YouTube评论以及W-NUT中的StackExchange帖子)。标签编号类型变得明显更大,例如HYENA中的505。我们还列出了一些特定领域的数据集,特别是在PubMed和MEDLINE文本上开发的数据集。实体类型的数量从NCBI疾病中的1种到GENIA中的36种不等。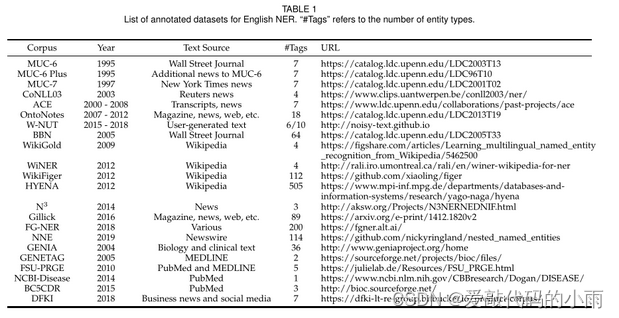
我们注意到,许多最近的NER研究报告了它们在CoNLL03和OntoNotes数据集上的性能(见表3)。
CoNLL03包含两种语言的路透社新闻注释:英语和德语。英语数据集包含大量体育新闻,其中有四种实体类型(个人、地点、组织和杂项)的注释[11]。
OntoNotes项目的目标是注释一个大型语料库,包括各种类型(网络日志、新闻、脱口秀、广播、usenet新闻组和会话电话语音)、结构信息(语法和谓词论证结构)和浅语义(与本体和共指关联的词义)。从1.0版到5.0版共有5个版本。文本注释有18种实体类型。我们还注意到两个Github资源库1,其中包含一些NER语料库。
有许多NER工具可用于在线预训练模型。表2按学术界(顶部)和行业(底部)总结了英语NER的流行值。
3. NER Evaluation Metrics
NER系统通常通过将其输出与人类注释进行比较来评估。可以通过精确匹配或放松匹配来量化比较。
3.1精确匹配评估
NER主要涉及两个子任务:边界检测和类型识别。在“精确匹配评估”[11],[41],[42]中,正确识别的实例需要系统同时正确识别其边界和类型。更具体地说,假阳性(FP)、假阴性(FN)和真阳性(TP)的数量用于计算精度、召回和F分数。
• False Positive (FP): entity that is returned by a NER system but does not appear in the ground truth.
• False Negative (FN): entity that is not returned by a NER system but appears in the ground truth.
• True Positive (TP): entity that is returned by a NER system and also appears in the ground truth
精度是指正确识别的系统结果的百分比。召回是指系统正确识别的实体总数的百分比。
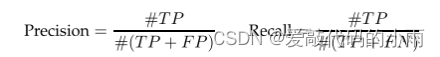
结合精度和召回的度量是精度和召回率的调和平均值,即传统的F度量或平衡F得分:
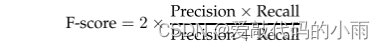
此外,宏观平均F分数和微观平均F分数都考虑了多个实体类型的绩效。宏观平均F得分独立计算不同实体类型的F得分,然后取F得分的平均值。微平均F分数汇总所有实体类型的单个假阴性、假阳性和真阳性,然后应用它们来获得统计数据。后者会受到语料库中大类实体识别质量的严重影响。
3.2轻松匹配评估
MUC-6[10]定义了一种宽松的匹配评估:如果实体被分配了其正确的类型,无论其边界如何,只要与地面真实边界存在重叠,就认为是正确的类型;无论实体的类型分配如何,都会记入正确的边界。然后ACE[12]提出了一个更复杂的评估程序。它解决了一些问题,如部分匹配和错误类型,并考虑了命名实体的子类型。然而,这是有问题的,因为只有当参数固定[1],[22],[23]时,最终得分才是可比的。复杂的评估方法不直观,使误差分析变得困难。因此,复杂的评估方法在最近的研究中没有得到广泛应用。
4. Traditional Approaches to NER
NER的传统方法大致分为三个主流:基于规则的、无监督的学习和基于特征的监督学习方法。
4.1基于规则的方法
基于规则的NER系统依赖手工制定的规则。基于手工制作的语义和句法规则来识别实体。当词汇穷尽时,基于规则的系统工作得很好。由于特定于领域的规则和不完整的字典,这些系统经常观察到高精度和低召回率,并且系统不能转移到其他领域。
4.2无监督学习方法
无监督学习的一种典型方法是聚类[1]。基于聚类的NER系统基于上下文相似性从聚类组中提取命名实体。关键思想是,可以使用在大型语料库上计算的词汇资源、词汇模式和统计信息来推断对命名实体的提及。
4.3 基于特征的监督学习方法
应用特征的监督学习,NER 被投射到多类分类或序列标记任务。给定带注释的数据样本,对特征进行了精心设计,以表示每个训练示例。然后利用机器学习算法来学习模型,以从看不见的数据中识别相似的模式。
特征工程在监督NER系统中至关重要。特征向量表示是对文本的抽象,其中单词由一个或多个布尔值、数值或标称值表示[1],[56]。单词级特征(例如,大小写、形态和词性标记)[57]–[59]、列表查找特征(例如维基百科地名录和DBpedia地名录)[60]–[63]以及文档和语料库特征(例如本地语法和多次出现)[64]–[67]已广泛用于各种受监管的NER系统。
基于这些特征,许多机器学习算法已应用于监督NER,包括隐马尔可夫模型(HMM)[69]、决策树[70]、最大熵模型[71]、支持向量机(SVM)[72]和条件随机场(CRF)[73]。
Deep learning techniques for NER
近年来,基于DL的NER模型成为主流,并取得了最先进的结果。与基于特征的方法相比,深度学习有助于自动发现隐藏特征。接下来,我们首先简要介绍什么是深度学习,以及为什么深度学习适用于NER。然后,我们调查了基于DL的NER方法。
1. Why Deep Learning for NER?
深度学习 是机器学习的一个领域,它由多个处理层组成,以学习具有多个抽象级别的数据表示[87]。典型的层是人工神经网络,由正向传递和反向传递组成。正向传递 计算前一层输入的加权和,并通过非线性函数传递结果。反向传递 是通过导数链式法则计算目标函数相对于多层模块堆栈权重的梯度。深度学习的关键优势是表示学习的能力和由向量表示和神经处理赋予的语义组合。这允许机器输入原始数据,并自动发现分类或检测所需的潜在表示和处理[87]。
将深度学习技术应用于NER有三大核心优势。首先,NER 受益于非线性变换,该变换生成从输入到输出的非线性映射。与线性模型(例如对数线性HMM和线性链CRF)相比,基于DL的模型能够通过非线性激活函数从数据中学习复杂和复杂的特征。第二,深度学习节省了设计NER特征的大量精力。传统的基于特征的方法需要大量的工程技能和领域专业知识。另一方面,基于DL的模型可以有效地从原始数据中自动学习有用的表示和潜在因素。第三,深度神经NER模型可以通过梯度下降以端到端的模式进行训练。这一特性使我们能够设计可能复杂的NER系统。
Why we use a new taxonomy in this survey?
现有的分类法[26],[88]基于字符级编码器、单词级编码器和标签解码器。我们认为,“单词级编码器”的描述是不准确的,因为单词级信息在典型的基于DL的NER模型中使用了两次:1)单词级表示用作原始特征,2)单词级表达(连同字符级表示)用于捕获标签解码的上下文相关性。
NER的最新进展,如下图所示的一般架构。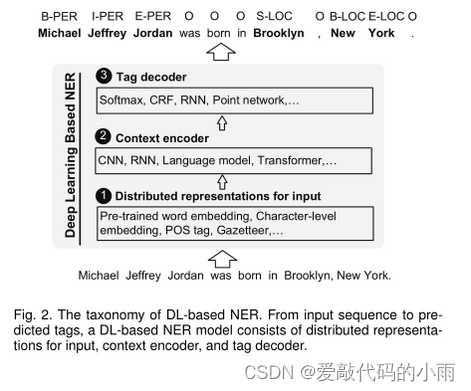
输入的分布式表示考虑了单词和字符级别的嵌入,以及在基于特征的方法中有效的POS标签和地名录等附加特征的结合。上下文编码器是使用CNN、RNN 或其他网络捕获上下文相关性。标记解码器预测输入序列中标记的标记。
在fig.2.中,每个tag都用一个标记进行预测,标记由一个命名实体的B-(开始)、I-(内部)、E-(结束)、S-(单例)及其类型表示,或者命名实体的O-(外部)表示。注意,还有其他标记方案或标记符号,例如BIO。标记解码器也可以被训练以检测实体边界,然后将检测到的文本跨度分类为实体类型。
2.Distributed Representations for Input 输入的分布式表示
表示单词的一个简单选项是一个热向量表示。在一个热向量空间中,两个不同的词具有完全不同的表示并且是正交的。分布式表示表示低维实值密集向量中的单词,其中每个维度表示潜在特征。从文本中自动学习,分布式表示捕获单词的语义和句法属性,这些属性在NER的输入。接下来,我们回顾了NER模型中使用的三种分布式表示:单词级、字符级和混合表示。
2.1单词级表示
通常通过无监督算法(如连续袋词(CBOW)和连续跳格模型[92])对大量文本进行预训练。可以在NER模型训练期间固定或进一步微调预训练的单词嵌入。常用的嵌入词包括Google Word2Sec、Stanford GloVe、Facebook fastText和SENNA。
2.2字符级表示
从端到端神经模型学习的基于字符的单词表示,而不是仅将单词级表示作为基本输入。已经发现字符级表示对于利用诸如前缀和后缀之类的显式子词级信息非常有用。另一个优势,字符级表示的特点是它自然地处理词汇表之外的内容。因此,基于字符的模型能够推断不可见单词的表示,并共享语素水平规则的信息。提取字符级表示有两种广泛使用的架构:基于CNN的模型和基于RNN的模型。如下:

利用CNN提取单词的字符级表示。然后,字符表示向量在馈送到RNN上下文编码器之前与单词嵌入连接。单词的最终嵌入被馈送到双向递归网络中。 Yang等人[102]提出了NER的神经重新排序模型,其中在字符嵌入层的顶部使用具有固定窗口大小的卷积层。最近,Peters等人[103]提出了ELMo单词表示,它是在具有字符卷积的两层双向语言模型之上计算的。
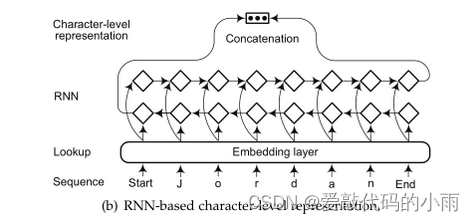
对于基于RNN的模型,长短期存储器(LSTM)和门控递归单元(GRU)是两种典型的基本单元选择。
Kuru 等人[100]提出了CharNER,一种用于语言无关NER的字符级标记器。CharNER将句子视为字符序列,并利用LSTM提取字符级表示。它为每个字符而不是每个单词输出标签分布。然后从字符级标签中获得单词级标签。 他们的结果表明,将字符作为主要表示优于将单词作为基本输入单元。
Lample 等人[19]利用双向LSTM提取单词的字符级表示。类似于[97],字符级表示与来自单词查找表的预训练单词级嵌入相连接。Gridach[104]研究了识别生物医学命名实体时的单词嵌入和字符级表示。Rei 等人[105]使用门控机制将字符级表示与单词嵌入相结合。通过这种方式,Rei 的模型动态地决定了从字符或单词级组件中使用多少信息。Tran等人[101]引入了一种具有堆栈残差LSTM和可训练偏差解码的神经NER模型,其中从单词嵌入和字符级RNN中提取单词特征。Yang等人[106]开发了一个模型,以统一的方式处理跨语言和多任务联合训练。他们使用深度双向GRU来学习信息形态学单词字符序列的表示。然后,字符级表示和单词嵌入被连接以产生单词的最终表示。
使用递归神经网络进行语言建模的最新进展使得将语言建模为字符上的分布成为可能。上下文字符串嵌入使用字符级神经语言模型为句子上下文中的字符串生成上下文化嵌入。一个重要的特性是嵌入是由其周围文本上下文化的,这意味着同一个单词根据其上下文用途具有不同的嵌入。下图说明了在句子上下文中提取嵌入单词“Washington”的上下文字符串的架构。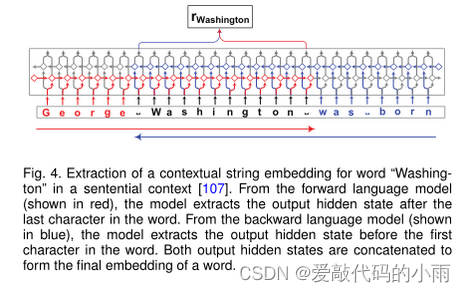
2.3.Hybrid Representation 混合表示法
基于DL的表示以混合方式与基于特征的方法相结合。
添加额外信息可能会提高NER的性能,代价是损害这些系统的通用性。
3.Context Encoder Architectures 上下文编码器体系结构
在这里,我们现在回顾了广泛使用的上下文编码器架构:卷积神经网络、递归神经网络、递推神经网络和深度变换器。
3.1卷积神经网络
句子方法网络,其中在考虑整个句子的情况下对单词进行标记,如图5所示。在输入表示阶段之后,输入序列中的每个单词都嵌入到N维向量中。然后使用卷积层来生成每个单词周围的局部特征,卷积层的输出大小取决于句子中的单词数量。通过组合由卷积层提取的局部特征向量来构造全局特征向量。全局特征向量的维数是固定的,与句子长度无关,以便应用后续的标准仿射层。
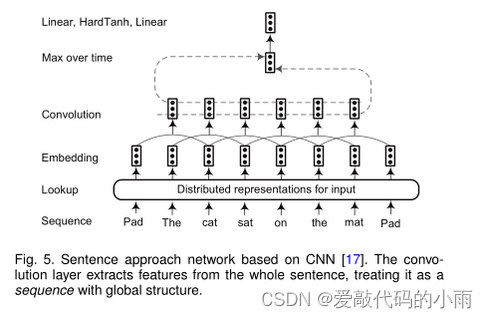
两种方法被广泛用于提取全局特征:对句子中的位置(即“时间”步长)进行最大值或平均值运算。最后,这些固定大小的全局特征被馈送到标签解码器,以计算网络输入中单词的所有可能标签的分布分数。 继Collbert的工作之后,Yao等人[94]提出了生物医学NER的Bio-NER。Wu等人[120]利用卷积层来生成由多个全局隐藏节点表示的全局特征。然后将局部特征和全局特征都输入到标准仿射网络中,以识别临床文本中的命名实体。
使用RNN,后一个词比前一个词对最终句子表示的影响更大。然而,重要的单词可能出现在句子的任何地方。 在他们提出的名为BLSTMRE的模型中,BLSTM用于捕获长期依赖性并获得输入序列的完整表示。然后利用CNN学习高级表示,然后将其输入到S形分类器中。最后,将整句表示(由BLSTM生成)和关系表示(由S形分类器生成)输入另一个LSTM以预测实体
传统上,长度为N的序列的LSTM的时间复杂度以并行方式为O(N)。
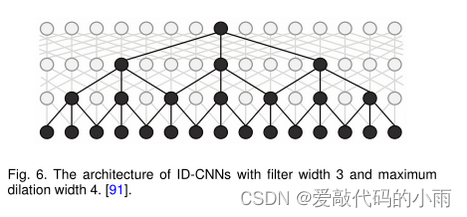
Strubell 等人[91]提出了 ID-CNNs,称为迭代扩张卷积神经网络,由于处理更大的上下文和结构化预测的能力,其计算效率更高。图6显示了一个扩展的CNN块的结构,其中四个宽度为3的堆叠扩展卷积产生令牌表示。实验结果表明,与Bi-LSTM CRF 相比,ID-CNN实现了14-20倍的测试时间加速,同时保持了相当的准确性。
3.2循环神经网络
递归神经网络及其变体,如门控递归单元(GRU)和长短期记忆(LSTM),在序列数据建模方面取得了显著的成就。特别是,双向RNN在特定时间帧内有效地利用过去信息(通过前向状态)和未来信息(通过后向状态)[18]。因此,由双向RNN将包含整个输入句子的证据。因此,双向RNN成为构成文本深度上下文相关表示的事实标准。
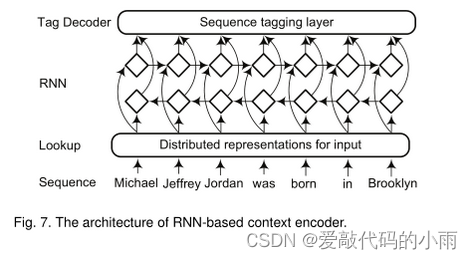
3.3递归神经网络
递归神经网络是非线性自适应模型,它能够通过按拓扑顺序遍历给定的结构来学习深度结构化信息。命名实体与语言成分高度相关,如名词短语[98]。然而,典型的顺序标注方法很少考虑句子的短语结构。为此,Li等人[98]提出对NER的选区结构中的每个节点进行分类。该模型递归计算每个节点的隐藏状态向量,并根据这些隐藏向量对每个节点进行分类。
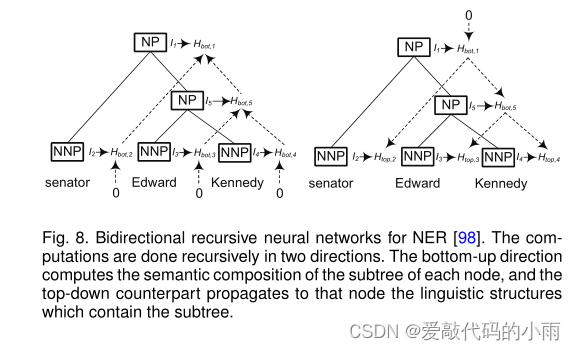
图8显示了如何递归地计算每个节点的两个隐藏状态特征。自底向上的方向计算每个节点子树的语义组成,自顶向下的方向将包含子树的语言结构传播到该节点。给定每个节点的隐藏向量,网络计算实体类型加上一个特殊的非实体类型的概率分布。
3.4神经语言模型
语言模型是描述序列生成的一系列模型。给定一个令牌序列(t1, t2,…, tN),一个正向语言模型通过建模标记tk的概率计算序列的概率给定其历史(t1,…, tk−1)[21]:
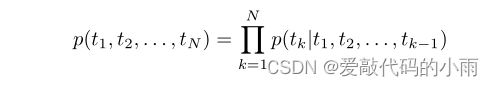
后向语言模型与前向语言模型相似,不同的是它以相反的顺序遍历序列,在给定其未来上下文的情况下预测前一个令牌:
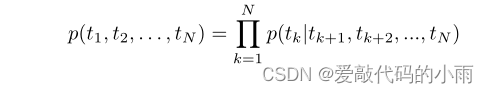
对于神经语言模型,标记tk的概率可以通过递归神经网络的输出来计算。
在每个位置k处,我们可以获得两种上下文相关的表示(向前和向后),然后将它们组合起来作为标记tk的最终语言模型嵌入。这种语言模型增强知识已被经验验证在许多序列标记任务中是有帮助的[21],[103],[124]-[127]。
Rei[124]提出了一个具有次要目标的框架——学习预测数据集中每个单词的周围单词。
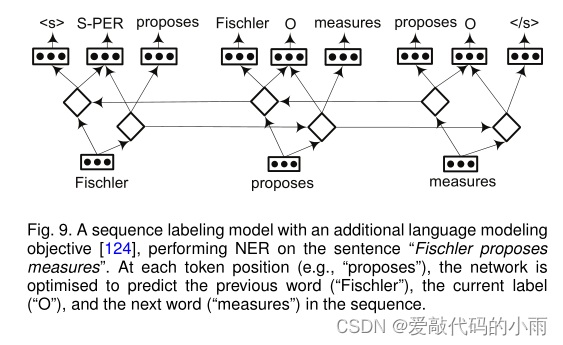
图9用一个简短的句子说明了该架构。在每个时间步(即,令牌位置),网络被优化以预测序列中的前一个令牌、当前标记和下一个令牌。添加的语言建模目标鼓励系统学习更丰富的特征表示,然后重用序列标记。
Peters等人[21]提出了一种语言模型增强序列标记器TagLM。该标记器对序列标记任务的输入序列中的每个标记都考虑预先训练的单词嵌入和双向语言模型嵌入。
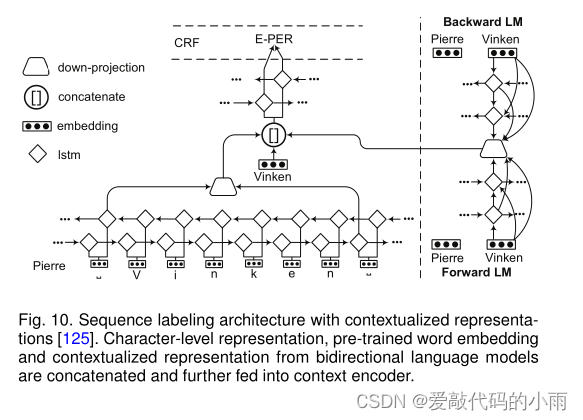
图10显示了LM-LSTM-CRF模型的体系结构[125],[126]。语言模型和序列标记模型共用一个字符层,实现多任务学习。来自字符级嵌入、预训练的单词嵌入和语言模型表示的向量被连接并输入到单词级lstm中。实验结果表明,多任务学习是指导语言模型学习任务特定知识的有效方法。

图4显示了Akbik等人[107]使用神经字符级语言建模的上下文字符串嵌入。他们利用前后循环神经网络的隐藏状态来创建上下文化的单词嵌入。该模型的一个主要优点是字符级语言模型独立于标记化和固定词汇表。Peters等人[103]提出了ELMo表示,它是在具有字符卷积的两层双向语言模型之上计算的。这种新型的深度上下文化单词表示既能够建模单词使用的复杂特征(例如语义和语法),也能够建模跨语言上下文的用法变化(例如多义词)。
3.5 Deep Transformer
神经序列标记模型通常基于复杂的卷积或循环网络,其中包括编码器和解码器。由Vaswani等人[128]提出的Transformer完全不需要递归和卷积。Transformer利用堆叠的自注意和点向,完全连接的层来构建编码器和解码器的基本块。对各种任务的实验[128]-[130]表明,Transformer的质量优越,而需要的训练时间明显更少。
基于transformer, Radford等人[131]提出了用于语言理解任务的生成式预训练transformer (GPT)。GPT有一个两阶段的培训过程。
首先,他们在未标记的数据上使用带有transformer的语言建模目标来学习初始参数。
然后,他们将这些参数调整到使用监督目标的目标任务,从而使预先训练的模型发生最小的变化。与GPT(从左到右的体系结构)不同,来自Transformer的双向编码器表示(BERT)被提议通过在所有层中联合调节左右上下文来预训练deep idirectional Transformer[119]。
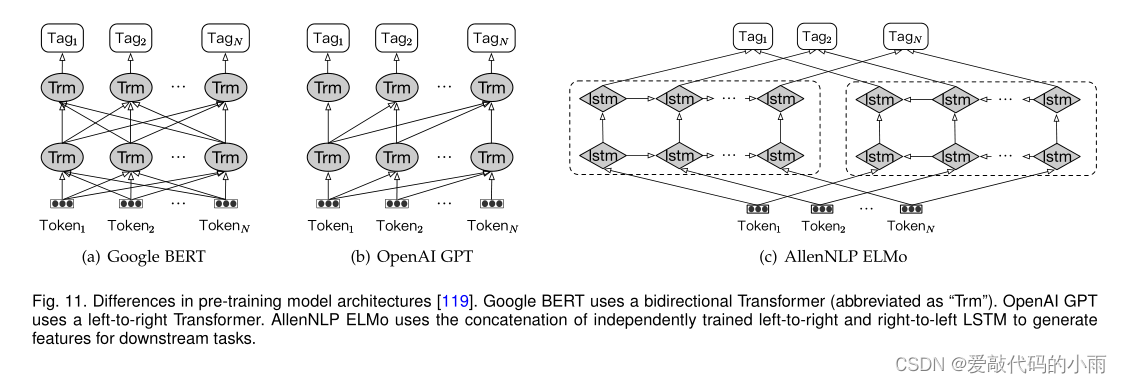
图11总结了BERT[119]、GPT[131]和ELMo[103]。此外,Baevski等人[132]提出了一种基于双向Transformer的新型完形词驱动预训练机制,该机制使用完形语目标进行训练,并在所有左右上下文条件下预测中心词。
这些使用Transformer预先训练的语言模型嵌入正在成为NER的一种新范式。首先,这些嵌入是上下文化的,可以用来取代传统的嵌入,如谷歌Word2vec和Stanford GloV e。一些研究[108],[110],[133]-[136]通过利用传统嵌入和语言模型嵌入的结合取得了良好的性能。其次,可以通过一个额外的输出层对这些语言模型嵌入进行进一步的微调,以实现包括NER和分块在内的广泛任务。
特别是Li等人[137][138]将NER任务框定为机器阅读理解(MRC)问题,可以通过微调BERT模型来解决。
4.Tag Decoder Architectures
标签解码器是NER模型的最后一个阶段。它接受与上下文相关的表示作为输入,并生成与输入序列对应的标记序列。
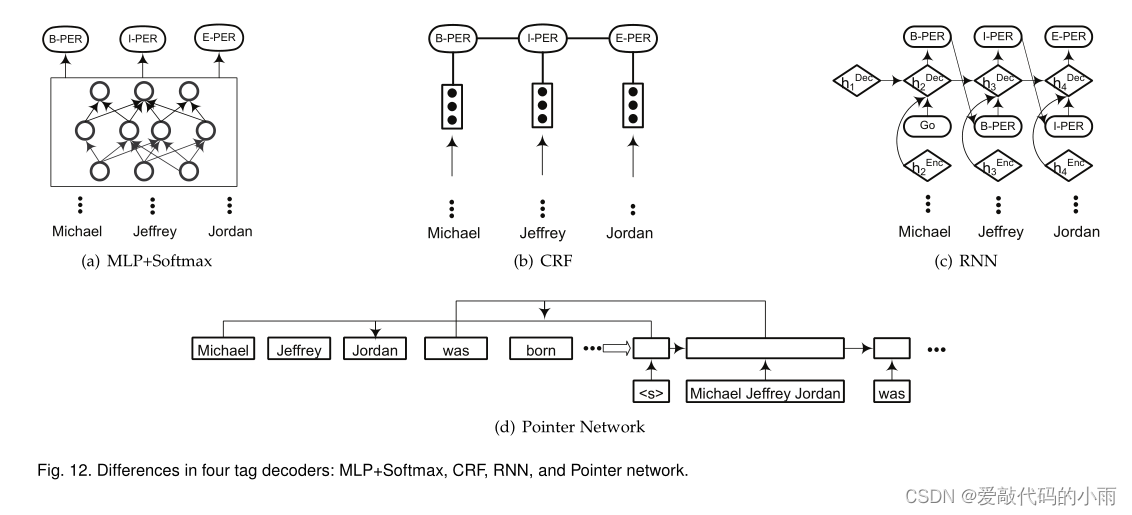
图12总结了标签解码器的四种架构:MLP + softmax层、条件随机场(CRFs)、循环神经网络和指针网络。
4.1 Multi-Layer Perceptron + Softmax
NER通常被表述为一个序列标记问题。采用Multi-Layer Perceptron + Softmax层作为标记解码器层,将序列标记任务转换为一个多类分类问题。每个单词的标签都是基于上下文相关的表示独立预测的,而不考虑它的邻居。
4.2 Conditional Random Fields
条件随机场(CRF)是一个以观测序列为全局条件的随机场[73]。crf在基于特征的监督学习方法中被广泛使用(见第2.4.3节)。许多基于深度学习的NER模型使用CRF层作为标记解码器,例如,在双向LSTM层[18],[90],[103],[141]之上,在CNN层[17],[91],[94]之上。
然而,crf不能充分利用段级信息,因为段的内部属性不能用词级表示完全编码。Zhuo等人[142]提出了gated recursive semi-markovCRFs,直接对片段而不是单词建模,并通过门控递归卷积神经网络自动提取段级特征。最近,Ye和Ling[143]提出了用于神经序列标记的hybrid semi-Markov CRFs。该方法采用分段代替词作为特征提取和转换建模的基本单元。推导段分数中使用了单词级标签,因此,这种方法能够利用词级和段级信息进行段分计算。
4.3 Recurrent Neural Networks
RNN标签解码器的性能优于CRF,并且在实体类型数量较大时训练速度更快。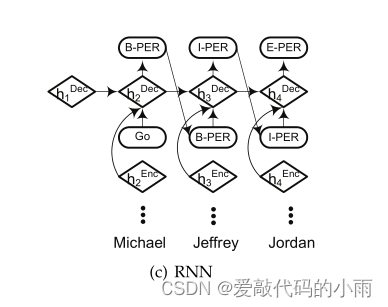
©展示了基于rnn的标记解码器的工作流程,它作为一种语言模型,贪婪地产生标记序列。第一步的[GO]-符号作为y1提供给RNN解码器。随后,在每一个时间步骤i, RNN解码器根据前一步标记yi、前一步解码器隐藏状态hDeci和当前步进编码器隐藏状态hEnci+1计算当前解码器隐藏状态hDeci+1;使用softmax损失函数对当前输出标记yi+1进行解码,并进一步作为下一个时间步的输入。最后,我们获得了所有时间步骤上的标记序列。
4.4 Pointer Networks
指针网络应用rnn来学习输出序列的条件概率,输出序列的元素是与输入序列中的位置相对应的离散令牌[145],[146]。它通过使用软最大概率分布作为“指针”来表示可变长度的字典。
5. Summary of DL-based NER
5.1体系结构概述
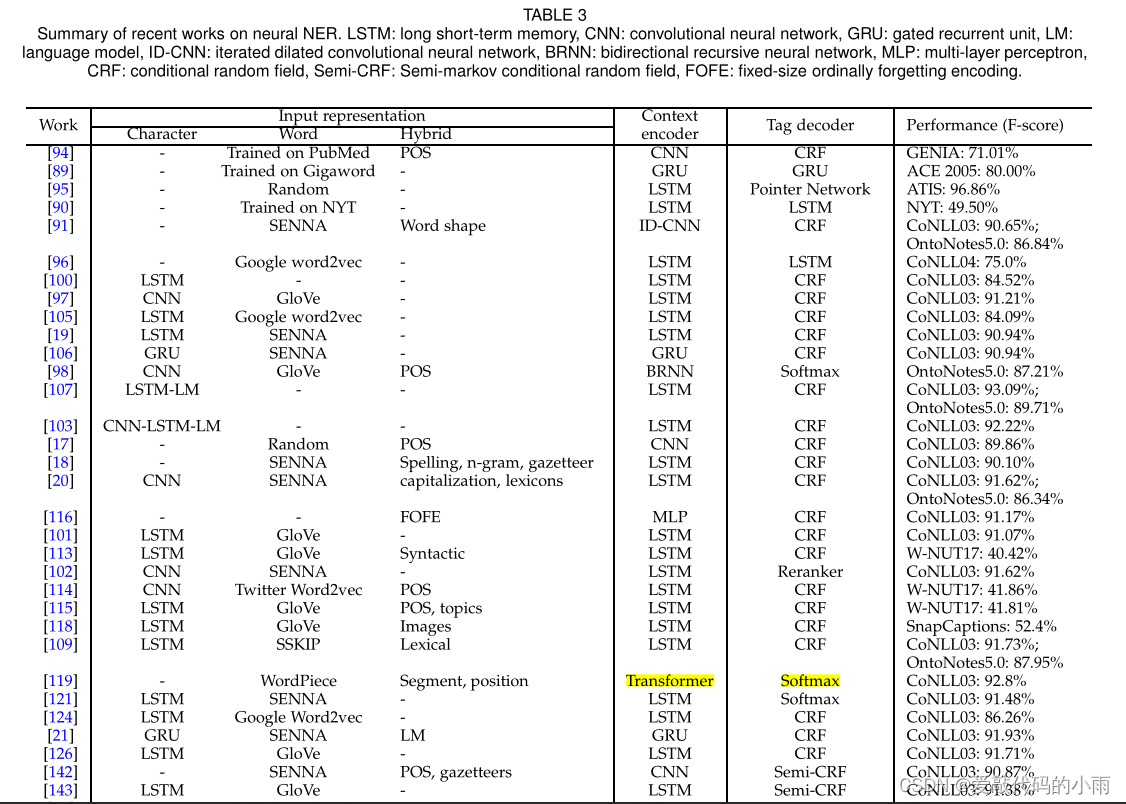

表3根据体系结构选择总结了神经NER的最新研究成果。BiLSTM-CRF 是使用深度学习的NER最常见的体系结构。
5.2体系结构的比较
首先,对于外部知识是否应该或如何集成到基于dl的NER模型中,还没有达成共识。然而,缺点也很明显:1)获取外部知识是劳动密集型的(例如,地名辞典)或计算成本高(例如,依赖性);2)集成外部知识对端到端学习产生不利影响,损害了基于dl的系统的通用性。
其次,当Transformer在大量语料库上进行预训练时,Transformer编码器比LSTM更有效。
如果没有预先训练且训练数据有限,变压器在NER任务中会失败[147],[148]。另一方面,当序列n的长度小于表示的维数d(复杂度:自注意O(n2·d)和循环O(n·d2))[128]时,Transformer编码器比递归层更快。第三,RNN和指针网络解码器的一个主要缺点是贪婪的解码,这意味着当前步的输入需要前一步的输出。这种机制可能会对速度产生重大影响,并且是并行化的障碍。CRF是标签解码器最常用的选择。当采用非语言模型(即非上下文化的)嵌入时,如Word2vec和GloVe, CRF在捕获标签转换依赖性方面非常强大。然而,当实体类型的数量很大时,CRF的计算成本可能很高。
更重要的是,与softmax分类相比,CRF并不总是能带来更好的性能。采用情境化的语言模型嵌入,如BERT和ELMo[137],[139]。
对于最终用户,选择什么体系结构取决于数据和域任务。如果数据丰富,可以考虑从头开始使用rnn训练模型和微调上下文化语言模型。如果数据稀缺,采用转移策略可能是更好的选择。对于新闻专线领域,有许多预先训练过的现成模型可用。对于特定领域(例如,医疗和社交媒体),使用特定领域的数据对通用上下文化语言模型进行微调通常是一种有效的方法。
5.3 NER for Different Languages
除了英语,还有许多关于其他语言或跨语言环境的研究。Zhang和Yang[150]为中文NER提出了一种网格结构LSTM模型,该模型对输入字符序列以及与词典匹配的所有潜在单词进行编码。对于理解该语言的NER任务的基本原理,每种语言都有自己的特点。也有一些研究[106],[158]-[160]旨在解决跨语言环境下的NER问题,方法是将知识从源语言转移到目标语言,很少或没有标签。
Applied Deep Learning For NER
在本节中,我们将概述近期应用于NER的深度学习技术。
1. Deep Multi-task Learning for NER(面向NER的深度多任务学习)
多任务学习[161]是一种学习一组相关任务的方法。通过考虑不同任务之间的关系,多任务学习算法有望比单个学习每个任务的算法取得更好的效果。
Collobert等[17]训练了窗口/句子方法网络来联合执行POS、Chunk、NER和SRL任务。这种多任务机制允许训练算法发现对所有感兴趣的任务都有用的内部表示。Yang等人[106]提出了一种多任务联合模型,用于学习语言特定的规律,联合训练POS、Chunk和NER任务。Rei[124]发现,通过在训练过程中包含无监督语言建模目标,序列标记模型实现了一致的性能改进。Lin等人[160]提出了一种针对低资源环境的多语言多任务体系结构,该体系结构可以有效地转移不同类型的知识来改进主模型。
除了将NER与其他序列标记任务一起考虑外,多任务学习框架还可以应用于实体和关系的联合提取[90],[96],或将NER建模为两个相关的子任务:实体分割和实体类别预测 [114],[162]。在生物医学领域,由于不同数据集的差异,每个数据集上的NER被认为是多任务设置中的一个任务[163],[164]。这里的一个主要假设是,不同的数据集共享相同的字符和单词级信息。然后应用多任务学习来更有效地利用数据,并鼓励模型学习更广义的表示。
2. Deep Transfer Learning for NER(面向NER的深度迁移学习)
迁移学习旨在利用从源领域学习到的知识,在目标领域执行机器学习任务[165]。在自然语言处理中,迁移学习也被称为领域适应。
3. Deep Active Learning for NER(面向NER的深度主动学习)
主动学习背后的关键思想是,如果允许机器学习算法选择从中学习的数据,那么它可以在训练数据少得多的情况下表现得更好[181]。深度学习通常需要大量的训练数据,而获取这些数据的成本很高。因此,将深度学习与主动学习相结合有望减少数据注释的工作量。
4.Deep Reinforcement Learning for NER(面向NER的深度强化学习)
其理念是,智能体将通过与环境的互动向环境学习,并通过执行动作获得奖励。具体来说,RL问题可以表述如下[186]:将环境建模为一个随机有限状态机,它具有输入(来自agent的动作)和输出(对agent的观察和奖励)。它包含三个关键部分:(i)状态转移函数,(ii)观察(即输出)函数,(iii)奖励函数。
代理也被建模为具有输入(来自环境的观察/奖励)和输出(对环境的行动)的随机有限状态机。它由两个部分组成:(i)状态转换函数和(ii)策略/输出函数。代理的最终目标是通过尝试最大化累积奖励来学习良好的状态更新函数和策略。
5. Deep Adversarial Learning for NER(NER的深度对抗学习)
对抗性学习[190]是针对对抗性例子显式训练模型的过程。其目的是使模型对攻击更具鲁棒性,或减少在干净输入时的测试误差。对抗网络通过二人博弈从训练分布中学习生成:一个网络生成候选人(生成网络),另一个评估候选人(辨别网络)。通常,生成网络学会从潜在空间映射到感兴趣的特定数据分布,而鉴别网络则区分生成器生成的候选数据和来自真实数据分布的实例。
6. Neural Attention for NER(神经内神经注意)
注意机制松散地建立在人类的视觉注意机制上[196]。例如,人们通常以“高分辨率”关注图像的某一区域,而以“低分辨率”感知周围区域。神经注意机制使神经网络能够专注于输入的子集。利用注意机制,NER模型可以捕获输入中信息量最大的元素。
特别是,前面介绍的Transformer体系结构完全依赖于注意机制来绘制输入和输出之间的全局依赖关系。
自适应共注意网络是一个利用共注意过程的多模态模型。共同注意包括视觉注意和语篇注意,以捕捉不同形态间的语义交互作用。
Challenges and Conclusion
Challenges
- NER通常被认为是下游应用程序的预处理组件。这意味着特定的NER任务是由下游应用程序的需求定义的。
- 细粒度NER和边界检测。据我们所知,没有任何现有的工作单独专注于实体边界检测以提供健壮的识别器。我们期待未来这一研究方向会有突破。
- 联合NER和实体链接。关联的实体有助于成功检测实体边界和正确分类实体类型。值得探索联合执行NER和EL,甚至实体边界检测、实体类型分类和实体链接的方法,以使每个子任务受益于其他子任务的部分输出,并减少管道设置中不可避免的错误传播。
- 基于dl的具有辅助资源的非正式文本的NER。问题是如何在用户生成的内容或特定于域的文本上为NER任务获取匹配的辅助资源,以及如何在基于dl的NER中有效地合并辅助资源。
- 基于dl的NER的可伸缩性。使神经NER模型更具可扩展性仍然是一个挑战。此外,当数据规模增长时,参数指数增长的优化仍然需要解决方案。然而,如果终端用户无法访问强大的计算资源,则无法对这些模型进行微调。开发平衡模型复杂性和可伸缩性的方法将是一个有前途的方向。另一方面,模型压缩和修剪技术也可以减少模型学习所需的空间和计算时间。
- NER的深度迁移学习。许多以实体为中心的应用程序求助于现成的NER系统来识别命名实体。然而,由于语言特征的差异以及注释的差异,在一个数据集上训练的模型在其他文本上可能不能很好地工作。未来应进一步研究如何有效地将知识从一个领域转移到另一个领域,探索以下研究问题:(a)开发一种能够在不同领域良好工作的鲁棒识别器;(b)在NER任务中探索零次、一次和少次学习;©提供解决跨域设置中的域不匹配和标签不匹配的方案。
- 一个易于使用的Tooolkit用于基于dl的NER。我们设想一个易于使用的NER工具包可以指导开发人员使用一些标准化的模块来完成它:数据处理、输入表示、上下文编码器、标记解码器和有效性度量。
Conclusion
本调查旨在回顾近期关于基于深度学习的NER解决方案的研究,以帮助新的研究人员建立对该领域的全面理解。在本调查中,包括了NER研究的背景、传统方法的简要介绍、当前的技术状况、挑战和未来的研究方向。首先,整合了现有的NER资源,包括有标记的NER语料库和现成的NER系统,重点关注通用领域的NER和英语的NER。以表格形式展示这些资源,并提供链接以方便访问。其次,从NER任务的定义、评价指标、传统的NER方法、深度学习的基本概念等方面进行了初步介绍。第三,回顾了基于不同深度学习模型的文献,并根据一种新的分类法绘制了这些研究。进一步调查了最近在新问题设置和应用中应用深度学习技术的最具代表性的方法。最后,总结了NER的应用,并向读者提出了NER的挑战和未来的发展方向。希望本研究可以为设计基于dl的NER模型提供良好的参考。














 3706
3706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









