






一、摘要
由于内存限制,修复只能处理低分辨率输入,通常小于1K。而移动设备拍摄的照片分辨率提高到8K。对低分辨率的上采样结果只会产生一个大而模糊的结果。然而,在大的模糊图像上添加高频残差图像可以产生清晰的结果,丰富的细节和纹理。基于此,本文提出了一种上下文残差聚合(CRA)机制,该机制可以通过加权聚合上下文补丁的残差来产生缺失内容的高频残差,从而只需要来自网络的低分辨率预测。由于神经网络的卷积层只需要在低分辨率输入和输出,内存成本和计算能力都得到了很好的抑制。此外,还减少了对高分辨率训练数据集的需求。本文在分辨率为512×512的小图像上训练所提出的模型,并在高分辨率图像上进行推理,获得了令人信服的修复质量。我们的模型可以绘制大至8K的图像,并且具有相当大缺失区域,这对于以前基于学习的方法来说是难以解决的。
二、介绍
本文提出了一种新的上下文残差聚合(CRA)机制,以便在有限的资源下完成超高分辨率图像。具体而言,使用神经网络来预测低分辨率的修复结果,并对其进行上采样以产生大的模糊图像。然后,通过对上下文补丁的加权高频残差进行聚合,得到孔内补丁的高频残差。最后,我们将聚合残差添加到大的模糊图像中,以获得清晰的结果。此外,我们还引入了其他技术,包括薄层和深层配置,注意力分数共享,多尺度注意力转移和轻量级门控卷积(LWGC),以提高绘制质量,计算和速度。
贡献
①设计了一种新颖高效的上下文残差聚合(CRA)机制,实现了超高分辨率的修复。该机制允许在有限的内存和计算资源下修复损失较大的区域,这对于以前的方法来说是难以解决的。此外,该模型可以在小图像上进行训练,也可以应用于大图像上,大大减轻了对高分辨率训练数据集的要求。
②我们设计了一个轻量级的不规则孔洞填充模型,可以对2K分辨率的图像进行实时推断,使用的技术包括薄层和深层配置,注意力分数共享和轻量级门控卷积(LWGC)。
③在多个抽象级别上使用注意力转移,这可以通过在多个尺度上从上下文加权复制特征来填充孔洞,从而提高修复质量,即使在低分辨率图像上进行测试,修复质量也优于现有方法。
三、相关的工作
卷积
对于不规则的孔洞填充,香草卷积本质上是麻烦的,因为卷积过滤器将所有像素视为有效像素,导致视觉伪影,如颜色不一致、模糊和边界伪影。部分卷积可以处理不规则孔洞,其中卷积被掩码并重新归一化仅以有效像素为条件。门控卷积通过为每个通道和每个空间位置提供可学习的动态特征选择机制,推广了部分卷积思想,实现了更好的视觉性能。本文通过轻量级设计进一步改进门控卷积以提高效率。
上下文注意力
上下文注意被提出用于在修复过程中允许远程空间依赖,从而可以从遥远的位置借用像素来填充缺失的区域。上下文注意力层有两个阶段:“匹配”和“参与”。在匹配阶段,通过获得孔洞内外补丁之间的区域亲和力来计算注意力分数。在“参与”阶段,通过复制和聚合由注意力分数加权的上下文的补丁来修复漏洞。本文只计算一次注意力分数,并在多个抽象级别重用它们,这导致参数更少,计算量更少。
图像残差
图像与其自身的模糊版本之间的差异代表了图像的高频部分。模糊版本通常通过对图像进行高斯模糊得到。
用于频率分解: 早期的研究采用了通过高斯模糊得到的差异来进行低级图像处理任务,比如边缘检测、图像质量评估和特征提取。本文采用了类似的思想,将输入图像分解为低频和高频两个部分。
低频分量:通过对相邻像素进行平均来获得低频分量。
高频分量:通过用原始图像减去其低频分量来获得高频分量,也即图像残差。
通过这种方式,输入图像被分解为两个部分:一个是平滑的低频成分,另一个是原始图像与低频成分的差异,即高频成分。这种分解有助于更有效地处理图像的不同频率信息,对于一些任务如边缘检测等可能提供有益的信息。
窗体底端
四、方法
步骤
给定一个高分辨率的输入图像,我们首先将图像向下采样到512 × 512,然后再上采样以获得与原始输入相同大小的模糊图像。图像的高度和宽度不必相等,但必须是512的倍数。生成器获取低分辨率图像并修复孔洞。同时,通过生成器的注意力计算模块(ACM)计算注意力得分。通过从原始输入中减去大的模糊图像来计算上下文残差,然后通过注意转移模块(ATM)从上下文残差和注意分数中计算掩码区域中的聚合残差。最后,将聚合残差添加到上采样的修复结果中,在掩码区域产生一个大而精确的输出,而掩码外的区域只是原始输入的副本。
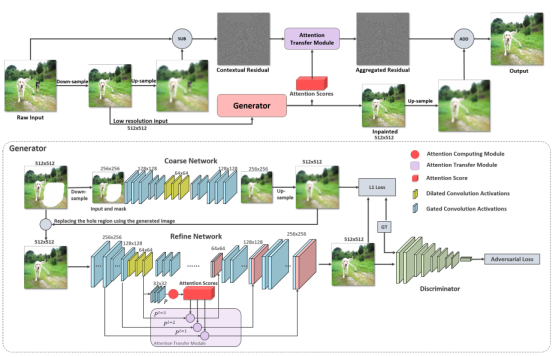
上下文残差聚合(CRA)
通过使用上下文信息和上下文注意力机制来修复缺失的区域。本文使用CRA机制来从上下文区域借用信息。CRA机制不仅借鉴了特征,还借鉴了残差。特别是,本文采用了上下文注意力的思想,通过获得缺失区域内外补丁之间的区域亲和力来计算注意分数。因此,与上下文相关的特征和外部残差可以转移到孔洞中。这个机制包括两个关键模块:注意力计算模块和注意力转移模块。
注意力计算模块
注意力分数是基于高级特征映射的区域亲和力计算的。称高级特征映射为P,P被划分为几个补丁。计算缺失区域内外补丁之间的余弦相似度为:

对相似度分数应用Softmax函数,得到每个补丁的注意力分数
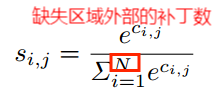
Softmax是一种常见的分类函数,它将一个n维向量输入,将其标准化为一个n维概率分布,其中每个像素的值都介于0和1之间,并且所有的元素和为1。Softmax函数通过将n维向量z的每个元素除以所有元素的和来计算归一化的概率分布。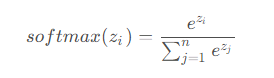
注意力转移模块
用注意力分数加权的上下文补丁填充底层特征映射(Pl)中的孔洞。

计算完所有孔洞内补丁后,最终得到一个填充特征。由于特征图的大小随层的不同而不同,因此补丁的大小也应相应变化。
补丁尺寸的计算
假设特征图的大小为128 * 128,注意力分数需要从32 * 32个补丁中计算得到,则每个补丁的尺寸大小为:128/32 = 4,则补丁尺寸为4 * 4。因此所有的补丁都会被覆盖。如果补丁的尺寸大于4*4,那么某些像素是重叠的,这很好,因为网络的后续层可以学习适应。
多尺度注意力转移与分数共享
本文框架使用同一组注意力分数多次应用注意力转移。注意力分数的共享导致参数更少,在内存和速度方面效率更高。
残差聚合
残差聚合的目标是计算缺失区域的残差,从而恢复缺失内容的清晰细节。缺失内容的残差可以通过将前面步骤中得到的加权上下文残差进行集合来计算:
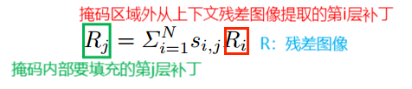
选择适当的补丁大小以准确覆盖所有像素而不重叠,以确保填充残差与周围区域一致。一旦得到聚合残差图像,我们将其加入到生成器的上采样模糊图像中,得到一个清晰的结果。
生成器的框架
使用了一个两阶段的从粗到细的网络架构,其中粗网络产生粗略的缺失内容,而精网络预测更精细的结果。真实图像和缺失区域的二进制掩码作为输入,并预测完成的图像。预计输入和输出大小为512 × 512。为了扩大感知范围和减少计算量,粗网络在卷积前将输入下采样到256×256,而精网络在512×512上进行操作。粗网络的预测结果与输入图像进行混合,作为精网络的输入。精网络使用一个高级特征映射计算上下文注意力分数,并在多个低级特征映射上执行注意力转移,从而可以在多个抽象层上借用远程上下文信息。我们还在粗网络和精网络中采用了孔洞卷积,以进一步扩大感受野的大小。为了提高计算效率,我们的修复网络采用了细而深的设计方式,并将LWGC(轻量级门控卷积)应用于生成器的所有层。
轻量级门控卷积(LWGC)
门控卷积利用了不规则孔洞的修复艺术。但是与普通卷积相比,几乎增加了一倍的参数数量和处理时间。门控卷积的表达式为:

提出LWGC三个变体:深度可分离LWGC——![]() 、像素级LWGC——
、像素级LWGC——![]() 、单通道LWGC——
、单通道LWGC——![]()
它们的不同区别在于门控分支的计算。深度可分离LWGC采用深度卷积,然后是1 × 1卷积来计算门控。像素级LWGC使用像素级或1 × 1卷积来计算门。单通道LWGC输出一个单通道掩码,该掩码在乘法期间广播到所有特征通道。单通道掩码类似于部分卷积,但是部分卷积的掩码是硬连接的且不可训练的,而且生成二进制掩码而不是软掩码。对粗网络的所有层使用单通道LWGC,对精网络的所有层使用深度可分离或像素级LWGC。
损失函数:重建损失+对抗损失
使用WGAN-GP损失作为对抗损失

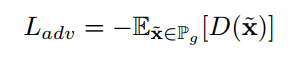
重建损失:为所有孔洞内像素的重建损失分配一个较小的常数权重

粗网络是明确地用重建损失来训练的,而精网络是用重建和GAN损失的加权和来训练的。粗网络和精网络同时训练,并合并损失。
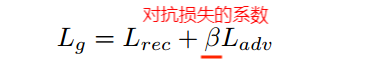















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









