







DML语言
Data Manipulation Language 数据操作语言
插入语句、修改语句、删除语句
insert、update、delete
1、表插入数据
1.1、方式一
语法:
INSERT INTO 表名 (列名1,...)
VALUES
(值1,...) ;
注意:
- 插入的值的类型要与列的类型一致或兼容(字符型和日期型的数据都要用单引号)
- 不可以为 NULL 的列必须插入值(表的
Nullable指的是该列数据可以为NULL) - 可以为NULL的列,可以用插入NULL,或者不插入该列数据
- 列的顺序可以调换,但要与列名对应
- 注意,列名的个数必须与值的个数保持一致,不能有列名,没有插入的值
- 可以省略列名,那么默认就是所有列,且顺序是表的列的顺序
- 方式一的插入语句支持插入多行
- 方式一的插入语句支持子查询语句,执行的结果就是将查询语句的结果集插入到表中
案例1:
给女神表插入一行数据
字符型和日期型的数据都要用单引号
表的 Nullable 指的是该列数据可以为 NULL
#给女神表插入一行数据
INSERT INTO `beauty` (
`id`,
`name`,
`sex`,
`borndate`,
`phone`,
`photo`,
`boyfriend_id`
)
VALUES
(
13,
'唐艺昕',
'女',
'1990-4-23',
'12312312333',
NULL,
3
) ;
案例2:
插入多行
INSERT INTO `beauty`
VALUES
(23,'唐艺昕','女','1990-4-23','12312312333',NULL,3
),
(24,'唐艺昕1','女','1990-4-23','12312312331',NULL,3
),
(25,'唐艺昕2','女','1990-4-23','12312312332',NULL,3
) ;
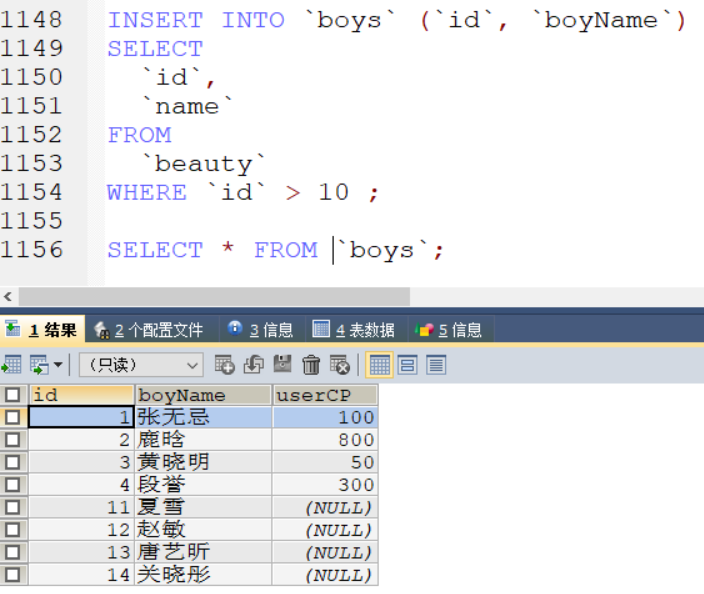
案例3:
支持子查询语句
INSERT INTO `boys` (`id`, `boyName`)
SELECT
`id`,
`name`
FROM
`beauty`
WHERE `id` > 10 ;
执行结果如下
1.2、方式二
语法:
INSERT INTO 表名
SET
列名1=值1,
列名2=值2,
... ;
案例:
给女神表插入一行数据
如果创建表的时候有设置默认值,那么没插入数据的列就显示默认值
#给女神表插入一行数据
INSERT INTO `beauty` SET `id` = 14,
`name` = '关晓彤',
`phone` = '45645645645' ;
2、修改表数据
2.1、修改单表的记录
语法:
UPDATE
表名
SET
列名1 = 值1,
列名2 = 值2,
...
WHERE 筛选条件 ;
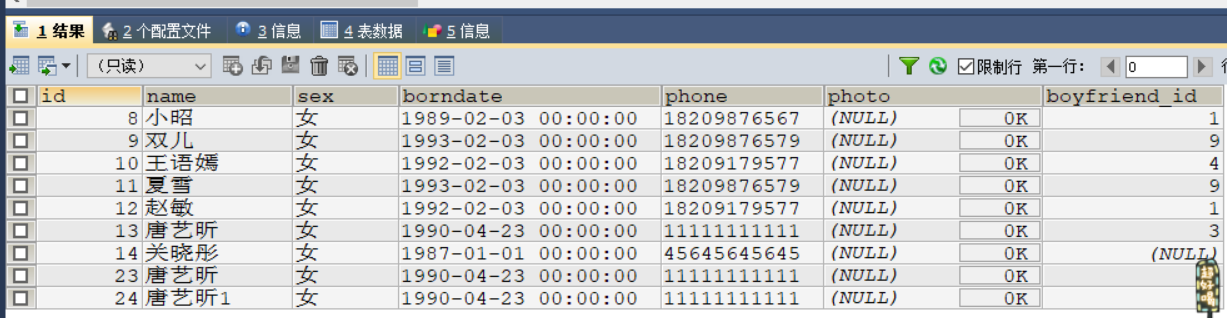
案例:
修改女神表中姓唐的女神电话改为 11111111111
#修改女神表中姓唐的女神电话
UPDATE
`beauty`
SET
`phone` = '11111111111'
WHERE `name` LIKE '唐%' ;
2.2、修改多表连接的记录
语法: 注意分 sql92 和 sql99 的情况
# sql92
UPDATE
表1 别名,表2 别名
SET
列名1 = 值1,
列名2 = 值2,
...
WHERE 连接条件
AND 筛选条件 ;
# sql99
UPDATE
表1 别名
INNER|LEFT|RIGHT JOIN 表2 别名
ON 连接条件 SET 列名1 = 值1,
列名2 = 值2,
...
WHERE 筛选条件 ;
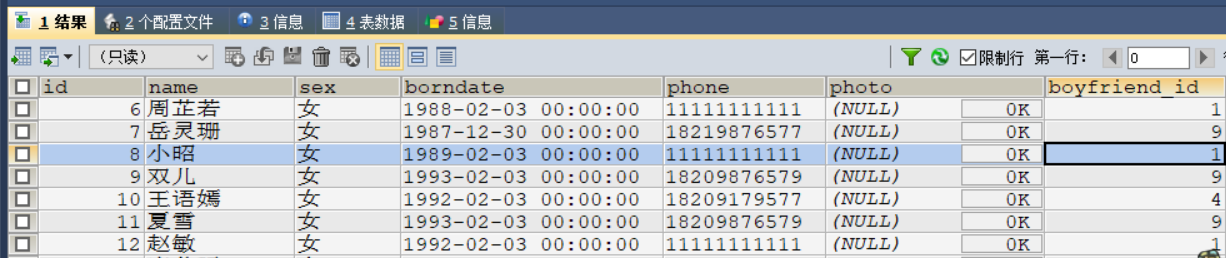
案例1:
修改张无忌的女神的手机号 为11111111111
#修改张无忌的女神的手机号
UPDATE
`boys` bo
LEFT JOIN `beauty` b
ON bo.`id` = b.`boyfriend_id` SET b.`phone` = '11111111111'
WHERE bo.`boyName` = '张无忌' ;
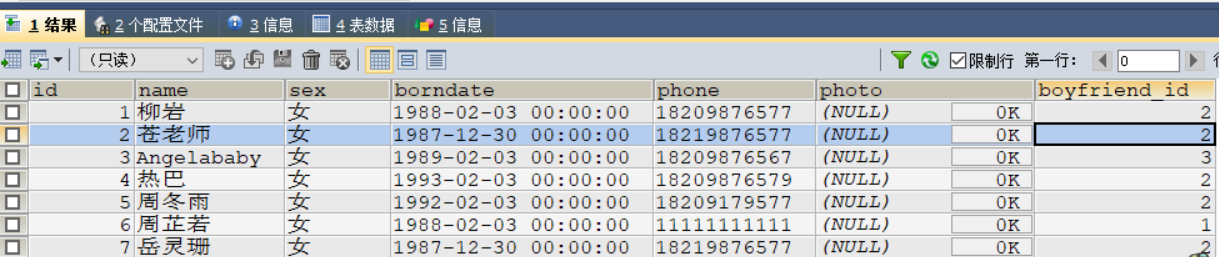
案例2:
修改没有男友的女神的男友编号改为2
#修改没有男友的女神的男友编号
USE `girls`;
UPDATE
`beauty` b
LEFT JOIN `boys` bo
ON bo.`id` = b.`boyfriend_id` SET b.`boyfriend_id` = 2
WHERE bo.`id` IS NULL ;
3、删除表内数据
3.1、方式一 delete
3.1.1、单表内的删除
语法: 注意若没有删除加筛选条件,那就是整个表的信息
DELETE
FROM
表名
WHERE 筛选条件 ;
案例:
删除女神表里面姓唐的女神信息
#删除女神表里面姓唐的女神信息
DELETE
FROM
`beauty`
WHERE `name` LIKE '唐%' ;
3.1.2、多表连接的删除
注意DELETE后写了两个表的别名,就会删除两个表里所有符合筛选条件的数据
语法: 注意分 sql92 和 sql99 的情况
# sql92
DELETE
表1的别名,表2的别名
FROM
表1 别名,表2 别名
WHERE 连接条件
AND 筛选条件 ;
# sql99
DELETE
表1的别名,表2的别名 #注意这里写了两个表,就删除了两个表里符合条件的数据
FROM
表1 别名
INNER|LEFT|RIGHT JOIN 表2 别名
ON 连接条件
WHERE 筛选条件 ;
案例1: ★★★★
删除张无忌的女朋友的信息
#删除张无忌的女朋友的信息
DELETE
b,
FROM
`beauty` b
INNER JOIN `boys` bo
ON b.`boyfriend_id` = bo.`id`
WHERE bo.`boyName` = '张无忌' ;
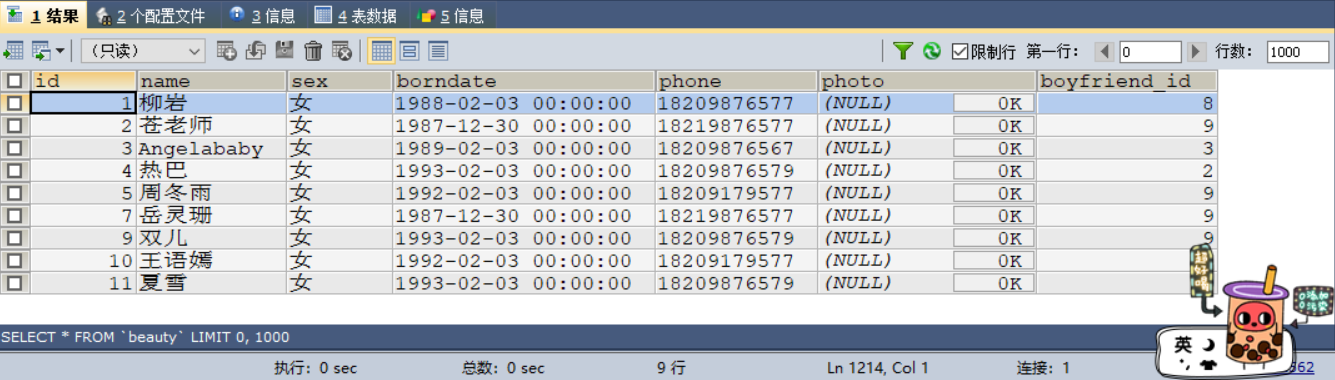
案例2: ★★★★
删除黄晓明的信息以及他的女朋友的信息
这里与上一个案例的区别仅仅在于DELETE后写了两个表的别名
#删除黄晓明的信息以及他的女朋友的信息
DELETE
b,
bo
FROM
`beauty` b
INNER JOIN `boys` bo
ON b.`boyfriend_id` = bo.`id`
WHERE bo.`boyName` = '黄晓明' ;
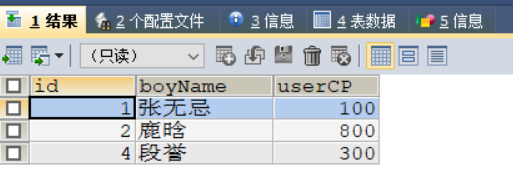
3.2、方式二 truncate
语法: 删除整个表的信息,不可以加筛选条件
TRUNCATE
TABLE
表名 ;
注意:
- 假如要删除的表中有自增长列(比如男神表的 ID )
用DELETE删除之后再插入数据,自增长列的值从断点开始
用TRUNCATE删除后再插入数据,自增长列的值从 1 开始 TRUNCATE删除不会显示有几行受影响,即没有返回值TRUNCATE删除不能回滚,DELETE删除可以回滚
以下展示何为断点
原来的数据:
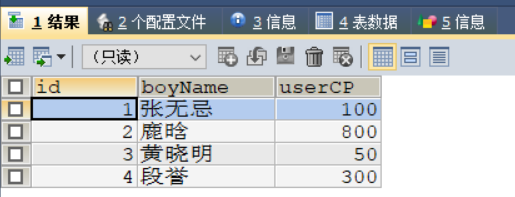
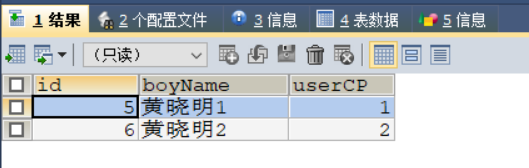
执行以下代码之后:
SELECT * FROM `boys`;
DELETE FROM `boys`;
INSERT INTO `boys` (`boyName`, `userCP`)
VALUES
('黄晓明1', 1),
('黄晓明2', 2) ;
DDL语言
Data Define Language 数据定义语言
库和表的管理、常见数据类型介绍、常见约束
create、alter、drop
1、库的管理
- 库的创建
- 重复创建库会报错,所以可以和
EXISTS搭配使用
CREATE DATABASE IF NOT EXISTS 库名 ; - 数据存储在C:\ProgramData\MySQL\MySQL Server 5.5\data
- 重复创建库会报错,所以可以和
- 库的修改
- 库一般不修改,容易导致数据丢失,若要修改库名,直接修改库的文件夹
- 可以修改库的字符集
ALTER DATABASE 库名 CHARACTER SET gbk ;
- 库的删除
- 重复删除库会报错,所以可以和 EXISTS 搭配使用
DROP DATABASE IF EXISTS 库名 ;
- 重复删除库会报错,所以可以和 EXISTS 搭配使用
2、表的管理
2.1、表的创建
语法: 重复创建会报错,所以可以和 EXISTS 搭配使用😂
CREATE TABLE IF NOT EXISTS 表名(
列名 类型【(长度) 约束】,
列名 类型【(长度) 约束】,
...
列名 类型【(长度) 约束】
);
查看表的结构😒
DESC 表名
查看当前库所有表😍
SHOW TABLE;
#创建库
CREATE DATABASE books;
#创建表
CREATE TABLE book (
id INT,
bookname VARCHAR (20),
author_id INT,
test INT
) ;
DESC `book`;
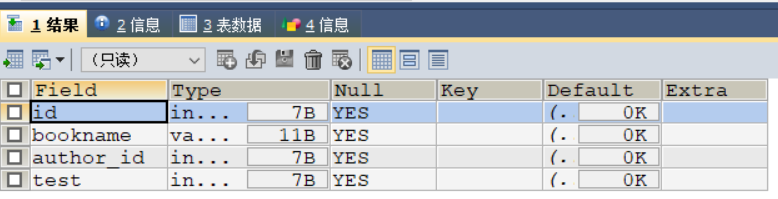
2.2、表结构的修改
语法:
ALTER TABLE 表名 ADD|DROP|MODIFY|CHANGE COLUMN 列名 【列的类型 约束】;
- 修改列名
ALTER TABLE 表名 CHANGE 【COLUMN】 旧列名 新列名 列的类型 ;
案例:
#修改列名
ALTER TABLE book
CHANGE COLUMN `test` `test_1` INT ;
- 修改列的类型或约束
ALTER TABLE 表名 MODIFY 【COLUMN】 列名 新的列类型;
案例:
#修改列的类型
ALTER TABLE book
MODIFY `test_1` VARCHAR (5) ;
- 添加列
ALTER TABLE 表名 ADD 【COLUMN】 列名 列的类型 ;
案例:
#添加列
ALTER TABLE book
ADD test_2 INT ;
- 删除列
ALTER TABLE 表名 DROP 【COLUMN】 IF EXISTS 列名 ;
案例:
#删除列
ALTER TABLE book DROP test_2 ;
- 修改表名
ALTER TABLE 旧表名 RENAME TO 新表名 ;
案例:
#修改表名
ALTER TABLE book
RENAME TO book_1 ;
2.3、表的删除
重复删除表会报错,所以可以和 EXISTS 搭配使用🤞
DROP TABLE IF EXISTS 表名;
2.4、表结构+数据的复制
仅仅复制表的结构
#复制表的结构
CREATE TABLE copy_1 LIKE `book`;
复制表的结构+数据
(加上查询语句,可以选择哪些列)
#复制表的结构+数据
CREATE TABLE copy_2 SELECT * FROM `book`;
复制表的部分列,带数据的
(加上筛选条件,可以筛选数据)
#复制表的部分列,带数据的
CREATE TABLE copy_3
SELECT
`id` , `bookname`
FROM
`book`
WHERE `id` > 3 ;
仅仅复制表的部分列,但是没有数据
(筛选条件是无法成立的,就是没有数据)😜
#仅仅复制表的部分列,但是没有数据
CREATE TABLE copy_4
SELECT
`id` , `bookname`
FROM
`book`
WHERE `1=2;
3、数据类型介绍
3.1、整型
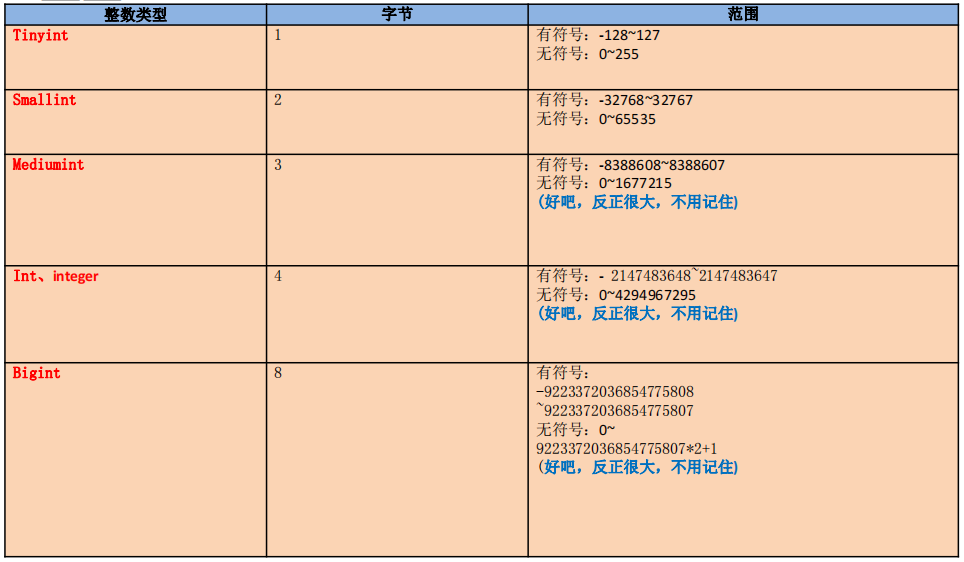
特点:
- 如果不设置有符号还是无符号,默认是有符号
- 设置无符号,需要在创建表时在类型后添加
UNSIGNED - 如果插入的数据超出了类型范围,会报错,【有可能会插入临界值】
- 如果不设置长度,会有默认的长度
- 长度代表了显示的最大宽度,在创建表时添加
ZEROFILL实现用 0 在左边填充
注意
创建表时在类型后添加UNSIGNED设置无符号
CREATE TABLE book (
id INT,
bookname VARCHAR (20),
author_id INT UNSIGNED,
test INT
) ;
创建表时添加ZEROFILL实现用 0 在左边填充显示最大宽度
CREATE TABLE book (
id INT,
bookname VARCHAR (20),
author_id INT ZEROFILL,
test INT ZEROFILL
) ;
3.2、浮点型
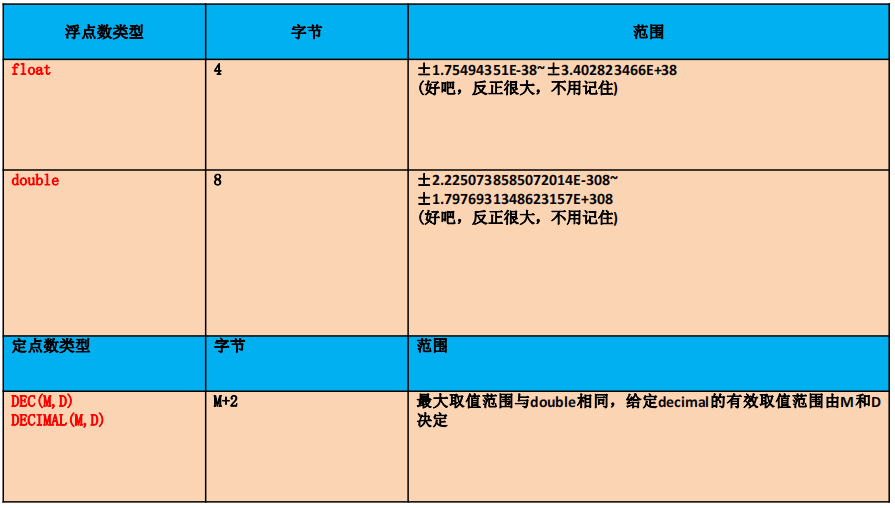
定点数精度更精确一些
特点:
- M:整数部位+小数部位
- D:小数部位
- (M,D) 可以省略
此时FLOAT与DOUBLE插入什么数据都可以
DECIMAL则默认为(10,0) - 定点型的精确度较高,若要求插入数值的精确度高如货币运算,考虑使用
- 原则:选择的类型越简单越好
FLOAT(M,D)、DOUBLE(M,D)、DEC(M,D)M指整数位+小数位的最大个数,D指小数位保留位数
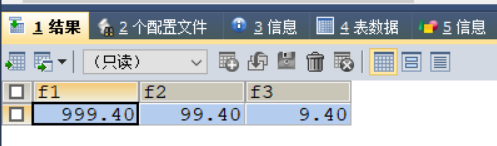
CREATE TABLE test_float (f1 FLOAT (5, 2), f2 DOUBLE (5, 2), f3 DEC (5, 2)) ;
INSERT INTO `test_float`
VALUES
(999.4, 99.4, 9.4) ;
3.3、字符型
较长的文本由 TEXT、BLOB(较大的二进制)存储
较短的二进制由 BINARY(固定)、VARBINARY(可变)存储
特点:
CHAR(M):存储固定长度的字符,耗费空间,但效率高
M 可省略,默认为1
可用于在 “ 性别 ” 等固定字符数的地方VARCHAR(M):存储可变长度的字符,节省空间,效率低
M 不可省略ENUM枚举类型, 要求插入的值必须属于列表中指定的值之一 ,不区分大小写
最多只有 65535 个成员SET类型,和Enum类型类似,要求插入的值必须属于列表中指定的值,但是一次可以选取多个成员 ,不区分大小写
最多只有 64 个成员😊
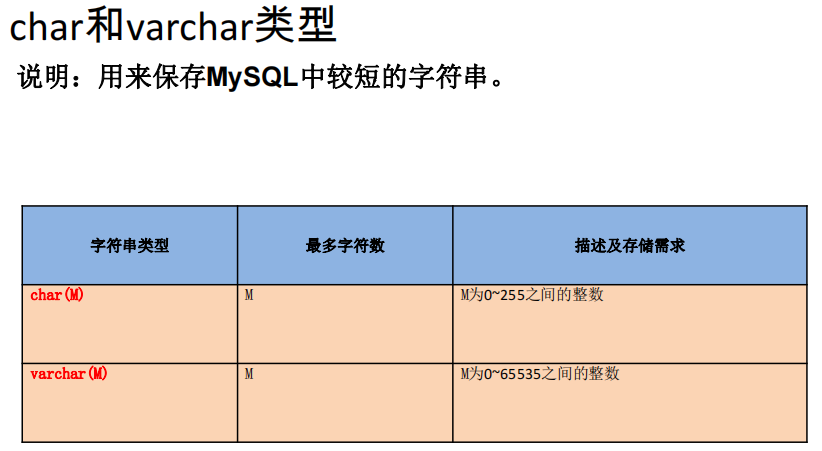
ENUM枚举类型
CREATE TABLE test_char (c1 ENUM ('a', 'b','c')) ;
INSERT INTO `test_char` VALUES ('a');
INSERT INTO `test_char` VALUES ('A');
以下会报错
INSERT INTO `test_char` VALUES ('m'); #会报错
执行结果如下
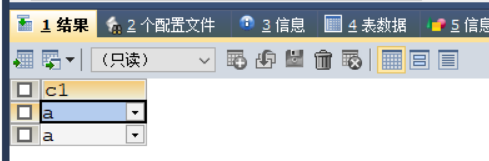
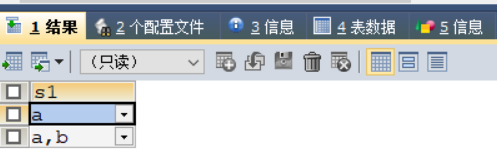
SET 类型
CREATE TABLE test_set (s1 SET ('a', 'b','c','d')) ;
INSERT INTO test_set VALUES ('a');
INSERT INTO test_set VALUES ('a,b');
执行结果如下
3.4、日期型
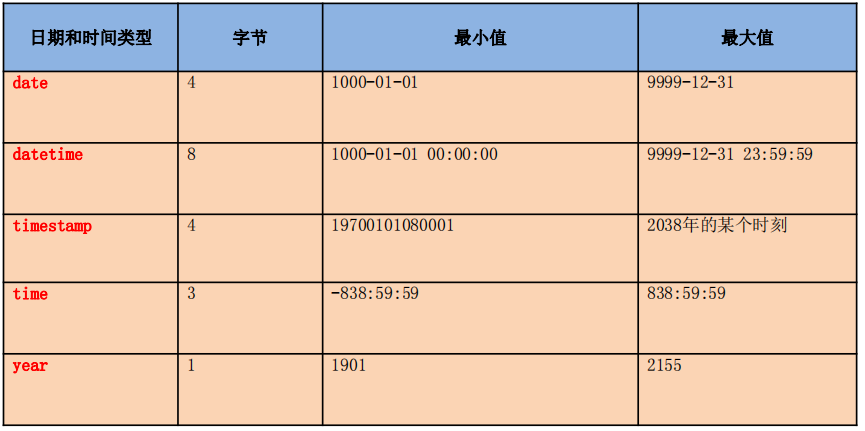
TIMESTAMP和实际时区有关,会受时区的变化而变化
且其的属性受Mysql版本和SQLMode的影响很大
下面代码演示TIMESTAMP受时区影响
此为当前时区的当前时间
CREATE TABLE test_time (d1 DATETIME,d2 TIMESTAMP);
INSERT INTO test_time VALUES(NOW(),NOW());
SELECT * FROM test_time;
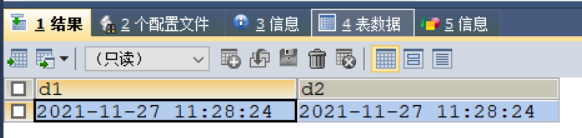
更改时区后,再次查询表格数据
SET time_zone = '+9:00'; #设置更改时区
SHOW VARIABLES LIKE 'time_zone'; #查看当前时区
SELECT * FROM test_time;
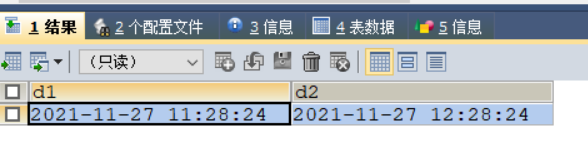
4、约束
可以在创建表、修改表时添加约束
分类:六大约束
NOT NULL:非空,用于保证该字段的值不能为空
👌比如姓名、学号等DEFAULT:默认,用于保证该字段有默认值
🤞比如性别PRIMARY KEY:主键,用于保证该字段的值具有唯一性,并且非空
👍比如学号、员工编号UNIQUE:唯一,用于保证该字段的值具有唯一性,可以为空
✌比如座位号CHECK:检查约束【MySQL可以使用,但没有任何效果】
🙌比如性别FOREIGN KEY:外键,用于限制两个表的关系,用于保证从表中该字段的值必须来自于主表的关联列的值,在从表中添加外键约束,用于引用主表中某列的值
👏比如学生表(从表)的专业(主表)编号,员工表的部门编号,员工表的工种编号
约束添加分类:
- 列级约束:六大约束都可,但外键约束没效果
- 表级约束:除了非空、默认,其他都可
CREATE TABLE IF NOT EXISTS 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
);
SHOW INDEX FROM 表名:显示表中所有索引,包括主键、外键、唯一
可以查看约束是否添加成功
4.1、创建表时的约束
4.1.1、添加列级约束
只支持 主键、非空、唯一、默认
CREATE TABLE test_1 (
id INT PRIMARY KEY, #主键
stuName VARCHAR (20) NOT NULL, #非空
seat INT UNIQUE, #唯一
age INT DEFAULT 18, #默认,后跟默认值
sex CHAR(1) CHECK (sex = '男'
OR sex = '女'), #检查,没效果
majorId INT REFERENCES major (id) #外键,没效果
) ;
CREATE TABLE major (
id INT PRIMARY KEY,
majorName VARCHAR (20) NOT NULL
) ;
查看设置效果
#查看设置效果
DESC `test_1`;
SHOW INDEX FROM `test_1`;
4.1.2、添加表级约束
非空、默认无法在表级约束进行设置
注意,给主键无法设置约束名,主键的名字固定是PRIAMRY,设置不了名字
语法: 在字段的最下面
【CONSTRAINT 约束名】 约束类型(字段名)
添加表级约束
#添加表级约束
CREATE TABLE test_2 (
id INT,
stuName VARCHAR (20),
seat INT,
age INT,
sex CHAR(1),
majorId INT,
CONSTRAINT pk PRIMARY KEY (id), #主键
CONSTRAINT uq UNIQUE (seat), #唯一
CONSTRAINT ck CHECK (sex = '男' OR sex = '女'), #检查
CONSTRAINT fk_test_2_major FOREIGN KEY (majorId) REFERENCES major (id) #外键
) ;
查看设置效果,外键设置成功
#查看设置效果
DESC `test_2`;
SHOW INDEX FROM `test_2`;
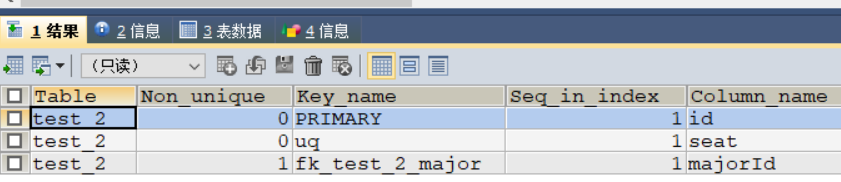
注意:
- 一般表级约束只用于外键设置
- 外键之后,还可加以下两个语句
ON DELETE CASCADE(级联删除): 当父表中的列被删除时,子表中相对应的列也被删除
ON DELETE SET NULL(级联置空): 子表中相应的列置空 - 可以创建多列外键组合
CONSTRAINT fk FOREIGN KEY(classes_name,classes_number) REFERENCES classes(NAME,number) 【ON DELETE CASCADE】;
4.2、主键与唯一区别
主键和唯一的对比:
- 都保证了唯一性
- 主键为非空,唯一允许为空(注意,NULL值永远唯一,即可以重复插入NULL值)
- 主键只可有一个要么就没有,唯一可以有多个
- 可以有组合成为主键,也可以组合成为唯一
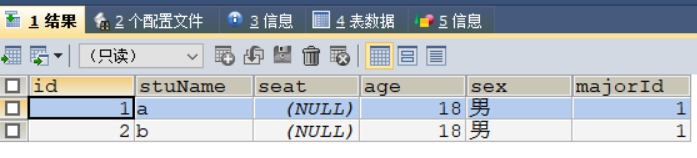
主键为非空,唯一允许为空
NULL值永远唯一,即可以重复插入NULL值
INSERT INTO `test_2`
VALUES
(1, 'a', NULL, 18, '男', 1),
(2, 'b', NULL, 18, '男', 1) ;
可以有组合成为主键,也可以组合成为唯一
CREATE TABLE test_3(
id INT,
stuName VARCHAR (20),
seat INT,
age INT,
majorId INT,
CONSTRAINT pk PRIMARY KEY (id,stuName), #组合主键
CONSTRAINT uq UNIQUE (seat,age), #组合唯一
CONSTRAINT fk_test_3_major FOREIGN KEY (majorId) REFERENCES major (id) #外键
);
对于组合主键、组合唯一,只要有一个值不同,都可算不重复
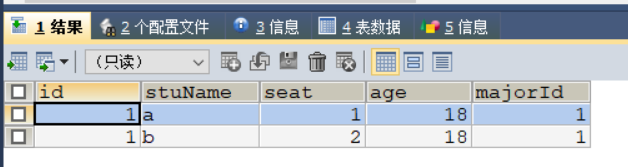
INSERT INTO `test_3`
VALUES
(1, 'a', 1, 18, 1),
(1, 'b', 2, 18, 1) ;
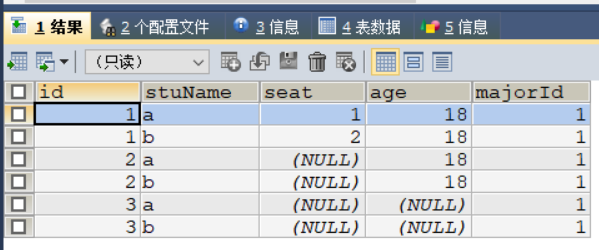
而NULL值永远唯一,所以在组合唯一中,只要有一个为NULL值,其他填什么值都可以
INSERT INTO `test_3`
VALUES
(2, 'a', NULL, 18, 1),
(2, 'b', NULL, 18, 1),
(3, 'a', NULL, NULL, 1),
(3, 'b', NULL, NULL, 1) ;
4.3、外键特点
外键特点:
- 要求在从表设置外键关系
- 从表的外键列的类型和主表的关联列类型要求一致或兼容,名称无要求
- 主表的关联列必须是一个 KEY ,要求必须是主键或唯一
- 插入数据时,先插入主表,再插入从表
- 删除数据时,先删除从表,再删除主表
主表的关联列必须是一个 KEY ,要求必须是主键或唯一
CREATE TABLE major (
id INT PRIMARY KEY,
majorName VARCHAR (20) NOT NULL
) ;
4.4、修改表时的约束
4.4.1、修改表时添加约束
语法:
添加列级约束
ALTER TABLE 表名 MODIFY COLUMN 字段名 字段类型 新约束类型;
添加表级约束
ALTER TABLE 表名 ADD 【CONSTRAINT 约束名】新约束类型(字段名) 【外键的引用】
- 添加非空约束
ALTER TABLE `test_4`
MODIFY COLUMN `stuName` VARCHAR (20) NOT NULL ;
改为可为空约束,只需要去掉 not null
ALTER TABLE `test_4` MODIFY COLUMN `stuName` VARCHAR (20) ;
- 添加默认约束
#添加默认约束
ALTER TABLE `test_4` MODIFY COLUMN `age` INT DEFAULT 18 ;
- 添加主键
列级约束
#添加主键——列级约束
ALTER TABLE `test_4` MODIFY COLUMN id INT PRIMARY KEY;
表级约束
#添加主键——表级约束
ALTER TABLE test_4 ADD CONSTRAINT pk PRIMARY KEY(id);
- 添加唯一
列级约束
#添加唯一——列级约束
ALTER TABLE `test_4` MODIFY COLUMN seat INT UNIQUE;
表级约束
#添加唯一——表级约束
ALTER TABLE test_4 ADD UNIQUE(seat);
- 添加外键
#添加外键
ALTER TABLE test_4 ADD FOREIGN KEY(`majorId`) REFERENCES major(id);
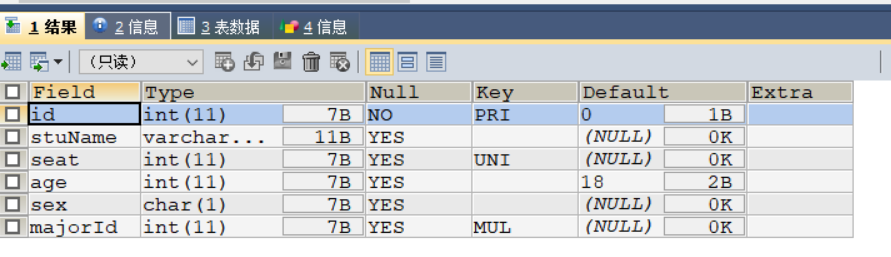
以上添加执行结果如下
DESC test_4;
4.4.2、修改表时删除约束
- 删除非空约束
ALTER TABLE `test_4` MODIFY COLUMN `stuName` VARCHAR (20) ;
或者是
ALTER TABLE `test_4` MODIFY COLUMN `stuName` VARCHAR (20) NULL;
- 删除默认约束
ALTER TABLE `test_4` MODIFY COLUMN `age` INT;
- 删除主键
ALTER TABLE test_4 DROP PRIMARY KEY;
- 删除唯一
ALTER TABLE test_4 DROP INDEX seat;
- 删除外键
注意这里只可以跟约束名,而且删除之后外键仍然在,所以还是要删除该字段
ALTER TABLE test_4 DROP FOREIGN KEY fk_major_id;
#还是要删除该字段
ALTER TABLE test_4 DROP `majorId`;
4.5、标识列
又称为 自增长列
含义:可以不用手动插入值,系统提供默认的序列值
用DELETE删除之后再插入数据,自增长列的值从断点开始
用TRUNCATE删除后再插入数据,自增长列的值从 1 开始
4.5.1、创建表时设置标识列
在字段约束类型后跟AUTO_INCREMENT
注意:
- 标识列必须和 key 搭配,比如主键、唯一、外键
- 标识列至多可有一个
- 标识列只能是数值型,小数整数都可
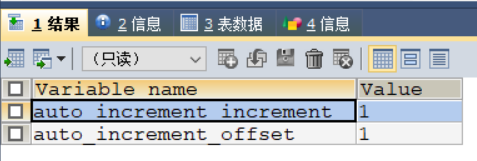
- 可以通过
SET auto_increment_increment = 3;修改步长 - 可手动修改起始值
标识列设置语法:
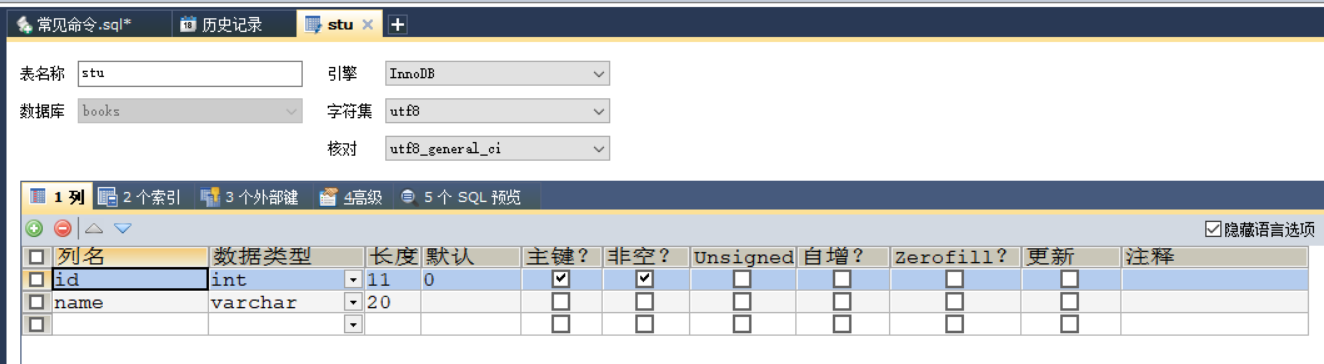
CREATE TABLE stu (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR (20)
) ;
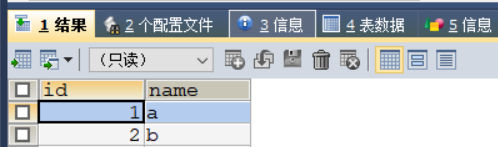
1、可输入 NULL
该列虽为主键,也可输入 NULL,其实是自增长
INSERT INTO stu (id,NAME) VALUES (NULL,'a');
INSERT INTO stu (NAME) VALUES('b');
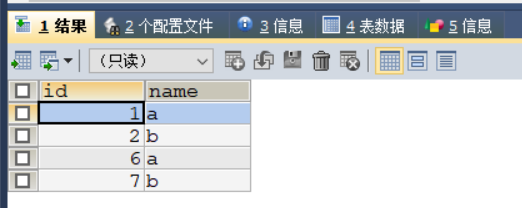
2、可手动修改起始值
若输入数据为自己的数字,则自增长跟在自定义值之后
INSERT INTO stu (id,NAME) VALUES (6,'a');
INSERT INTO stu (NAME) VALUES('b');
3、可修改步长
若想自增长的跨度不是1,可更改参数auto_increment_increment
原本是1
更改为3
SET auto_increment_increment = 3;
SHOW VARIABLES LIKE '%auto_increment%';
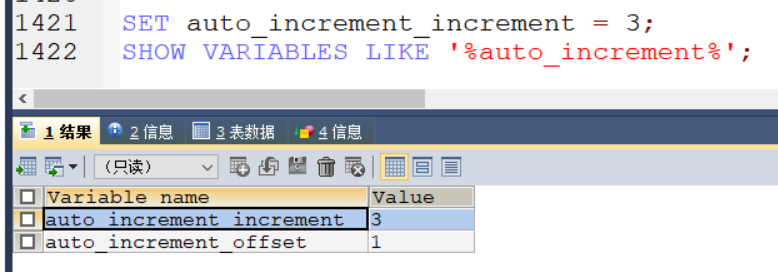
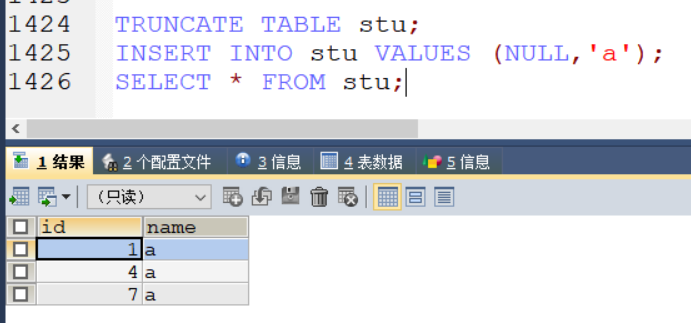
则此时自增长以 3 为跨度
TRUNCATE TABLE stu;
INSERT INTO stu VALUES (NULL,'a');
SELECT * FROM stu;
4.5.2、修改表时设置标识列
修改表时设置标识列
ALTER TABLE stu MODIFY COLUMN id INT PRIMARY KEY AUTO_INCREMENT;
修改表时删除标识列
ALTER TABLE stu MODIFY COLUMN id INT;
注意,主键、唯一 要用前面4.4.2提到的删除方式删除
TCL语言
Transaction Control Language
事务控制语言
1、事务介绍
设置安全模式
SET SQL_SAFE_UPDATES = 0;
含义:
事务由单独单元的一个或多个SQL语句组成,在这个单元中,每个MySQL语句是相互依赖的,整个单独单元作为一个不可分割的整体
如果单元中某条SQL语句一旦执行失败或产生错误,整个单元将会回滚,所有数据将返回到事物开始以前的状态
如果单元中的所有SQL语句均执行成功,则事物被顺利执行
即一个或多个SQL语句组成一个执行单元,这个执行单元要么全部执行,要么全部不执行
举例:转账
张三丰1000,郭襄1000,张三丰转给郭襄500,二人余额同时变动,此时可以将以下语句封为一个事务
UPDATE 表名 SET 张三丰余额=500 WHERE NAME = '张三丰';
UPDATE 表名 SET 郭襄余额=1500 WHERE NAME = '郭襄';
因为执行过程中可能有意外,导致第一句执行,第二句未得到执行,此时的事务就是用于处理这种情况,要么全部执行,要么全部不执行
如果单元中某条SQL语句一旦执行失败或产生错误,整个单元将会回滚,所有数据将返回到事物开始以前的状态
如果单元中的所有SQL语句均执行成功,则事物被顺利执行
MySQL中的存储引擎
在mysql中的数据用各种不同的技术存储在文件(或内存)中,其中innodb支持事务,而myisam、memory等不支持事务
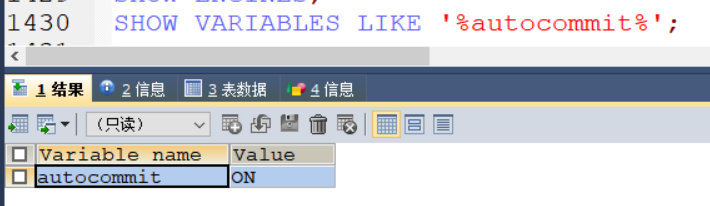
SHOW ENGINES;查看存储引擎
事务的特点 ACID
- 原子性(Atomicity)
指事务是一个不可分割的工作单位,事务中的操作要么
都发生,要么都不发生。 - 一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态
比如:转账前后二人余额和始终为2000 - 隔离性(Isolation)
一个事务的执行不能被其他事务干扰,并发执行的各个事务之间不能互相干扰。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
1.1、事务的创建
隐式事务:
事务没有明显的开启和结束的标记
比如 insert、update、delete 语句,直接一句SQL语句就是一个事务
这种情况是因为有自动提交功能,直接执行一个语句就自动提交
autocommit
显式事务:
事务具有明显的开启和结束的标记
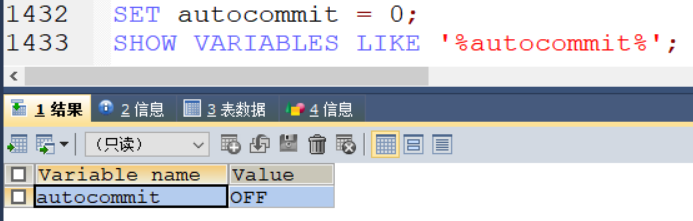
前提:
先设置自动提交功能为禁用SET autocommit = 0;
步骤1:开启事务
以下面的其中之一作为开始:
- 以第一个 DML 语句的执行作为开始
SET autocommit = 0;可选的,可写可不行START TRANSACTION;可选的,可写可不行- 以上两句都写也可,都不写也可,任写一句也可
步骤2:编写事务语句
只可以是 DML 语句( select、insert、update、delete 语句)
步骤3:结束事务
以下面的其中之一作为结束:
COMMIT;提交事务ROLLBACK;回滚事务(语句不会有执行效果)- DDL 或 DCL 语句(自动提交)
- 用户会话正常结束
- 系统异常终了
ROLLBACK; 回滚事务(语句不会有执行效果)
START TRANSACTION;
SET autocommit = 0;
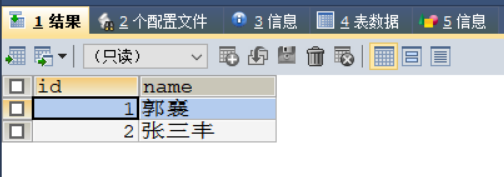
UPDATE stu SET id = 3 WHERE `name` = '张三丰';
UPDATE stu SET id = 4 WHERE `name` ='郭襄';
ROLLBACK;
执行没有效果
1.2、事务隔离
当同时运行的多个事务访问数据库中相同的数据时,若没有采取必要的隔离机制, 就会导致各种并发问题:已知两个事务 T1、T2
- 脏读: T1 读取了已经被 T2 更新但还没有被提交的字段。之后,若 T2 回滚,T1读取的内容就是临时且无效的
- 不可重复读: T1 读取了一个字段,然后 T2 更新了该字段。之后,T1再次读取同一个字段,值就不同了
- 幻读: T1 从一个表中读取了一个字段,然后 T2 在该表中插入了一些新的行。之后,如果 T1 再次读取同一个表,,就会多出几行
一个事务与其他事务隔离的程度称为事务隔离级别:

| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| read committed | × | √ | √ |
| repeatable read | × | × | √ |
| serializable | × | × | × |
Mysql 中默认第三种隔离级别REPEATABLE READ,并支持4中隔离级别
Oracle 中默认第二种隔离级READ COMMITED,支持2种,第二、四
select @@tx_isolation;:查看当前隔离级别
select @@transaction_isolation;:MySQL8的版本查看当前隔离级别
set session|global transaction isolation level read uncommitted;:修改隔离级别
set names gbk;修改字符集
以下演示脏读的情况:
先要将MySQL的隔离级别改为最低级别
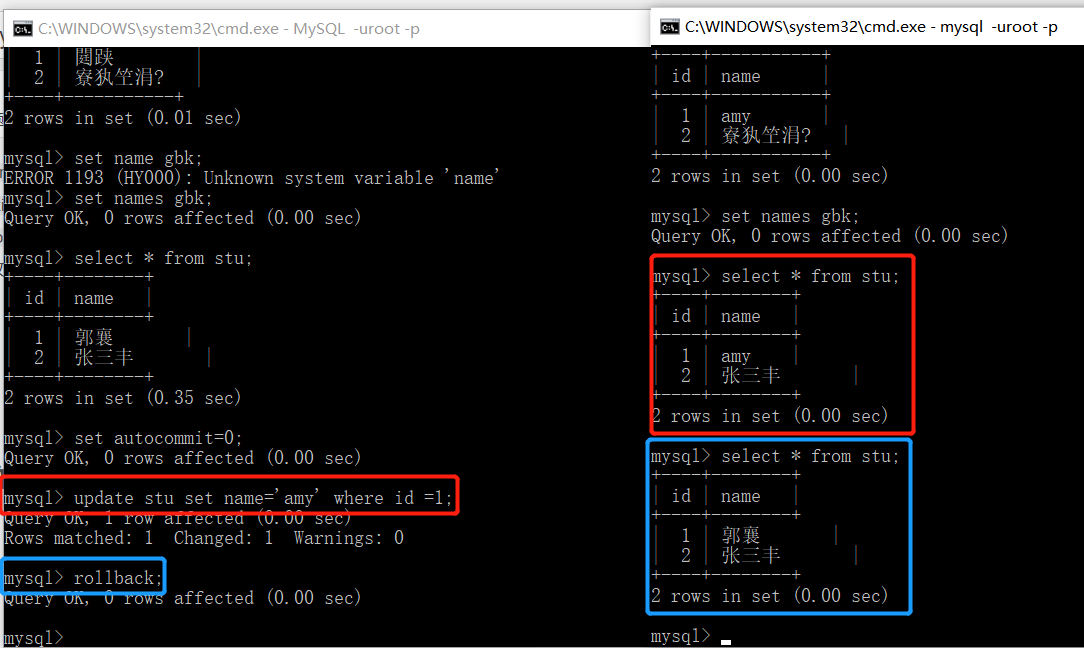
当左边事务执行红框语句时候,右边事务读取的数据是Amy,当左边事务回滚之后,右边事务就变回了郭襄,读取的数据是临时且无效的
1.3、保存点
保存点只可与回滚搭配使用,类似于复活点
SAVEPOINT 节点名;设置保存点
ROLLBACK TO 节点名; 回滚到保存点,节点名可以任意设置
原始数据为:
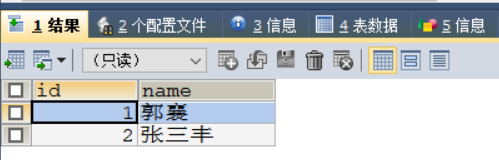
设置回滚点后
#保存点
START TRANSACTION;
SET autocommit = 0;
UPDATE stu SET id = 3 WHERE `name` = '张三丰';
SAVEPOINT b;
UPDATE stu SET id = 4 WHERE `name` ='郭襄';
ROLLBACK TO b;
SELECT * FROM stu;
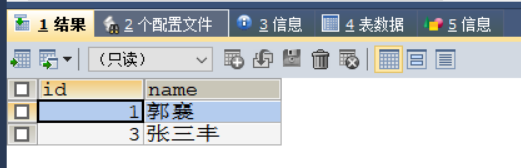
相当于复活点
1.4、DELETE与TRUNCATE对于回滚的区别
TRUNCATE删除不能回滚,DELETE删除可以回滚
DELETE删除可以回滚
#delete
SET autocommit = 0;
START TRANSACTION;
DELETE FROM stu;
ROLLBACK;
执行结果,并未删除数据,说明已回滚
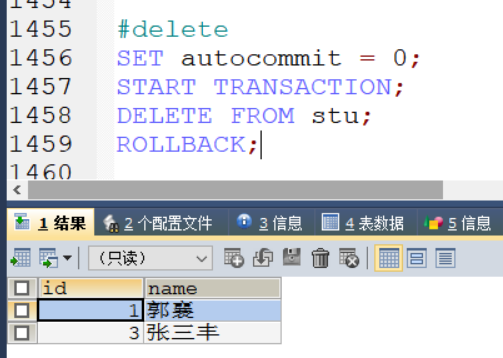
TRUNCATE删除不能回滚
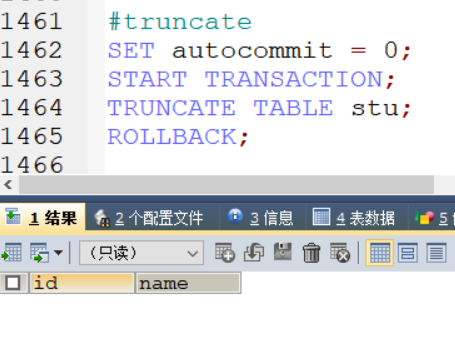
#truncate
SET autocommit = 0;
START TRANSACTION;
TRUNCATE TABLE stu;
ROLLBACK;
数据被删除,不能回滚















 6280
6280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









