







对于分类问题来讲,感知器(感知机)可以有多个“好的”分类器来完成对应的分类任务,如下图所示,假设训练数据线性可分,图中所有的直线都代表感知器的一个分界面,那么下图所有的分界面都能够顺利完成分类任务。

其中红色的线表示最好的一个分界面。理想的分界面要距离每一个样本都较远,这样的模型兼容性好、泛化能力和稳定性强,可以容忍在采集数据时造成的一定的噪声问题。
间隔(到超平面的距离)
为了描述上述思想,提出了间隔(margin) 的概念,是指决策边界(超平面)到分类样本(x)的最短距离。
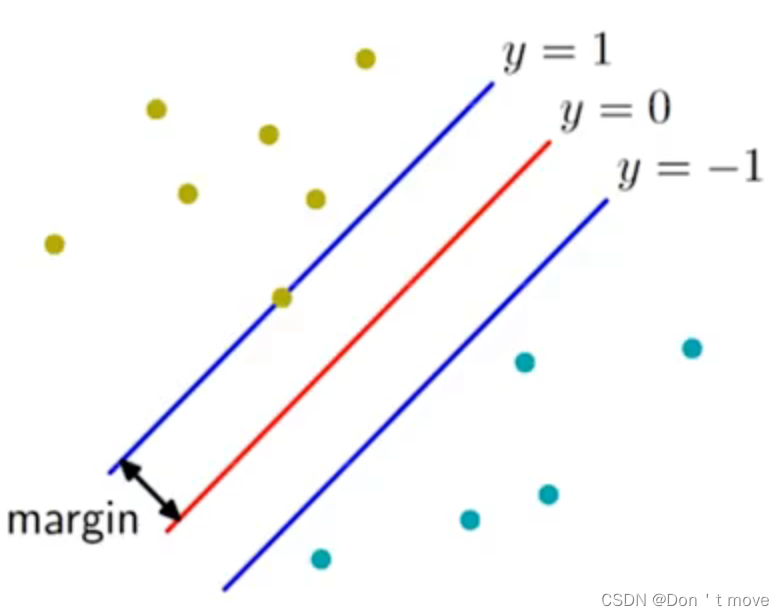
如此以来,最好的分类器就是使得间隔最大的一种。将选择间隔最大的决策边界作为优化准则,叫做支持向量机(support vector machine)
如下图,对于判别函数
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx+b
f(x)=wTx+b,红色线
f
(
x
)
=
0
f(x)=0
f(x)=0表示决策边界。
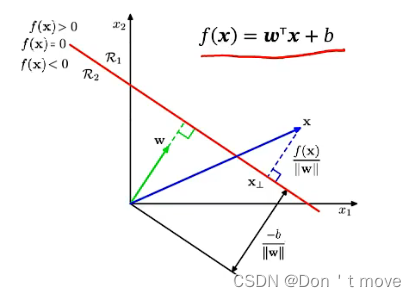
首先,
w
w
w方向上的法向量为
w
∥
w
∥
\frac{w}{\| w\|}
∥w∥w,则
x
x
x在
w
w
w上的投影就是
w
∥
w
∥
x
=
w
T
x
∥
w
∥
\frac{w}{\| w\|}x=\frac{w^Tx}{\| w\|}
∥w∥wx=∥w∥wTx
然后计算坐标原点到决策边界的距离,根据点到直线的距离公式可得
∣
w
T
⋅
0
+
b
∣
∥
w
∥
=
b
∥
w
∥
\frac{|w^T\cdot 0+b|}{\| w\|}=\frac{b}{\| w\|}
∥w∥∣wT⋅0+b∣=∥w∥b
事实上,
w
w
w的方向与决策边界是垂直的,也就是说原点到决策边界的垂直连线与
w
w
w的方向相同,证明如下1:
设
x
1
,
x
2
为
f
(
x
)
=
0
上任意两点
则
f
(
x
1
)
=
f
(
x
2
)
w
T
x
1
+
b
=
w
T
x
2
+
b
w
T
(
x
1
−
x
2
)
=
0
即
w
T
与
x
1
−
x
2
正交
又
x
1
,
x
2
为
f
(
x
)
上任意两点
所以
w
T
与
f
(
x
)
上任意一向量正交也即
w
T
与
f
(
x
)
垂直
\begin{aligned} &设x_1,x_2为f(x)=0上任意两点\\ &\begin{aligned} 则\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ f(x_1)&=f(x_2)\\ w^Tx_1+b&=w^Tx_2+b\\ w^T(x_1-x_2)&=0 \end{aligned}\\ &即w^T与x_1-x_2正交\\ &又x_1,x_2为f(x)上任意两点\\ &所以w^T与f(x)上任意一向量正交也即w^T与f(x)垂直 \end{aligned}
设x1,x2为f(x)=0上任意两点则 f(x1)wTx1+bwT(x1−x2)=f(x2)=wTx2+b=0即wT与x1−x2正交又x1,x2为f(x)上任意两点所以wT与f(x)上任意一向量正交也即wT与f(x)垂直
接下来计算点
x
x
x到决策边界的距离,用
x
x
x到
w
w
w方向上的投影减去(如上图,或者
x
x
x在分界线下方时加上)原点到决策边界的距离:
γ
=
w
T
x
∥
w
∥
±
b
∥
w
∥
=
w
T
x
±
b
∥
w
∥
=
f
(
x
)
∥
w
∥
\begin{aligned} \gamma &=\frac{w^Tx}{\| w\|}\pm\frac{b}{\| w\|}\\ &=\frac{w^Tx\pm b}{\| w\|}\\ &=\frac{f(x)}{\| w\|} \end{aligned}
γ=∥w∥wTx±∥w∥b=∥w∥wTx±b=∥w∥f(x)
其实就是点到直线的距离公式。
假设超平面可以将训练集所有的样本分开,则对于训练样本
(
x
,
y
)
(x,y)
(x,y)有
y
(
w
T
x
+
b
)
>
0
y(w^Tx+b)>0
y(wTx+b)>0
其中
y
=
±
1
y=\pm 1
y=±1,式子
γ
=
y
(
w
T
x
+
b
)
\gamma=y(w^Tx+b)
γ=y(wTx+b)代表样本与超平面的函数间隔,
w
T
x
+
b
w^Tx+b
wTx+b越大,样本与超平面的函数间隔越远2。若等比例缩放参数
w
,
b
w,b
w,b,虽然超平面仍然为
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0,但用函数间隔表示出的距离会发生改变,因此需要对函数间隔进行归一化处理,最后得到样本到超平面的几何间隔
γ
=
∣
w
T
x
+
b
∣
∥
w
∥
=
y
(
w
T
x
+
b
)
∥
w
∥
\begin{aligned} \gamma &=\frac{|w^Tx+b|}{\| w\|}\\ &=\frac{y(w^Tx+b)}{\| w\|} \end{aligned}
γ=∥w∥∣wTx+b∣=∥w∥y(wTx+b)
在几何间隔下,参数等比例缩放不会影响样本与超平面的距离值。
支持向量机
支持向量机的目标是寻找一个超平面
(
w
∗
,
b
∗
)
(w^*, b^*)
(w∗,b∗)使得
γ
\gamma
γ最大,即
max
w
,
b
γ
s
.
t
.
y
(
n
)
(
w
T
x
(
n
)
+
b
)
∥
w
∥
≥
γ
,
∀
n
∈
{
1
,
⋯
,
N
}
\begin{aligned} \max_{w,b}&\ \ \gamma\\ s.t.&\ \ \ \frac{y^{(n)}(w^Tx^{(n)}+b)}{\|w\|}\geq\gamma,\forall n\in\{1,\cdots,N\} \end{aligned}
w,bmaxs.t. γ ∥w∥y(n)(wTx(n)+b)≥γ,∀n∈{1,⋯,N}
上式就是支持向量机的目标
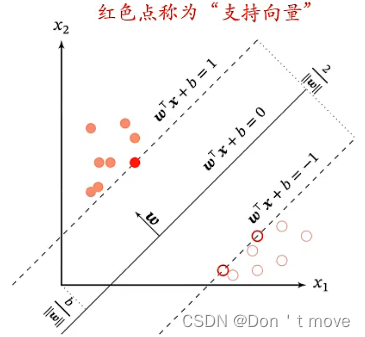
其中,数据集中每个样本到超平面的距离为:
γ
(
n
)
=
∣
w
T
x
(
n
)
+
b
∣
∥
w
∥
=
y
(
n
)
(
w
T
x
(
n
)
+
b
)
∥
w
∥
\gamma^{(n)}=\frac{|w^Tx^{(n)}+b|}{\|w\|}=\frac{y^{(n)}(w^Tx^{(n)}+b)}{\|w\|}
γ(n)=∥w∥∣wTx(n)+b∣=∥w∥y(n)(wTx(n)+b)
由于上式中对于参数
w
,
b
w,b
w,b进行等比例缩放不会影响
γ
\gamma
γ的大小,也就是说
∥
w
∥
\|w\|
∥w∥等于任意一个常数不会影响
γ
\gamma
γ(因为分子此时也会对应进行等比例变化),不妨设
∥
w
∥
=
1
γ
\|w\|=\frac{1}{\gamma}
∥w∥=γ1,移项得
γ
=
1
∥
w
∥
\gamma=\frac{1}{\|w\|}
γ=∥w∥1。在进行函数优化时,对
∥
w
∥
\|w\|
∥w∥取平方不会影响优化结果,因此支持向量机的目标函数也可以直接记作:
max
w
,
b
1
∥
w
∥
2
→
min
∥
w
∥
2
s
.
t
.
y
(
n
)
(
w
T
x
(
n
)
+
b
)
≥
1
,
∀
n
∈
{
1
,
⋯
,
N
}
\begin{aligned} \max_{w,b}&\ \ \frac{1}{\|w\|^2}\rightarrow\min \|w\|^2\\ s.t.&\ \ \ y^{(n)}(w^Tx^{(n)}+b)\geq1,\forall n\in\{1,\cdots,N\} \end{aligned}
w,bmaxs.t. ∥w∥21→min∥w∥2 y(n)(wTx(n)+b)≥1,∀n∈{1,⋯,N}
要注意,取
∥
w
∥
=
1
γ
\|w\|=\frac{1}{\gamma}
∥w∥=γ1之后,可得
γ
∥
w
∥
=
y
(
w
T
x
+
b
)
=
1
\gamma\|w\|=y(w^Tx+b)=1
γ∥w∥=y(wTx+b)=1,也就是说,实际上这样做是限制了样本点与超平面的函数间隔,使得函数间隔固定。同时,不等式是由上面第一次提到的目标函数中的不等式两侧同时乘以
∥
w
∥
\|w\|
∥w∥得到的。
这样,就确定了间隔(如上图两虚线)。落在间隔上的点称为支持向量,因此SVM的优化目标即是让支持向量距离超平面的距离最大。在SVM中,决策边界是由支持向量决定的。
软间隔(Soft Margin)
在上面的推导中,我们推导的前提条件是训练集样本必须线性可分,但实际上样本并不都是线性可分的,此时SVM无法找到最优解。为了能够容忍部分不满足约束的样本,引入松弛变量(Slack Variable)来对原始SVM问题做转换。改进后的SVM目标:
min
w
,
b
1
2
∥
w
∥
2
+
C
∑
n
=
1
N
ξ
n
s
.
t
.
1
−
y
(
n
)
(
w
T
x
(
n
)
+
b
)
−
ξ
n
≤
0
,
∀
∈
{
1
,
⋯
,
N
}
ξ
n
≥
0
,
∀
n
∈
{
1
,
⋯
,
N
}
\begin{aligned} \min_{w,b} &\ \ \frac{1}{2}\|w\|^2+C\sum_{n=1}^N\xi_n\\ s.t. &\ \ \ 1-y^{(n)}(w^Tx^{(n)}+b)-\xi_n\leq0,\forall\in\{1,\cdots,N\}\\ &\ \ \ \xi_n\geq0, \forall n\in\{1,\cdots,N\} \end{aligned}
w,bmins.t. 21∥w∥2+Cn=1∑Nξn 1−y(n)(wTx(n)+b)−ξn≤0,∀∈{1,⋯,N} ξn≥0,∀n∈{1,⋯,N}
上式中优化目标加了
1
2
\frac{1}{2}
21是优化上的习惯,这样在优化过程中求
w
w
w的偏导正好能消掉。
C
C
C是一个控制变量,
C
C
C越大对应的松弛变量就要越小,对样本的容忍度低,
C
C
C越小松弛变量越大,对样本的容忍度更高。这种包含松弛变量的SVM目标就是软间隔。
从本质上说,在原来的SVM目标函数中,有些样本无法满足条件的根本原因是无法满足样本的函数间隔大于等于1这一约束条件(
y
(
n
)
(
w
T
x
(
n
)
+
b
)
≥
1
y^{(n)}(w^Tx^{(n)}+b)\geq1
y(n)(wTx(n)+b)≥1),因此在式子中加入一个的松弛变量
ξ
≥
0
\xi\geq0
ξ≥0,让约束条件变得宽松
y
(
n
)
(
w
T
x
(
n
)
+
b
)
≥
1
−
ξ
n
\begin{aligned} y^{(n)}(w^Tx^{(n)}+b)\geq1-\xi_n \end{aligned}
y(n)(wTx(n)+b)≥1−ξn
同时,上式还要让
ξ
\xi
ξ尽可能的小
- 当 ξ = 0 \xi=0 ξ=0时最佳,说明此时样本集仍然满足严格的SVM标准
- 当 ξ ∈ ( 0 , 1 ) \xi\in(0,1) ξ∈(0,1)时,虽然能被超平面分开,但不符合SVM标准
- 当
ξ
>
1
\xi>1
ξ>1时,说明超平面无法正确将样本分开
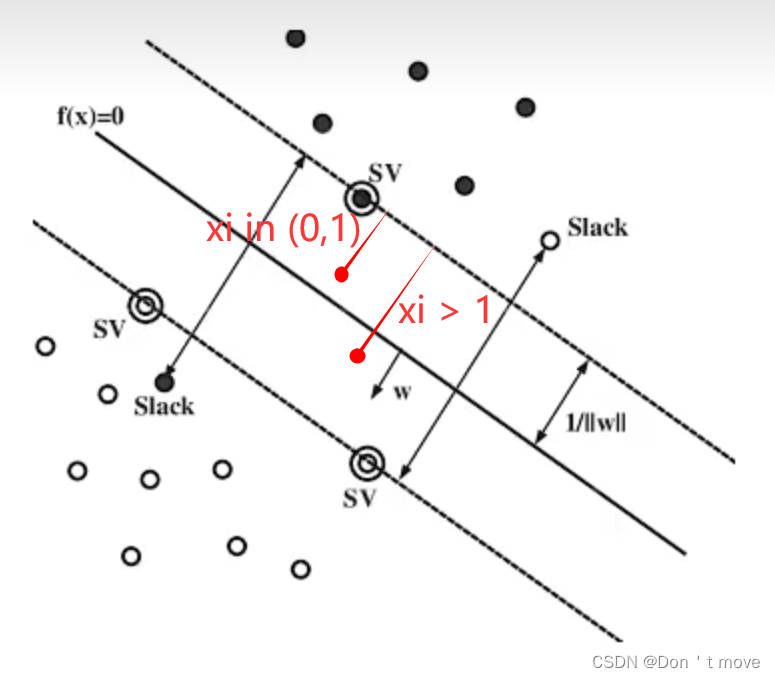
对于支持向量机来说,当样本集不严格符合SVM标准时都需要对超平面做调整。对于松弛变量
ξ
\xi
ξ可以记作:
ξ
n
=
{
0
1
−
y
(
n
)
(
w
T
x
(
n
)
+
b
)
\xi_n=\left\{\begin{aligned} & 0 \\ & 1-y^{(n)}(w^Tx^{(n)}+b) \end{aligned}\right.
ξn={01−y(n)(wTx(n)+b)
同时,有之前的推导可知当样本分类正确时,
y
(
n
)
(
w
T
x
(
n
)
+
b
)
≥
1
y^{(n)}(w^Tx^{(n)}+b)\geq 1
y(n)(wTx(n)+b)≥1,因此上式也可以记作
max
(
0
,
1
−
y
(
n
)
(
w
T
x
(
n
)
+
b
)
)
\max(0,1-y^{(n)}(w^Tx^{(n)}+b))
max(0,1−y(n)(wTx(n)+b)) 。这样之后,再对SVM目标进行改写:
min
w
,
b
1
2
C
∥
w
∥
2
+
∑
n
=
1
N
max
(
0
,
1
−
y
(
n
)
(
w
T
x
(
n
)
+
b
)
)
\begin{aligned} \min_{w,b} & \ \ \frac{1}{2C}\|w\|^2+\sum_{n=1}^N\max(0,1-y^{(n)}(w^Tx^{(n)}+b)) \end{aligned}
w,bmin 2C1∥w∥2+n=1∑Nmax(0,1−y(n)(wTx(n)+b))
稍微改变一下顺序,形式就变得很熟悉了
min
w
,
b
∑
n
=
1
N
max
(
0
,
1
−
y
(
n
)
(
w
T
x
(
n
)
+
b
)
)
⏟
经验风险
+
1
2
C
∥
w
∥
2
⏟
正则化项
\begin{aligned} \min_{w,b} & \ \ \underbrace{\sum_{n=1}^N\max(0,1-y^{(n)}(w^Tx^{(n)}+b))}_{经验风险}+\underbrace{\frac{1}{2C}\|w\|^2}_{正则化项} \end{aligned}
w,bmin 经验风险
n=1∑Nmax(0,1−y(n)(wTx(n)+b))+正则化项
2C1∥w∥2
这里的经验风险有个专门的名称,叫做Hinge损失函数,它与感知器的损失函数非常类似,二者的区别在于在感知器损失函数中如果样本分类正确就不会更新参数,但对于Hinge损失来说,即使样本分类正确,但得分不超过1,仍然会更新参数
















 3835
3835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











