







模型选择是机器学习中比较重要的问题,选择的不同的模型会造成不同的后果:
- 拟合能力强的模型一般复杂度较高,容易过拟合
- 如果限制模型复杂度,降低拟合能力,可能会欠拟合
在模型训练的过程中越复杂的模型对应的训练错误率越低,但是并不能以训练时的错误率去评判模型的优劣,要用与训练过程无关的测试集来判断,这也就意味着在选择模型时,测试集不可见。那么在训练时,要如何判断哪个模型更优秀呢?为此,需要引入验证集(Validation Set或Development Set)。
验证集可以是单独的数据集,也可以从原训练集中选择部分作为验证集。当使用不同的模型在训练集上完成训练后,接着验证模型在验证集上的错误率,以此来评价哪个模型更优秀。
但是当训练集数据很少时,如果再从中拿出足够量的训练集,就会加剧数据稀疏问题。为此,可以通过交叉验证(Cross-Validation) 方式来尽可能的使验证集与训练集比例相当,尽可能提高数据利用率。
所谓交叉验证就是指将训练集分为S组,每次使用S-1组作为训练集,剩下一组作为验证集。然后最终选择验证集上平均性能最好的一组作为最后的模型。
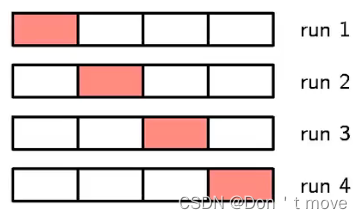
如上图将训练集分为4组,每次选择3组作为训练集、剩下1组作为验证集。
除了上面所说通过验证集来进行模型选择之外,还可以在一些准则的指导下进行模型选择,常用的准则有:
- 赤池信息量准则(Akaike Information Criterion,AIC)
- 贝叶斯信息准则(Bayesian Information Criterion,BIC)1
偏差-方差分解(Bais-Variance Decomposition)
模型选择的实质是在期望风险与模型复杂度之间做平衡,二者之间的关系可以从期望风险入手,将期望风险分为方差(Variance) 和偏差(Bais) 来进一步解释期望风险与模型复杂度的关系。
仍然以线性回归为例,设当前选择的模型为
f
(
x
)
f(x)
f(x),损失函数仍然是平方损失函数,则对应的经验风险为
R
(
f
)
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
(
x
)
)
2
]
=
(
y
−
f
(
x
)
)
2
p
(
x
,
y
)
=
(
y
−
f
(
x
)
)
2
p
(
x
)
p
(
y
∣
x
)
=
(
(
y
−
f
(
x
)
)
2
p
(
y
∣
x
)
)
p
(
x
)
=
E
y
∼
p
r
(
y
∣
x
)
[
(
y
−
f
(
x
)
)
2
]
p
(
x
)
=
E
x
∼
p
r
(
x
)
[
E
y
∼
p
r
(
y
∣
x
)
[
(
y
−
f
(
x
)
)
2
]
]
\begin{aligned} \mathcal{R}(f) &=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f(x))^2]\\ &=(y-f(x))^2p(x,y)\\ &=(y-f(x))^2p(x)p(y\mid x)\\ &=((y-f(x))^2p(y\mid x))p(x)\\ &=\mathbb{E}_{y\sim p_r(y\mid x)}[(y-f(x))^2]p(x)\\ &=\mathbb{E}_{x\sim p_r(x)}[\mathbb{E}_{y\sim p_r(y\mid x)}[(y-f(x))^2]]\\ \end{aligned}
R(f)=E(x,y)∼pr(x,y)[(y−f(x))2]=(y−f(x))2p(x,y)=(y−f(x))2p(x)p(y∣x)=((y−f(x))2p(y∣x))p(x)=Ey∼pr(y∣x)[(y−f(x))2]p(x)=Ex∼pr(x)[Ey∼pr(y∣x)[(y−f(x))2]]
下面为了方便看,把
E
x
∼
p
r
(
x
)
\mathbb{E}_{x\sim p_r(x)}
Ex∼pr(x)简写成
E
x
\mathbb{E}_x
Ex,把
E
y
∼
p
r
(
y
∣
x
)
\mathbb{E}_{y\sim p_r(y\mid x)}
Ey∼pr(y∣x)简写成
E
y
\mathbb{E}_y
Ey,另外把
y
y
y given
x
x
x下
y
y
y的期望记作
μ
(
x
)
\mu(x)
μ(x)也即
μ
(
x
)
=
E
y
∼
p
r
(
y
∣
x
)
[
y
]
\mu(x)=\mathbb{E}_{y\sim p_r(y\mid x)}[y]
μ(x)=Ey∼pr(y∣x)[y] 。
R ( f ) = E x [ E y [ ( y − f ( x ) ) 2 ] ] = E x [ E y [ ( y − μ ( x ) + μ ( x ) − f ( x ) ) 2 ] ] = E x [ E y [ ( y − μ ( x ) ) 2 + ( μ ( x ) − f ( x ) ) 2 + 2 ( μ ( x ) − f ( x ) ) ( y − μ ( x ) ) ] ] = E x [ E y [ ( y − μ ( x ) ) 2 + ( μ ( x ) − f ( x ) ) 2 ] + 2 ( μ ( x ) − f ( x ) ) E y [ ( y − μ ( x ) ) ] ] = E x [ E y [ ( y − μ ( x ) ) 2 + ( μ ( x ) − f ( x ) ) 2 ] + 2 ( μ ( x ) − f ( x ) ) ( E y [ y ] − E y [ μ ( x ) ] ) ] = E x [ E y [ ( y − μ ( x ) ) 2 + ( μ ( x ) − f ( x ) ) 2 ] + 2 ( μ ( x ) − f ( x ) ) ( μ ( x ) − μ ( x ) ) ] = E x [ E y [ ( y − μ ( x ) ) 2 + ( μ ( x ) − f ( x ) ) 2 ] \begin{aligned} \mathcal{R}(f) &=\mathbb{E}_x[\mathbb{E}_y[(y-f(x))^2]]\\ &=\mathbb{E}_x[\mathbb{E}_y[(y-\mu(x)+\mu(x)-f(x))^2]]\\ &=\mathbb{E}_x[\mathbb{E}_y[(y-\mu(x))^2+(\mu(x)-f(x))^2+2(\mu(x)-f(x))(y-\mu(x))]]\\ &=\mathbb{E}_x[\mathbb{E}_y[(y-\mu(x))^2+(\mu(x)-f(x))^2] +2(\mu(x)-f(x))\mathbb{E}_y[(y-\mu(x))]]\\ &=\mathbb{E}_x[\mathbb{E}_y[(y-\mu(x))^2+(\mu(x)-f(x))^2] +2(\mu(x)-f(x))(\mathbb{E}_y[y]-\mathbb{E}_y[\mu(x)])]\\ &=\mathbb{E}_x[\mathbb{E}_y[(y-\mu(x))^2+(\mu(x)-f(x))^2] +2(\mu(x)-f(x))(\mu(x)-\mu(x))]\\ &=\mathbb{E}_x[\mathbb{E}_y[(y-\mu(x))^2+(\mu(x)-f(x))^2] \end{aligned} R(f)=Ex[Ey[(y−f(x))2]]=Ex[Ey[(y−μ(x)+μ(x)−f(x))2]]=Ex[Ey[(y−μ(x))2+(μ(x)−f(x))2+2(μ(x)−f(x))(y−μ(x))]]=Ex[Ey[(y−μ(x))2+(μ(x)−f(x))2]+2(μ(x)−f(x))Ey[(y−μ(x))]]=Ex[Ey[(y−μ(x))2+(μ(x)−f(x))2]+2(μ(x)−f(x))(Ey[y]−Ey[μ(x)])]=Ex[Ey[(y−μ(x))2+(μ(x)−f(x))2]+2(μ(x)−f(x))(μ(x)−μ(x))]=Ex[Ey[(y−μ(x))2+(μ(x)−f(x))2]
对于模型
f
(
x
)
f(x)
f(x)来说,要想让经验风险最小,必须要让上式中与
f
(
x
)
f(x)
f(x)有关的项最小,也就是说当
(
μ
(
x
)
−
f
(
x
)
)
2
(\mu(x)-f(x))^2
(μ(x)−f(x))2最小即
f
(
x
)
=
μ
(
x
)
=
E
y
∼
p
r
(
y
∣
x
)
[
y
]
f(x)=\mu(x)=\mathbb{E}_{y\sim p_r(y\mid x)}[y]
f(x)=μ(x)=Ey∼pr(y∣x)[y]时,经验风险最小。也就是说,机器学习能学到的最优模型为:
f
∗
(
x
)
=
E
y
∼
p
r
(
y
∣
x
)
[
y
]
f^*(x)=\mathbb{E}_{y\sim p_r(y\mid x)}[y]
f∗(x)=Ey∼pr(y∣x)[y]
这表明当机器学习取最优模型时,模型的预测值将正好与样本中实际的取值相等。将
f
∗
(
x
)
f^*(x)
f∗(x)代回原期望函数:
R
(
f
)
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
∗
(
x
)
+
f
∗
(
x
)
−
f
(
x
)
)
2
]
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
∗
(
x
)
)
2
+
(
f
∗
(
x
)
−
f
(
x
)
)
2
+
2
(
f
∗
(
x
)
−
f
(
x
)
)
(
y
−
f
∗
(
x
)
)
]
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
∗
(
x
)
)
2
+
(
f
∗
(
x
)
−
f
(
x
)
)
2
]
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
∗
(
x
)
)
2
]
+
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
f
∗
(
x
)
−
f
(
x
)
)
2
]
=
E
x
∼
p
r
(
x
)
[
E
y
∼
p
r
(
y
∣
x
)
[
(
y
−
f
∗
(
x
)
)
2
]
]
+
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
f
∗
(
x
)
−
f
(
x
)
)
2
]
=
E
x
∼
p
r
(
x
)
[
(
f
(
x
)
−
f
∗
(
x
)
)
2
]
+
ϵ
\begin{aligned} \mathcal{R}(f) &=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f^*(x)+f^*(x)-f(x))^2]\\ &=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f^*(x))^2+(f^*(x)-f(x))^2+2(f^*(x)-f(x))(y-f^*(x))]\\ &=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f^*(x))^2+(f^*(x)-f(x))^2]\\ &=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f^*(x))^2]+\mathbb{E}_{(x,y)\sim p_r(x,y)}[(f^*(x)-f(x))^2]\\ &=\mathbb{E}_{x\sim p_r(x)}[\mathbb{E}_{y\sim p_r(y\mid x)}[(y-f^*(x))^2]]+\mathbb{E}_{(x,y)\sim p_r(x,y)}[(f^*(x)-f(x))^2]\\ &=\mathbb{E}_{x\sim p_r(x)}[(f(x)-f^*(x))^2]+\epsilon \end{aligned}
R(f)=E(x,y)∼pr(x,y)[(y−f∗(x)+f∗(x)−f(x))2]=E(x,y)∼pr(x,y)[(y−f∗(x))2+(f∗(x)−f(x))2+2(f∗(x)−f(x))(y−f∗(x))]=E(x,y)∼pr(x,y)[(y−f∗(x))2+(f∗(x)−f(x))2]=E(x,y)∼pr(x,y)[(y−f∗(x))2]+E(x,y)∼pr(x,y)[(f∗(x)−f(x))2]=Ex∼pr(x)[Ey∼pr(y∣x)[(y−f∗(x))2]]+E(x,y)∼pr(x,y)[(f∗(x)−f(x))2]=Ex∼pr(x)[(f(x)−f∗(x))2]+ϵ
其中
(
y
−
f
∗
(
x
)
)
2
(y-f^*(x))^2
(y−f∗(x))2是模型与最优模型差的平方。
ϵ
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
∗
(
x
)
)
2
]
\epsilon=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f^*(x))^2]
ϵ=E(x,y)∼pr(x,y)[(y−f∗(x))2]表示包含噪声的样本中的
y
y
y与预测出的最优的
y
y
y的损失的期望,也就是期望风险中的噪声,有时候由于样本中的
y
y
y包含噪声从而导致
ϵ
\epsilon
ϵ过大,进一步导致期望风险过大,这样的情况是无法通过优化模型来降低的。
在实际训练一个模型时,不同的训练集会得到不同的模型,为了评价机器学习算法(包括模型以及优化算法)的能力,可以用不同训练集上的模型的平均性能评价。令
f
D
(
x
)
f_{\mathcal{D}}(x)
fD(x)表示在训练集
D
\mathcal{D}
D上学习到的模型,只看经验风险函数中跟模型有关的项(也就是暂时不看
ϵ
\epsilon
ϵ),对其期望风险进一步做与上面同样方式的配方:
E
D
[
(
f
D
(
x
)
−
f
∗
(
x
)
)
2
]
=
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
+
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
]
=
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
+
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
+
2
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
]
=
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
+
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
]
+
2
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
]
=
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
+
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
]
=
E
D
[
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
]
+
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
]
=
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
+
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
]
\begin{aligned} \mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-f^*(x))^2] &=\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]+\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2]\\ &=\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2+(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2\\ &\ \ \ \ +2(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))]\\ &=\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2+(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2]\\ &\ \ \ \ +2\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))]\\ &=\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2+(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2]\\ &=\mathbb{E}_{\mathcal{D}}[(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2]+\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2]\\ &=(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2+\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2]\\ \end{aligned}
ED[(fD(x)−f∗(x))2]=ED[(fD(x)−ED[fD(x)]+ED[fD(x)]−f∗(x))2]=ED[(fD(x)−ED[fD(x)])2+(ED[fD(x)]−f∗(x))2 +2(fD(x)−ED[fD(x)])(ED[fD(x)]−f∗(x))]=ED[(fD(x)−ED[fD(x)])2+(ED[fD(x)]−f∗(x))2] +2ED[(fD(x)−ED[fD(x)])(ED[fD(x)]−f∗(x))]=ED[(fD(x)−ED[fD(x)])2+(ED[fD(x)]−f∗(x))2]=ED[(ED[fD(x)]−f∗(x))2]+ED[(fD(x)−ED[fD(x)])2]=(ED[fD(x)]−f∗(x))2+ED[(fD(x)−ED[fD(x)])2]
其中,前项
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2
(ED[fD(x)]−f∗(x))2叫做偏差(bias),记作
(
b
i
a
s
.
x
)
2
(bias.x)^2
(bias.x)2,表示训练集上模型的期望(模型预测值
y
y
y在数据集上的平均水平)与最优模型期望(数据集上真实值
y
y
y的平均水平)之间的偏差,也就是模型的预测值与训练集上的真实值之间的差距。
后项
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
]
\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2]
ED[(fD(x)−ED[fD(x)])2]叫做方差(variance),记作
v
a
r
i
a
n
c
e
.
x
variance.x
variance.x,表示训练集上给定
x
x
x模型的预测值与模型的期望之间的偏差,模型的期望表示预测的平均值,与数据集
D
\mathcal{D}
D有关但与给定的
x
x
x无关,是个定值,因此方差实际上表示预测模型不同
x
x
x取值下对应
y
y
y的预测值与数据集上
y
y
y的平均值之间的差异,也就是在该模型下预测值的波动程度。
最后,给出经过偏差-方差分解后完整的期望风险:
R
(
f
)
=
(
b
i
a
s
)
2
+
v
a
r
i
a
n
c
e
+
ϵ
(
b
i
a
s
)
2
=
(
E
D
[
f
D
(
x
)
]
−
f
∗
(
x
)
)
2
v
a
r
i
a
n
c
e
=
E
D
[
(
f
D
(
x
)
−
E
D
[
f
D
(
x
)
]
)
2
]
ϵ
=
E
(
x
,
y
)
∼
p
r
(
x
,
y
)
[
(
y
−
f
∗
(
x
)
)
2
]
\begin{aligned} \mathcal{R}(f)&=(bias)^2+variance+\epsilon\\ (bias)^2&=(\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)]-f^*(x))^2\\ variance&=\mathbb{E}_{\mathcal{D}}[(f_{\mathcal{D}}(x)-\mathbb{E}_{\mathcal{D}}[f_{\mathcal{D}}(x)])^2]\\ \epsilon&=\mathbb{E}_{(x,y)\sim p_r(x,y)}[(y-f^*(x))^2] \end{aligned}
R(f)(bias)2varianceϵ=(bias)2+variance+ϵ=(ED[fD(x)]−f∗(x))2=ED[(fD(x)−ED[fD(x)])2]=E(x,y)∼pr(x,y)[(y−f∗(x))2]
在经过上述分解后,在对模型进行选择时,就可以根据偏差和方差来选择最合适的模型。根据不同情况,可以将机器学习模型分为:
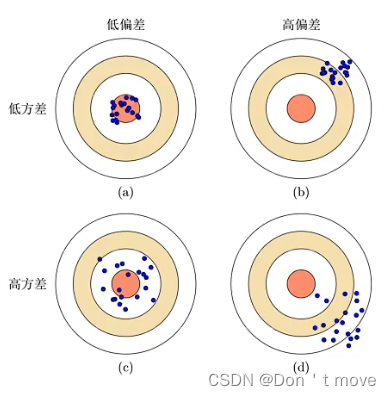
- 低偏差、低方差:模型预测值与真实值相差较小且模型预测值波动幅度不大,是理想的模型
- 高偏差、低方差:模型预测值与真实值相差较大,模型在训练集上预测能力较差,而模型预测值之间的波动幅度较小,模型能力较弱,发生欠拟合现象。
- 低偏差、高方差:模型预测值与真实值相差较小,模型在训练集上预测能力较好,而模型预测值之间的波动幅度较大,模型能力较强,发生过拟合现象。
- 高偏差、高方差:模型预测值与真实值相差较大,模型在训练集上预测能力较差,且模型预测值之间的波动幅度较大,模型能力较强但预测能力差。
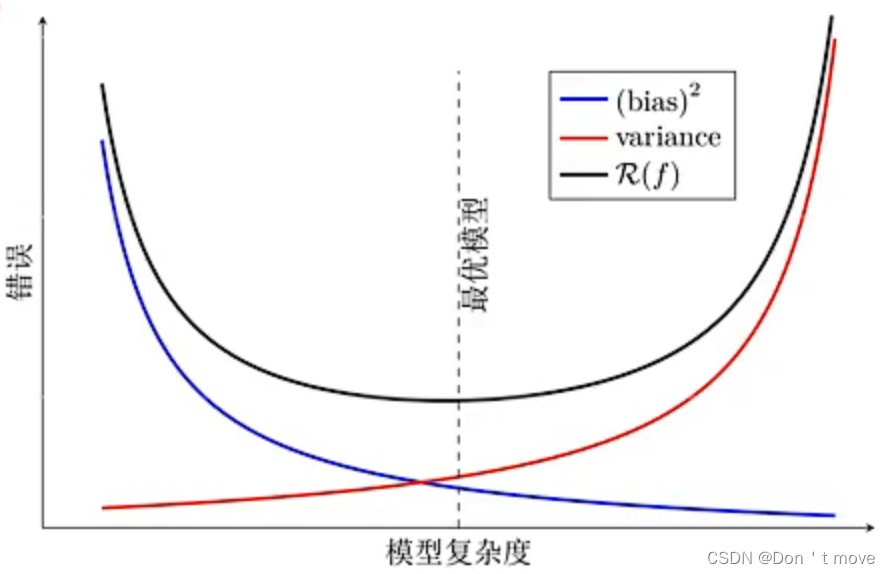
因此,期望风险最小化等价于方差和偏差的最小化。如下图所示,一般来说,随着模型复杂度的增加,模型的偏差会逐渐减小(在训练集上的预测能力增强)、方差会逐渐增大(模型预测的波动增大),若要期望风险最小,就需要取得一个合适的模型,使得二者的和最小。
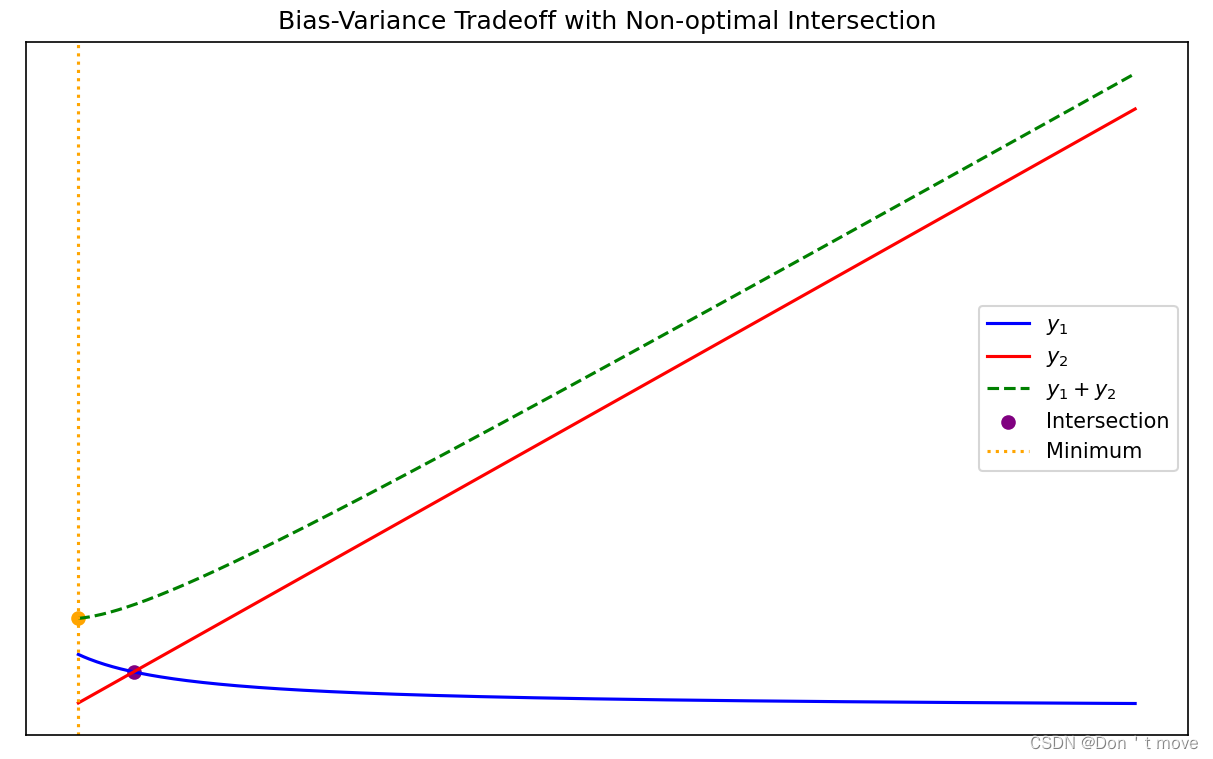
此外还要注意,两曲线的交点不一定是函数最小值点,不知道怎么解释,但是举个反例:
y
1
=
1
x
+
1
y
2
=
x
y
1
+
y
2
=
1
x
+
1
+
x
\begin{aligned} y_1&=\frac{1}{x+1}\\ y_2&=x\\ y_1+y_2&=\frac{1}{x+1}+x \end{aligned}
y1y2y1+y2=x+11=x=x+11+x
图像如下
















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











