







余数
10%%3
商
10%/%3
10/3


关系运算
identical(2^3,2**3)

变量赋值
x<-1.5
x

类
class(sqrt(1:10))
ls(pattern="^is",baseenv())

检查变量:print,summary,head,str,unclass,attributes,view
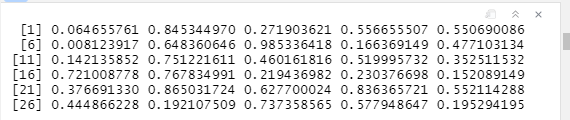
均匀分布的30个随机数
num<-runif(30)
概述性描述
summary(num)

因子,分类变量
fac<-factor(sample(letters[1:5],30,replace=T))
fac

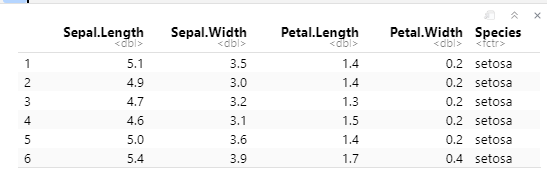
数据集,查询前六行表头(是表格)
dfr<-iris
head(dfr)
描述性统计:分类型自动频数分布
summary(dfr)

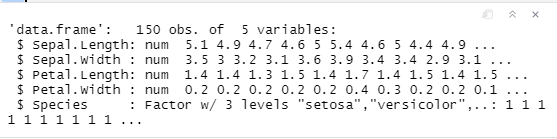
structure
str(num)

structure:obs表示observation观测值的个数,150次观测,每次5个变量。给出大概的结构。
str(dfr)
去掉类别:unclass
factor 会把字符串用数字的形式进行存储
unclass返回到了存储形式
fac
print("*****")
unclass(fac)

属性
attributes(fac)

view:比print更加高级一点
print(num)
View(num)
工作区:global environment
查看工作区变量ls()
删除工作区变量rm()
garbage colect
ls()
#rm(list=ls())删除掉所有变量,但是并没有真正的删除,通过gc()删除标注为不在需要的变量。相当于在Windows中,用rm()删除了文件,gc()清空回收站。

向量:首尾都能取到
8.5:4.5

c(1,1:3,c(56,9),1)
创建vector:
vector('numeric',5)

vector('logical',5)
注意是单引号
vector('character',5)

vector('list',5 )

对于较大的数据时候,尽量先初始化,不要动态的创建
numeric(5)# 初始化
创建序列seq
seq.int(3,12)

seq.int(3,12,2)
seq.int(0.1,0.01,-0.01)

特例
n<-0
1:n
1:1
seq_len(n)#生成一个长度为n的序列,从0开始
seq_len(10)

seq_along:得到位置号
pp<-c('peter','piper')
seq_along(pp)
for(i in seq_along(pp)) print(pp[i])
向量的长度
length(1:5)
length(c(T,F,NA))#缺失值仍是占有空间的所以结果为3,而不是2

字符串向量
sn<-c('sehee','djife')
length(sn)#字符串向量长度
nchar(sn)#字符串长度,得到的结果是每个位置上的字符串有多少个字符,返回形式是向量。
改变向量长度的后果
poincare<-c(1,0,0,0,2)
length(poincare)<-3#改变长度,直接截取前三个
poincare
length(poincare)<-5
poincare#恢复长度后,用na填补

向量元素的命名
c(apple=1,banana=2,'kiwi fruit'=3,4)
#c生成向量,数值有名字,有空格就需要引号,第四个值得名字是4
x<-1:4
names(x)
names(x)<-c('apple','banana','kiwi fruit','')
names(x)
names(1:4)#直接创建向量是没有名字的

向量的索引:
索引:访问向量中部分或者个别元素(子集,下标,切片)
x<-(1:5)^2
x
x[c(1,3,5)]#索引以1开始,与Python从0开始不同
x[c(-2,-4)]#删除第二个和第四个数后的结果进行显示
x[c(T,F,T,F,T)]#逻辑向量进行索引,F位置上的不显示
x

names(x)<-c('a','b','c','d','e')#给每个位置命名方便后续索引操作
x[c('a')]
c错误示范
x[c(-1,1)]
x[c(1,NA,5)]

错误示范
x[c(-2,NA)]
允许越界,结果是na
x[6]

非整数索引
x<-1:10
x[1.9]
which函数
which(x>8)
which.min(x)#最小值在哪里,给出位置
which.max(x)

向量循环和重复
#r语言会自动对参与运算的向量自动匹配
1:5+1
1:5+1:15
1:5+1:7#给出警告,因为长的和短的不是整数倍的关系

rep函数:广播机制
将一个向量重复一定的次数repeat,可以用于做初始化,很方便
rep(1:5,3)
rep(1:5,each=3)
rep(1:5,times=1:5)
rep(1:5,length.out=7)
rep.int(1:5,3)
rep_len(1:5,13)

矩阵和数组
dim=c(行,列,页面)
#array函数
three_d_array<-array(1:24,dim=c(4,3,2),dimnames=list(c('one','two','three','four'),c('ein','zwei','drei'),c('un','duex')))
three_d_array
class(three_d_array)

a_matrix<-matrix(1:12,nrow=4,dimnames=list(c('one','two','three','four'),c('ein','zwei','drei')))
a_matrix
class(a_matrix)
two_d_matrix<-array(1:12,dim=c(4,3),dimnames=list(c('one','two','three','four'),c('ein','zwei','drei')))
two_d_matrix
class(two_d_matrix)

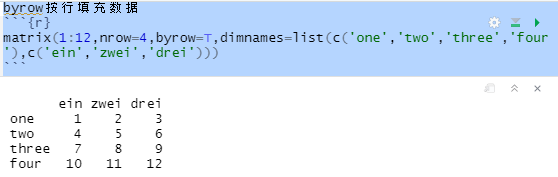
byrow按行填充数据
matrix(1:12,nrow=4,byrow=T,dimnames=list(c('one','two','three','four'),c('ein','zwei','drei')))
行列和维度
dim(three_d_array)
dim(a_matrix)
nrow(a_matrix)
nrow(a_matrix)
ncol(three_d_array)
length(three_d_array)
length(a_matrix)

plot(cars)
















 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









