






在命名实体识别(NER)和其他信息抽取任务中,如何利用语言特征(如词性标注或分块)来提高性能。
-
背景介绍:
- 在命名实体识别(NER)和其他信息抽取任务中,通常会使用一些语言特征(如词性标注或分块)。
- 对于那些文本中词边界不易识别的语言(如中文),词语分割是生成NER系统特征的关键第一步。
- 虽然使用词边界标记作为特征有帮助,但那些有助于识别这些边界的信号可能为NER系统提供更丰富的信息。
-
新方法:
- 最新的词语分割系统使用神经模型来学习表示,以预测词边界。
- 研究显示,这些用于预测词边界的表示,若与NER系统联合训练,可以显著提高NER的性能。
-
实验结果:
- 在实验中,使用LSTM-CRF模型联合训练NER和词语分割,在中文社交媒体上取得了显著的效果。
- 与之前发表的结果相比,联合训练方法带来了近5%的绝对提升。
简而言之,这段文字的意思是通过将词语分割和NER任务联合训练,可以显著改善NER系统的性能,特别是在中文社交媒体的文本处理中。具体来说,使用神经网络模型来同时学习词边界和命名实体,可以提供更丰富的信息,从而提高NER的效果。
内容和意义:
-
研究目标:
- 研究如何更好地将词边界信息整合到中文社交媒体的NER系统中。
-
方法介绍:
- 结合了最先进的中文分词系统(Chen等,2015)和最好的中文社交媒体NER模型(Peng和Dredze,2015)。
- 由于这两个系统都使用了学习到的表示(learned representations),作者提出了一种集成模型,允许对学习到的表示进行联合训练。
-
创新点:
- 与基于分词输出的特征相比,联合训练可以为NER系统提供更多关于从分词中学习到的隐藏表示的信息。
-
实验结果:
- 作者的集成模型在中文社交媒体的NER和名词提及(nominal mentions)任务上,较之前最好的结果实现了近5%的绝对提升。
简而言之,这段文字的意思是通过将最先进的中文分词系统和中文社交媒体NER模型进行整合,并对它们的学习表示进行联合训练,可以显著提升NER系统的性能,尤其是在中文社交媒体文本处理方面。这种联合训练方法提供了比传统的基于分词输出特征的方法更多的有用信息,从而取得了近5%的性能提升。
在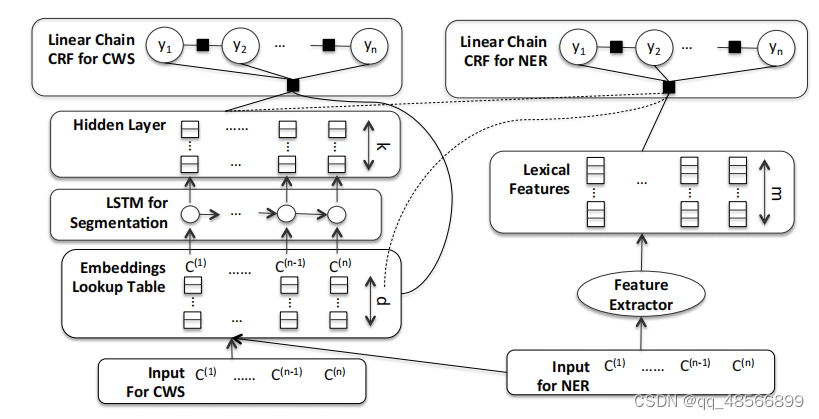
-
模型结构:
- 左侧:LSTM模块用于词语分割。
- 右侧:传统的基于特征的CRF模型用于NER。
-
CRF模型的特点:
- 用于NER的线性链CRF(linear chain CRF)不仅可以访问专门用于NER的特征提取器,还可以访问由LSTM模块为词语分割生成的表示。
- 这种CRF是一个对数双线性CRF(log-bilinear CRF),它将嵌入表示和隐藏向量输入视为变量,并根据目标函数对其进行调整。
-
联合训练的机制:
- 通过这种设计,可以将梯度传播回LSTM,以调整LSTM的参数。
- 因此,词语分割和NER训练共享LSTM模块的所有参数,从而实现联合训练。
简而言之,这段文字的意思是描述了一个联合模型的结构,该模型通过共享LSTM模块的参数实现中文分词和NER任务的联合训练。左侧的LSTM模块处理词语分割任务,右侧的CRF模型处理NER任务,并且可以访问LSTM生成的表示。CRF模型使用对数双线性方法,将输入的嵌入表示和隐藏向量视为变量,并根据目标函数进行调整,从而使梯度可以传播回LSTM模块,实现参数共享和联合训练。这样设计的目的是通过联合训练来提高两个任务的性能。















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









