






 LayoutLM模型系列从v1到v2增加了对图像信息的处理,通过2-Dpositionembedding结合OCR实现文本和布局的对齐。LayoutLMv2引入了空间感知自注意力及图像编码器,强化了文本、布局和图像三者之间的交互,适用于实体抽取、文档分类和文档问答等任务。
LayoutLM模型系列从v1到v2增加了对图像信息的处理,通过2-Dpositionembedding结合OCR实现文本和布局的对齐。LayoutLMv2引入了空间感知自注意力及图像编码器,强化了文本、布局和图像三者之间的交互,适用于实体抽取、文档分类和文档问答等任务。
LayoutLMv1、Mv2
一、LayoutLMv1
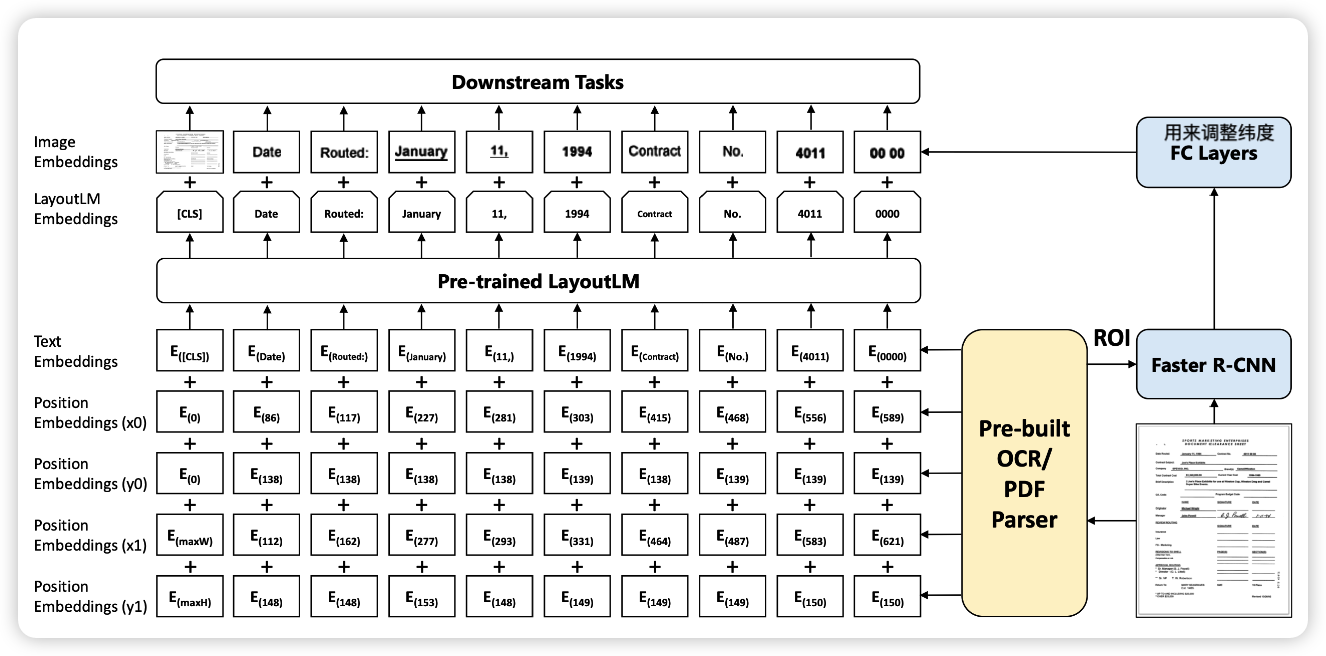
- LayoutLM任务是对现有的语言类与训练模型做了一个扩展,基于BERT的基础在与训练阶段对Embedding加入了一个2-D position embedding:
- 将文档通过OCR后,对文档建立坐标,以OCR结果的左上角作为坐标原点如下图

那么就可以获取OCR后的文本的位置,那么这些位置信息可以通过embedding的方式转化成position信息,然后加在text embedding上,然后传入transform,通过transform的上下文化的能力让模型能感知这个文本的位置,得到文本上下文和布局上下文的信息。
- 将文档通过OCR后,对文档建立坐标,以OCR结果的左上角作为坐标原点如下图
- 但是通过Faster R-CNN的ROI得到的图像信息并没有参与与训练中,这样视觉领域事实上没有在预训练上被学习到,导致模型在预训练阶段并没有接触到图像的上下文信息
二、LayoutLMv2
结构
-
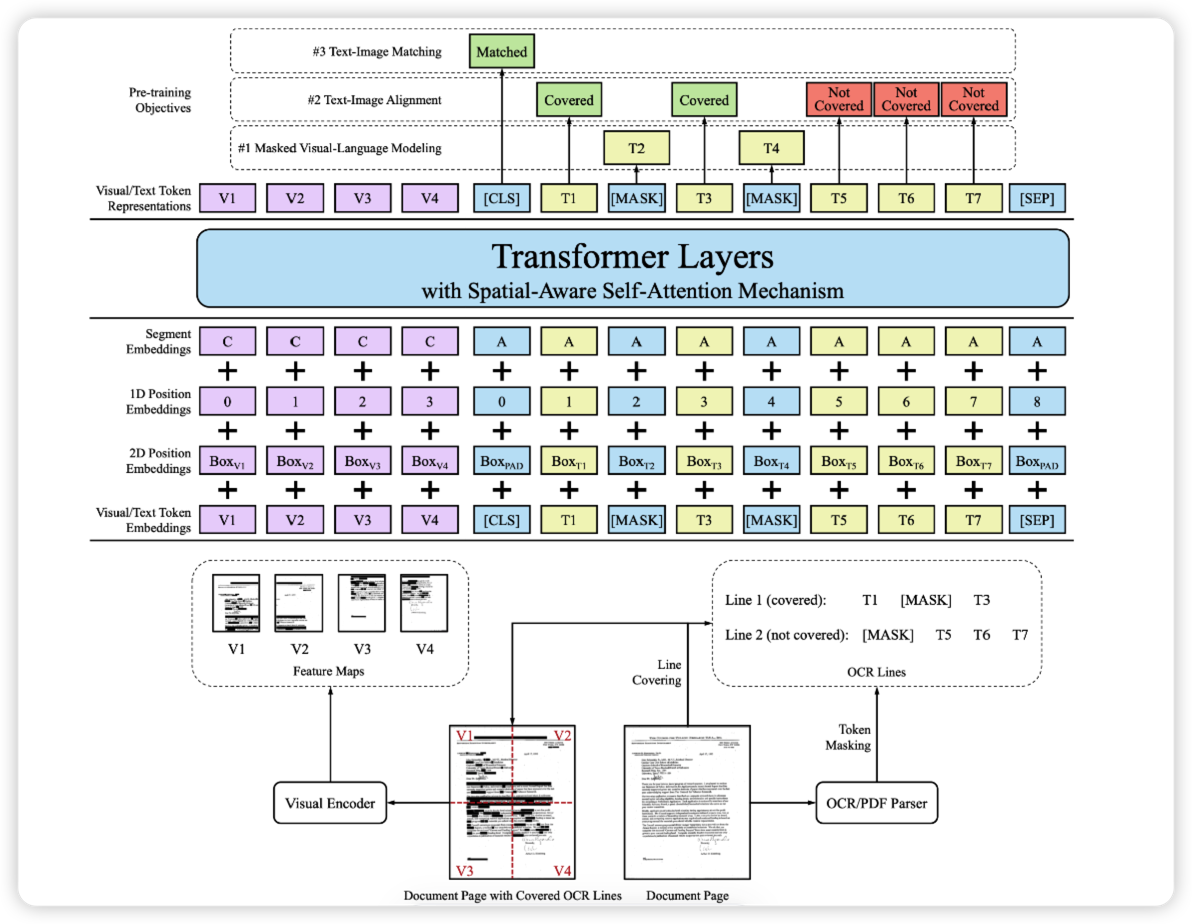
v2版本加入了3个模态的输入,还加入了论文给出的Spatital-Aware Self-Attention(空间感知的自注意力机制)。
并且将与训练的内容运用于3个下游任务:Entity Extraction Tasks、RVL-CDIP、DocVQA。I 图像编码器
- 图像的token是通过给定一个Document Page image传入到Visual Encoder中,采用的是ResNet的图像的编码器。通过图像编码器获得一个7*7的Fature Map,然后通过Flatten操作展平成1*49的序列,上图是把文档图片分成了4个visual token,但实际上会分成7*7个visual token,然后会加上language的512个token。
II 组合以及位置信息
- 通过相加的形式将visual token和text token(通过OCR得来),

就可以把那个坐标信息以2-D embedding的形式加在文本上,同时visual token也是有position信息的,图像的position是可以根据页面的大小进行缩放的
III Transform

原本的编码器采用的是self-attention,但根据这个position的特点,引入空间特征进入self-attention:- X序列是来自transform中间层的信息组成的序列,z序列就是经过self-Attention编码后的序列
- 采用一个相似度的方式来让每个x经过编码后让每个token感知到上下文的信息
- 但是这样还是缺少空间信息,那么就加入了以个bias,为了去表达1维的空间信息,不过以为本文以2-D position,所以引入了x和y两个维度的信息
IIII 预训练任务
-
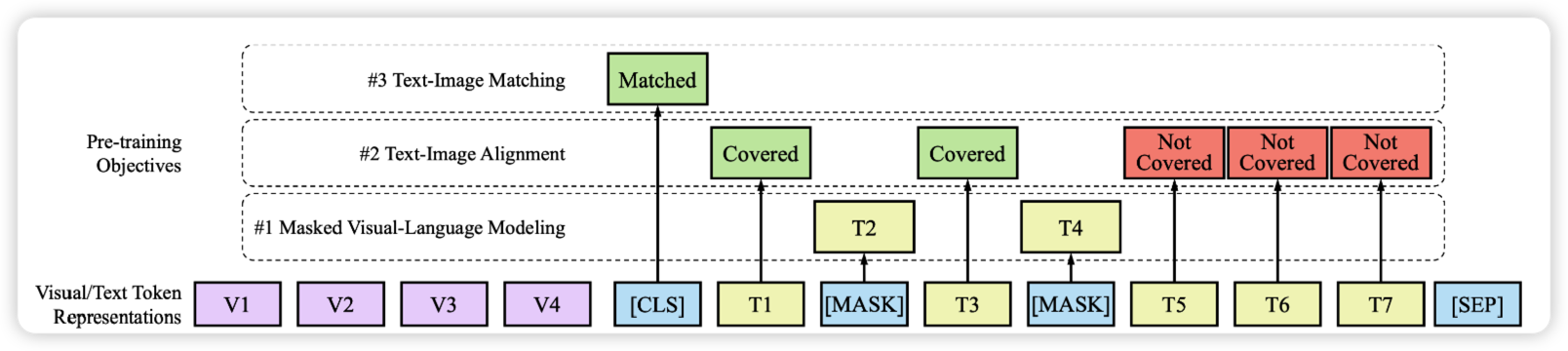
这个模型的预训练的主要任务主要要做的事三个模态的对齐-
MVLM就是layoutLMv1提出的内容,就是对文本做mask掩码,但是会保留本文在文档中的位置信息,这样有了空间位置的暗示,就可以通过position embedding的暗示进行上下文的学习,实现了文本和布局的对齐
-
TIA文本-图像对齐,在文本图像中随机挑选一行进行遮盖,用[covered]来表示,保留文本信息,然后在文本段预测是否有被covered,做一个0/1的二分类,利用2-D position和Spatial-Aware Self-Attention来学习,通过被covered的文本和实际的文本来做一些预测,就能做到在这两个模态对齐
-
TIM文本-图像匹配任务,让模型学习文本是否来自这个图像
-
实验
预训练
Entity Extraction Tasks

数据集来自IIT-CDIP# LayoutLMv1、Mv2
一、LayoutLMv1
- LayoutLM任务是对现有的语言类与训练模型做了一个扩展,基于BERT的基础在与训练阶段对Embedding加入了一个2-D position embedding:
- 将文档通过OCR后,对文档建立坐标,以OCR结果的左上角作为坐标原点如下图
那么就可以获取OCR后的文本的位置,那么这些位置信息可以通过embedding的方式转化成position信息,然后加在text embedding上,然后传入transform,通过transform的上下文化的能力让模型能感知这个文本的位置,得到文本上下文和布局上下文的信息。
- 将文档通过OCR后,对文档建立坐标,以OCR结果的左上角作为坐标原点如下图
- 但是通过Faster R-CNN的ROI得到的图像信息并没有参与与训练中,这样视觉领域事实上没有在预训练上被学习到,导致模型在预训练阶段并没有接触到图像的上下文信息
二、LayoutLMv2
结构
-
v2版本加入了3个模态的输入,还加入了论文给出的Spatital-Aware Self-Attention(空间感知的自注意力机制)。
并且将与训练的内容运用于3个下游任务:Entity Extraction Tasks、RVL-CDIP、DocVQA。I 图像编码器
- 图像的token是通过给定一个Document Page image传入到Visual Encoder中,采用的是ResNet的图像的编码器。通过图像编码器获得一个7*7的Fature Map,然后通过Flatten操作展平成1*49的序列,上图是把文档图片分成了4个visual token,但实际上会分成7*7个visual token,然后会加上language的512个token。
II 组合以及位置信息
- 通过相加的形式将visual token和text token(通过OCR得来),
就可以把那个坐标信息以2-D embedding的形式加在文本上,同时visual token也是有position信息的,图像的position是可以根据页面的大小进行缩放的
III Transform
原本的编码器采用的是self-attention,但根据这个position的特点,引入空间特征进入self-attention:- X序列是来自transform中间层的信息组成的序列,z序列就是经过self-Attention编码后的序列
- 采用一个相似度的方式来让每个x经过编码后让每个token感知到上下文的信息
- 但是这样还是缺少空间信息,那么就加入了以个bias,为了去表达1维的空间信息,不过以为本文以2-D position,所以引入了x和y两个维度的信息
IIII 预训练任务
-
这个模型的预训练的主要任务主要要做的事三个模态的对齐-
MVLM就是layoutLMv1提出的内容,就是对文本做mask掩码,但是会保留本文在文档中的位置信息,这样有了空间位置的暗示,就可以通过position embedding的暗示进行上下文的学习,实现了文本和布局的对齐
-
TIA文本-图像对齐,在文本图像中随机挑选一行进行遮盖,用[covered]来表示,保留文本信息,然后在文本段预测是否有被covered,做一个0/1的二分类,利用2-D position和Spatial-Aware Self-Attention来学习,通过被covered的文本和实际的文本来做一些预测,就能做到在这两个模态对齐
-
TIM文本-图像匹配任务,让模型学习文本是否来自这个图像
-
实验
预训练
Entity Extraction Tasks
数据集来自IIT-CDIP
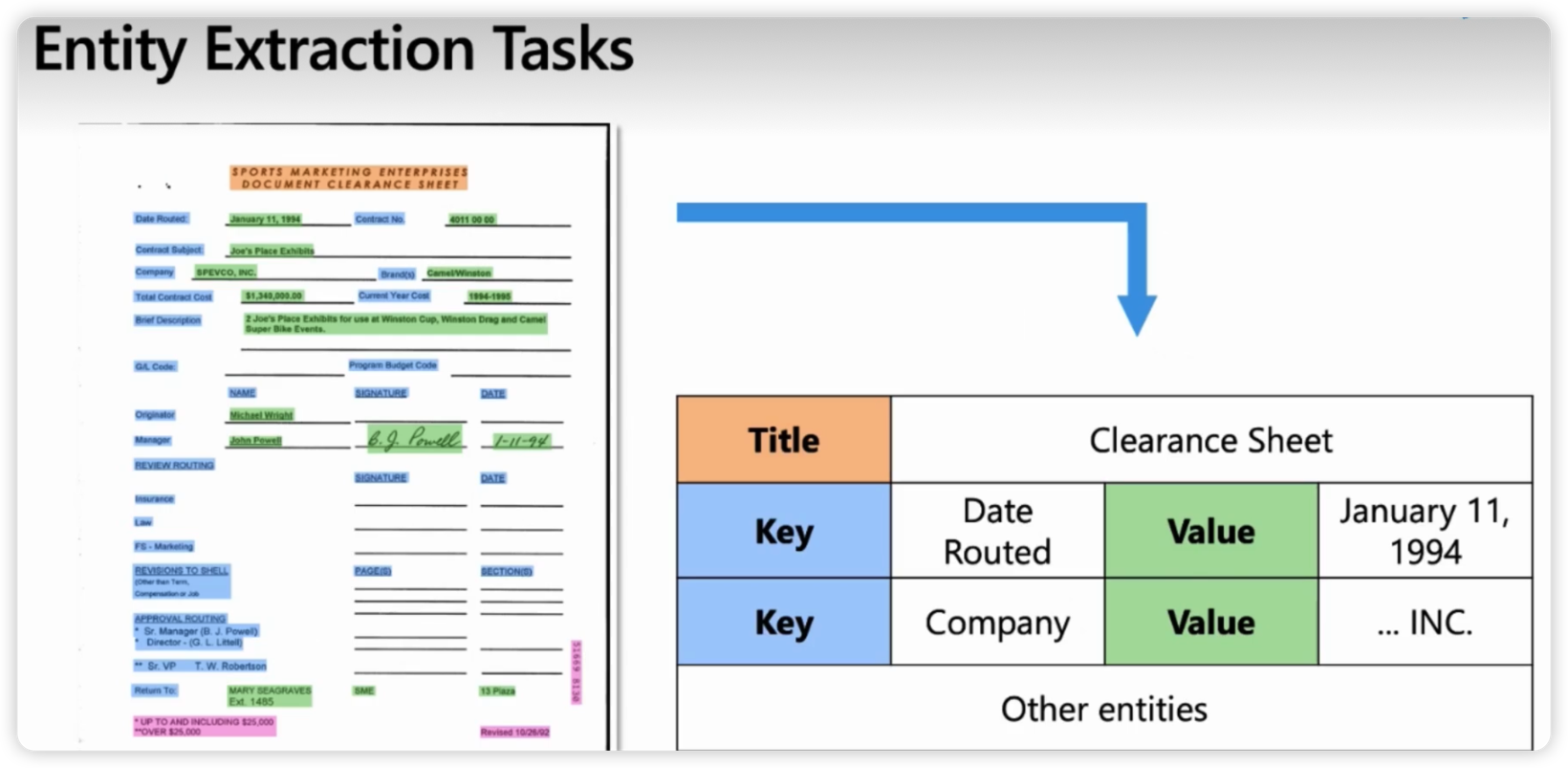
实体抽取,抽取出键值对
Document Image Classification

数据集来自RVL-CDIP
VQA on Document Images:
数据集来自DocVQA
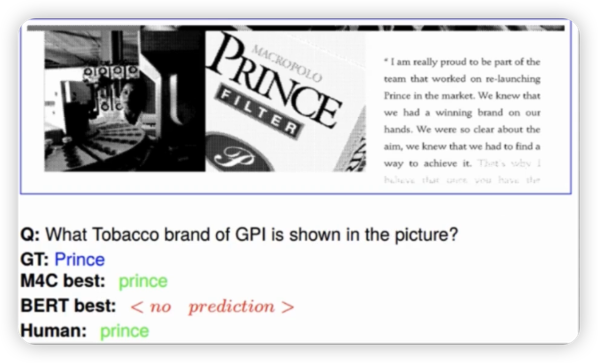
文档问答,给出图像再给出文档,然后针对问题进行回答
实体抽取,抽取出键值对
Document Image Classification
数据集来自RVL-CDIP
VQA on Document Images:
数据集来自DocVQA
文档问答,给出图像再给出文档,然后针对问题进行回答


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









