






 论文提出Negative-AwareAttentionFramework(NAAF),关注图像文本匹配中的不匹配片段,通过迭代优化和双分支匹配机制,利用不匹配的消极影响和匹配的积极影响,提高匹配的准确性和鲁棒性。
论文提出Negative-AwareAttentionFramework(NAAF),关注图像文本匹配中的不匹配片段,通过迭代优化和双分支匹配机制,利用不匹配的消极影响和匹配的积极影响,提高匹配的准确性和鲁棒性。
Negative-Aware Attention Framework for Image-Text Matching
发表于IEEE/CVF 2022
团队:University of Science and Technology of China
Abstract
Image-text matching就在于准确测量这两种模式之间的相似性。论文认为,不匹配的文本片段,也包含着丰富的不匹配线索,对于图像文本匹配有着重要作用,于是提出了Negative-Aware Attention Framework,利用匹配片段的积极作用和不匹配片段的消极作用来共同推断图文匹配的相似度。
以往的工作主要是基于匹配片段(即具有高相关性的词/区域),而低估甚至忽略了不匹配的片段(即具有低相关性的词/区域)的影响,例如,通过典型的LeaklyReLU或ReLU操作,迫使负分接近或精确到零。
NAAF (1) 设计了一个迭代优化方法,以最大限度地挖掘不匹配的片段,促进更多的歧视性和稳健的负面效应;(2) 设计了双分支匹配机制,以精确计算具有不同掩码的匹配/不匹配片段的相似度/相似度。
Conclusion
论文提出了一个负向感知的注意力框架用于image-text matching。不同于传统注意力的是该方法可以同时关注不匹配和匹配的片段;通过构建了一个迭代优化,挖掘出负面的不匹配片段,产生具有鉴别力和稳健的负面效应,用双分支匹配机制能攻分别测量准确的相似度或不相似度,从而推断出整体的image-text相似度。
Introduction
这种匹配任务的目的是搜索图像的文字描述,或找到与图像查询相关的文字。图像-文本匹配的关键挑战在语义对应关系,以衡量它们的相似性。
在现有的图像-文本匹配方法中,有两种范式:
- 第一种倾向于进行全局层面的匹配,即寻找全文和整个图像之间的语义对应。他们通常将整体图像和文本投射到一个共同的潜在空间,然后将两种模式进行匹配。
- 第二种范式侧重于研究局部水平的匹配,即图像中的突出区域和文本中的词语之间的匹配。局部层面的匹配考虑到了图像和文本之间细粒度的语义对应关系。
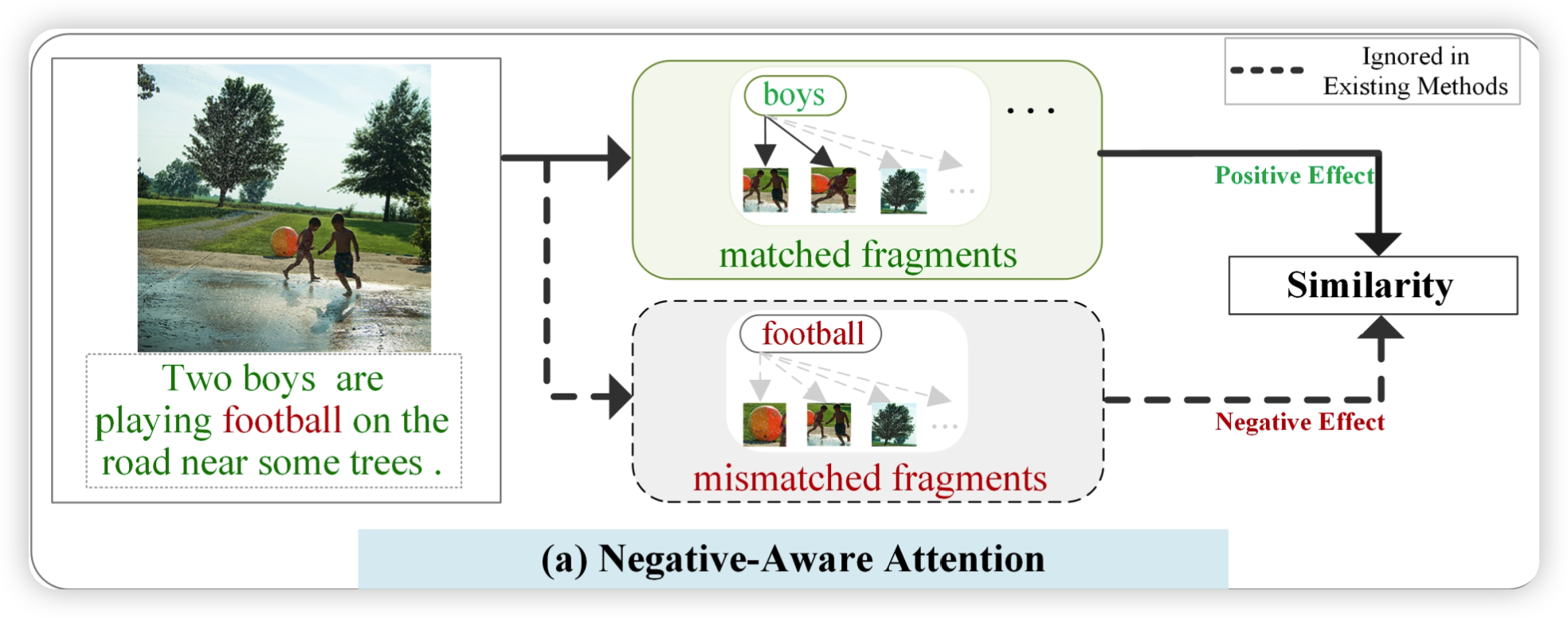
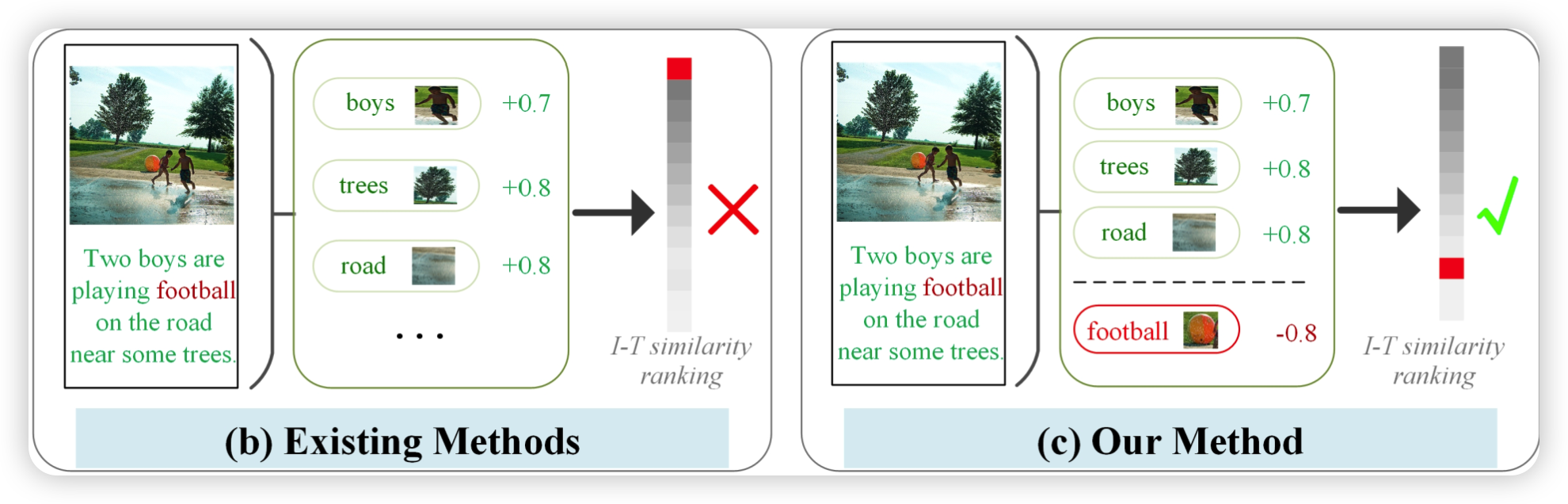 这里说的大概是:
这里说的大概是:
例a中说利用的是“男孩”、“树”等文字来匹配的图像,而football被典型LeaklyReLU或ReLU弱化或忽略了。
例b中说先有方法存在flase- positive(这里指的是漏报,把正确的例子归于错误的)的情况时仍然可以获得一个高的相似度。
例c中说在论文的模型中不匹配的和匹配的片段都会被挖掘出来,并且分别会产生正面和负面影响,让flase-positive也会对最后的相似度起到影响效果。
现有方法都忽略了不匹配的文本片段,因为它们描述的内容不在图像中。但是图像通常包含更多的背景对象区域,因此我们主要关注不匹配的文本片段,即单词。
由于现有的匹配方法都是寻找匹配上的片段而忽略不匹配片段的影响。所以就会出现正类样本被归到负类(图像中有的东西文本中也出现了,但是就是没有作为最终相似度计算的一部分)。
所以作者认为一个合理的匹配框架应该同时考虑两个方面,即一个图像-文本对的整体匹配分数不仅由匹配片段的积极影响决定,而且由不匹配片段的消极影响决定(例如,图像中没有提到的词可能会降低整体匹配分数)。
作者提出的negative-aware attention framework 与传统的匹配机制不同机,egative-aware attention framework可以有效地挖掘不匹配的文本片段,并利用它们来准确反映两种模式的不相似程度。
1)不匹配挖掘模块:通过建模匹配片段和不匹配片段的相似度分布,然后通过优化两个分布的最小错分概率求解最优的相似度区分阈值,从而尽可能的区分不匹配片段。**2)正负双分支匹配模块:**通过两种不同的掩码注意力机制,一方面关注匹配片段的相似度,另一方面精确计算不匹配片段的不相似度,联合利用前者的正面作用和后者的负面作用进行图像和文本之间的跨模态语义关联衡量。
基于不匹配和匹配片段的相似度分布,首先通过最小化训练过程中匹配和不匹配相似性分布之间错误重叠的惩罚概率,自适应地学习它们之间的最佳决策边界,这在理论上可以保证挖掘的准确性。然后,学习到的边界被整合到注意力匹配过程中,以优化更具判别力的相似度分布。这样的迭代优化将这两类分布强行分开,尽可能使不匹配的文本片段得到最大程度的挖掘。通过这种方式,NAAF不仅关注匹配的片段,而且还能在不同的模式中分辨出细微的不匹配的片段,以实现更准确的 图像-文本匹配。
Method
符号表示,text-image pair用(U,V)表示,其单词的文本特征用U={ui|i∈ [1, m],ui ∈ Rd}表示(ui应该代表的是每个单词的特征),图像区域的视觉特征用V={vj|j ∈ [1, n],vj ∈ Rd}表示。m和n分别表示词和区域的数量;d表示特征维度
Negative-aware Attention
NAAF中的两个模块:
- 判别性错配挖掘,旨在明确建模并最大限度地挖掘错配片段,通过在训练过程中最小化正确匹配和不匹配相似度分布之间的错误重叠的惩罚概率;
- 正-负分支匹配,目的是精确计算消极不匹配和积极匹配对通过设计的双分支匹配共同推断相似性的影响,即负面和正面的注意力分支。
作者希望能对不匹配和匹配片段的相似性分布进行明确和适应性的建模,旨在最大限度地分离它们,以实现有效的不匹配片段的挖掘。
在训练过程中,对于不匹配和匹配的单词区域片段对,首先对它们的相似度进行采样

S-表示不匹配区域-单词的相似度分数,S+表示匹配区域-单词的相似度分数。
基于构造出的两个集合,可以分别建立匹配片段和不匹配片段的相似度分数s的概率分布模型:
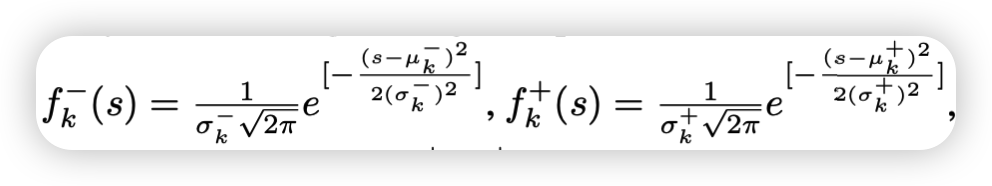
但是为什么是高斯分布?
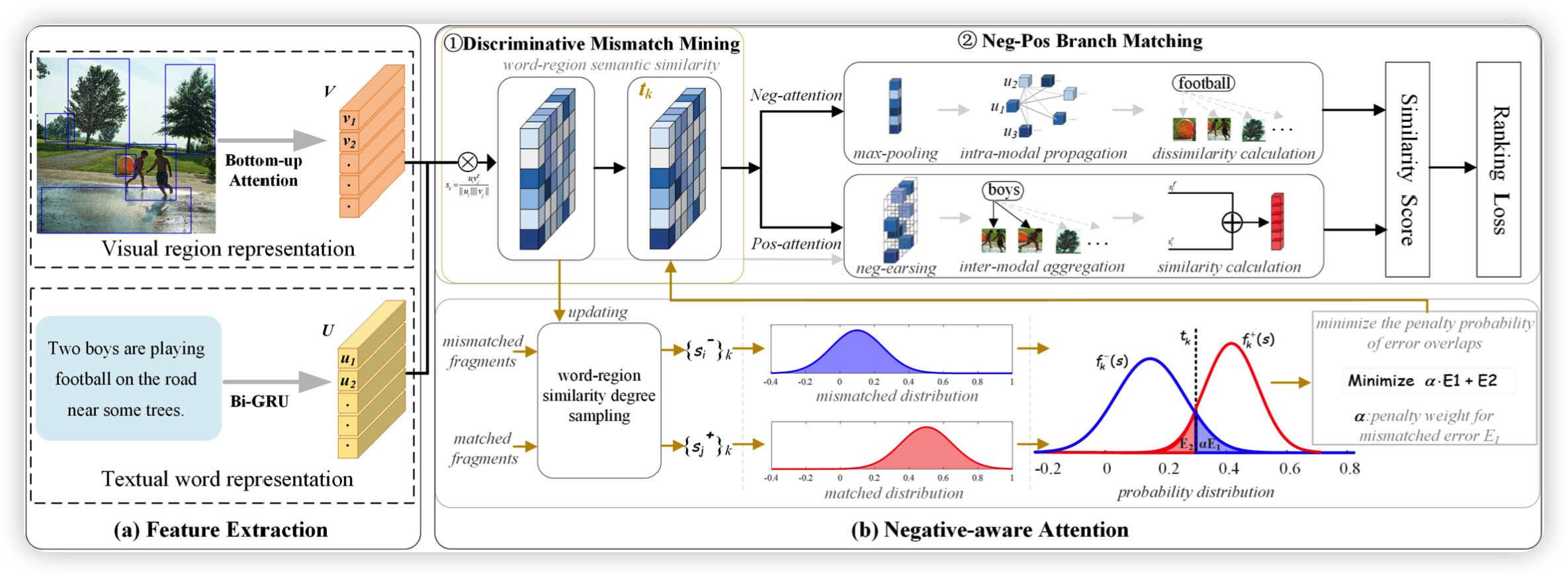 所提出的框架NAAF的概述,包含两个主要模块,用于明确利用消极不匹配和积极匹配的文本片段来共同推断图像-文本相似性。 鉴别性的错配挖掘,主要是将错配片段的相似性分布与匹配的片段最大限度地分开,同时也学习这两种分布之间的适应性边界,使错配线索产生更强的负面效应。Neg-Pos分支匹配引入不同的掩码,精确计算两类片段的正面和负面效应,以衡量整体相似度。
所提出的框架NAAF的概述,包含两个主要模块,用于明确利用消极不匹配和积极匹配的文本片段来共同推断图像-文本相似性。 鉴别性的错配挖掘,主要是将错配片段的相似性分布与匹配的片段最大限度地分开,同时也学习这两种分布之间的适应性边界,使错配线索产生更强的负面效应。Neg-Pos分支匹配引入不同的掩码,精确计算两类片段的正面和负面效应,以衡量整体相似度。
分别得到两个相似度分布建模后,可以用一个显式的边界t在匹配片段和不匹配片段之间进行区分,如图所示,相似度分数大于决策线tk的区域-单词对被视为匹配片段,反之则为不匹配片段,但是不可避免的就会出现两种误判:将实际上不匹配的片段区分为匹配的(如图中的E1) 和 将实际上匹配的片段误认为是不匹配的(如图中的E2)。而此模块的目的是最大限度的挖掘出不匹配片段,找出一个最优的边界t,使得区分错误的概率最低,保证识别的准确性,那么就把照决策面的问题转化成求minimize(E1+E2)的问题了。
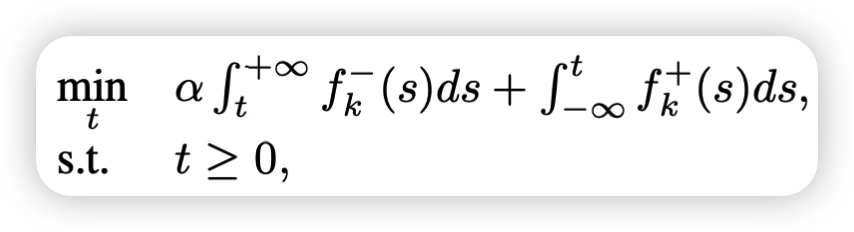
α是区分不匹配片段错误的惩罚参数;
为了求上面公式的最小值,可以通过计算其一阶导数等于0时候的取值, 求t大于0的那一部分,并且用[·]+ ≡ max(·, 0)来过滤。其中β应该是每个导数的部分,
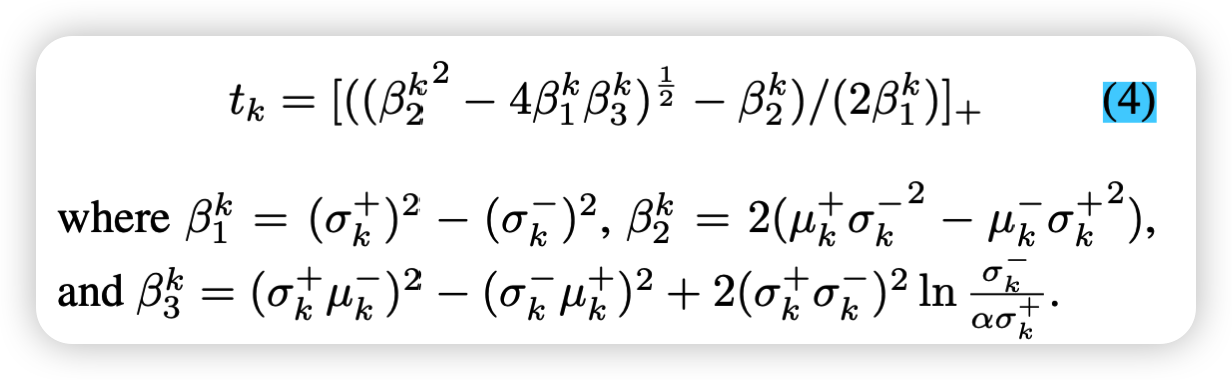
1)从不匹配和匹配的相似性分布中学习边界tk,然后整合到注意力机制中,进行迭代优化,来调整更多的相似性分布,这样就可以最大程度的从匹配片段中把不匹配片段从分布中分离出来,就能够更好的计算负面效应。2)为了有更好的效果需要设置一个惩罚参数 α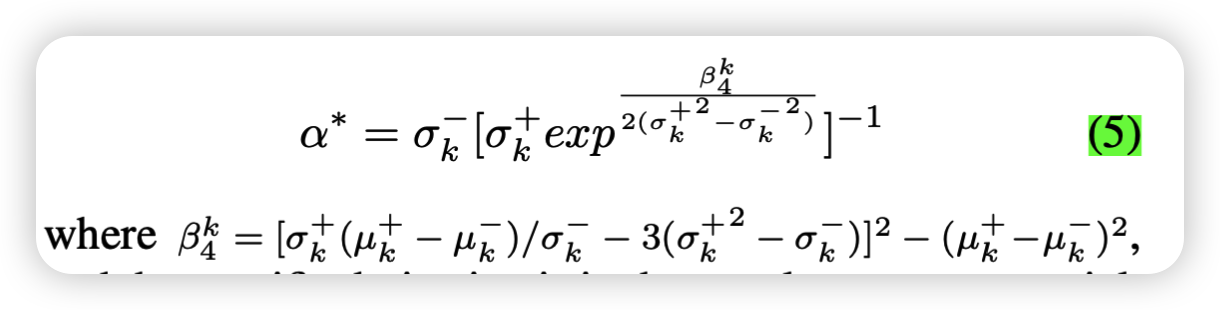
Neg-Pos Branch Matching
双分支框架可以同时关注图像-文本对中的不匹配和匹配片段,通过诉诸不同的注意力掩码来精确测量它们分别在消极和积极注意力中的效果。
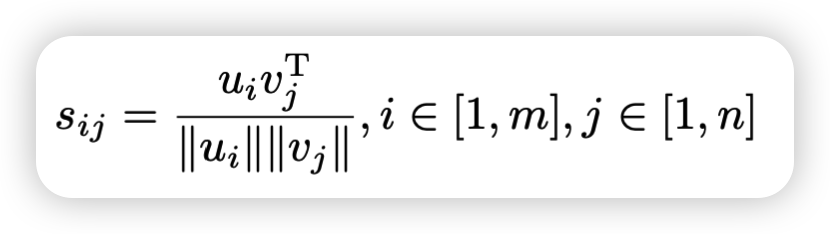
所有单词和区域之间的语义相关性得分,原理与AttnGAN中的DAMSM类似,我感觉和余弦相似度很像这里。
Negative attention
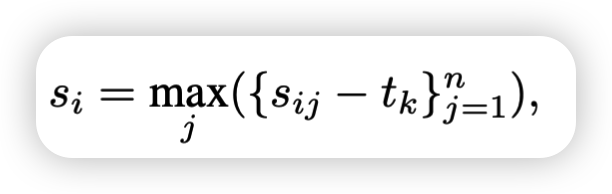
从文本出发,用一个文本单词和一个图像所有区域的相似度与边界tk做差,求最大值,就可以知道这个文本和这个图像中的某个区域的匹配或者不匹配程度。
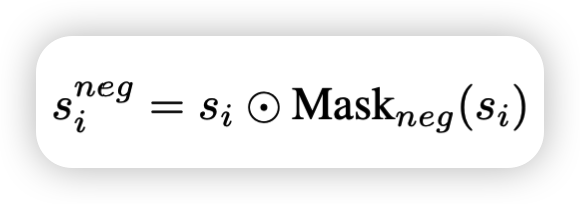
通过si就可以计算出在这个image-text pair中第i个单词所带来的负面作用;其中Maskneg(·)是掩码函数,若·为负数则输出1,否则为0。
由于文本语义的关系,使用语义相似的单词也应该获得相同的匹配关系,所以在intra- modal propagation中对每个单词的匹配程度进行一次模态内的传播,在inference过程(类似测试的过程)中增强过的si_hat会代替原有seg_neg中的si,wil代表第i个和第l个单词片段之间的语义关系(固定i,遍历l,算出词i和词l之间的近似程度),λ是比例因子,这样si_hat就是能代表近似词的;si_hat就是相似语义的词是否与图像区域的匹配程度:

Positive attention
这个分支旨在测量图像-文本对的相似程度,其中有两个方面需要考虑。首先关注的是跨模式的共享语义,也就是说,就每个查询词而言,对匹配的图像区域进行汇总,以衡量匹配片段的相似度。具体来说, 模式间的关注权重是通过以下方式计算的。
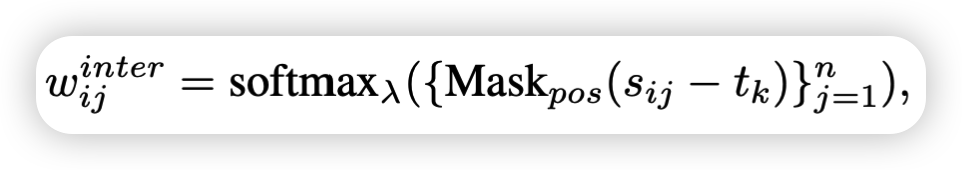
通过关注跨模态的共享语义,第i个单词在图像中相关的注意力分数wij,Mask_pos(·)用来遮掩不相关区域,当输入的·为正数时输入和输出相等,否则输出−∞,就可以使得不相关区域的注意力权重削减至0。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QEopueoq-1681713351814)(null)]
利用单词在图像中的匹配到的注意力分数与图像原有的特征相乘,实现跨模态中视觉部分的共享语义的和。这里其实就是用文本的匹配注意力和图像特征相乘,这样就可以实现跨模态的语义信息融合了,有关联的文本图像部分的特征就会更好。
根据文本得到的图文片段之间相似度分数:
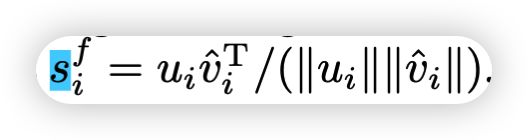
区域与单词之间的相关度分数反映了图文之间的相似度,相关性权重*相似度,得到的是加权后的相似度(基于文本图像间相关性的相似度)
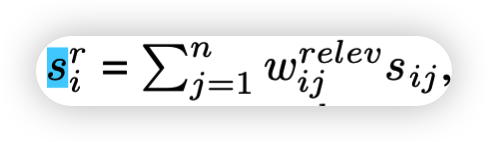
得到所有文本和图像的权重并且做一个softmax:
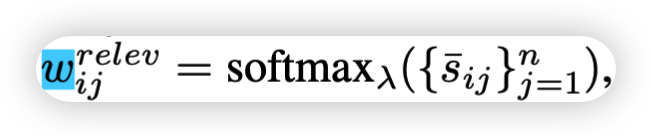
每个文本对一个图像区域的相似度占总的相似度的多少,就相当于是一个权重
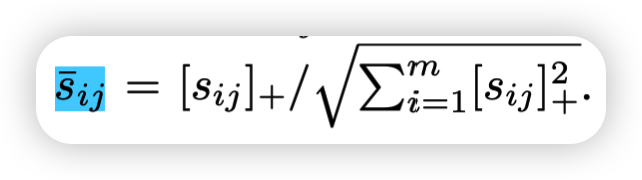
一个图像文本对中第i个单词所带来的正面作用,这里把基于文本-图像间的相关性的相似度+图文间的相似度,得到了更好的相正面作用(相似度分数)
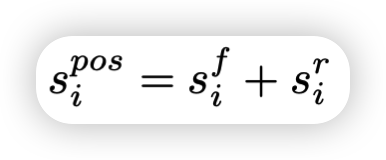
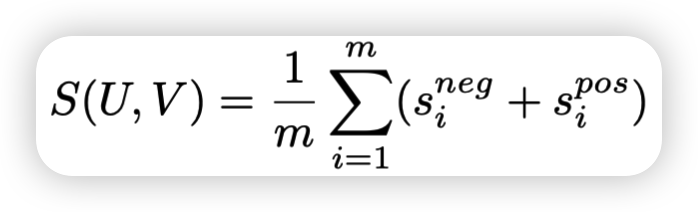
对正负相似度进行求和,共同确定负效应和正效应共同决定。
Sampling and Updating Strategy
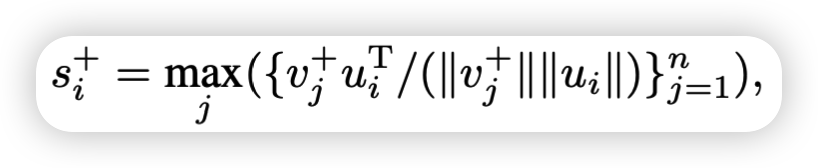
对于对齐的单词,在正确的图像中至少有一个匹配区域。则si+则是对单词ui和图像区域vj+之间的最大相似度。
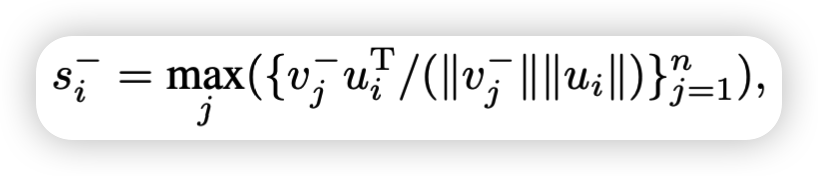
对于未对齐的单词,不正确图像中的所有区域都与其不匹配,但是作者认为没有匹配上的词语-区域相似性的最大值提供了错匹配的区分能力的上限。对于具有来自错误图像的图像区域vi-的词ui的不匹配相似度为si-。
为了对精确的伪词区域相似性标签进行采样,作者基于计算的相似度排名的正确性设计来决定是否更新si+和si-。
Loss Function
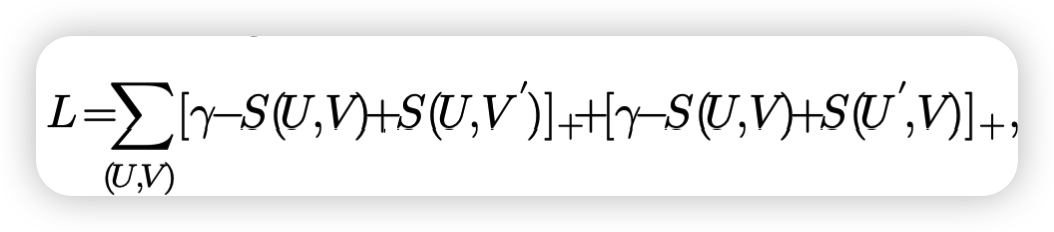
端到端训练的目标函数是双向三元组排序损失,损失函数.其中(U, V )表示成功匹配的图像和匹配的文本,(U, V′)和(U′, V )表示未成功匹配的图像和文本。
相关知识
SCAN
是一种基于注意力的局部水平匹配的方法中的代表。其关键思想是通过关注相关片段与另一模式的每个查询片段来发现所有的词-区域匹配。总之,匹配的片段(即具有高相关性分数的词-区域对)将对最终的图像-文本相似性做出很大贡献,而不匹配的片段(即具有低相关性分数的词-区域对)的影响将被削弱甚至消除,例如,通过典型的LeakyReLU或ReLU,在关注过程中迫使负分数接近或完全为零。
Intra-modal propagation
Intra-modal propagation是指在模型中进行信息传递时,同一种模态的信息在不同的层之间进行传递的过程。在图像和文本生成任务中,可以将图像和文本视为两种不同的模态,因此,在生成模型中,可以使用intra-modal propagation来传递图像和文本之间的信息。
双分支匹配
双分支的匹配机制是一种常见的深度学习模型,用于解决文本匹配或句子对匹配问题。其基本思想是通过两个分支来对待匹配的两个句子进行编码,然后将两个编码结果进行匹配得到一个相似度得分。以文本匹配任务为例,如问答匹配任务。在训练阶段,模型输入一个问题和一个答案,通过两个独立的编码器将问题和答案分别编码成两个向量。然后将两个向量输入到匹配模型中,计算两个向量的相似度得分。最后将得分通过一个全连接层输出预测匹配结果的概率。在测试阶段,当输入一个新的问题和答案时,模型可以根据相似度得分预测出它们是否匹配。
错误重叠匹配
相似性分布之间错误重叠的惩罚概率指的是,在自然语言处理任务中,在多个相似性分布之间匹配实体时,惩罚模型将同一实体匹配到多个分布的概率。这个概率通常用来衡量模型对错误重叠的敏感性,以及模型在处理多个相似性分布时的准确性。
在许多自然语言处理任务中,例如问答系统、文本匹配和信息抽取等任务,相似性分布被用来计算文本之间的相似度得分。这些相似度得分可以用来判断两个文本是否相似,或者两个文本中的实体是否匹配。在多个相似性分布之间进行匹配时,错误重叠可能会导致模型产生错误的匹配结果,从而降低模型的准确性。
为了避免错误重叠,通常会在模型的损失函数中引入相应的惩罚项,以惩罚模型将同一实体匹配到多个相似性分布的行为。
AttenGAN是一种用于图像生成的生成对抗网络(GAN)模型,它使用注意力机制来提高生成图像的质量。
注意力机制使生成器在生成新细节时可以聚焦于图像的特定区域,而不是一次性生成整个图像。这有助于生成器产生更逼真和详细的图像。
AttenGan DAMSM
AttenGAN是一种用于图像生成的生成对抗网络(GAN)模型,它使用注意力机制来提高生成图像的质量。
注意力机制使生成器在生成新细节时可以聚焦于图像的特定区域,而不是一次性生成整个图像。这有助于生成器产生更逼真和详细的图像。
DAMSM是AttenGAN模型中的一种神经网络,用于计算图像和文本之间的相似性分数,以改善生成图像的质量。
DAMSM代表“Dual Attention Multi-Scale Spatial Memory”,它包括两个部分:注意力机制(Attention)和多尺度空间记忆(Spatial Memory)。其中注意力机制用于对齐图像和文本的特征向量,以计算它们之间的相似性分数。而多尺度空间记忆则用于将注意力机制应用于多个尺度的图像特征上,以提高生成图像的质量和多样性。
DAMSM模型包含多个公式,其中最重要的是计算图像和文本之间相似性分数的公式。具体而言,这个公式可以表示为:
similarity = exp( f(I, T) / temperature )
其中,f(I, T)表示注意力机制计算出的图像和文本的特征向量之间的余弦相似性分数。temperature是一个超参数,它控制相似性分数的大小,可以通过调整它来平衡模型的准确性和多样性。
注意力机制的公式也很重要,它可以表示为:
M = softmax( f(I, T) / sqrt(d_k) ) V
其中,f(I, T)是将图像和文本特征向量变换到一个共同的向量空间中的函数。d_k是向量的维度,softmax函数用于计算权重,V是值向量。这个公式将图像和文本的特征向量映射到一个中间向量M,该向量反映了图像和文本之间的对齐程度,从而帮助计算它们之间的相似性分数。
跨模态的共享语义
跨模态的共享语义是指不同模态(例如语言、图像、声音等)之间共享的意义和概念,它们在不同模态之间具有相同的语义含义。这些共享的语义可以用于跨模态的任务,如图像描述、视觉问答和视频分类等。
共享语义是通过将不同模态之间的数据转换为共同的语义表示来实现的。这种表示可以是低维的向量空间,其中每个向量表示一个概念或意义。这些向量可以用于在不同模态之间建立语义联系和相似性,从而实现跨模态的任务。
- 图像描述
在图像描述任务中,计算机需要将一张图像转换为自然语言描述。为了实现这个任务,计算机需要将图像中的视觉信息转换为自然语言,这就需要建立跨模态的共享语义。具体地,我们可以将图像中的每个区域(如物体、场景、颜色等)表示为向量,然后将这些向量与自然语言中的单词和短语相匹配。这样,我们就可以建立图像和文本之间的共享语义,从而实现图像描述任务。
2.视频分类
在视频分类任务中,计算机需要根据视频内容将其归类到不同的类别中。为了实现这个任务,我们需要将视频中的多个模态(如图像、音频和文本)转换为共同的语义表示,从而捕捉视频中的内容和情感。具体地,我们可以使用卷积神经网络(CNN)和循环神经网络(RNN)等模型从视频帧中提取视觉信息,并使用语音识别技术从视频中提取语音信息。然后,我们可以将这些信息转换为共同的语义表示,从而实现跨模态的视频分类任务。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









