






LayoutLMv3
提出的问题
- 对于之前所提出的LayoutLMv2来说,已经有了很好的效果,但由于layoutlm系列的基础框架用的是Transformer模型,如果想要改善模型,就要从①一开始的特征融合,②Transformer模块,③训练默任务;对于VrDU的任务来说,在文本模态上基本保持一致,采取MLM预训练策略,但是在图像模态上的预训练任务往往是不同的,所以对于多模态之间的特征学习就造成了困难(因为之前采用的都是cnn或者fast-RCNN的特征提取方法来提取的图像特征)。
模型
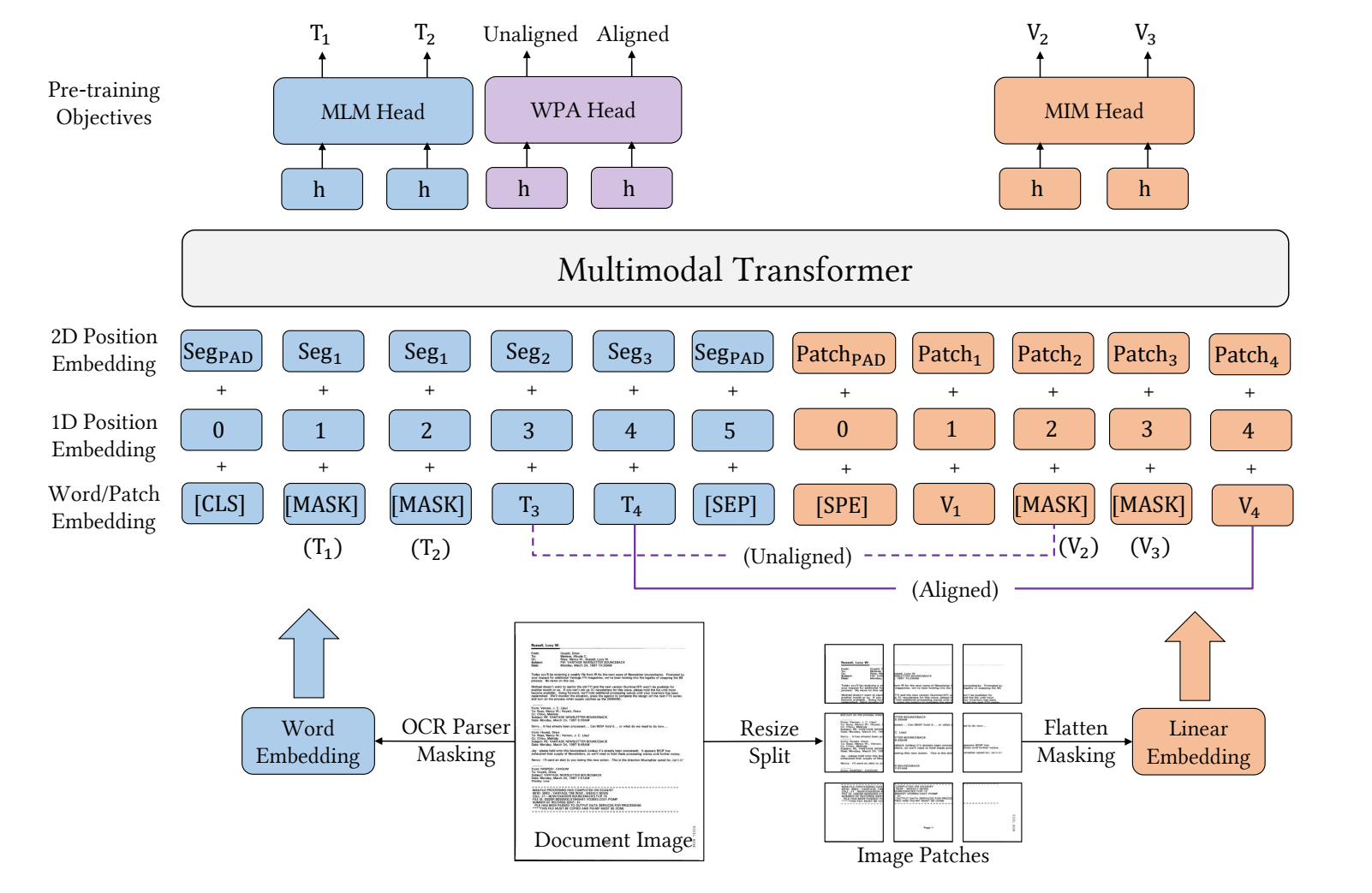
特征融合部分
- LayoutLMv3改善了LayoutLMv2在特征融合时的2D position embedding,认为在同一个OCR框中的单词是能够表达类似意思的,于是认为同一个OCR框中的单词享用一样的2D position embedding,这么做可以使模型学习到更多的语义信息。
- 例如说上图的word embedding那边,T1和T2来自一个OCR框,那么在2D position embedding那边他们都用一样的seg作为他们的坐标。
- 将图像的特征提取方面不再像LayoutLMv2一样是采用别的CNN或者fastrcnn中的骨干网络进行提取后flatten成一维的token,而是改成使用ViT(可以吧ViT理解成就是图像分类的操作)将图像转换成token。
- ViT大致就在做一件事情,就是说把一张图像(C*A*A)放进来,然后将它分成一个a*a大小的patch,共分成N个
- 然后对其进行线性变换(用一个a*a的卷积层进行卷积)降维转换成1*1大小的特征
- 对整个图像做上述操作之后就可以得到一个长宽都是A/a大小的fature map,并且特征深度为a*a*C
- 最后Flatten成一维的token
- 在模型中在加上一个开始符合结束符(图像没有结束符),然后作为embedding
- 对于图像的position embedding只用1D的不需要使用2D(上图的这个patch1什么的没啥用)
预训练任务部分
- Masked Language Modeling (MLM) 文本对齐任务:
- 不再是随机、孤立的mask掉某个token,而是一次性mask一定长度的tokens。长度从泊松分布(λ=3)中抽样确定。从视觉上下文token(X′)以及文本上下文token(Y′)来预测这些真正被mask掉的文本token。在保持布局信息不变的情况下,该目标有助于模型学习布局信息与文本和图像上下文之间的对应关系。(参考与BART模型)
- 填空任务,学习文本的表征
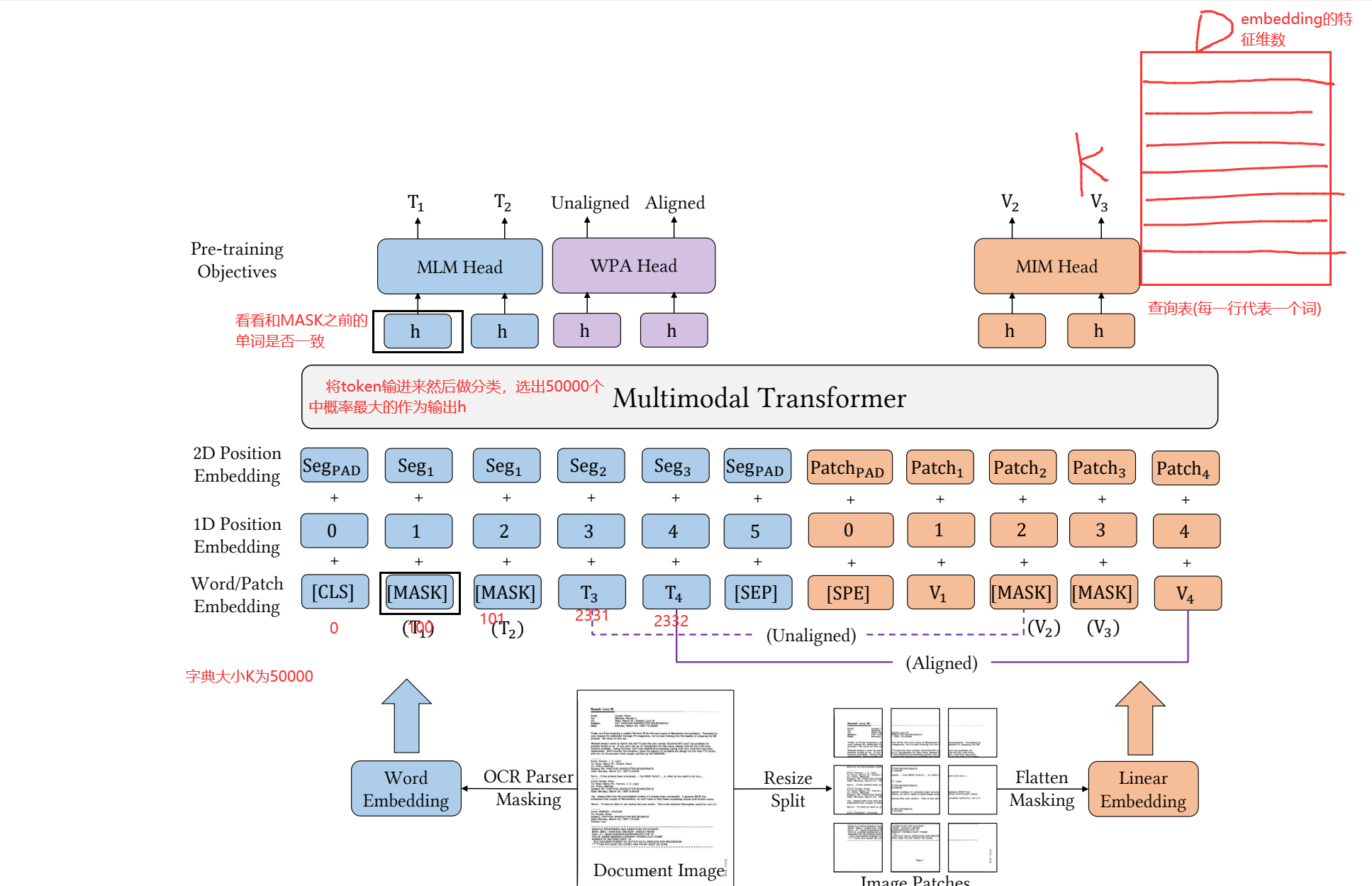
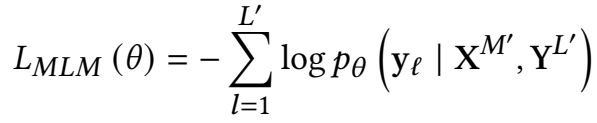
- **Masked Image Modeling (MIM)**图像对齐任务:
- 和上面的一样,这个是预测被mask的图像token。随机mask掉约40%的image toke,mask策略采用blockwise masking strategy。(具体参照Beit)。被mask掉的patch通过image tokenizer转化为离散的数字(image tokenizer来源于预训练DiT),进而对这些maskedpatch进行预测即可。
- 也是类似填空任务,只不过是面对图像,让模型学习图像的表征
- 这里用的mask是mask一个区域然后在Flatten的,这样就可以让图像被mask后不那么容易被复原,而这个任务的目标也是做出一个预测,那么就同样需要一个词典,而这个图像词典是来自DALL-E2模型生成的,就可以把对应的预测结果去图像词典中去找
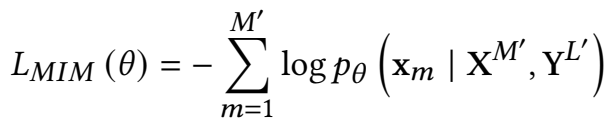
- 做法和文本对齐类似,思想源于BEiT
- **Word-Patch Alignment (WPA)**词-块对齐:
- 前俩预训练任务没有显式的做visual和text之间的模态对齐。对于前两个任务所产生的输入,这里会对每个text token赋予<aligned>以及<unaligned>标签。
- 对于那些text token没被MLM掉,但是被MIM掉(每个text token会有其位置信息的)的,赋予<unaligned>标签。对于那些没被MLM掉,也没被MIN掉的,赋予<aligned>标签。
- 对于以上被标记了的token,通过两层FC进行预测是aligned还是unaligned,所以是一个二分类。
- 这里要忽略掉那些被MLM掉的text token,即它们不参与loss计算,这么做事为了防止模型从masked text以及image patch之间学到一些没什么用的关系。
- 目的就是预测文本单词对应的图像块是否有被掩盖,对到让模型知道文本是来自于哪一个图像
- 这里要注意一下的是该任务用的文本token是没有被mask的,如果有mask的就只拿去做第一个预训练任务
- 补充说一下第2点,假设传入的是上图中的T3 token,那么经过任务三之后会去对齐说来自于哪一个图像patch,若它所在的图像patch被mask掉了,那么就会预测出<unaligned>,否则是<aligned>
- 对于文章作者并没没有采用一个单词一个单词的去做对齐,而是采用了这个单词所在的ocr框框去做对齐的
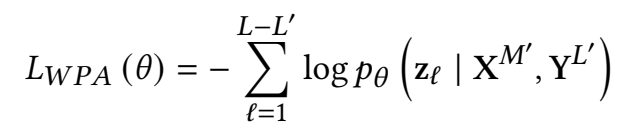
总结
- 提出了一个采取统一文本和图像掩膜任务并应用于Document AI的多模态预训练模型——LayoutLMv3。
- 不再需要预训练CNN或者Faster-RCNN进行视觉特征抽取。
- LayoutLMv3不论在text-centric task还是image-centric task上均取得了SOTA。
个人的疑问
- 问:图像块说的应该是文本块,词难道说的是单词吗?单词和和文本图像对齐?
- 答:字面意思上的单词和文本图像对齐。
- 问:为什么说段中单词共享相同2D位置,是因为单词通常表达相同的语义?
- 答:我猜这里说的每个ocr框中的内容所代表的是具有相同的语义的意思是对于类似模板的文档,在相同的坐标位置中所包含的内容是一样的key所对应的不同的value,这样学出来的模型更具有鲁棒性
- 纠正:这里说的共享2D位置并非上面我所说,而是说以往的layoutlmv2采用的,都是传统OCR算法(给出的都是成行的OCR框,例如Happy day那么OCR框出来的一般就是这两个单词何在一起的)然后根据单词的长度什么的特征去估算每个单词在OCR框中的坐标位置,而LayoutLMv3则不去关注每个单词的位置,而是将每个单词的2D坐标就认为是OCR出来的坐标,因为能过被OCR在一起的单词通常是具有类似的意思的;这么做的话就可以让模型学到更多的语义信息















 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









