







最小生成树算法(Prim和Kruskal)
最小生成树—Prim算法
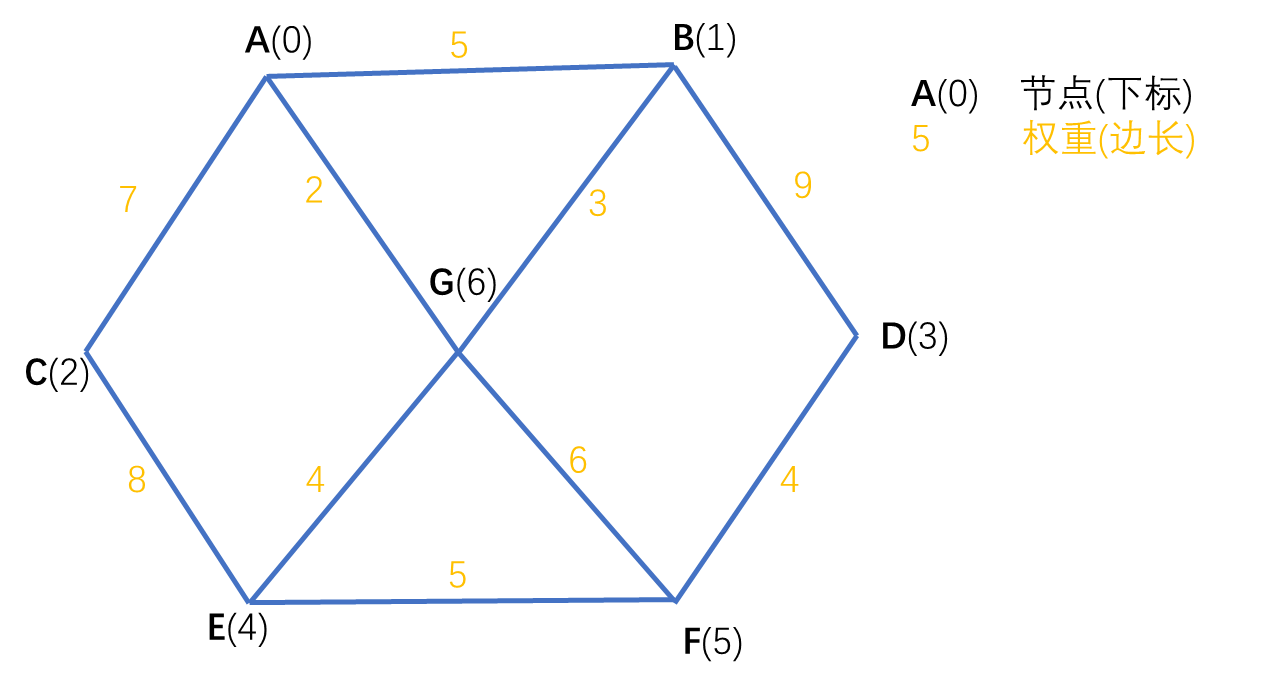
最小生成树(Minimum Cost Spanning Tree),简称MST,也叫极小连通子图给定一个带权的左向连接通图,如何选取一棵生成树,使树上所有边上权的总和为最小.
最小生成树中, N N N个顶点,一定有 N − 1 N-1 N−1条边,包含全部顶点, N − 1 N-1 N−1条边都在图中
Prim算法流程(Prim算法针对的是顶点,不会操作标记集以内的顶点,故不会产生回路):
- 设 G = ( V , E ) G=(V,E) G=(V,E)是连通网, T = ( U , D ) T=(U,D) T=(U,D)为最小生成树, V , U V,U V,U是顶点集合, E , D E,D E,D是边的集合
- 若从顶点 u u u开始构造最小生成树,则从集合 V V V中取出 u u u放入集合 U U U中,标记顶点 v v v的 v i s i t e d [ u ] = 1 visited[u]=1 visited[u]=1
- 若集合 U U U中的顶点 u i u_i ui与集合 V − U V-U V−U(差集)中的顶点 v j v_j vj存在边,则寻找所有这些边中权值最小的边(不会构成回路),将顶点 v j v_j vj加入集合 U U U中,将边 ( u i , v j ) (u_i,v_j) (ui,vj)加入集合 D D D中,标记 v i s i t e d [ v j ] = 1 visited[v_j]=1 visited[vj]=1
- 重复步骤3,直到 U U U中包含了 V V V所有的顶点,即所有的顶点都被标记访问过,此时 D D D中恰好有 n − 1 n-1 n−1条边
具体实现见后文完整代码(注释有更详细的解析)
最小生成树—Kruskal算法
Kruskal算法流程(Kruskal算法针对的是边,因此增加边的时候需要考虑是否会产生回路):
-
创建所有边的集合
-
将边集中,以边的权重为指标,将所有边按照权重升序排列
-
创建一个空集合,用于存储最小生成树的边
-
循环对边按权重从低到高进行检查,从每条边的起点和终点进行检查,判断是否构成回路,没有形成回路则将边加入集合中
-
一直到最小生成树集合中存在 n − 1 n-1 n−1条边( n n n为顶点数量)
具体实现见后文完整代码(注释有更详细的解析)
完整代码:
import java.util.ArrayList;
import java.util.Collections;
//无向图
public class Graph
{
char[] vertexes; //顶点集合(字符)
int verNum; //顶点数量
int[][] weightMatrix; //邻接矩阵
ArrayList<Edge> edges; //边的集合
int edgeNum; //边的数量
final int maxValue = 10000; //极大值(用于初始化不可及的边长)
//构造函数
public Graph(char[] vertexes)
{
this.vertexes = vertexes;
verNum = vertexes.length;
weightMatrix = new int[verNum][verNum];
for (int i = 0; i < verNum; i++)
{
for (int j = 0; j < verNum; j++)
{
if(i == j) //条件:此时含义为自己到自己的距离,初始化为0
{
weightMatrix[i][j] = 0;
}
else
{
weightMatrix[i][j] = maxValue;
}
}
}
edges = new ArrayList<>(); //边集初始化为空集合
edgeNum = 0; //边数初始化为0
}
/**
* 获取顶点(字符)在字符数组中的的下标索引
* @param c 顶点字符
* @return 返回该字符在数组中的索引下标
*/
private int getPosition(char c)
{
for (int i = 0; i < verNum; i++)
{
if(vertexes[i] == c) //条件:输入字符与数组中的字符相等
{
return i; //返回索引
}
}
return -1; //循环结束还未找到,则返回-1
}
/**
* 增加边的函数
* @param c1 起始顶点字符
* @param c2 末尾顶点字符
* @param weight 边的权重
*/
public void addEdge(char c1,char c2,int weight)
{
int c1Index = getPosition(c1); //获取c1的索引
int c2Index = getPosition(c2); //获取c2的索引
if(c1Index != -1 && c2Index != -1) //条件:索引有效
{
weightMatrix[c1Index][c2Index] = weight;
weightMatrix[c2Index][c1Index] = weight;
edges.add(new Edge(c1,c2,weight)); //添加至边集
edgeNum++; //边数加1
}
}
/**
* 最小生成树---Prim算法
*/
public void Prim()
{
boolean[] isVisited = new boolean[verNum]; //记录是否已被标记的数组
ArrayList<Edge> mst = new ArrayList<>(); //最小生成树的边集
isVisited[5] = true; //标记初始顶点
int distAll = 0; //生成树的总长初始化为0
for (int k = 0; k < verNum - 1; k++) //除去初始顶点之后,还需要标记verNum - 1个顶点
{
int start = -1; //start为此次循环找到的边的起始点
int end = -1; //end为此次循环找到的边的末尾点
int minDist = maxValue; //minDist为此次循环找到的边的权值
//两层循环遍历所有顶点(遇到已标记的跳过本次循环)
for (int i = 0; i < verNum; i++) //i遍历起始点
{
for (int j = 0; j < verNum; j++) //j遍历末尾点
{
//条件:顶点i(下标)已被标记,顶点j未被标记,且当前找到的边(i->j)小于已经找到的边的最小值minDist
if(isVisited[i] && !isVisited[j] && weightMatrix[i][j] < minDist)
{
minDist = weightMatrix[i][j]; //更新minDist
start = i;
end = j;
}
}
}
isVisited[end] = true; //标记新找到的边的末尾点
mst.add(new Edge(vertexes[start],vertexes[end],minDist));
distAll += minDist;
}
System.out.println("Prim算法---最小生成树的总长度为:" + distAll);
System.out.println(mst);
}
/**
* 最小生成树--Kruskal算法
*/
public void Kruskal()
{
Collections.sort(edges); //将所有的边按照边长进行升序排列
ArrayList<Edge> mst = new ArrayList<>(); //创建最小生成树的边集合
int[] ends = new int[verNum]; //创建ends数组
int distAll = 0; //初始化生成树总长度为0
for (Edge edge : edges) //按照边长,从小到大遍历所有边
{
int v1 = getPosition(edge.start); //v1为当前边的起始点
int v2 = getPosition(edge.end); //v2为当前边的末尾点
int v1Cluster = getCluster(ends,v1); //v1Cluster为起始点的类别
int v2Cluster = getCluster(ends,v2); //v2Cluster为末尾点的类别
if(v1Cluster != v2Cluster) //条件:如果起始点和末尾点的类别不同,则认为加入当前边并不会连通该图
{ // 即仍然可以保持树的结构,此时添加该边至最小生成树的边集
mst.add(edge); //添加该边至最小生成树的边集
ends[v2Cluster] = v1Cluster; //将起始点和末尾点划为一类
distAll += edge.weight; //累加当前边的权重
}
else
{
continue; //若为一类,则直接进行下一次循环
}
if(mst.size() == verNum - 1) //最小生成树MST的边数为顶点数 - 1(verNum - 1),若达到这个数量则可以直接结束循环
{
break;
}
}
System.out.println("Kruskal算法---最小生成树的总长度为:" + distAll);
System.out.println(mst);
}
/**
* 获取该顶点的类别标号
* @param ends ends为一个一维数组,长度和顶点集合vertexes一样长.
* 给定一个顶点的索引值cluster,对应的数组值ends[cluster]的值有以下含义:
* 1. ends[cluster]不为0:ends[cluster]为下一个同类别的顶点的索引,
* 获取这个索引后应继续往下寻找,直至找到ends[cluster] == 0的顶点索引
* 2. ends[cluster]为0:代表同类别的顶点已搜索到最后一个
* @param vertex vertex代表输入的顶点的索引
* @return 用寻找到的同类别的最后一个顶点的下标当作"类别名",然后将其返回
*/
private int getCluster(int[] ends,int vertex)
{
int cluster = vertex; //初始化顶点的类别,为顶点自身的下标
while(ends[cluster] != 0) //循环退出条件:寻找到该类的尽头
{
cluster = ends[cluster];
}
return cluster;
}
}
//"边"类(要实现Comparable接口,为了方便排序)
class Edge implements Comparable<Edge>
{
char start;
char end;
int weight;
public Edge(char start, char end, int weight)
{
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public String toString()
{
return "<" + start + "->" + end + ">=" + weight;
}
@Override
public int compareTo(Edge o)
{
return this.weight - o.weight;
}
}















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











